ドキュメント
ドキュメント
Apache Spark™用Snowpark Connect の機能のドキュメントをご覧ください。
機能
Apache Spark™用Snowpark Connectを使用して、運用のオーバーヘッドなしに、より高速なパフォーマンスとコストの削減を両立できます。

スケール専用に設計されたベクトル化エンジンにより、複雑なSparkワークロードをマネージドSparkプロバイダーと比較して5.1倍# 高速に実行できます。

フルマネージド環境により、クラスターのプロビジョニングをスキップしてデータ移動コストを回避できます。

お客様は、Sparkクラスターのプロビジョニングとチューニングに伴う負担から解放されます。インフラストラクチャ管理に追われるのではなく、高付加価値なデータプロダクトの構築にエンジニアリングリソースを集中できます。
メリット
Sparkをネイティブに実行
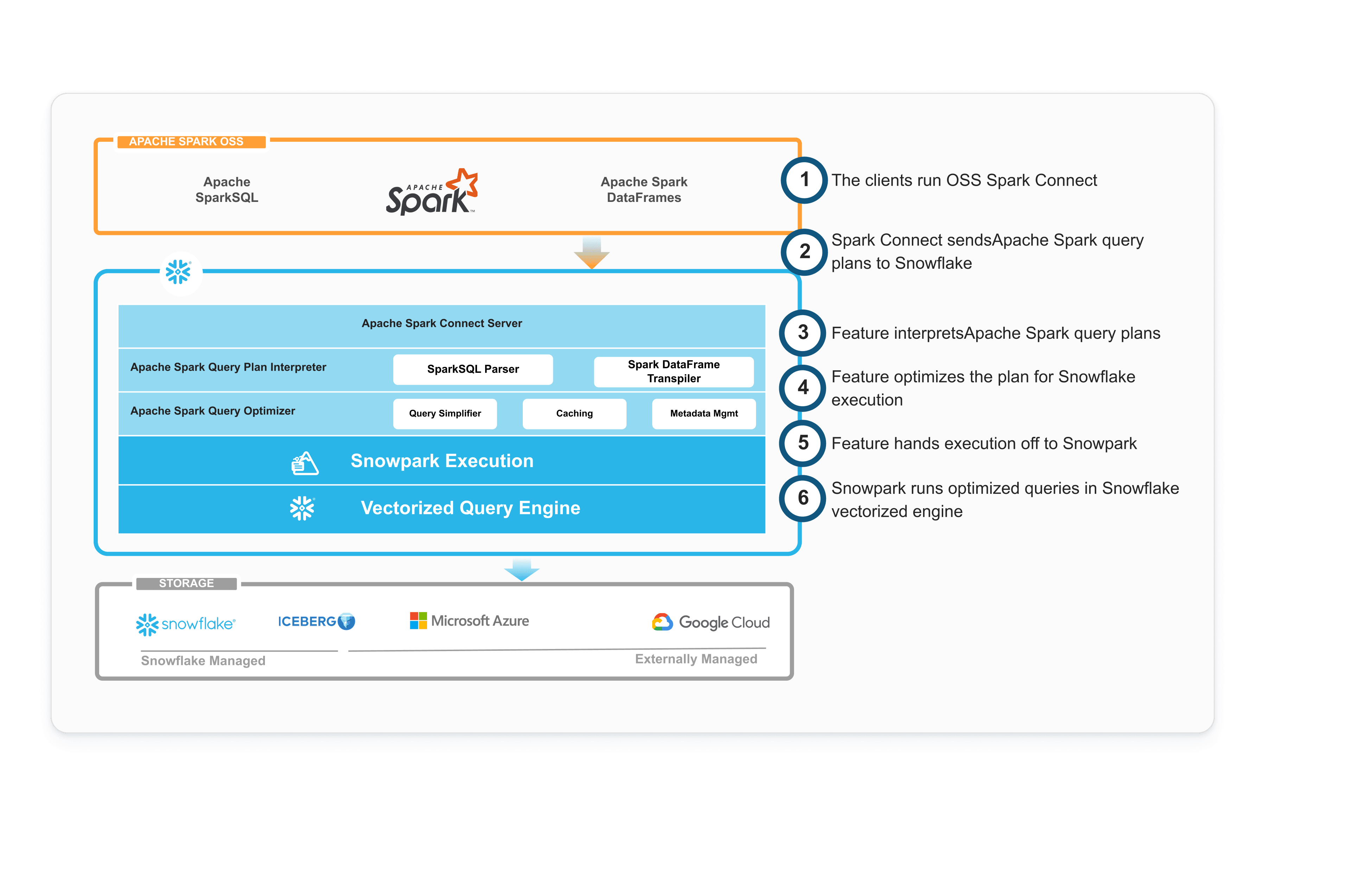
Snowpark Connectは、オープンソースのSpark Connectプロトコルを使用して、Snowflake内でワークロードをネイティブに実行します。これにより、既存のSparkコードを維持しながら、複雑なETLタスクにおいて平均42%のコスト削減と5.1倍#高速なパフォーマンスを実現します。
