O hub de metadados: um plano de controle para todo o seu data estate

Durante anos, a promessa de uma plataforma de dados coesa esbarrou na mesma dura realidade: os dados estão em toda parte. Há dados no Snowflake, no AWS Glue, no Microsoft OneLake, no Databricks Unity Catalog, no Apache Polaris™ e em catálogos REST internos que ninguém lembra direito de ter criado... Cada plataforma veio com suas próprias regras, seus próprios metadados e sua própria gravidade. E a cada novo sistema, a distância entre uma plataforma comum e seus dados aumentava.
A resposta não é mover tudo para um só lugar. Isso é coisa do passado. A resposta é conectar tudo por meio de uma única camada: um hub de metadados.
O problema de "apenas escolher uma plataforma"
O senso comum costumava ser a consolidação. Escolha uma nuvem. Escolha um catálogo. Migre os dados e dê o trabalho como concluído. Mas o cenário de dados foi além dessa visão. Migrar dados é contraproducente para o contexto da IA. Aquisições trazem novas plataformas. As equipes desenvolvem nas ferramentas que conhecem. Requisitos regulatórios exigem separação geográfica. O uso de vários catálogos e ambientes multinuvem não é um "erro". É a realidade em que a maioria das empresas vive.
Isso significa a fragmentação de metadados ao ajustar a escala de forma muito ampla. Você pode saber quais dados tem no Snowflake. Mas você sabe o que há no seu catálogo do Glue? No seu workspace do Unity? Na sua instância do OneLake? Você consegue fazer uma consulta em todos eles sem copiar dados? Você consegue governá-los a partir de uma única política? Você consegue ver, em tempo real, tudo o que o seu data estate contém?
Para a maioria das organizações, a resposta honesta é não. É por isso que a Snowflake está focando na interoperabilidade como um hub de metadados.
O que realmente é um hub de metadados
Um hub de metadados não é outro catálogo competindo por dominância. Um hub de metadados agrega e federa metadados de todo o seu data estate em uma única interface consultável. Em vez de forçar a migração de dados, ele reúne a compreensão desses dados, dando a cada usuário uma visão unificada da estrutura, semântica, linhagem, qualidade e propriedade, independentemente de qual sistema armazena os dados.
O Snowflake Horizon Catalog é a camada conectiva, um plano único de visibilidade e controle que fica acima dos seus catálogos existentes e os torna mais úteis.
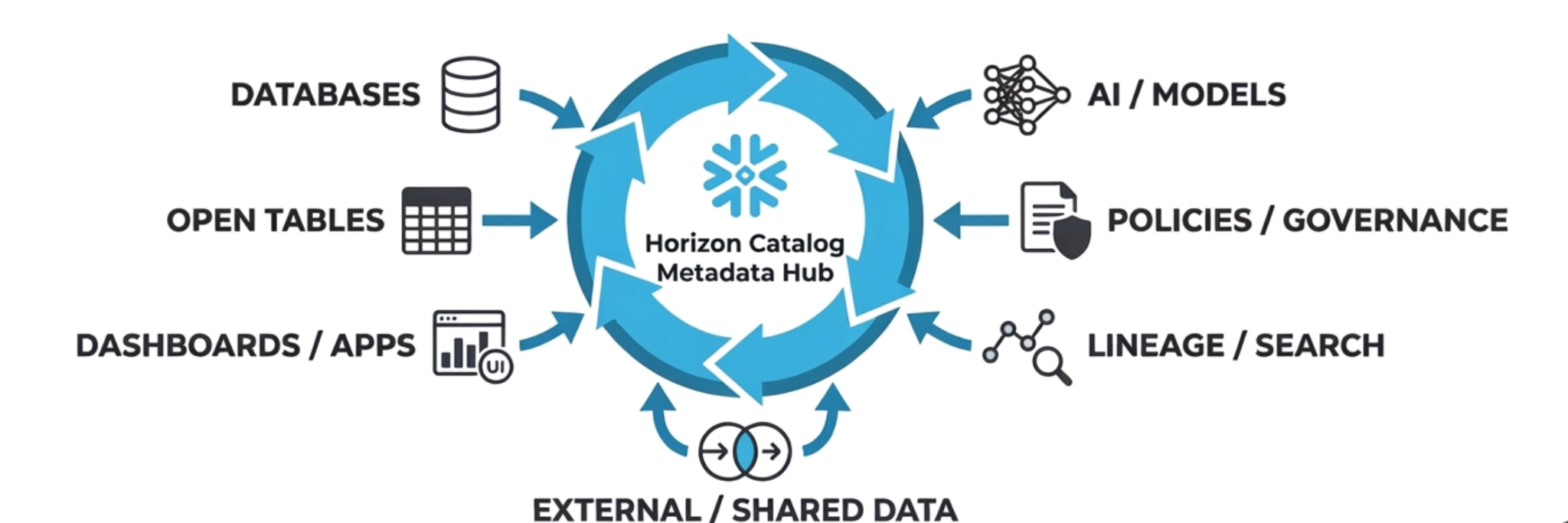
Um hub de metadados se baseia em três ideias fundamentais:
1. Aberto desde a concepção
O ecossistema do Apache Iceberg™ estabeleceu algo raro no mundo dos dados: um padrão aberto genuíno. O formato de tabela do Iceberg e a especificação do Iceberg REST Catalog (IRC) criam um protocolo compartilhado do qual qualquer sistema pode participar. A Snowflake, a AWS, a Databricks e o setor em geral se uniram em torno dele. Publicamos e consumimos o Iceberg REST Catalog (IRC) por meio da instância incorporada do Apache Polaris em cada Horizon Catalog. É contínuo, totalmente integrado e não requer configuração adicional para desbloquear esses recursos de interoperabilidade.
