

Updates have been made since the original publishing of this blog post. For the latest information about Snowflake’s support for Apache Iceberg, please see here.
Apache Iceberg continues to grow in popularity as the industry standard for open table formats. Because of its leading ecosystem of diverse adopters, contributors and commercial offerings, Iceberg helps prevent storage lock-in and eliminates the need to move or copy tables between different systems, which often translates to lower compute and storage costs for your overall data stack.
With your invaluable feedback, we have made significant progress in improving our Iceberg offering, now available in private preview. With this release comes performance improvements, new concepts, new features and changes to how Snowflake can fit into an architecture with Iceberg:
- Unifying Iceberg Tables: Instead of two separate table types for Iceberg, we are combining Iceberg External Tables and Native Iceberg Tables into one table type with a similar user experience. You can easily configure your Iceberg catalog to match the capabilities you need.
- Improved performance: Iceberg Tables managed by Snowflake now offer similar performance to ingested Snowflake-format tables, and Iceberg Tables managed by an external catalog perform over 2x better than Iceberg External Tables.
- Catalog Integration: Our newly developed Catalog Integration feature allows you to seamlessly plug Snowflake into other Iceberg catalogs tracking table metadata.
In this blog post, we’ll dive into the details of these features and the benefits for customers.
Recapping our journey with Iceberg
Last year we announced two Iceberg Table previews based on functionality already available in Snowflake. Since 2021, Snowflake has had External Tables for the purpose of read-only querying external data lakes. In 2022, We announced added support for Iceberg for External Tables to easily read Iceberg datasets. In addition to Iceberg External Tables, we introduced Native Iceberg Tables. Like Snowflake-format tables, Native Iceberg Tables were designed for use cases that require read and write operations while storing Parquet and Iceberg metadata files in customer-supplied storage.
Unifying Iceberg Tables
In the past year, we’ve had a lot of great feedback from customers testing our previews for Iceberg at scale. This feedback can be summarized into three themes:
- Onboarding: Whether a customer is currently using a table format like Hive or no table format at all, they want an easy, frictionless way to create Iceberg Tables.
- Performance: Simply put, regardless of which engine is writing the data, customers want equally fast performance across the board.
- Catalogs: Since they typically already have one or more catalogs, customers want Snowflake to easily integrate with each of those catalogs.
We’ve taken all of this feedback and revised our approach with Iceberg, which we announced at Summit 2023, and have now updated our private previews. We’ve converged Native and External Tables for Iceberg into a single table type with a single user syntax. For metadata management, you can configure Snowflake to manage your Iceberg data or use an external Iceberg catalog. This convergence comes with far less performance trade-offs, and both modes store all Parquet data and Iceberg metadata files externally in customer-supplied object storage. We’ve added an easy way to integrate Snowflake with an external Iceberg catalog starting with AWS Glue Catalog. Also, we're adding a simple, low-cost way to convert an Iceberg Table’s catalog from external to Snowflake, making it easy for customers to onboard without having to rewrite entire tables.
How Iceberg Tables work
With Iceberg Tables, Snowflake can serve as the table catalog for managing metadata. In this mode, Snowflake can read and write Iceberg and Parquet data to your storage account, and Snowflake takes care of storage maintenance operations like compaction, expiring snapshots, and deleting orphan files. Iceberg Tables in this mode can either be created from scratch using methods such as CTAS or CREATE TABLE, or they can be created by converting an Iceberg Table previously created using an external catalog, without any underlying data rewrite or ingestion cost. As described in the Iceberg Catalog SDK announcement, you can connect to the Snowflake Iceberg catalog via Apache Spark without requiring any Snowflake compute resources.
