Zero Redundancy Rollouts (ZoRRo): Breaking the Speed-of-Light for Enterprise RL Training


Special Relativity states that nothing can travel faster than the speed-of-light. In AI systems, we often refer to the hardware peak as this speed-of-light that cannot be exceeded. And while exceeding this limit is impossible, it is possible to create shortcuts. Wormholes in theory can bend space-time to allow traveling millions of light-years in seconds without violating the laws of physics.
In the same spirit, we have identified redundancies in reinforcement learning (RL) training computational space that, when removed, allow us to achieve speeds that seemingly exceed the achievable hardware peak (see Figure 1). We call these optimizations ZoRRo (Zero Redundancy Rollouts) for RL.
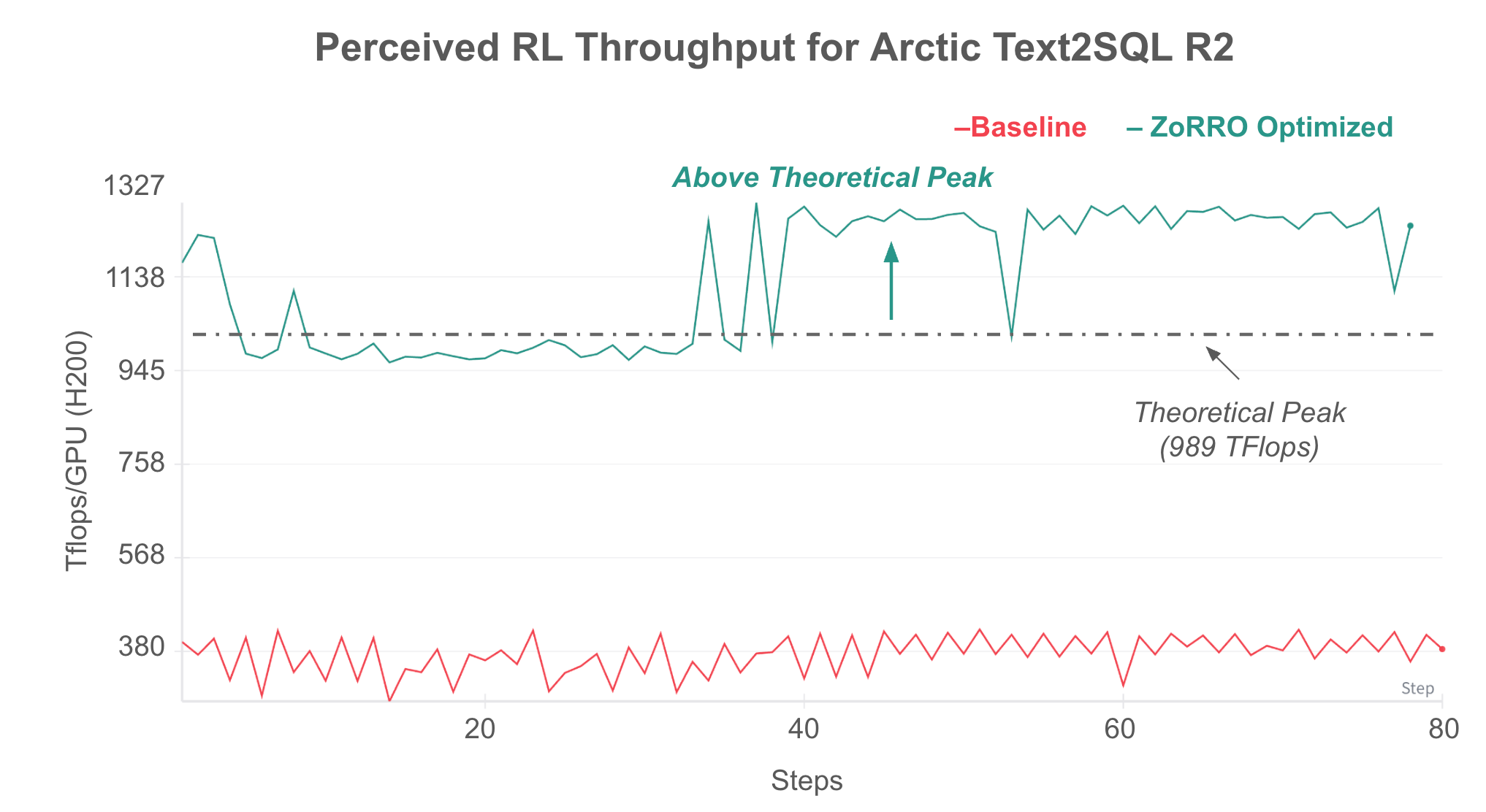
Figure 1: Perceived RL throughput comparison for Arctic Text2SQL R2 production run on 32xH200 GPUs between vanilla VeRL baseline and ZoRRo optimized version1. Normalized to the total computation in baseline VeRL that includes prompt redundancy, our ZoRRo optimized implementation achieves per GPU throughput of over 1130 TFlops seemingly exceeding the theoretical peak H200 throughput of 989 TFlops in bf16.
