DOKUMENTATION
Dokumentation
Die Dokumentation zu Snowpark Connect for Apache Spark™.
Funktion
Setzen Sie auf Snowpark Connect for Apache Spark™ – für maximale Performance und geringere Kosten ohne zusätzlichen Betriebsaufwand.

Ihre komplexen Spark-Workloads werden im Durchschnitt 5,1-mal schneller# ausgeführt als bei anderen Managed Spark-Anbietern – dank einer vektorisierten Engine, die speziell auf Skalierbarkeit ausgelegt ist.

Sparen Sie sich die Cluster-Bereitstellung und vermeiden Sie teure Datenverschiebungen – dank einer vollständig verwalteten Umgebung.

Entlasten Sie Ihr Team von der aufwendigen Bereitstellung und Optimierung von Spark-Clustern. Fokussieren Sie Ihre Engineering-Ressourcen lieber auf wertschöpfende Datenprodukte statt auf das Infrastrukturmanagement.
Vorteile
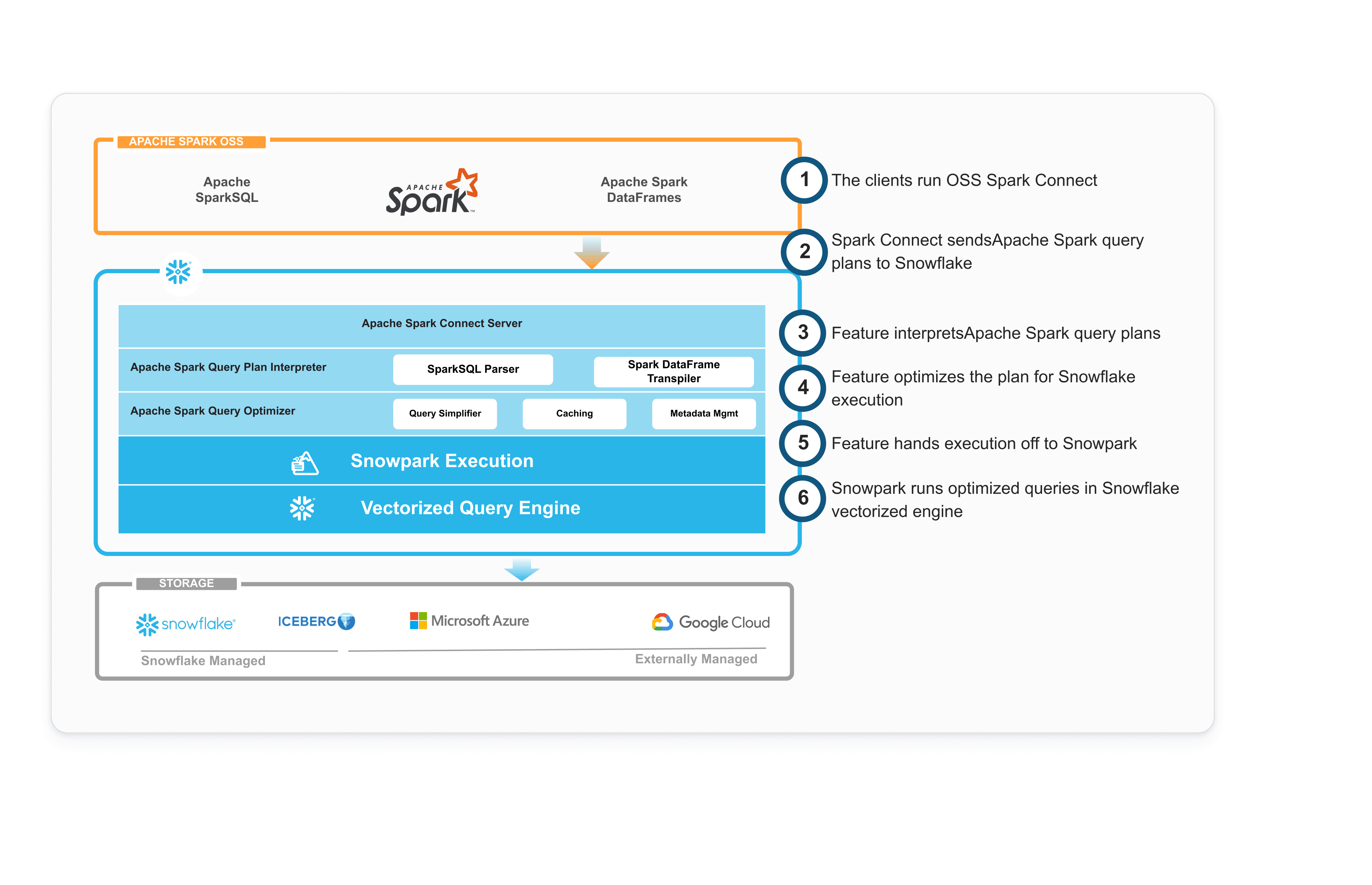
NATIVE AUSFÜHRUNG VON SPARK
Snowpark Connect nutzt das Open-Source-Protokoll Spark Connect, um Workloads nativ direkt in Snowflake zu verarbeiten. Dadurch erzielen Sie im Durchschnitt 42 % Kosteneinsparungen bei komplexen ETL-Aufgaben und eine 5,1-mal schnellere# Performance – ohne Ihren bestehenden Spark-Code ändern zu müssen.
