Iceberg Tables: Catalog Support Now Available


Updates have been made since the original publishing of this blog post. For the latest information about Snowflake’s support for Apache Iceberg, please see here.
As announced at Snowflake Summit 2022, Iceberg Tables combines unique Snowflake capabilities with Apache Iceberg and Apache Parquet open source projects to support your architecture of choice. As part of the latest Iceberg release, we’ve added catalog support to the Iceberg project to ensure that engines outside of Snowflake can interoperate with Iceberg Tables.
What is a catalog? Why is it important?
A key benefit of open table formats, such as Apache Iceberg, is the ability to use multiple compute engines over a single copy of the data. What enables multiple, concurrent writers to run ACID transactions is a catalog. A catalog tracks tables and abstracts physical file paths in queries, making it easier to interact with tables. A catalog serves as an option to ensure all readers have the same view, and to make it cleaner to manage the underlying files. But even without the catalog, Iceberg Tables are still accessible if the user directly points at appropriate file locations.
Iceberg supports many catalog implementations: Hive, AWS Glue, Hadoop, Nessie, Dell ECS, any relational database via JDBC, REST, and now Snowflake. This new Snowflake catalog is ideal for accessing Iceberg Tables managed and written by Snowflake’s engine.
How does the Snowflake Catalog SDK work?
Native Iceberg Tables in Snowflake are currently in private preview, and with the Apache Iceberg 1.2.0 release, this Snowflake Iceberg Catalog SDK allows preview participants to more easily query Iceberg Tables managed in Snowflake from Apache Spark.
The Snowflake Catalog SDK allows you to bring your compute engine of choice to any Iceberg data that is authored and maintained by Snowflake. When using a compute engine external to Snowflake, Snowflake compute is not required to read the data. After making an initial connection to Snowflake via the Iceberg Catalog SDK, Spark can read Iceberg metadata and Parquet files directly from the customer-managed storage account. With this configuration, multiple engines can consistently read from a single copy of data.
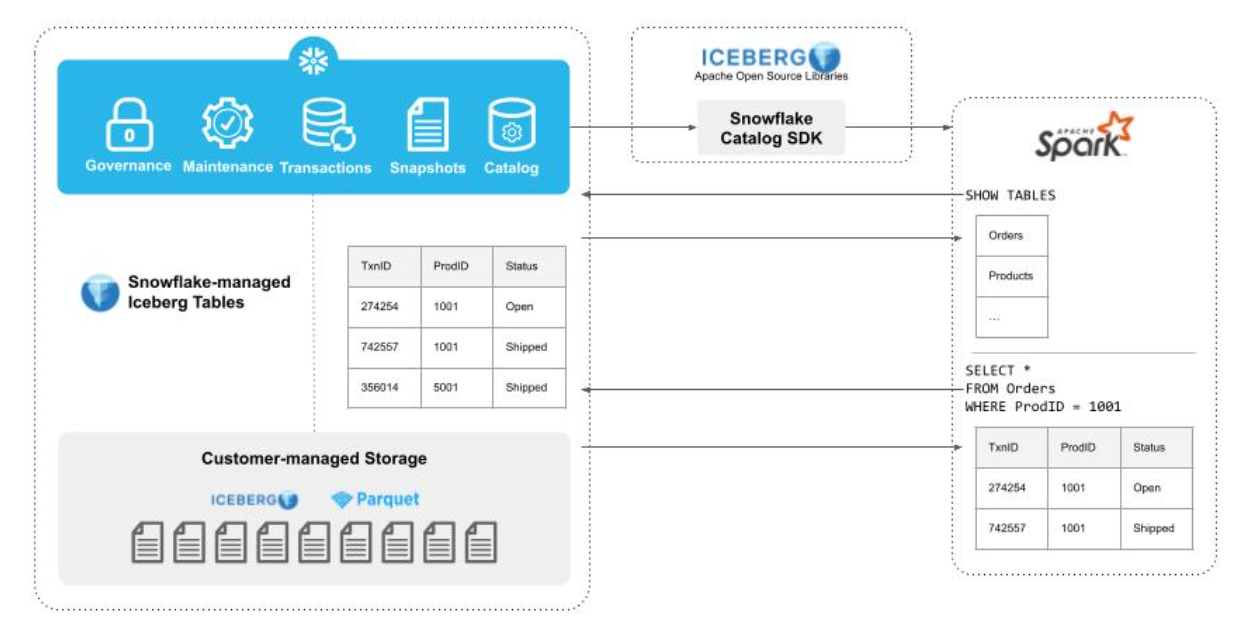
To use the Snowflake Catalog SDK, all you have to do is specify a few configurations to your Spark cluster.