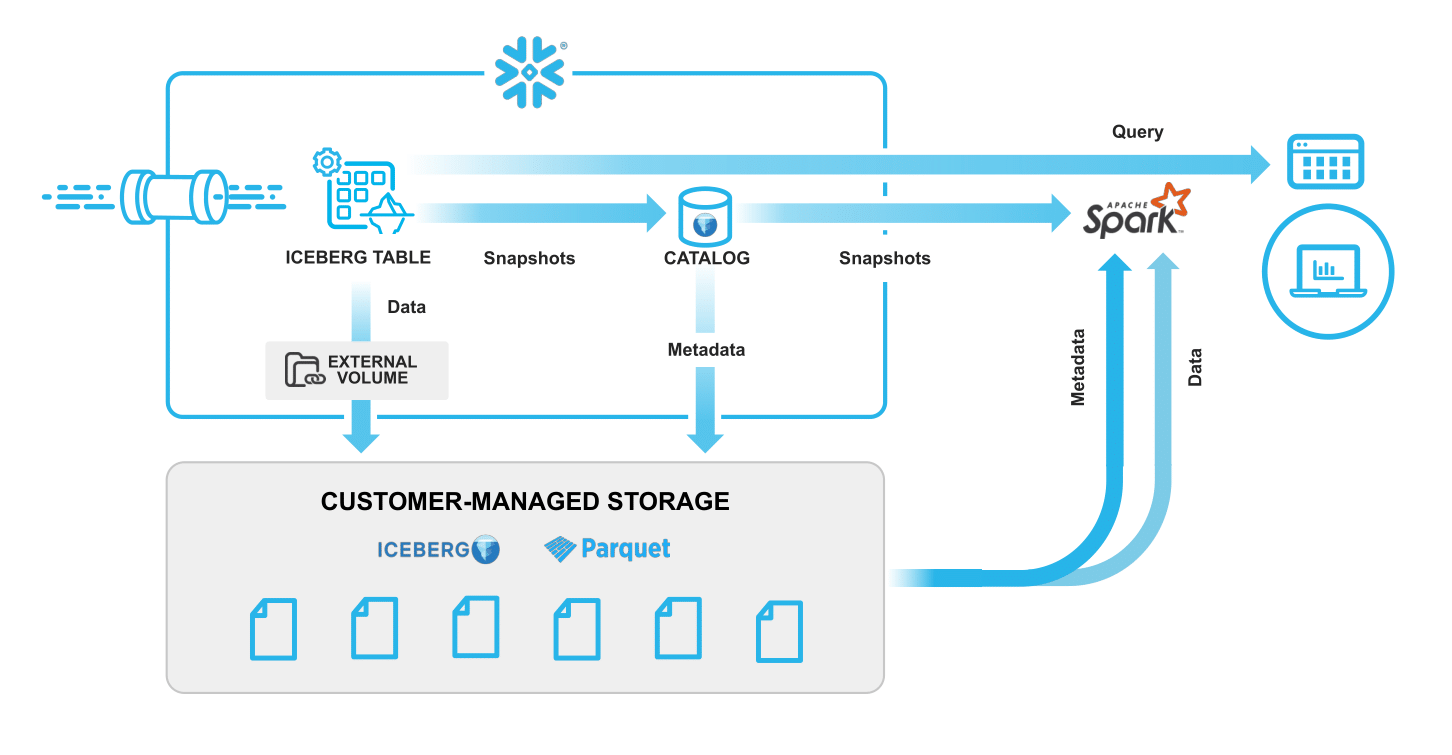
Iceberg Tables can also be easily integrated with external catalogs to very quickly and easily query Iceberg data sets from Snowflake. With an external catalog, Snowflake has read-only access to Iceberg data sets in your storage account, and your catalog manages storage maintenance—or you can, manually. With this preview, you can either point Snowflake to a metadata file location or create a simple Catalog Integration with AWS Glue Catalog. A Catalog Integration is a new type of object in Snowflake that greatly simplifies metadata refresh in comparison to the previous Iceberg offering with External Tables.
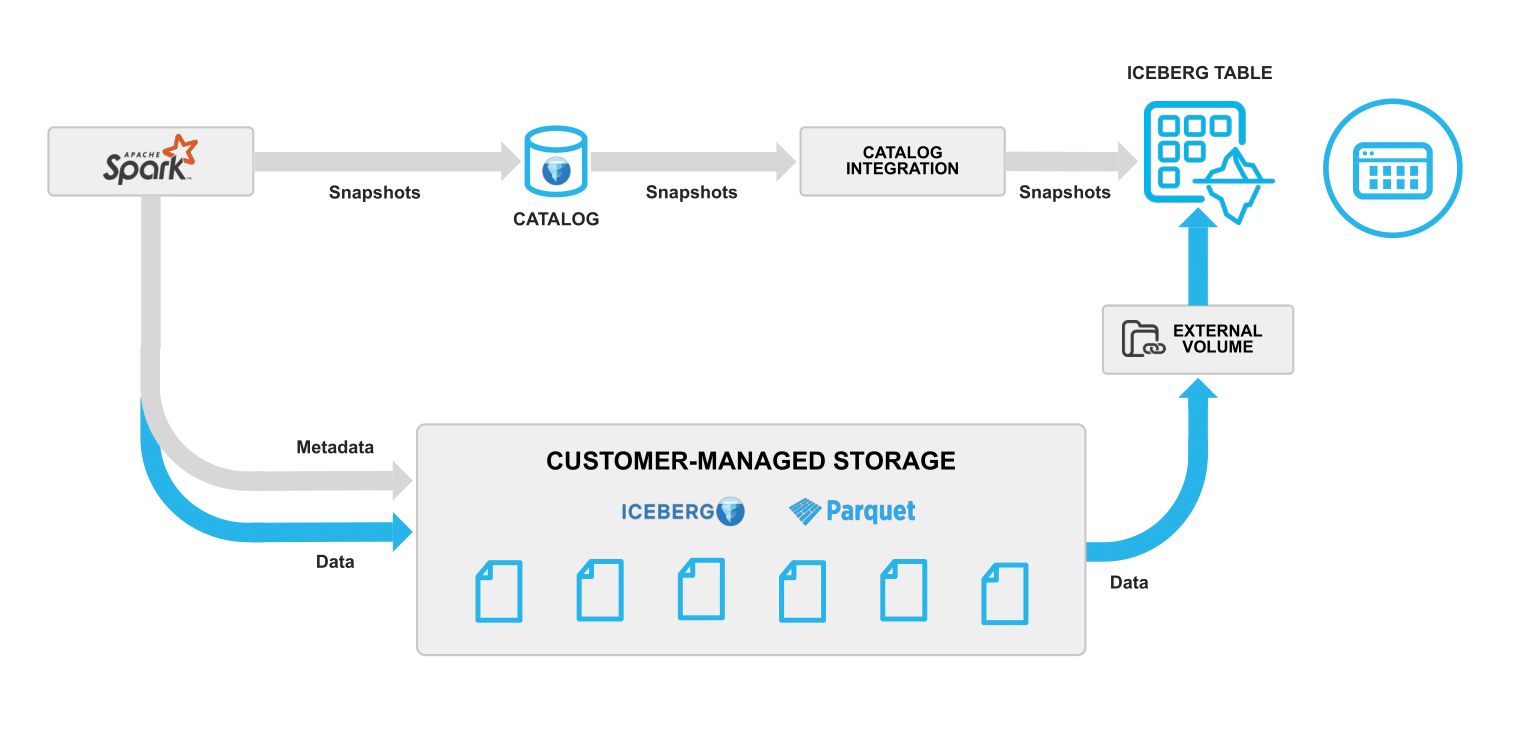
Acting on the feedback for easier onboarding, we're adding an ALTER TABLE command that makes it simple to convert an externally managed Iceberg Table to a Snowflake-managed one. Without rewriting or reformatting any files in your storage bucket associated with your Iceberg Table, catalog ownership changes from your external catalog to Snowflake. And once converted, you can immediately begin benefiting from Snowflake’s automated storage management. Over time, as Snowflake’s engine performs more write operations on the table such as INSERT, UPDATE, DELETE and MERGE, performance will continue to improve.
Better performance
External Tables come with an external scanner that works with various file sizes and formats including CSV, AVRO, ORC and Parquet. But, that flexibility comes with some sacrifices in performance. When building Native Iceberg Tables before, we developed a highly optimized Parquet scanner, which we’re now using for Iceberg Tables with both Snowflake-managed and externally managed catalogs. This scanner uses full statistics from Parquet and Iceberg, which explains the 2x performance improvement from External Tables to Iceberg Tables integrated with an external catalog. In addition to leveraging the optimized Parquet scanner, all Iceberg Table data is cached locally on the warehouse. This caching provides a boost to concurrent workloads, which isn’t available with External Tables.