ANBINDUNG BESTEHENDER WORKLOADS
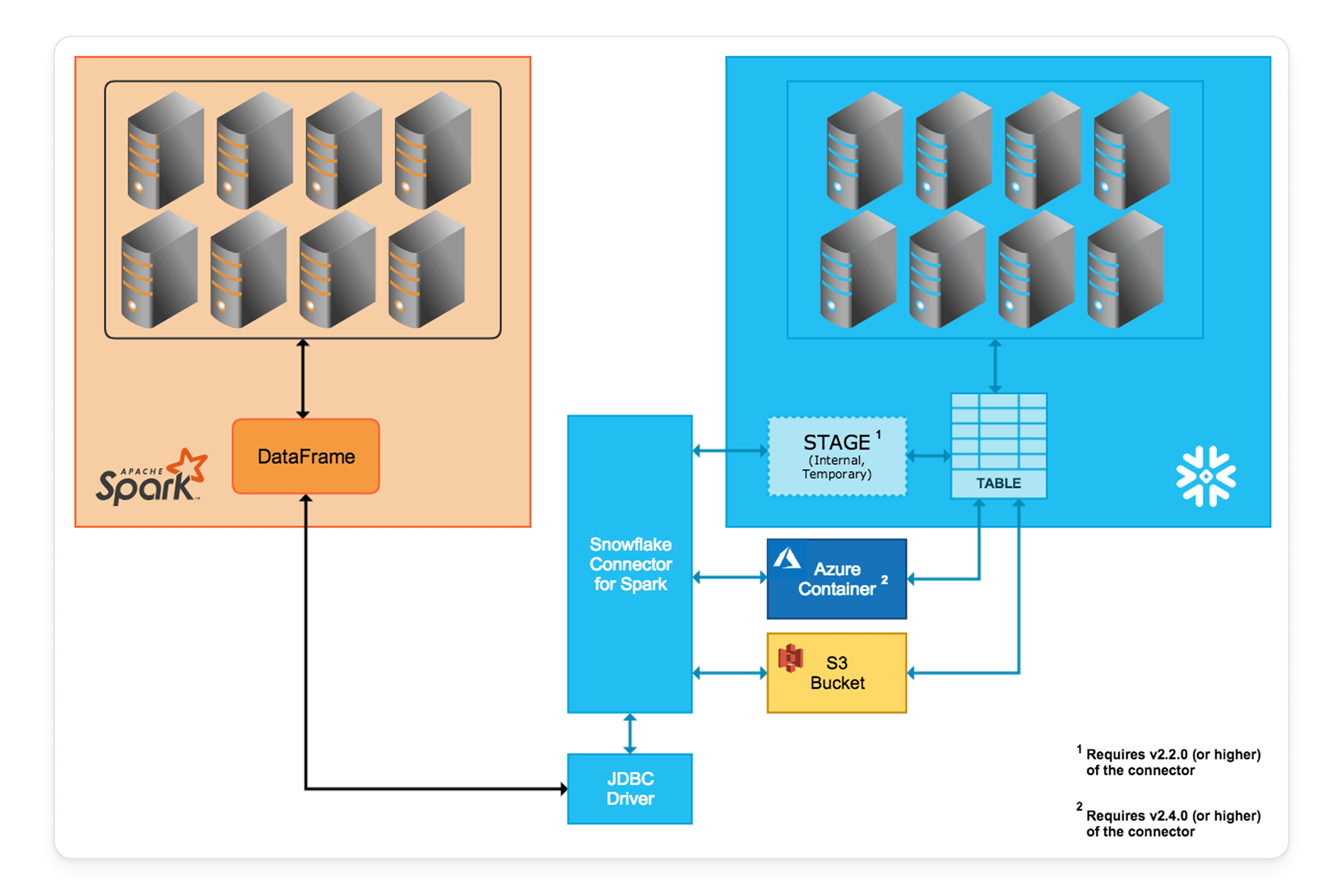
Wenn Ihre Workloads auf externe Spark-Umgebungen oder bestehende APIs (einschließlich RDDs und MLlib) angewiesen sind, bietet der Snowflake Connector for Spark eine leistungsstarke Brücke. Sämtliche Sicherheits- und Governance-Kontrollen von Snowflake greifen nahtlos auch bei dieser Datenübertragung.
