Beyond RAG: Enterprise Search Meets Analytics Over Unstructured Data


A popular narrative has taken hold in the AI community: RAG is dead. The argument goes something like this: RAG was always a workaround for tiny context windows — for example, GPT-3.5 could read roughly six pages, GPT-4 about twelve, and now LLMs can ingest a million tokens. So the right move is to load the documents and let the model reason end-to-end without dealing with chunking, embeddings or retrieval.
We think the argument is reasonably correct about "traditional" RAG but it is wrong about what is going to replace it.
The biggest failure mode of RAG was not the context window. RAG was never designed to analyze (for example, aggregate or compare) across hundreds of documents at once. So while a bigger context window lets a model read more, it doesn't give it a database. As we'll show in our benchmarks, a standard RAG agent achieves just 5.6% accuracy on operational analytical tasks over unstructured data, largely because top-k retrieval is not built for corpus wide aggregation, not because the model is weak. We propose that the answer isn't "just make the context window bigger" but instead a smarter analytical execution layer.
Most enterprise search systems were designed to find a document. Analytical Search is designed to answer. Not surface relevant results, not retrieve the closest match, but answer — even when doing so requires reading across hundreds of documents. It does this by treating your document corpus the way a database treats a table: something you can filter, aggregate, count and compare, not just search.
Today, we are excited to introduce Analytical Search (in public preview), a new search paradigm designed to help Snowflake users get deep, actionable insights from unstructured data. Starting with Snowflake CoWork, Analytical Search is available today to knowledge workers who need answers, not just results. By orchestrating efficient semantic search via Snowflake Cortex Search with high-fidelity information processing via Snowflake Cortex AI Functions, Analytical Search delivers the kind of sophisticated analysis that traditional enterprise search engines simply can't facilitate.
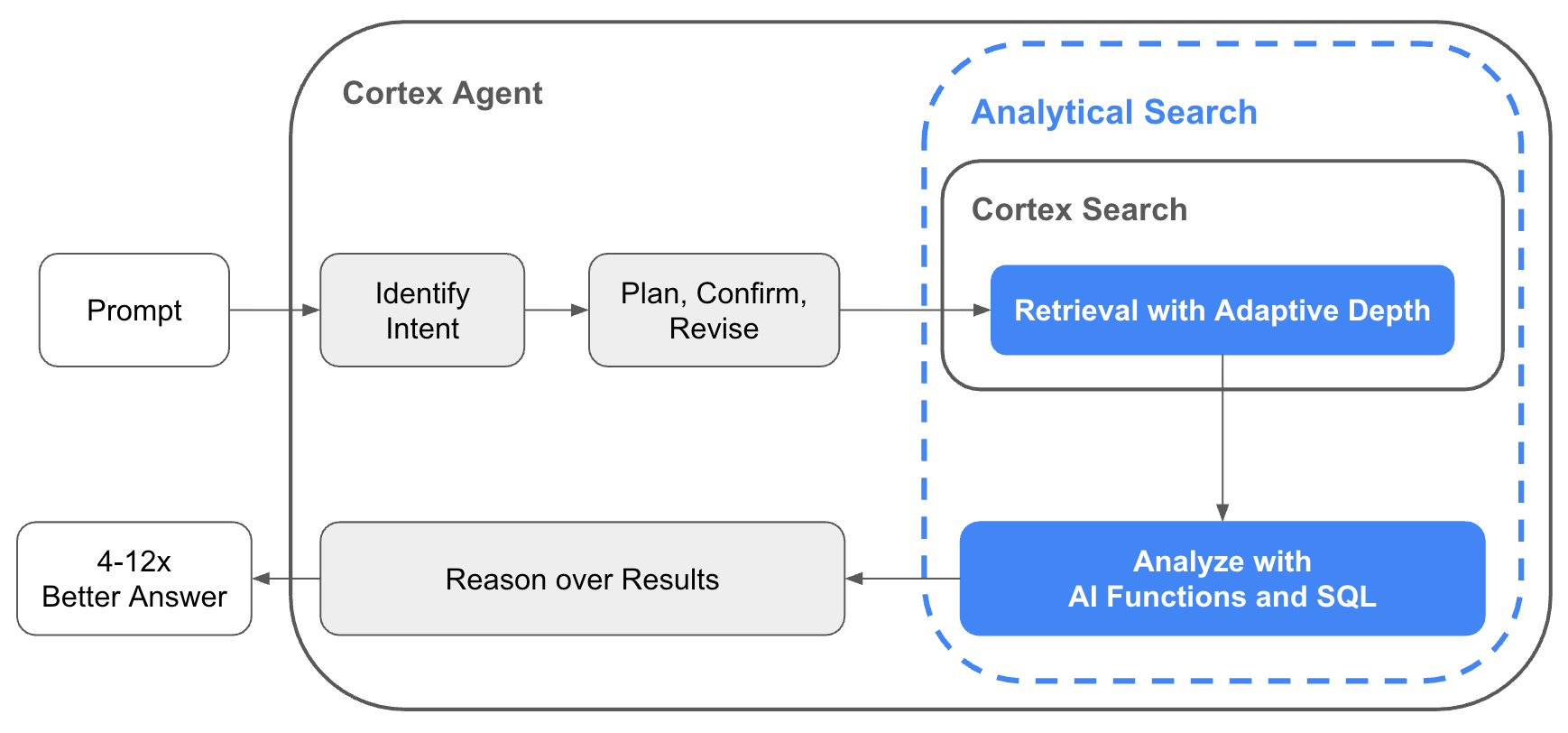
Cortex Agent with Analytical Search. The agent identifies analytical intent in the user's prompt and plans a retrieval-then-analysis execution path. Analytical Search gathers evidence from Cortex Search with adaptive depth, then analyzes it with AI functions and SQL before returning results and reasoning to the agent for the final response.