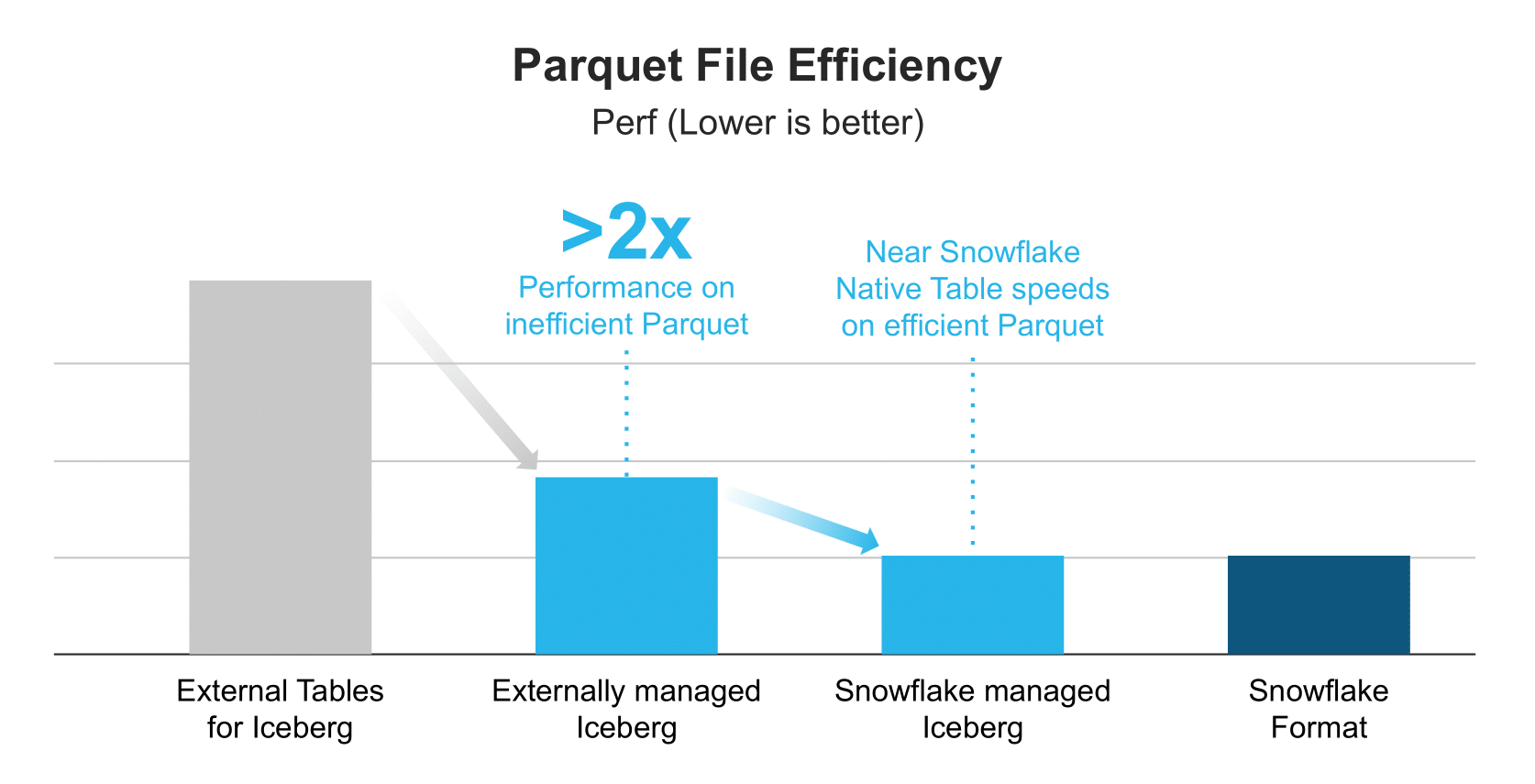
Why is there still a gap between externally managed and Snowflake-managed catalogs for Iceberg Tables? Snowflake’s performance on Iceberg Tables is primarily dependent on how efficiently the Parquet files are written. So if another engine writes to the table, generates Parquet files, but doesn’t write full statistics, this will negatively impact performance with Snowflake.
See it in action
In case you missed it, check out this demo on using Iceberg with Snowflake and AWS services, including Amazon S3, Amazon Athena and AWS Glue Catalog.
Have a Snowflake account and want to try this out? Reach out to your Snowflake account manager to enroll.
Forward-Looking Statements
This post contains express and implied forward-looking statements, including statements regarding (i) Snowflake’s business strategy, (ii) Snowflake’s products, services, and technology offerings, including those that are under development or not generally available, (iii) market growth, trends, and competitive considerations, and (iv) the integration, interoperability, and availability of Snowflake’s products with and on third-party platforms. These forward-looking statements are subject to a number of risks, uncertainties and assumptions, including those described under the heading “Risk Factors” and elsewhere in the Quarterly Reports on Form 10-Q and Annual Reports of Form 10-K that Snowflake files with the Securities and Exchange Commission. In light of these risks, uncertainties, and assumptions, actual results could differ materially and adversely from those anticipated or implied in the forward-looking statements. As a result, you should not rely on any forward-looking statements as predictions of future events.
© 2023 Snowflake Inc. All rights reserved. Snowflake, the Snowflake logo, and all other Snowflake product, feature and service names mentioned herein are registered trademarks or trademarks of Snowflake Inc. in the United States and other countries. All other brand names or logos mentioned or used herein are for identification purposes only and may be the trademarks of their respective holder(s). Snowflake may not be associated with, or be sponsored or endorsed by, any such holder(s).