In long-context RL training, standard RL systems replicate prompts for each rollout, resulting in massive redundancies in both training and rollout. ZoRRo eliminates these fundamental bottlenecks in long-context RL training. By removing prompt redundancy across training and inference, ZoRRo delivers two critical capabilities: speed and scale. For our production RL workloads, ZoRRo accelerates RL training by up to 3.5x, allowing rapid iteration cycles that allow us to explore fine-grained reward formulations and architectural variations that would be prohibitively time-consuming with standard systems. Simultaneously, ZoRRo reduces memory consumption that allows up to 3.2x longer context window — increases that were impossible with standard RL systems without introducing instabilities or costly throughput overheads.
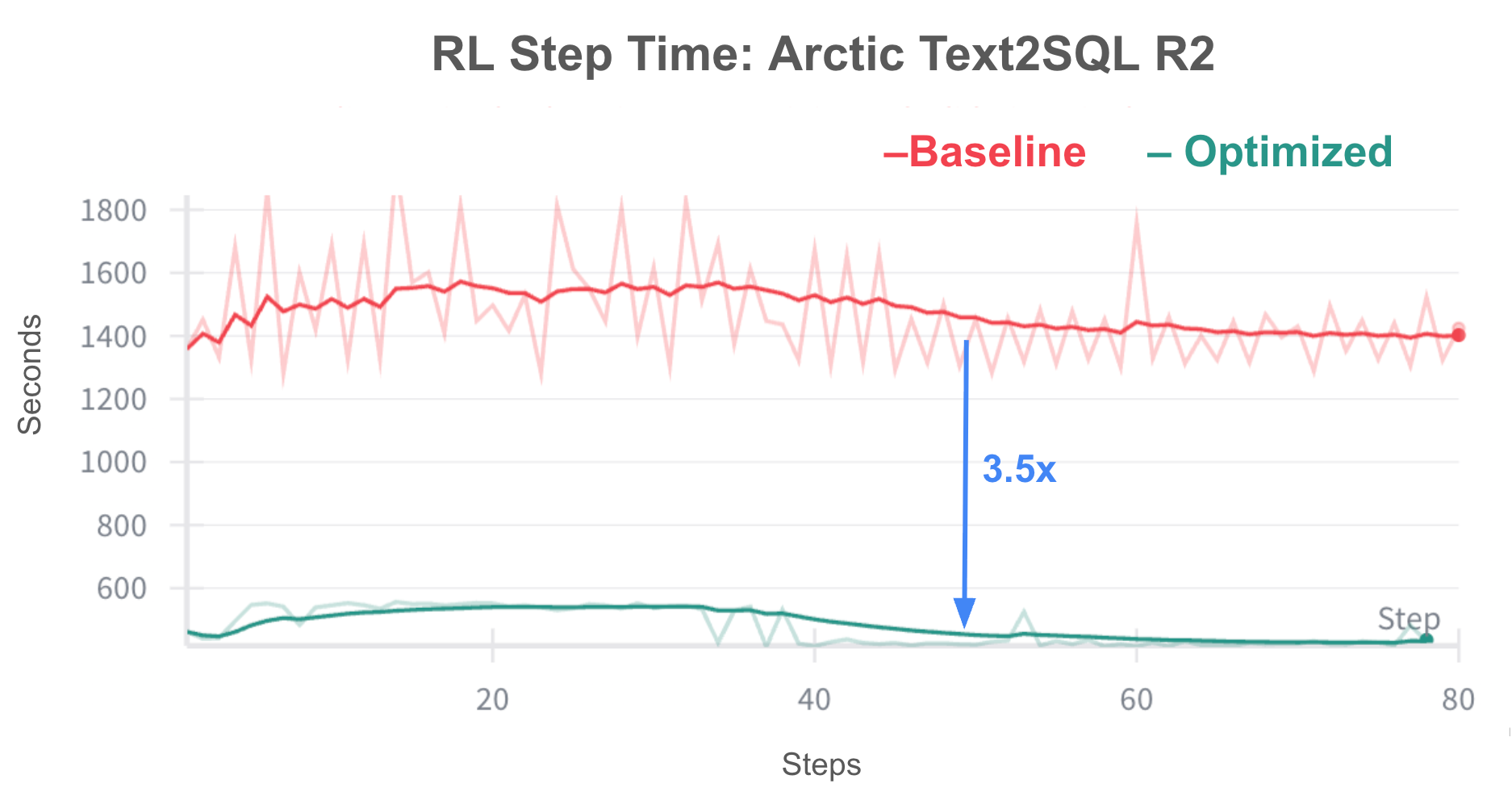
Figure 2: RL iteration time in seconds for training Arctic-Text2SQL-R2 using VeRL baseline vs VeRL+ ZoRRo on 32 H200 GPUs. ZoRRo offered a 3.5x speedup, allowing each training run to complete in 1.5 days compared to over five days with the baseline.
Together, these improvements directly translated to model quality: Faster iteration allowed us to refine our training recipe quickly, while larger batches improved gradient stability and longer contexts captured richer task structure. The result: Arctic-Text2SQL-R2, a model that outperformed frontier models like Gemini 3.1 Pro and Claude 4.7 on Snowflake's enterprise SQL benchmark despite being significantly smaller.
