The Metadata Hub: One Control Plane for Your Entire Data Estate


For years, the promise of a cohesive data platform has bumped into the same hard reality: Data lives everywhere. There is data in Snowflake, in AWS Glue, in Microsoft OneLake, in Databricks Unity Catalog, in Apache Polaris™, in homegrown REST catalogs no one fully remembers building.... Every platform came with its own rules, its own metadata, its own gravity. And with each new system, the distance between a common platform and your data grew wider.
The answer isn't to move everything into one place. That ship has sailed. The answer is to connect everything through one layer: a Metadata Hub.
The problem with "just pick one platform"
The conventional wisdom used to be consolidation. Pick a cloud. Pick a catalog. Migrate data and call it done. But the data landscape has moved beyond that vision. Migrating data is counterproductive to AI context. Acquisitions bring new platforms. Teams build on the tools they know. Regulatory requirements demand geographic separation. Multi-catalog/multi-cloud isn't a "mistake." It's the reality that most enterprises live in.
That means metadata fragmentation at a very broad scale. You might know what data you have in Snowflake. But do you know what's in your Glue catalog? Your Unity workspace? Your OneLake instance? Can you query across all of them without copying data? Can you govern them from a single policy? Can you see, in real time, everything your data estate contains?
For most organizations, the honest answer is no. This is why Snowflake is focusing on interoperability as a Metadata Hub.
What a Metadata Hub actually is
A Metadata Hub isn't another catalog competing for dominance. A Metadata Hub aggregates and federates metadata across your entire data estate into a single, queryable interface. Rather than forcing data migration, it brings the understanding of that data together, giving every user a unified window into structure, semantics, lineage, quality and ownership no matter which system holds the data.
Snowflake Horizon Catalog is the connective layer, a single plane of visibility and control that sits above your existing catalogs and makes them more useful.
Learn more about Metadata Management.
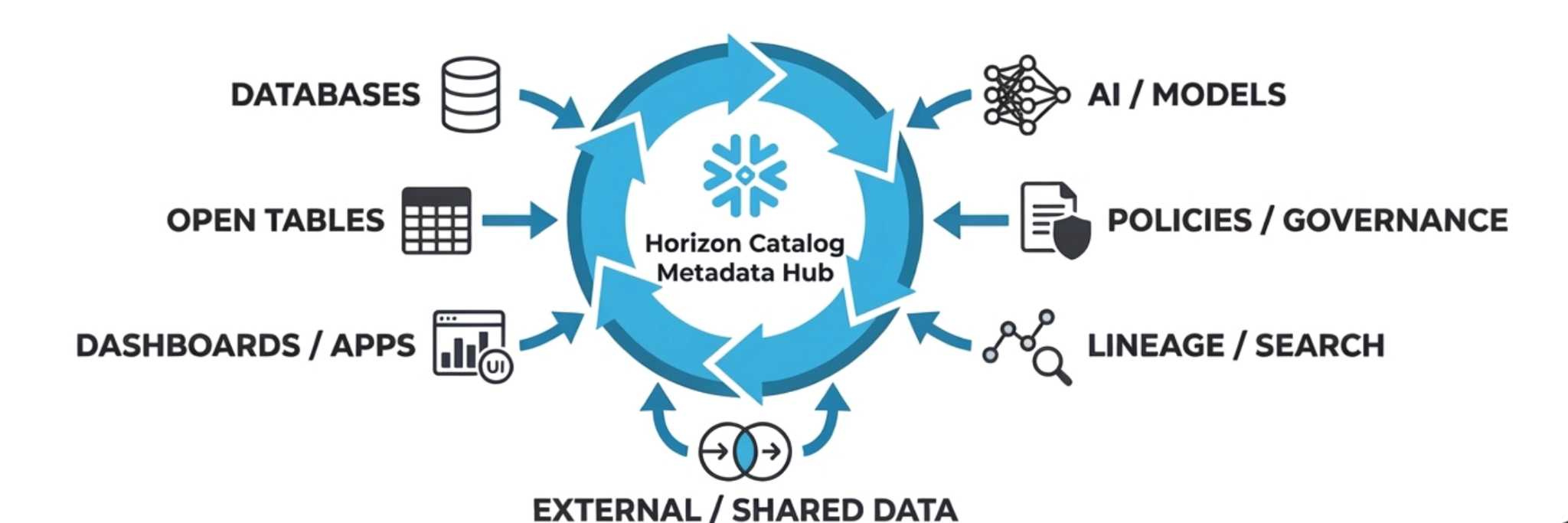
A Metadata Hub rests on three foundational ideas:
1. Open by design
The Apache Iceberg™ ecosystem has established something rare in the data world: a genuine open standard. Iceberg's table format and the Iceberg REST Catalog (IRC) specification create a shared protocol that any system can participate in. Snowflake, AWS, Databricks and the broader industry have all rallied around it. We publish and consume Iceberg REST Catalog (IRC) through the embedded Apache Polaris instance in every Horizon Catalog. It's seamless, fully integrated and requires no additional configuration to unlock these interoperability capabilities.
Iceberg and the IRC specification establish an open protocol the industry can build on. AWS, Databricks and many others have aligned around that standard. We went further by investing in Apache Polaris™, now a Top-Level Project, to help advance what an open catalog should be. By embedding Polaris in every Horizon Catalog, we give you a genuinely open catalog foundation for your lakehouse.