NUTZUNG GEWOHNTER TOOLS
Verbinden Sie Ihren Spark-Client mit Ihren bevorzugten Umgebungen wie Jupyter Notebooks, VS Code und Apache Airflow™, um Spark-Jobs mühelos auszuführen.

IN-PLACE-DATENVERARBEITUNG
Vermeiden Sie kostspielige Datenverschiebungen und teure Egress-Gebühren.
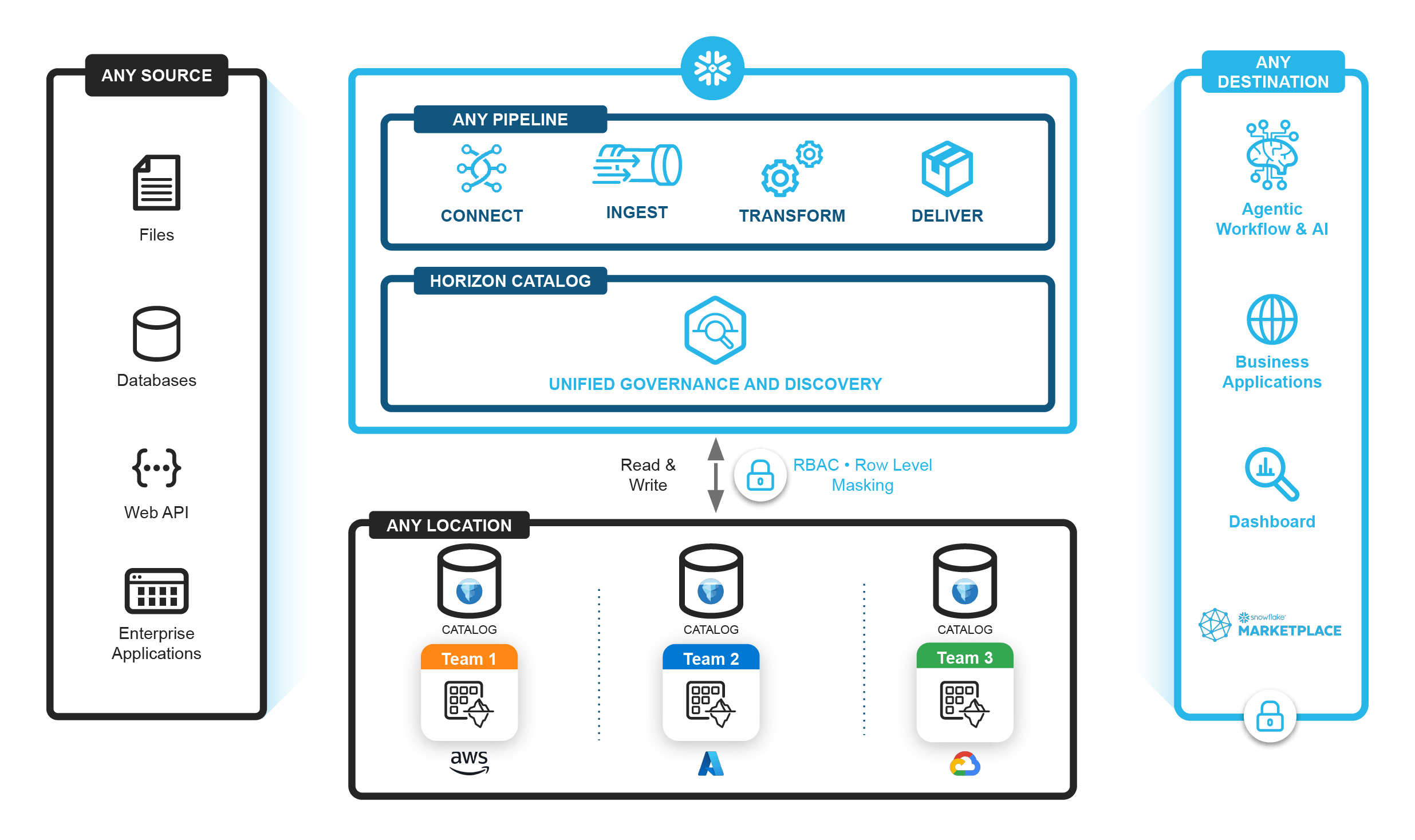
Wenden Sie einheitliche Governance-Kontrollen ein einziges Mal auf Ihren gesamten Datenlebenszyklus an.
„Der Wechsel vom bisherigen Snowflake-Konnektor zu Snowpark Connect hat beeindruckende Ergebnisse geliefert: Unsere Laufzeit sank von 1,5 Stunden auf gerade einmal rund 25 Minuten.“
Dimitar Nedev
Principal Data Engineer, AI & Insights Platform













SNOWPARK CONNECT FOR APACHE SPARK
Hier finden Sie Antworten auf häufig gestellte Fragen zu Snowpark Connect for Apache Spark und erfahren, wie Sie Ihre Spark-Workloads auf Snowflake ausführen.
Mit Snowpark Connect können Sie Spark-Clients (wie PySpark) verwenden, um eine Verbindung mit Snowflake herzustellen und modernen Apache Spark DataFrame-, Spark SQL- und UDF-Code direkt mit der Snowflake-Engine auszuführen. Dadurch reduziert sich der Betriebsaufwand für separate Spark-Umgebungen deutlich.