既存のワークロードの連携
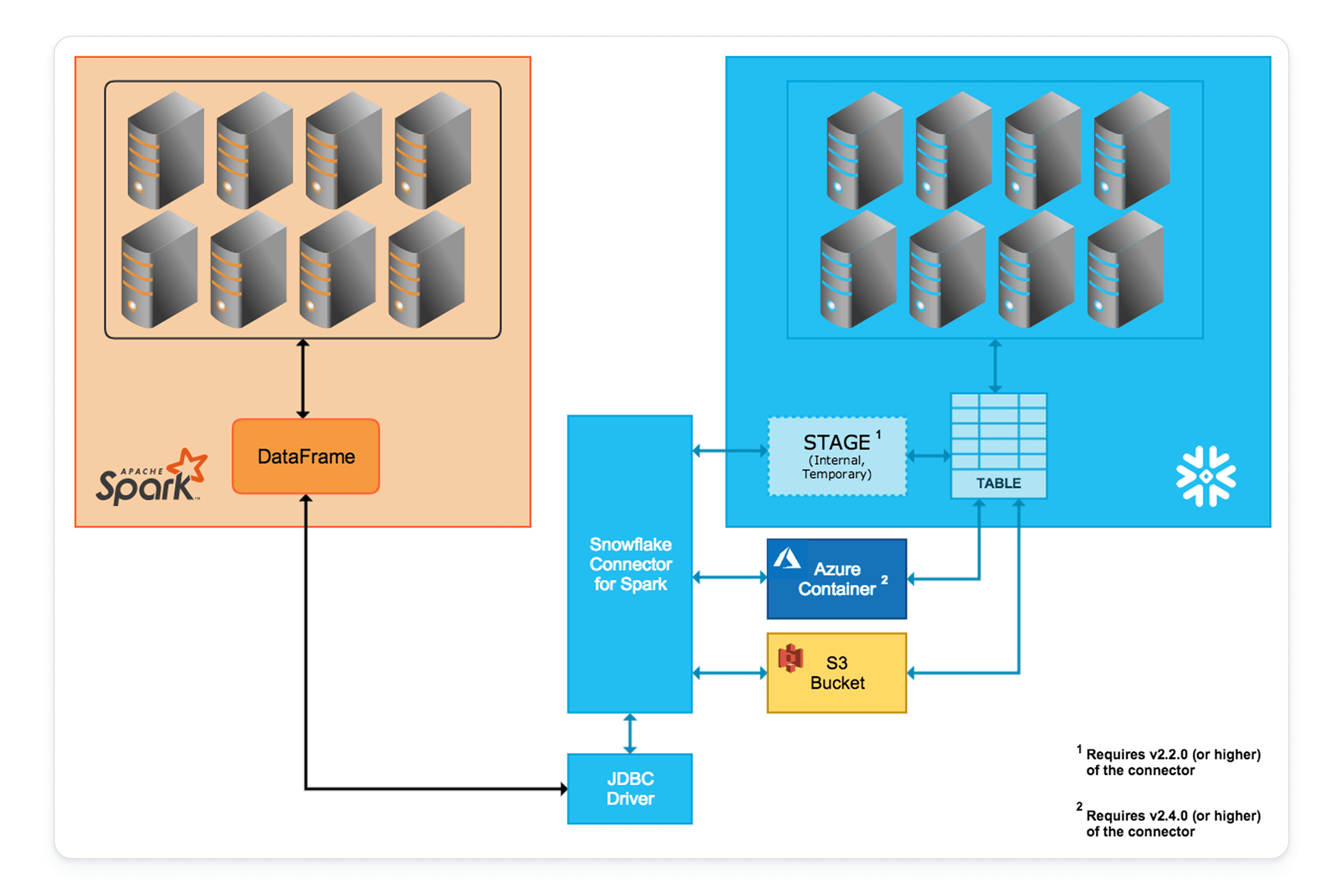
お客様のワークロードに外部のSpark環境や既存のAPI(RDDやMLlibなど)が必要な場合、Apache Spark用Snowpark Connectが高性能なブリッジを提供します。データ転送においても、Snowflakeのセキュリティとガバナンスの制御が引き続き適用されます。
既存ツールの活用
Jupyter Notebook、VS Code、Apache Airflow™などといったお好みの環境からお客様のSparkクライアントを接続し、Sparkジョブを実行できます。

データの場所を問わずSparkを実行
高コストなデータの移動やエグレス料金を回避できます。
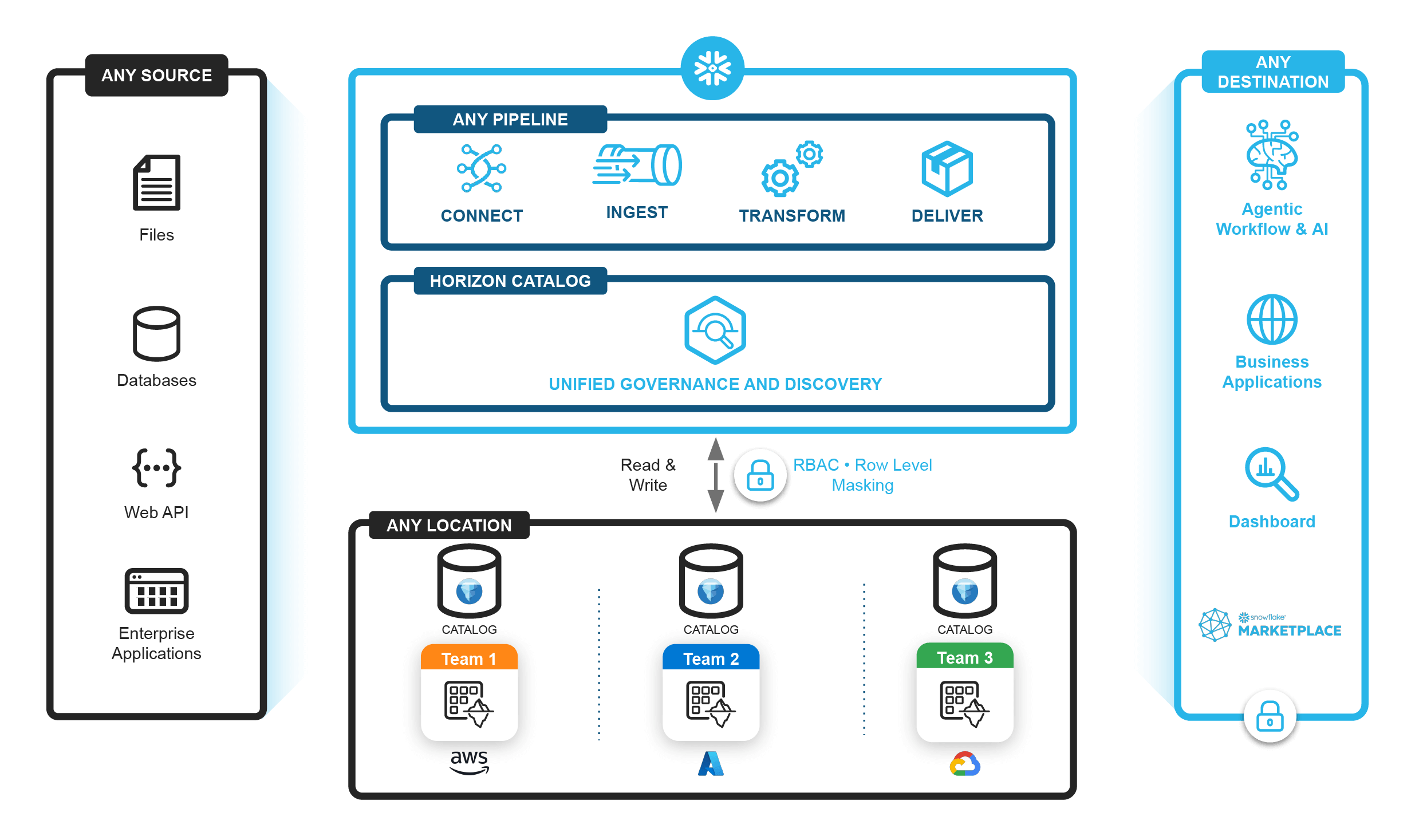
データライフサイクル全体にわたって、一度の設定で統一されたガバナンス制御を適用できます。
「従来のSnowflakeコネクタからSnowpark Connectへと切り替えたことで、極めて大きな成果が得られました。実行時間が1.5時間から約25分へと大幅に短縮されました」
—Dimitar Nedev氏
