Il Metadata Hub: un unico control plane per l’intero patrimonio dati

Per anni, la promessa di una piattaforma dati coesa si è scontrata con la stessa dura realtà: i dati risiedono ovunque. Ci sono dati in Snowflake, in AWS Glue, in Microsoft OneLake, in Databricks Unity Catalog, in Apache Polaris™, in cataloghi REST sviluppati internamente che nessuno ricorda più di aver creato.... Ogni piattaforma aveva le proprie regole, i propri metadati, la propria forza di gravità. E a ogni nuovo sistema, la distanza tra una piattaforma comune e i tuoi dati aumentava.
La risposta non è spostare tutto in un solo posto. Quel treno è ormai passato. La risposta è connettere tutto attraverso un unico livello: un Metadata Hub.
Perché “scegliere un’unica piattaforma” non basta
La saggezza convenzionale era il consolidamento. Scegli un cloud. Scegli un catalogo. Migra i dati e considera l’operazione conclusa. Ma il panorama dei dati ha superato quella visione. Migrare i dati è controproducente per il contesto dell’AI. Le acquisizioni introducono nuove piattaforme. I team sviluppano sugli strumenti che conoscono. I requisiti normativi impongono la separazione geografica. Multi-catalogo/multi-cloud non è un “errore”. È la realtà in cui vive la maggior parte delle aziende.
Ciò comporta una frammentazione dei metadati su scala molto ampia. Forse sai quali dati hai in Snowflake. Ma sai cosa contiene il tuo catalogo Glue? Il tuo workspace Unity? La tua istanza OneLake? Puoi eseguire query su tutti questi senza copiare i dati? Puoi governarli con un’unica policy? Puoi vedere, in tempo reale, tutto ciò che contiene il tuo patrimonio dati?
Per la maggior parte delle organizzazioni, la risposta onesta è no. Ecco perché Snowflake punta sull’interoperabilità come Metadata Hub.
Cos’è davvero un Metadata Hub
Un Metadata Hub non è l’ennesimo catalogo in lotta per il predominio. Un Metadata Hub aggrega e federa i metadati dell’intero patrimonio dati in un’unica interfaccia su cui eseguire query. Anziché imporre la migrazione dei dati, riunisce la comprensione di quei dati, offrendo a ogni utente una finestra unificata su struttura, semantica, lineage, qualità e ownership, indipendentemente dal sistema che ospita i dati.
Snowflake Horizon Catalog è il livello di connessione, un unico piano di visibilità e controllo che si colloca al di sopra dei cataloghi esistenti e li rende più utili.
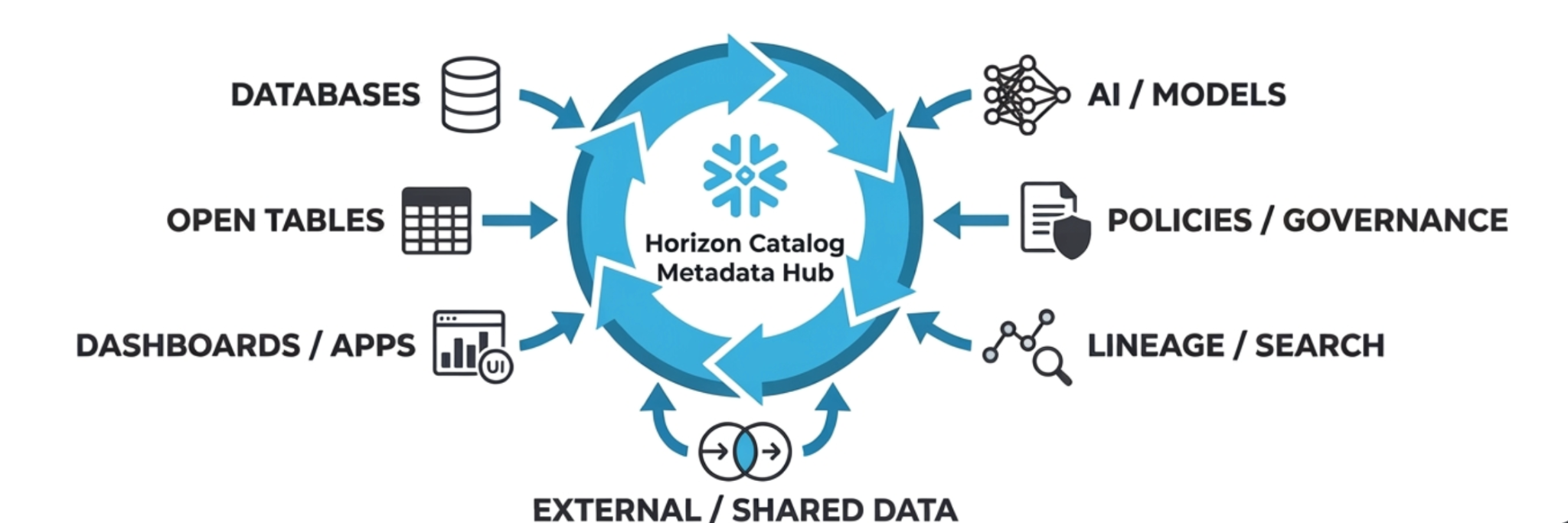
Un Metadata Hub poggia su tre idee fondamentali:
1. Open by design
L’ecosistema Apache Iceberg™ ha realizzato qualcosa di raro nel mondo dei dati: un autentico standard open. Il formato tabellare di Iceberg e la specifica Iceberg REST Catalog (IRC) creano un protocollo condiviso a cui qualsiasi sistema può partecipare. Snowflake, AWS, Databricks e l’industria in senso più ampio si sono tutti uniti attorno a esso. Pubblichiamo e consumiamo Iceberg REST Catalog (IRC) tramite l’istanza Apache Polaris integrata in ogni Horizon Catalog. È fluido, completamente integrato e non richiede configurazioni aggiuntive per sbloccare queste capacità di interoperabilità.