In this blog, we share the key optimizations behind ZoRRo — split attention for training, Forest Cascade Attention for inference and speculative decoding for generation — and demonstrate how these techniques allowed Arctic-Text2SQL-R2 to achieve state-of-the-art accuracy on highly technical enterprise data. For details on the Text2SQL modeling recipe, data pipeline and reward formulation, see our sister blog post.
Zero Redundancy Rollouts (ZoRRo)
In reinforcement learning (RL) training, each prompt is paired with multiple rollouts — typically eight to 64 completions per prompt. Standard systems treat each prompt-response pair independently, recomputing the identical prompt representation over and over during the actor update, log-prob computation and rollout generation. For long-prompt workloads like Text2SQL, where prompts can be an order of magnitude longer than responses, this redundancy dominates the training cost. For instance across a batch of 16K samples with 16 rollouts per prompt, only 1K unique prompts exist — yet the system processes all 16K prompt representations as if they were distinct.
ZoRRo eliminates this redundancy across both training and inference.
ZoRRo for Training2 (Actor Update and Log Prob). ZoRRo's prompt deduplicator scans the batch, identifies groups of samples sharing identical prompts and constructs a deduplicated sequence: Each unique prompt appears once, followed by all its associated responses. For non-attention layers (MLPs, LayerNorms), deduplication is straightforward — forward on unique prompts and all the responses. The key challenge is attention, where prompt and response tokens interact during attention.