Why Analytical Search? Analysts and business users need more than just a list of links. Rather than merely retrieving a few semantically relevant documents for a carefully phrased query, we understand that modern users would rather depend on a search agent to handle the full spectrum of complex tasks. Data practitioners today often split this into RAG and ETL pipelines to force structure onto data. This approach rarely scales beyond well-defined sources and outcomes. Analytical search addresses this by effectively building a schema on generation, where the prompt is the contract to the data schema and output is required to provide the analysis.
Take this prompt as an example: "Find documents focused on shipments from the Northwestern US and compare trends from Q1 to Q3."
- Standard RAG (Retrieval-Augmented Generation) agents may fail here because they weren't built for analytical synthesis. The search system will provide top-k results based on relevance and a given agent will do its best to answer the prompt. The reality, however, is that the agent was subjected to that very top-k set of results. Unstructured data isn't just a collection of random web pages or text blobs; it consists of business-critical assets like orders, transactions, and research reports. At this scale, precise, document-level analytics are vital for operational success and strategic decision-making. For the above example prompt, a standard RAG response will likely be relevant, but incomplete.
- Analytical Search addresses this by splitting the task into two phases: retrieval via adaptive-depth search, and computation via AI Functions and SQL operators — so the agent can pull the right slice of evidence and then aggregate it precisely instead of stuffing raw text into its context. Coding agents take the alternative route — grep through documents locally, load matches into the agent's context, and reason over the result — which is a strong agentic baseline but doesn't scale once the question demands corpus-wide aggregation. The accuracy gap follows. On our benchmarks, Analytical Search outperformed standard agentic RAG by 4 to 12 times on analytical tasks, and outperformed coding agents by up to 45% on multistep analytical questions.
The three stages of search
To understand why Analytical Search changes the game, it helps to look at how enterprise search has evolved into three distinct stages:
1. Standard RAG (The baseline)
RAG is simple and powerful: retrieve the top-k most relevant text chunks and ask a large language model to extract an answer. This is highly effective when the answer is localized, textual, and contained within a few passages.