Iceberg e la specifica IRC stabiliscono un protocollo open su cui l’industria può sviluppare. AWS, Databricks e molti altri si sono allineati attorno a questo standard. Siamo andati oltre, investendo in Apache Polaris™, oggi un Top-Level Project, per contribuire a far progredire ciò che un catalogo open dovrebbe essere. Integrando Polaris in ogni Horizon Catalog, ti offriamo una base di catalogo davvero open per il tuo lakehouse.
L’interoperabilità non è un elemento di differenziazione, è lo standard di base. Qualsiasi sistema che parla Iceberg può scambiare dati, condividere metadati e partecipare a un patrimonio dati più ampio, senza connettori personalizzati, bridge proprietari o controllo da parte dei vendor. Nessun silos.
2. Nativo e bidirezionale
L’accesso di sola lettura è una soluzione di ripiego. La partecipazione nativa? Questa è l’architettura collaborativa, quella che desideri.
L’integrazione IRC di Snowflake va oltre. Quando Horizon Catalog si connette a un catalogo supportato, come AWS Glue, Databricks Unity Catalog1, Polaris o qualsiasi altra piattaforma supportata, si connette in modo nativo e bidirezionale. Non stai eseguendo query su una copia o un riflesso. Leggi e scrivi i dati direttamente, nel loro formato nativo, con piena fedeltà. AWS Glue o Databricks Unity vede ogni modifica apportata da Snowflake. Snowflake può eseguire query immediatamente sui dati che qualsiasi altra piattaforma sta scrivendo in modo nativo. Le voci del catalogo sono live e hai la possibilità di configurare l’intervallo di sincronizzazione (in genere consigliamo 30 secondi). Considera questo esempio per importare un Unity Catalog tramite IRC:
CREATE DATABASE my_unity_linked_db
LINKED_CATALOG = (
CATALOG = 'my_unity_catalog_int',
SYNC_INTERVAL_SECONDS = 30-- controls namespace/table discovery polling
)
CATALOG_CASE_SENSITIVITY = CASE_INSENSITIVE;Questo ti consente sia di leggere sia di scrivere su una sorgente Unity Catalog. Una vera partecipazione cross-platform. Non semplice accesso.
3. Visibilità completa
Il terzo pilastro trasforma la connettività in controllo. Utilizzare Horizon Catalog come Metadata Hub ti offre un inventario unico e in tempo reale dell’intero patrimonio dati. Ogni tabella, ogni database, ogni catalogo, su ogni piattaforma, ovunque risiedano i tuoi dati.
La visibilità completa non è un optional. È il prerequisito per tutto il resto. Questo conta per molto più che la semplice discovery di base. Puoi arricchire i metadati a cui sei connesso con definizioni semantiche e incorporare la logica di business direttamente nel livello dei metadati. Questo livello è la base per la governance. Non puoi applicare una policy a dati che non vedi. Non puoi tracciare il lineage attraverso un confine che non puoi osservare. Non puoi ottimizzare i costi su workload che non puoi misurare.
Tutto questo sta già accadendo. Le organizzazioni all’avanguardia ci stanno già sviluppando sopra oggi. I team di produzione eseguono workload su più cataloghi contemporaneamente, integrando Snowflake con AWS Glue, Databricks Unity Catalog, Apache Polaris e altri in un modello operativo coerente. Non si tratta di sperimentazione, è la loro architettura.