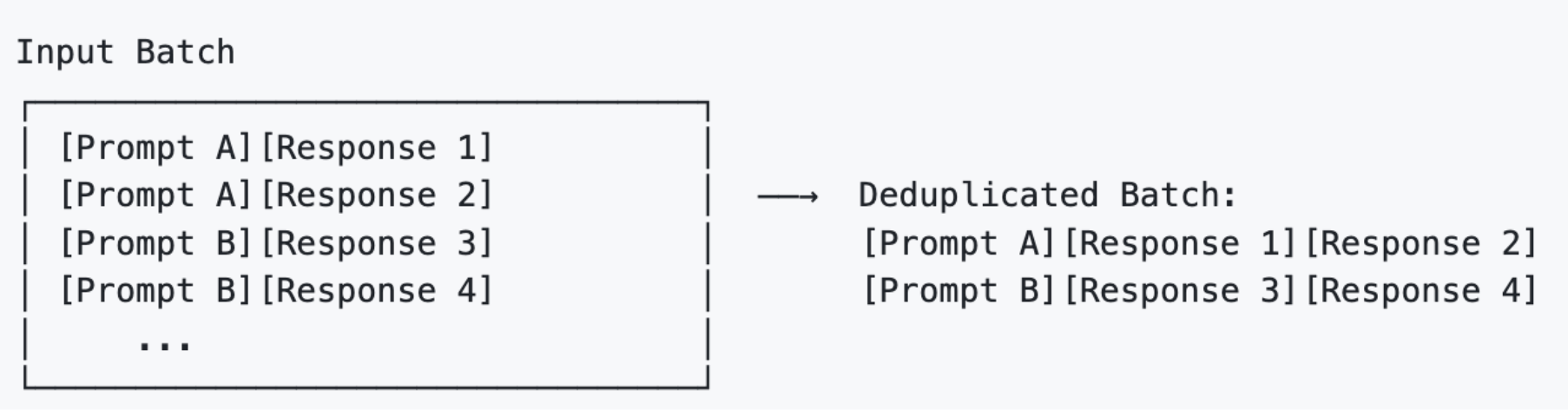
ZoRRo addresses this with split attention, which decomposes each attention layer into two phases:
- Prompt-only self-attention runs causal self-attention over only the unique prompts — computed once and reused across all rollouts in the group.
- Response-to-full-sequence cross-attention runs attention for each response attending to its full context (shared prompt + unique response).
The results are merged and passed through the output projection. A dedicated patcher restructures the forward pass to implement this decomposition, and gradients flow correctly through PyTorch autograd without any custom backward logic.
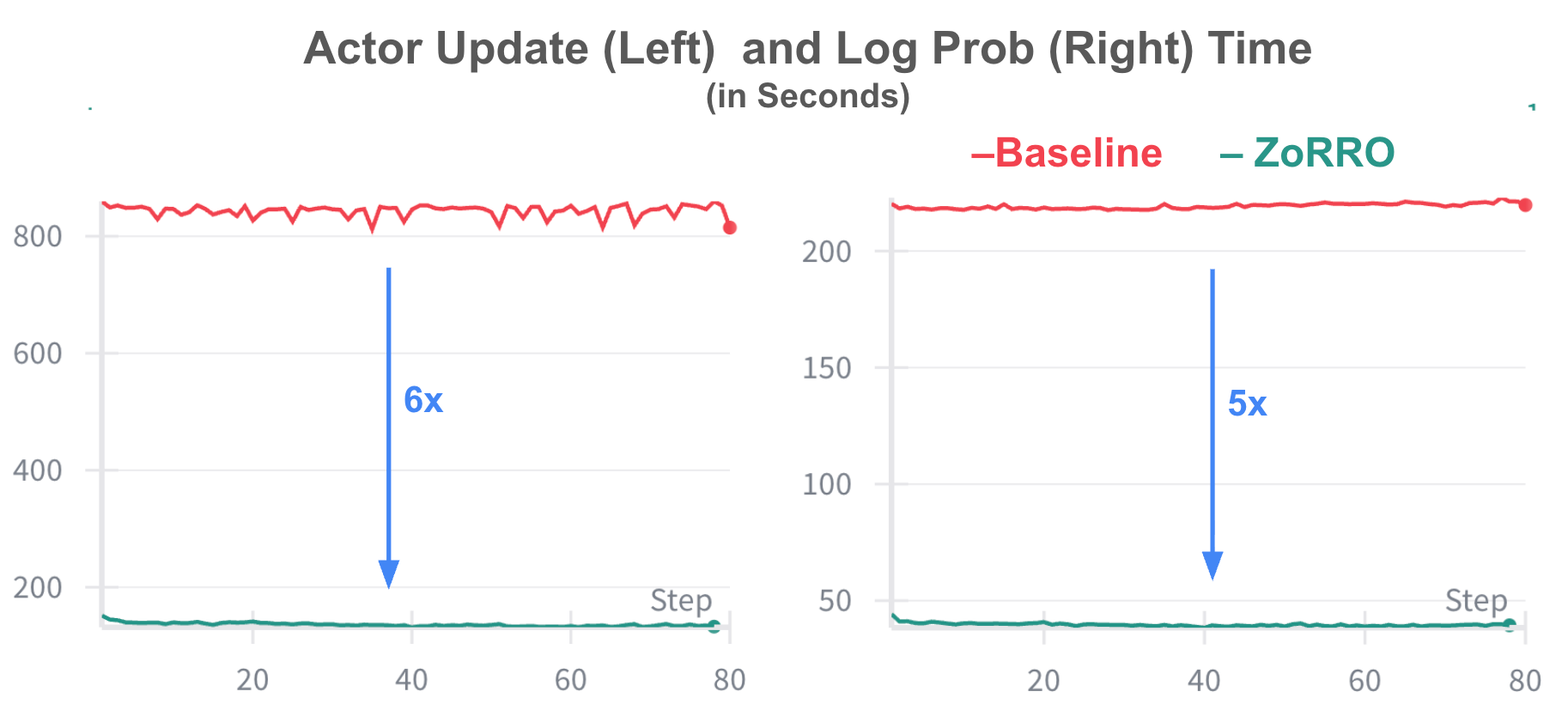
Figure 3: For Arctic-Text2SQL-R2 workload, ZoRRo demonstrated 6x faster actor update and 5x faster log prob computation. For this workload, our max prompt length was 16K, generation was 4K and rollout was 16.
The result: ~6x speedup on the actor update and 5x speedup on the log-prob computation for Arctic Text2SQL R2 training (see Figure 3). In general, ZoRRo's idealized compute reduction factor is approximately:
#rollout x (prompt_len + response_len) / (prompt_len + #rollout x response_len)
This is the ratio between the baseline work and ZoRRo's deduplicated work. Furthermore, this is also the ratio by which the memory needed to store activations during the training is reduced. This freed memory can be used to support larger prompt lengths. For Arctic Text2SQL, we were able to scale the context window by 3.2x from 20K → 64K.