- What goes wrong: If a task requires exhaustive coverage, aggregation, counting, comparison, or normalization across hundreds of documents, top-k retrieval becomes a brittle sampling strategy that misses the full picture.
2. Agentic Search (The evolution)
Agentic search introduces loops: an AI agent can search, read, reason, reformulate its query and search again. By decomposing a problem and chasing missing evidence, agents drastically improve recall and robustness for complex document QA.
- What goes wrong: At its core, much of agentic search is still fundamentally search-and-summarize, but in a reasoning loop. While the agent takes more turns to find better evidence, the final answer is still synthesized from a relatively small, sampled evidence set. It cannot perform true macro-analysis.
A natural next step is to skip retrieval entirely. With million-token context windows, why not load everything and let the model reason end-to-end? The answer is cost, reproducibility, and correctness. Loading thousands of documents into a single prompt is orders of magnitude more expensive than targeted retrieval, produces no auditable execution trace, and still doesn't give you grouping, counting, or SQL-level precision.
3. Analytical Search (The Paradigm Shift)
Analytical Search treats unstructured corpora as native data sources that can be filtered, transformed, joined, grouped and aggregated. Instead of treating documents as passive text blobs, it asks: What if the documents themselves are the table? What if semantic predicates, extractions and summaries become native operators inside an analytical execution plan?
- The Core Concept: Analytical Search brings rigorous, reproducible analytical capabilities to unstructured enterprise data in as few steps as possible. For data practitioners this brings the time-to-value to as little as a day to serve an agent with access to a search index as the only prerequisite.
Architecture: The two-layer paradigm
Analytical Search is able to handle complex analytical tasks by separating the problem into two complementary, highly efficient layers within Snowflake.
Layer 1: Use search to prune
Search is excellent at narrowing a massive corpus down to a highly relevant candidate set, such as finding documents about refrigerated shipping, identifying papers discussing prompt injection, or isolating contracts containing a specific liability clause.
Using Snowflake Cortex Search, the agent quickly isolates the relevant region of the corpus without scanning every single token with an expensive frontier model. Crucially, the depth of this pruning layer dynamically adapts to your data; stretching when the tail of results remains relevant, and cutting off the moment relevance drops.
Layer 2: Use AI functions and SQL to analyze
Once the corpus is pruned, the system shifts from retrieval to computation. Snowflake Cortex AI functions provide high-fidelity semantic operators directly within the data layer:
AI_FILTER: Tests whether text satisfies a specific semantic predicate.AI_EXTRACT: Pulls structured, deterministic fields out of unstructured text.AI_AGG: Summarizes and aggregates textual evidence at scale.
From there, SQL does exactly what it was built to do best: group, count, join, rank, trend, and calculate deltas. By marrying semantic AI operators with traditional relational algebra, the agent is no longer just reading documents. Analytical Search is executing a highly efficient, reproducible analytical workflow over them.
Auto-routing: Measuring analytical intent
Analytical search is the right tool for analytical questions, but not for every prompt. A user asking:
- "What does our travel policy say about meal reimbursement?" does not need exhaustive retrieval, semantic classification, and SQL aggregation.
- Meanwhile, "How does our supply-chain risk language compare to our peers across the last two years of earnings calls?" absolutely does.
Choosing the right engine for each question is itself a functional feature of Analytical Search and Snowflake Cortex Agents.
As shown in our Experiments section, getting auto-routing "right" matters. When a question has analytical shape but the agent treats it as RAG, the answer collapses. Auto-Routing handles the choice automatically. Cortex Agent classifies query intent at runtime: Simple, single-passage questions stay on the standard RAG path; corpus-wide analytical questions trigger the analytical-search loop. Users do not have to know in advance which mode their question belongs to, and you do not pay for analytical search orchestration on questions that do not need it.
Planning mode: Multistep, not one-shot
Answering a complex counting, ranking, or trend question isn't a one-shot retrieval task; it is a multi-step workflow. For instance, if a CFO asks to track risk frequencies across years of earnings calls compared to peers, the system must meticulously isolate the relevant corpus, extract specific semantic facts, and aggregate those trends over time.