Le organizzazioni di ogni settore non si stanno consolidando su un’unica piattaforma, ma stanno adottando un approccio interoperable-first su più piattaforme. Questa federazione si basa su Iceberg come linguaggio comune dei dati e su un Metadata Hub per offrire una vista unificata. Snowflake Horizon Catalog si trova in una posizione unica per fungere da questo Metadata Hub essenziale.
Cosa rende possibile tutto questo
Query cross-platform senza copiare i dati. Combina una tabella AWS Glue con una tabella Databricks Unity Catalog e una tabella gestita da Snowflake in un’unica query. Nessun processo ETL. Nessun ritardo di replica. Nessun costo di archiviazione duplicato.
Questa architettura ribadisce l’assenza di vendor lock-in.
Con i metadati consolidati, diventa possibile una serie di funzionalità che la frammentazione renderebbe impraticabili.
La governance dell’intero patrimonio dati è imprescindibile. Applica policy di accesso, regole di data masking e classificazione da un unico posto. Puoi definire regole di qualità dei dati e, grazie alla piena visibilità sulla lineage, monitorare la qualità sull’intero patrimonio dati. Quando si presentano problemi, puoi risalire alle cause profonde, comprendere gli impatti a monte e a valle e intervenire direttamente con Snowflake Cortex AI: tutto unificato da Horizon, indipendentemente dall’eterogeneità delle tue fonti di dati. Gestisci la governance del patrimonio, non solo della piattaforma.
Un’AI che comprende il tuo intero patrimonio. Un Metadata Hub non serve solo gli utenti umani. Serve anche l’AI. Quando Cortex AI accede a metadati unificati sull’intero patrimonio dati, opera con il contesto completo del tuo business: relazioni tra tabelle, definizioni semantiche, lineage, segnali di qualità e pattern di accesso. Questo si traduce in query in linguaggio naturale più accurate, risultati di ricerca più pertinenti e agenti AI capaci di ragionare tra i diversi cataloghi, anziché restare confinati in un singolo silo. Più i tuoi metadati sono ricchi e connessi, più Cortex diventa intelligente. La frammentazione priva l’AI del contesto. Un Metadata Hub le fornisce tutto ciò di cui ha bisogno per generare valore concreto.
Attribuzione dei costi in tempo reale. Individua con precisione quali workload consumano risorse in ogni integrazione di catalogo, ripartendo i costi per piattaforma, team o tipo di workload. Ottimizza con piena visibilità.
Ecosistema senza frammentazione. Lascia che i team utilizzino gli strumenti con cui sono più produttivi: Snowflake per l’AI conversazionale su un’ampia gamma di tabelle e funzionalità di analisi dei dati, inclusa qualsiasi tabella ovunque risieda; AWS Glue per EMR e Databricks dove applicabile. Il Metadata Hub tiene insieme il tutto e rende utilizzabile ogni tuo dato, indipendentemente dalle piattaforme scelte dai tuoi team.
L’architettura che lo rende possibile
Alla sua base, l’architettura del Metadata Hub si articola in tre livelli.
Il livello dei cataloghi è quello in cui i tuoi cataloghi esistenti restano la fonte autorevole per i propri metadati. Non sostituisci nulla. Non devi migrare o spostare i dati per renderli utilizzabili.
Il livello di connettività è quello in cui le integrazioni IRC creano collegamenti bidirezionali e aggiornati tra cataloghi e motori di calcolo. L’integrazione IRC Snowflake è l’implementazione di riferimento di questo livello. Horizon non si ferma qui. Disponiamo di una vasta gamma di connettori verso fonti esterne, anch’essi parte del Metadata Hub consolidato.
Il livello di controllo è l’interfaccia per discovery, governance, lineage e osservabilità, che opera simultaneamente su tutti i cataloghi connessi.
Il risultato è un sistema più capace di qualsiasi singolo catalogo, senza i costi di migrazione legati alla loro sostituzione.
Le opportunità future
Il settore dei dati ha trascorso un decennio a costruire silos migliori. Lake più veloci. Warehouse più intelligenti. Cataloghi più potenti. Ogni progresso era reale, ma ognuno alimentava la frammentazione.
Utilizzare Snowflake Horizon Catalog come Metadata Hub è l’architettura che trasforma quella frammentazione in un asset. Invece di contrastare la realtà multipiattaforma, la facciamo nostra e vi sovrapponiamo un livello di coerenza che rende ogni piattaforma più preziosa di quanto sarebbe da sola.
La domanda ora non è se questa architettura sia possibile. La domanda è se la tua organizzazione sia pronta ad adottare Snowflake Horizon Catalog come Metadata Hub, trasformando metadati frammentati in un patrimonio dati coeso, e cosa potrai fare una volta fatto questo passo.
1 Databricks attualmente non supporta l’accesso bidirezionale. Per ulteriori informazioni, consulta questo blog.