ZoRRo for Inference (rollout generation). But what about the other major bottleneck — rollout generation itself? Standard prefix caching avoids duplicated prefill by computing the prompt KV cache once and reusing it across rollouts that share the same prompt. However, it does not eliminate redundancy during decoding. After prefill, each rollout becomes an independent decode stream. At every decode step, every stream still attends to the same shared prompt KV cache, causing the same long-prefix KV tensors to be reread from HBM once per rollout. For long prompts and many rollouts per prompt, this repeated memory traffic can dominate generation time. ZoRRo targets this remaining bottleneck: redundant decode-time reads of the shared prompt KV cache.
Cascade attention addresses this by decoupling shared-prefix and per-request suffix attention into separate passes, keeping the shared KV cache in on-chip GPU shared memory (SMEM) for reuse across requests. However, standard cascade attention requires the prefix tree structure to be explicitly provided by the serving framework. RL workloads present further challenges: many distinct prompts, each generating multiple responses concurrently, with no predefined tree — a forest of prefix trees, not a single trunk.
Forest Cascade Attention is our extension of cascade attention to this multi-prefix RL setting. At decode time, it discovers groups of requests sharing KV-cache prefixes (via lexicographic sorting over block tables and longest-common-prefix computation), then performs a single grouped attention call per prefix group — achieving on-chip KV cache reuse via GPU shared memory across all requests in each group. Each request then runs a separate suffix attention for its unique continuation, and the results are merged via log-sum-exp. This turns what was a per-request memory-bandwidth bottleneck into a shared, amortized operation — even when dozens of different prompts are being rolled out simultaneously.