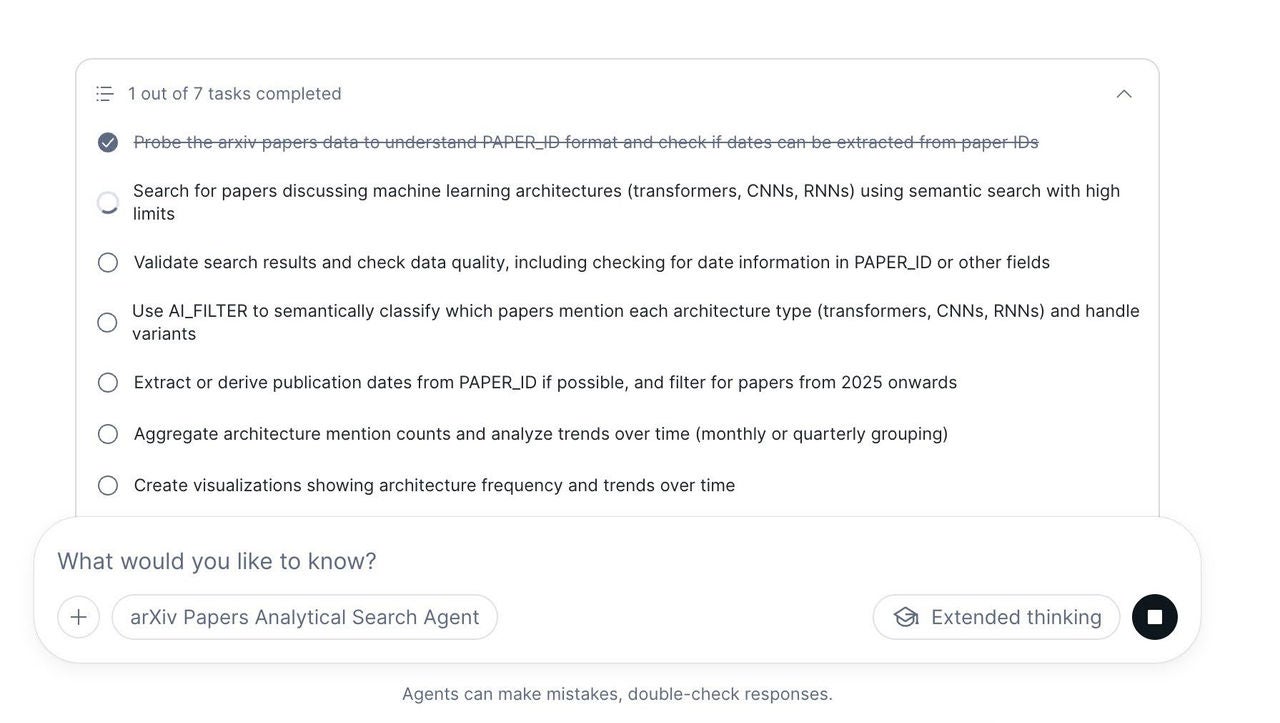
Analytical Search always invokes a multistep plan. Once approved, it converts into an interactive to-do list that updates as the agent performs the subtasks.
Because business decisions carry high stakes, Analytical Search rejects the "black box" approach. Before executing anything, the agent generates a clear, high-level execution plan mapping out its logical steps. It presents this plan to the user for explicit confirmation, allowing for quick course-corrections, like adjusting the peer set or time windows, before processing any data.
Once approved, the plan instantly converts into an interactive to-do list. As the agent prunes the corpus and runs semantic operations, the user can track its progress in real time. This supports complete transparency and trust: you don't need to read raw code to verify the results, because you can clearly see the exact logical path the agent took to deliver the final insight.
Adaptive depth: Search deep enough not to miss the answer
Adaptive depth is the mechanism that makes analytical search behave less like sampling and more like exhaustive analysis. A fixed top-k retrieval strategy gets two things wrong.