spark-shell --packages org.apache.iceberg:iceberg-spark-runtime-3.3_2.13:1.2.0,net.snowflake:snowflake-jdbc:3.13.22
# Configure a catalog named "snowflake_catalog" using the standard Iceberg SparkCatalog adapter
--conf spark.sql.catalog.snowflake_catalog=org.apache.iceberg.spark.SparkCatalog
# Specify the implementation of the named catalog to be Snowflake's Catalog implementation
--conf spark.sql.catalog.snowflake_catalog.catalog-impl=org.apache.iceberg.snowflake.SnowflakeCatalog
# Provide a Snowflake JDBC URI with which the Snowflake Catalog will perform low-level communication with Snowflake services
--conf spark.sql.catalog.snowflake_catalog.uri='jdbc:snowflake://<account_identifier>.snowflakecomputing.com'
# Configure the Snowflake user on whose behalf to perform Iceberg metadata lookups
--conf spark.sql.catalog.snowflake_catalog.jdbc.user=<user_name>
--conf spark.sql.catalog.snowflake_catalog.jdbc.password='<password>'
# Configure the credentials to use when connecting to Snowflake services; additional connection options can be found at https://docs.snowflake.com/en/user-guide/jdbc-configure.htmlIn this example, we’re authenticating with a user name and password, but for production workloads, you can set “spark.sql.catalog.snowflake_catalog.jdbc.private_key_file” with the location of your private key. With these configurations set on your Spark cluster, you can easily read Iceberg Tables from Spark. First, let’s see what tables are available to query.
spark.sessionState.catalogManager.setCurrentCatalog("snowflake_catalog");
spark.sql("SHOW NAMESPACES").show()
spark.sql("SHOW NAMESPACES IN my_database").show()
spark.sql("USE my_database.my_schema")
spark.sql("SHOW TABLES").show()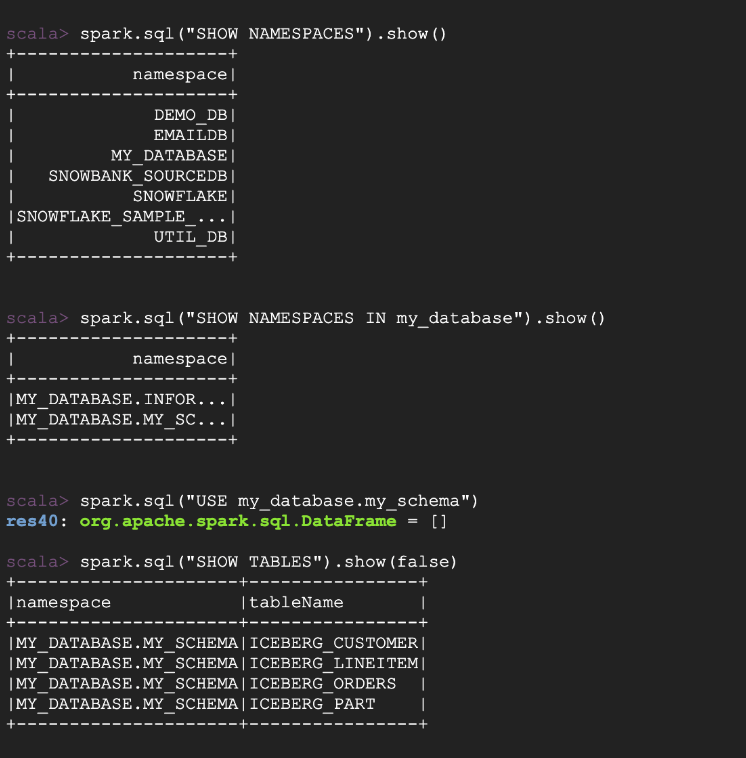
Now, let’s pick a table to query.