O Iceberg e a especificação IRC estabelecem um protocolo aberto sobre o qual o setor pode se basear. A AWS, a Databricks e muitas outras empresas se alinharam a esse padrão. Fomos além ao investir no Apache Polaris™, agora um projeto de nível superior, para ajudar a avançar o que um catálogo aberto deve ser. Ao incorporar o Polaris em cada Horizon Catalog, oferecemos a você uma base de catálogo genuinamente aberta para o seu lakehouse.
A interoperabilidade não é um diferencial; é o padrão de referência. Qualquer sistema que fale Iceberg pode trocar dados, compartilhar metadados e participar de um data estate mais amplo sem conectores personalizados, pontes proprietárias ou restrições de fornecedores. Sem silos.
2. Nativo e bidirecional
O acesso de somente leitura é uma solução paliativa. Participação nativa? Essa é a arquitetura colaborativa e a que você deseja.
A integração IRC da Snowflake vai além. Quando o Horizon Catalog se conecta a um catálogo compatível, como AWS Glue, Databricks Unity Catalog1, Polaris ou qualquer outra plataforma compatível, ele se conecta de forma nativa e bidirecional. Você não está consultando uma cópia ou um reflexo. Você está lendo e gravando dados diretamente, em seu formato nativo, com total fidelidade. O AWS Glue ou o Databricks Unity vê cada alteração que a Snowflake faz. A Snowflake pode consultar imediatamente os dados que qualquer outra plataforma está gravando de forma nativa. As entradas do catálogo são ativas, e você tem a opção de configurar o intervalo de sincronização (normalmente, recomendamos 30 segundos). Considere este exemplo para trazer um Unity Catalog via IRC:
CREATE DATABASE my_unity_linked_db
LINKED_CATALOG = (
CATALOG = 'my_unity_catalog_int',
SYNC_INTERVAL_SECONDS = 30-- controls namespace/table discovery polling
)
CATALOG_CASE_SENSITIVITY = CASE_INSENSITIVE;Isso permite que você leia e grave em uma fonte do Unity Catalog. Verdadeira participação multiplataforma. Não apenas acesso.
3. Visibilidade completa
O terceiro pilar transforma a conectividade em controle. Usar o Horizon Catalog como seu hub de metadados oferece a você um inventário único e em tempo real de todo o seu data estate. Cada tabela, cada banco de dados, cada catálogo, em cada plataforma, em todos os lugares onde seus dados residem.
A visibilidade completa não é apenas um diferencial. É o pré-requisito para todo o resto. Isso é importante para muito mais do que apenas a descoberta básica. Você pode enriquecer os metadados aos quais está conectado com definições semânticas e incorporar a lógica de negócios diretamente na camada de metadados. Essa camada é a base para a governança. Você não pode aplicar uma política a dados que não consegue ver. Você não pode rastrear a linhagem através de um limite que não consegue observar. Você não pode otimizar custos em workloads que não consegue medir.
Isso já está acontecendo. Organizações com visão de futuro já estão se baseando nisso hoje. Equipes de produção executam workloads em vários catálogos simultaneamente, da Snowflake ao AWS Glue, Databricks Unity Catalog, Apache Polaris e outros, em um modelo operacional coerente. Isso não é experimentação; é a arquitetura delas.