- Too shallow. The missing item is often the specific data point that changes the answer—perhaps a contract missing a standard termination clause, a paper reporting a different benchmark, or a document that flips a quarterly trend.
- Too deep. The user or the LLM optimistically asks for k=1,000, but the corpus actually contains only a few dozen relevant documents, and the rest is wasted compute.
Adaptive depth makes the cutoff a function of the data, not a guessed parameter, and it works in two phases.
- Phase 1: Bound the relevant region. The system fetches an initial batch of results and uses a fast LLM to judge small samples at the head and tail of the ranked list. If even the top results are irrelevant, the search itself is bad — the tool returns nothing rather than feed AI functions material that would only generate noise. If the tail is still relevant, the cutoff lives further out: The system extends the fetch limit and rejudges the new tail, repeating until the tail goes off-topic or a hard ceiling is reached.
- Phase 2: Find the exact cutoff. Once the relevant region is bounded, the system binary-searches inside it, LLM-judging a sample around the midpoint and tightening the window, to land on the precise boundary in a handful of rounds. A narrow fact question stays shallow; a trend across a broad corpus goes deep; a question against a sparse corpus stops early.
The cost story cuts both ways. Better coverage reduces wasted downstream, while AI calls and prevents expensive wrong answers. Better restraint avoids paying to extract and classify documents that would not have answered the question in the first place. AI functions are powerful but not free, as every unnecessary call adds latency and dollars. And adaptive depth is the layer that decides how many of those calls are worth making.
Experiments
We have benchmarked analytical search across three data sets, across four systems.
The three data sets
- OfficeQA Pro, an open public-finance benchmark over long-form financial reports, scanned tables, and historical documents. We use it to exercise the semantic search +
AI_EXTRACTpath: locate the right chunk via Cortex Search, pull values out of historical tables; annual totals, reported figures from scanned financials, period-over-period changes and run the arithmetic in SQL. This is per-document deep extraction rather than corpus-wide aggregation, which makes it a useful complement to the other data sets. - Logistics Documents (internal benchmark). Example questions: contracts with penalty clauses and SLA requirements grouped by carrier and value tier; emerging technologies such as automation, IoT tracking, or AI-driven routing tracked by quarter; total estimated shipment value for active purchase orders involving a given carrier and region. These are analytical workloads over operational documents.
- ArXiv Papers (internal benchmark). A representative question: "How many papers from 2023–2025 evaluate LLMs on the GPQA benchmark?" Others ask how mentions of techniques like chain-of-thought, mixture-of-experts, prompt injection, watermarking, or tool use in LLM agents change over time, or whether reported values agree across papers. This is literature review as analytics: not "find a paper," but "measure a pattern across papers."
The four systems
- Claude Code, using grep to search documents as local files and perform analytics in context.
- Snowflake CoCo, Snowflake's coding agent — a strong agentic baseline that can search, read, write code and execute SQL.
- RAG Agent — a conventional Cortex Agent with Cortex Search tool, but without the analytical search capabilities enabled.
- Cortex Agent with analytical search — adds the planning, AI-function, and adaptive-depth orchestration described above.
Evaluation metrics
Analytical questions vary in form, so we tailor the scoring metric to the query's shape. We use correctness × fidelity for numeric and categorical types, which accounts for both direction and magnitude. For list shapes, we use the F1 score, as it inherently balances precision and recall. These shapes are determined by the golden structure rather than the agent's response, and final accuracy is the mean of per-query scores. Prompt classifications included:
- List queries for example, "list every paper that proposes a new long-context benchmark"
- Scalar queries for example, "what fraction of 2024–2025 quantization papers evaluate at ≤4-bit?"
- Trend queries for example, "how has the count of HarmBench-evaluating papers changed from 2023 to 2025?"
- Categorical comparison queries for example, "which has more, MedQA or PubMedQA evaluators?"
For OfficeQA Pro, we follow the dataset's published convention, using a strict deterministic judge with zero error margin. For the Logistics and arXiv data sets, we use the per-shape decomposition described above.