Snowpark Connect ist eine vollständig verwaltete Compute-Lösung, die alle Operationen innerhalb der Snowflake-Engine per Query-Pushdown ausführt. Dadurch entfallen die Bereitstellung separater Spark-Cluster, teure Datenverschiebungen sowie die damit verbundenen Egress-/Ingress-Kosten. Spark Connector erfordert dagegen ein separates Spark-Cluster, bringt Datenübertragungen mit sich und unterstützt Pushdowns nur für eine Teilmenge der Spark-SQL-Operationen.
Snowpark Connect kann gängige Dateiformate wie CSV, JSON und Parquet lesen und schreiben. Die Lösung unterstützt Daten direkt in nativen Snowflake-Tabellen sowie in einem Open Lakehouse über von Snowflake verwaltete oder extern verwaltete Apache Iceberg™-Tabellen.
Snowpark Connect basiert auf dem Open-Source-Protokoll Spark Connect, das den Client von der Execution-Engine trennt. Die Lösung nutzt einen schlanken Spark Connect-Server, um den logischen Spark-Plan zu analysieren, und führt anschließend einen Pushdown des gesamten Workloads auf die vektorisierte Snowflake-Engine zur Ausführung durch. Sie müssen also keinen eigenen Spark-Cluster betreiben – die gesamte Verarbeitung erfolgt direkt in Snowflake.
Der Großteil des Codes für DataFrame-Operationen funktioniert direkt, indem die Session einfach auf Snowflake umgestellt wird. Mit dem Snowpark Migration Accelerator (SMA) können Sie zudem die Kompatibilität von Codebasen jeder Größenordnung analysieren.
Kunden, die ihre Spark-Workloads auf Snowflake migrieren, erzielen im Durchschnitt eine 5,1-mal schnellere Performance und 42 % Kosteneinsparungen.