Interoperability isn't a differentiator; it's the baseline. Any system that speaks Iceberg can exchange data, share metadata and participate in a broader data estate without custom connectors, proprietary bridges or vendor gatekeeping. No silos.
2. Native and bidirectional
Read-only access is a workaround. Native participation? That's the collaborative architecture and the one you want.
Snowflake's IRC integration goes further. When Horizon Catalog connects to a supporting catalog, such as AWS Glue, Databricks Unity Catalog1, Polaris or any other supporting platform, it connects natively and bidirectionally. You're not querying a copy or a reflection. You're reading and writing data directly, in its native format, with full fidelity. AWS Glue or Databricks Unity sees every change Snowflake makes. Snowflake can immediately query data that any other platform is writing natively. Catalog entries are live, and you have the option of configuring the synchronization interval (typically we recommend 30 seconds). Consider this example for bringing in a Unity Catalog over IRC:
CREATE DATABASE my_unity_linked_db
LINKED_CATALOG = (
CATALOG = 'my_unity_catalog_int',
SYNC_INTERVAL_SECONDS = 30-- controls namespace/table discovery polling
)
CATALOG_CASE_SENSITIVITY = CASE_INSENSITIVE;This allows you the ability to both read and write to a Unity Catalog source. True cross platform participation. Not just access.
3. Complete visibility
The third pillar turns connectivity into control. Using Horizon Catalog as your Metadata Hub gives you a single, real-time inventory of your entire data estate. Every table, every database, every catalog, on every platform, everywhere your data lives.
Complete visibility isn't a nice-to-have. It's the prerequisite for everything else. This matters for more than just basic discovery. You can enrich the metadata you're connected to with semantic definitions and incorporate business logic directly into the metadata layer. This layer is the foundation for governance. You can't apply a policy to data you can't see. You can't track lineage across a boundary you can't observe. You can't optimize costs on workloads you can't measure.
This is already happening. Forward-thinking organizations are building on it today. Production teams run workloads across multiple catalogs simultaneously, Snowflake to AWS Glue, Databricks Unity Catalog, Apache Polaris and others into a coherent operating model. This isn't experimentation; it's their architecture.
Organizations across industries are not consolidating onto a single platform; instead, they are adopting an interoperable-first approach across multiple platforms. This federation relies on Iceberg as a common data language and a Metadata Hub to provide a unified view. The Snowflake Horizon Catalog is uniquely positioned to serve as this essential Metadata Hub.
What this unlocks
Cross-platform queries without copying data. Join an AWS Glue table with a Databricks Unity Catalog table and a Snowflake-managed table in a single query. No ETL. No replication lag. No duplicated storage cost.
This architecture reinforces no vendor lock-in.
When your metadata is consolidated, a set of capabilities becomes possible that fragmentation makes impossible.
Governance over the entire data estate is an absolute must. Apply access policies, data masking and classification rules from one place. You can define data quality rules and, with full lineage visibility, monitor quality across your entire data estate. When issues arise, you can trace root causes, understand upstream and downstream impacts and remediate directly with Snowflake Cortex AI, all unified by Horizon, regardless of how diverse your data sources are. Govern the estate, not just the platform.
AI that understands your entire estate. A Metadata Hub doesn't just serve human users. It serves AI. When Cortex AI has access to unified metadata across your entire data estate, it operates with the full context of your business: table relationships, semantic definitions, lineage, quality signals and access patterns. This means more accurate natural language queries, more relevant search results and AI agents that reason across catalogs rather than stay confined to a single silo. The richer and more connected your metadata, the smarter Cortex becomes. Fragmentation starves AI of context. A Metadata Hub feeds it everything it needs to deliver real value.
Real-time cost attribution. See exactly what workloads consume resources across every catalog integration, breaking down costs by platform, team or workload type. Optimize with full visibility.
Ecosystem without fragmentation. Let teams use the tools they're most productive with: Snowflake for conversational AI across a broad swath of tables and analytics including any table wherever it lives, AWS Glue for EMR and Databricks where applicable. The Metadata Hub holds it together and makes all your data actionable, agnostic of the platforms your teams choose.
The architecture that makes it possible
At its core, the Metadata Hub architecture has three layers.
The catalog layer is where your existing catalogs remain authoritative for their own metadata. You are not replacing anything. You don't need to migrate/move data to make it actionable.
The connectivity layer is where IRC integrations create live, bidirectional links between catalogs and compute engines. Snowflake's IRC integration is the reference implementation of this layer. Horizon doesn't stop there. We have a diverse set of connectors to external sources that also participate in the consolidated Metadata Hub.
The control layer is the interface for discovery, governance, lineage and observability that operates across all connected catalogs simultaneously.
The result is a system that's more capable than any single catalog, without the migration cost of replacing them.
The opportunity ahead
The data industry spent a decade building better silos. Faster lakes. Smarter warehouses. More capable catalogs. Each one was a genuine advance, and each one added to the fragmentation.
Using Snowflake Horizon Catalog as your Metadata Hub is the architecture that turns that fragmentation into an asset. Instead of fighting the multi-platform reality, we embrace it and build a layer of coherence on top that makes every platform more valuable than it would be alone.
The question now isn't whether this architecture is possible. It's whether your organization is ready to move to Snowflake Horizon Catalog as your Metadata Hub, and turn the fragmented metadata to a cohesive data estate, and what you'll be able to do once you do.
1 Databricks does not currently support bidirectional access. For further information, please refer to this blog post.