spark.sql("SELECT * FROM my_database.my_schema.iceberg_customer LIMIT 10").show()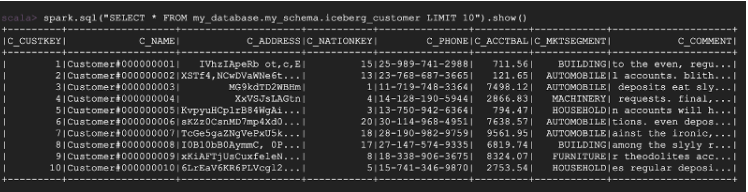
And you’re not limited to only SQL—you can also query using DataFrames with other languages like Python and Scala.
df = spark.table("my_database.my_schema.iceberg_customer")
df.show()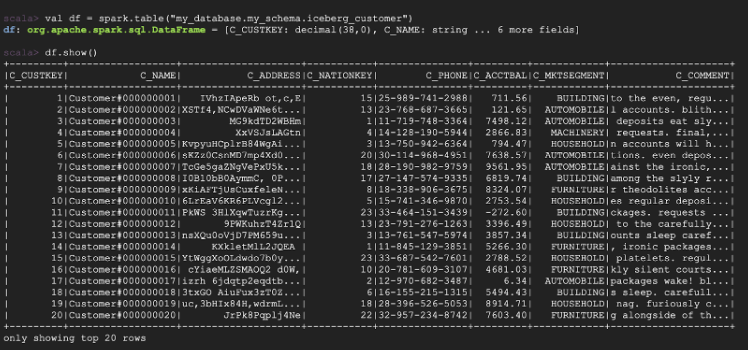
During the preview, many customers indicated a need for interoperability with Spark-based tools. For that reason, in this first release we’ve prioritized support for Spark-based tools to read from the Snowflake Catalog. As indicated here, Iceberg 1.2.0 is compatible with Spark version 2.4, 3.1 and above. We’d love feedback from users on what to build next, whether that be support for reads and writes from Spark, more engines, or both!
Contributing to open source
We want to give our customers the flexibility to build architectures that best suit their needs and use cases. With that in mind, we provide options by building different storage products to support different patterns and use cases. For those use cases requiring high interoperability, Iceberg is a fantastic solution because its growing ecosystem is turning it into a widespread standard. This release is a first step, and we look forward to contributing more to an already awesome, growing community.
How to get started
Have a Snowflake account and want to try this out? If you’re not already enrolled in our private preview for Iceberg Tables, reach out to your account manager to enroll. Use Snowflake to create some Iceberg Tables, and use the code above as a starting point to try querying those tables from Spark.
Forward-Looking Statements
This post contains express and implied forward-looking statements, including statements regarding (i) Snowflake’s business strategy, (ii) Snowflake’s products, services, and technology offerings, including those that are under development or not generally available, (iii) market growth, trends, and competitive considerations, and (iv) the integration, interoperability, and availability of Snowflake’s products with and on third-party platforms. These forward-looking statements are subject to a number of risks, uncertainties and assumptions, including those described under the heading “Risk Factors” and elsewhere in the Quarterly Reports on Form 10-Q and Annual Reports of Form 10-K that Snowflake files with the Securities and Exchange Commission. In light of these risks, uncertainties, and assumptions, actual results could differ materially and adversely from those anticipated or implied in the forward-looking statements. As a result, you should not rely on any forward-looking statements as predictions of future events.
© 2023 Snowflake Inc. All rights reserved. Snowflake, the Snowflake logo, and all other Snowflake product, feature and service names mentioned herein are registered trademarks or trademarks of Snowflake Inc. in the United States and other countries. All other brand names or logos mentioned or used herein are for identification purposes only and may be the trademarks of their respective holder(s). Snowflake may not be associated with, or be sponsored or endorsed by, any such holder(s).