AI & インサイトプラットフォーム担当、プリンシパルデータエンジニア













Apache Spark用Snowpark Connect
Apache Spark用Snowpark Connectに関するよくある質問や、Snowflake上でSparkワークロードを実行する際にどのように役立つかについての回答をご確認ください。
Snowpark Connectを利用することで、PySparkなどのSparkクライアントを使用してSnowflakeに接続し、最新のApache Spark DataFrame、Spark SQL、UDFコードをSnowflakeエンジンで直接実行できます。これにより、個別のSpark環境を維持管理するオーバーヘッドが軽減されます。
Snowpark Connectは、クエリプッシュダウンを介してSnowflakeエンジン内ですべての操作を実行するマネージドコンピューティングサービスです。これにより、個別のSparkクラスターのプロビジョニングやデータの移動、それに伴うエグレスおよびイングレスコストが不要になります。一方、Sparkコネクタは個別のSparkクラスターを必要とし、データの転送が発生するだけでなく、プッシュダウンできるのはSpark SQL操作の一部に限定されます。
Snowpark ConnectはCSV、JSON、Parquetなどの一般的なファイル形式の読み書きが可能です。Snowflakeネイティブテーブル内のデータだけでなく、Snowflake管理および外部管理のApache Iceberg™テーブルを介したオープンレイクハウス内のデータもサポートしています。
Snowpark Connectは、クライアントと実行エンジンを分離するオープンソースのSpark Connectプロトコルを基盤として構築されています。Snowpark Connectは、軽量のSpark Connectサーバーを使用してSparkの論理計画を解析し、ワークロード全体をSnowflakeベクトル化エンジンにプッシュダウンして実行します。これにより、ユーザーがSparkクラスターを運用する必要はなくなり、すべてのコンピュートがSnowflake内で行われるようになります。
DataFrame操作を中心としたほとんどのコードは、セッションの接続先をSnowflakeに変更するだけで動作するはずです。どのような規模のコードベースであっても、Snowpark移行アクセラレーター(SMA)を使用して互換性の詳細を確認できます。
SparkワークロードをSnowflakeに移行したお客様は、平均で5.1倍のパフォーマンス高速化と42%のコスト削減を実現しています。