Forest Cascade reduces the per-step cost of decoding, but rollout generation has yet another dimension: reasoning models produce long chains of thought, and each token still requires a full forward pass through the target model. Speculative decoding addresses this orthogonally — a lightweight draft model (in our case, LSTM-based Arctic Speculator) predicts multiple tokens at once, and the target model verifies them in a single forward pass. Combined with Forest Cascade, this compounds: fewer HBM reads per step and fewer steps overall.
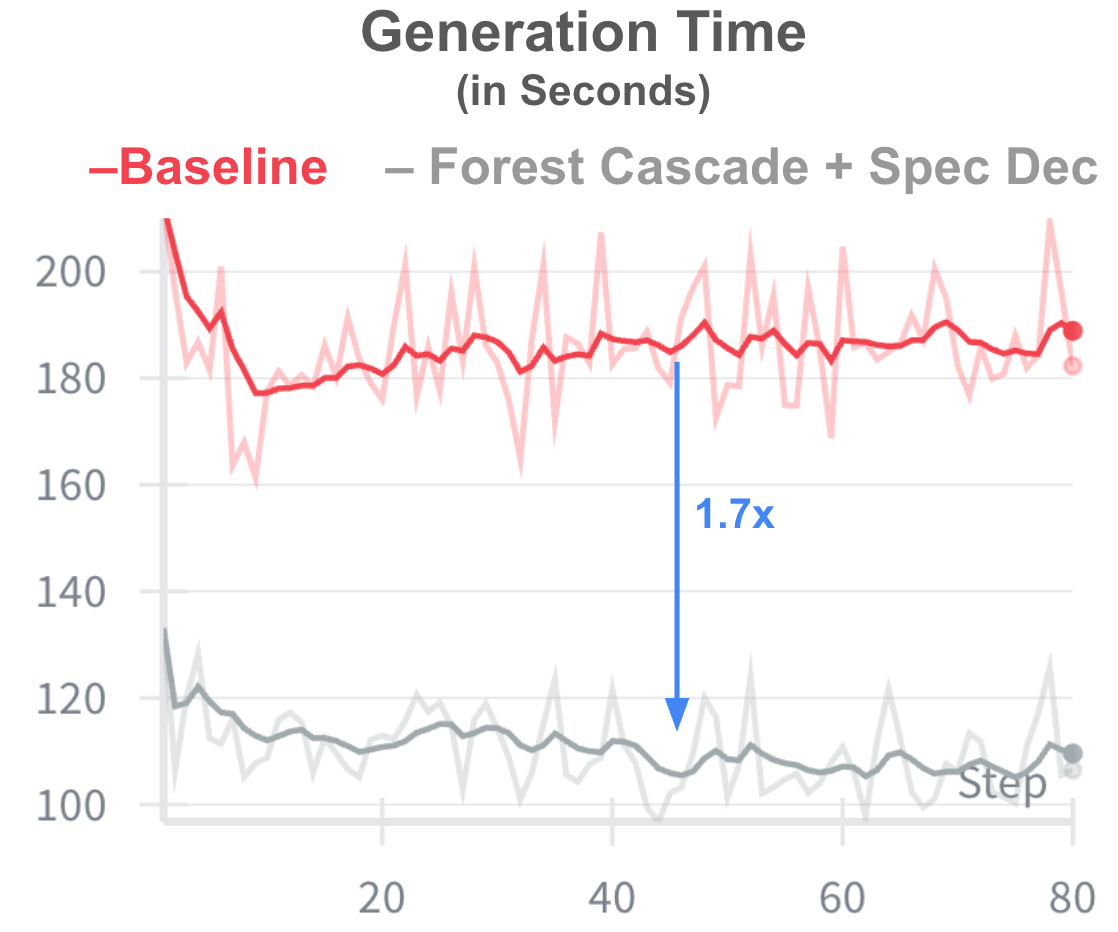
Figure 4: For Arctic-Text2SQL-R2 workload, ZoRRo demonstrated 1.7x faster generation time.