Organizations de vários setores não estão se consolidando em uma única plataforma; em vez disso, estão adotando uma abordagem priorizando a interoperabilidade em várias plataformas. Essa federação depende do Iceberg como uma linguagem de dados comum e de um hub de metadados para fornecer uma visão unificada. O Snowflake Horizon Catalog está em uma posição única para atuar como esse hub de metadados essencial.
O que isso possibilita
Consultas multiplataforma sem copiar dados. Junte uma tabela do AWS Glue com uma tabela do Databricks Unity Catalog e uma tabela gerenciada pela Snowflake em uma única consulta. Sem ETL. Sem atraso de replicação. Sem custo de armazenamento duplicado.
Essa arquitetura reforça a ausência de dependência de fornecedor.
Quando seus metadados estão consolidados, um conjunto de recursos que a fragmentação inviabiliza se torna possível.
A governança de todo o data estate é absolutamente essencial. Aplique políticas de acesso, mascaramento de dados e regras de classificação a partir de um único lugar. Você pode definir regras de qualidade de dados e, com total visibilidade da linhagem, monitorar a qualidade em todo o seu data estate. Quando surgem problemas, você pode rastrear as causas raiz, entender os impactos upstream e downstream e remediar diretamente com o Snowflake Cortex AI, tudo unificado pelo Horizon, independentemente da diversidade de suas fontes de dados. Governe o estate, não apenas a plataforma.
IA que entende todo o seu estate. Um Metadata Hub não atende apenas a usuários humanos. Ele atende à IA. Quando o Cortex AI tem acesso a metadados unificados em todo o seu data estate, ele opera com o contexto completo do seu negócio: relacionamentos de tabelas, definições semânticas, linhagem, sinais de qualidade e padrões de acesso. Isso significa consultas em linguagem natural mais precisas, resultados de pesquisa mais relevantes e agentes de IA que raciocinam entre catálogos, em vez de ficarem confinados a um único silo. Quanto mais ricos e conectados forem seus metadados, mais inteligente o Cortex se torna. A fragmentação priva a IA de contexto. Um Metadata Hub fornece tudo o que ela precisa para entregar valor real.
Atribuição de custos em tempo real. Veja exatamente quais cargas de trabalho consomem recursos em cada integração de catálogo, detalhando os custos por plataforma, equipe ou tipo de carga de trabalho. Otimize com visibilidade total.
Ecossistema sem fragmentação. Deixe as equipes usarem as ferramentas com as quais são mais produtivas: Snowflake para IA conversacional em uma ampla variedade de tabelas e análise de dados, incluindo qualquer tabela onde quer que ela resida, AWS Glue para EMR e Databricks, quando aplicável. O Metadata Hub mantém tudo unido e torna todos os seus dados acionáveis, independentemente das plataformas que suas equipes escolherem.
A arquitetura que torna isso possível
Em sua essência, a arquitetura do Metadata Hub tem três camadas.
A camada de catálogo é onde seus catálogos existentes permanecem como fontes confiáveis para seus próprios metadados. Você não está substituindo nada. Você não precisa migrar ou mover dados para torná-los acionáveis.
A camada de conectividade é onde as integrações de IRC criam links bidirecionais em tempo real entre catálogos e mecanismos de processamento. A integração de IRC do Snowflake é a implementação de referência dessa camada. O Horizon não para por aí. Temos um conjunto diversificado de conectores para fontes externas que também participam do Metadata Hub consolidado.
A camada de controle é a interface para descoberta, governança, linhagem e observabilidade que opera em todos os catálogos conectados simultaneamente.
O resultado é um sistema mais capaz do que qualquer catálogo individual, sem o custo de migração para substituí-los.
A oportunidade à frente
O setor de dados passou uma década construindo silos melhores. Lakes mais rápidos. Warehouses mais inteligentes. Catálogos mais capazes. Cada um foi um avanço genuíno, e cada um contribuiu para a fragmentação.
Usar o Snowflake Horizon Catalog como seu Metadata Hub é a arquitetura que transforma essa fragmentação em um ativo. Em vez de lutar contra a realidade multiplataforma, nós a adotamos e construímos uma camada de coerência por cima que torna cada plataforma mais valiosa do que seria sozinha.
A questão agora não é se essa arquitetura é possível. É se a sua organização está pronta para adotar o Snowflake Horizon Catalog como seu Metadata Hub, transformando os metadados fragmentados em um data estate coeso, e o que você poderá fazer quando isso acontecer.
1 Atualmente, o Databricks não oferece suporte a acesso bidirecional. Para obter mais informações, consulte esta publicação no blog.