The result: 1.7x speedup on rollout generation from Forest Cascade and speculative decoding combined for Arctic Text2SQL R2 training (see Figure 4).
Enterprise RL workloads accelerated with ZoRRo
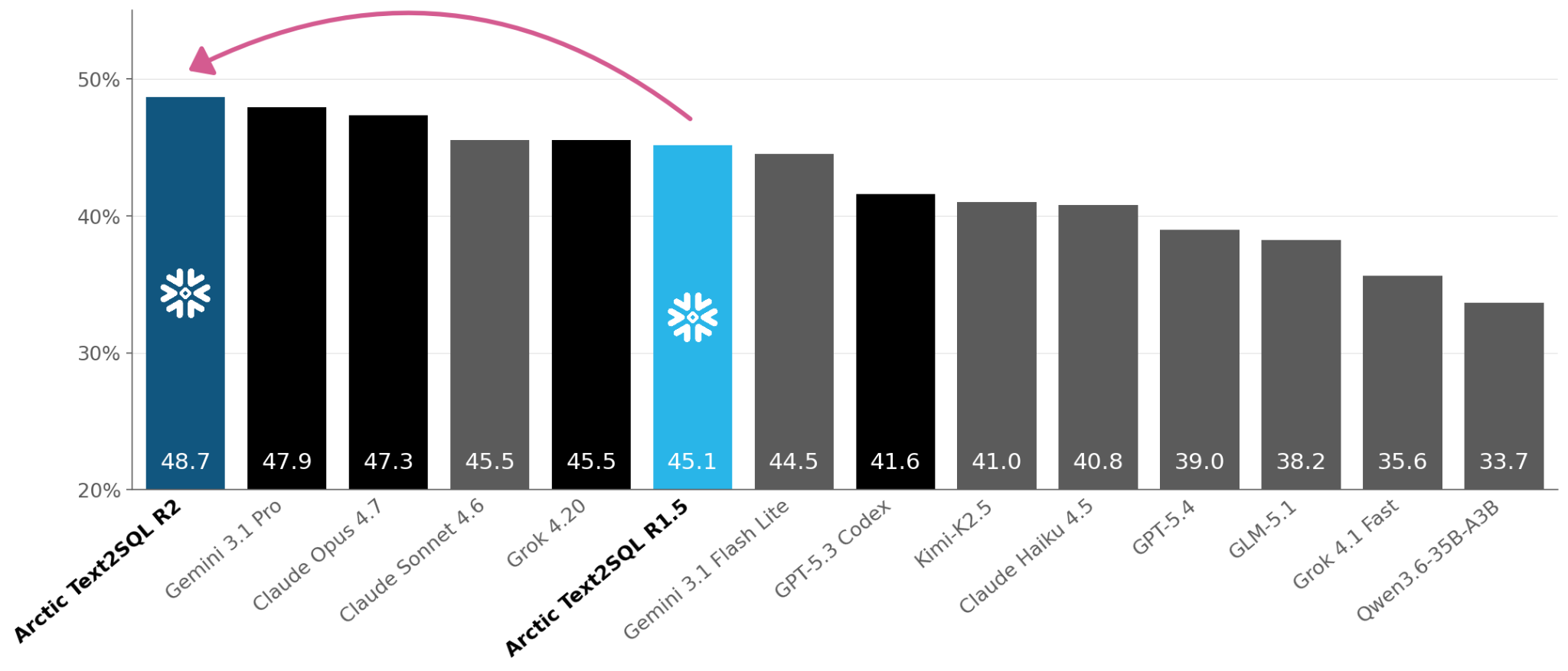
Figure 5: Accuracy on the Snowflake Text-to-SQL HARD benchmark, a deliberately difficult eval data set where even the strongest frontier models (black bars) struggle.
ZoRRo's efficiency gains directly enabled Arctic-Text2SQL-R2 to achieve breakthrough performance on enterprise SQL generation. By eliminating prompt redundancy, ZoRRo delivered dual benefits: 3.5x faster training by removing redundant computation and the ability to scale to 3.2x longer context (20K→64K) by removing redundant activations — configurations that were out of reach with standard RL systems due to GPU memory constraints. The speed improvement compressed training cycles from five days to under 36 hours, allowing us to rapidly iterate on reward formulations, explore architectural variations and refine our training recipe in ways that would have been prohibitively expensive. Simultaneously, longer contexts allowed the model to process complete database schemas alongside complex user queries without truncation. These combined improvements — faster iteration and larger scale — were essential to achieving the final model quality.
Arctic-Text2SQL-R2 outperforms frontier models like Gemini 3.1 Pro and Claude 4.7 on Snowflake's enterprise SQL benchmark despite being significantly smaller. The model masters complex Snowflake idioms and rare window functions that general-purpose frontier models consistently miss. This accuracy stems from three modeling innovations:
- Snowflake-first training recipe: We moved beyond generic synthetic data and labeled question-SQL pairs by shifting the center of gravity toward Snowflake-specific mid-training on a large curated corpus of Snowflake DDL, documentation, analytical scripts, stored procedures and real practitioner SQL. Coupled with a regrounding pipeline that detaches analytical questions from specific schemas, this gives the model a Snowflake-native foundation while helping it generalize across hundreds of thousands of unique database contexts.
- Collision-resistant execution rewards: Traditional execution-match rewards suffer from "near-misses," where incorrect SQL accidentally returns the correct result on simple datasets. We inject edge-case rows and tighten equivalence checks to ensure the model is only rewarded for genuinely correct logic.
- Rapid iteration and long-context RL enabled by ZoRRo: The 3.5x speedup in RL training time, combined with the ability to train on larger batches and longer contexts, allowed us to explore sophisticated training strategies that standard systems could not afford.
For full details on the modeling recipe, data pipeline and reward formulation, see our sister blog post on Arctic-Text2SQL-R2.
What's next: Making ZoRRo accessible
The ZoRRo optimizations span the entire RL training stack — from prompt deduplication during batching, split attention in the training loop, to Forest Cascade Attention in the inference engine, to model-level changes for speculative decoding. This breadth makes it challenging to adopt ZoRRo in existing RL frameworks without significant engineering effort.
We are addressing this problem in the coming weeks by open sourcing Arctic RL, an RL backend that incorporates all of the ZoRRo optimizations discussed in this blog. Arctic RL is designed for easy integration into existing RL frameworks through a server-client architecture, allowing teams to unlock ZoRRo's speedups with minimal code changes. We will release Arctic RL alongside examples and guidance to help teams get started.
Contributors
Systems: Samyam Rajbhandari, Ye Wang, Michael Wyatt, Stas Bekman, Reza Yazdani, Jaeseong Lee, Mert Hidayetoglu, Tunji Ruwase, Karthik Ganesan, Jeff Rasley, Yuxiong He
Modeling: Zhewei Yao, Xiaodong Yu, Lukasz Borchmann, Krzysztof Jankowski, Yite Wang, Gaurav Nuti
1 During each step, we compute log prob for the ref Qwen 3 32B model, forward-backward for the actor Qwen 3 32B model, and generation using the actor model. The average prompt length is 10.1K and average response length is 800 tokens.
For baseline we used vanilla VeRL. The ZoRRo optimized version leverages all optimizations discussed in this blog on top of Vanilla VeRL.
The TFlops are computed by converting the per step tokens/sec per GPU that VeRL reports into TFlops using the aforementioned information on model size, average prompt length and response lengths.
To demonstrate perceived throughput, both baseline and ZoRRo optimized version TFlop numbers are computed using the same number of processed tokens in the baseline that includes prompt redundancy.
2 While writing this blog, we observed that similar prompt deduplication ideas were independently explored by PrefixGrouper in some capacity. We see this as validation of the core insight: prompt-level redundancy is a fundamental inefficiency in RL workloads, and removing it yields large, consistent gains.