Results
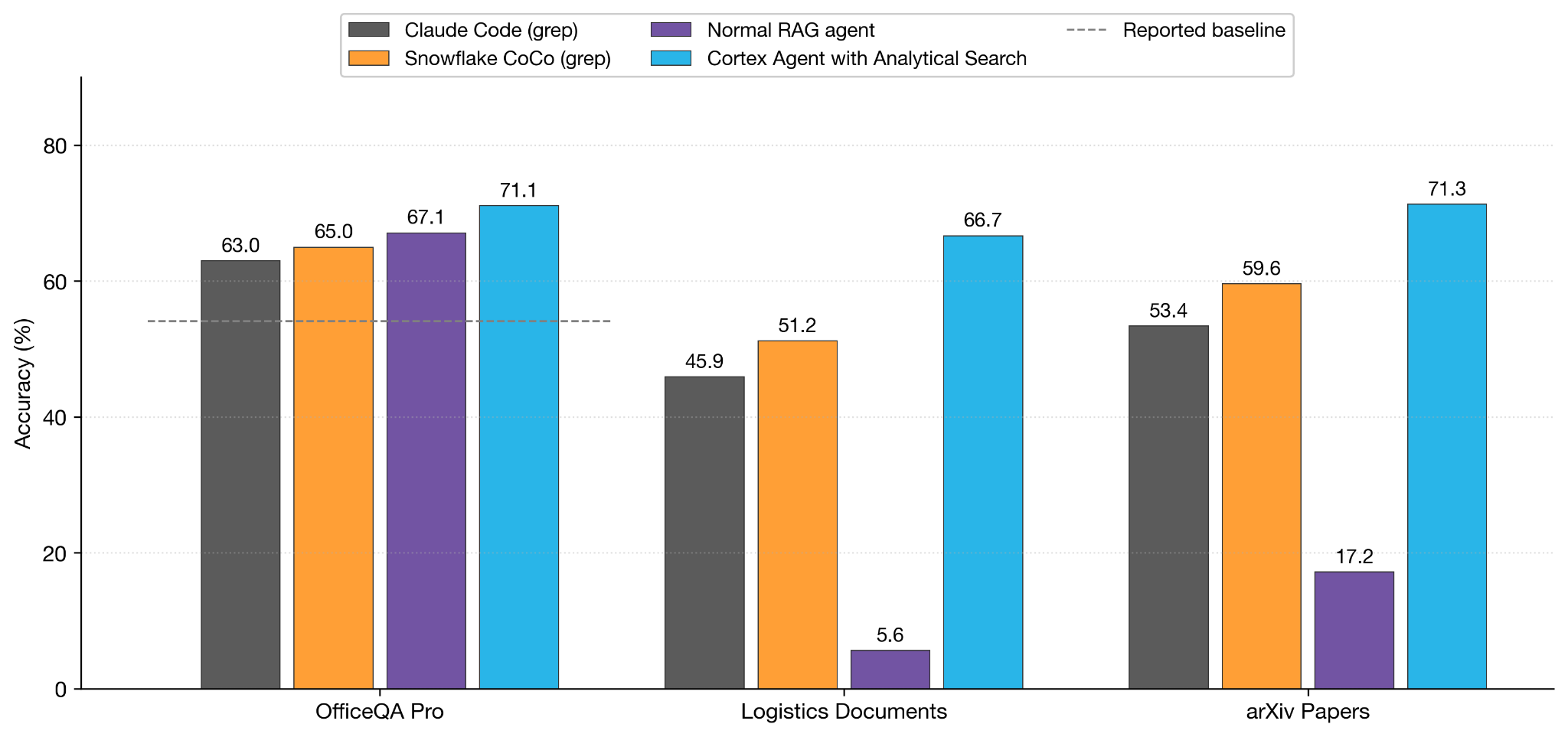
Accuracy of four systems across three data sets, evaluated with Claude Opus 4.6. OfficeQA Pro is scored by a deterministic judge (0% error margin). The dashed line on OfficeQA Pro shows the reported comparable baseline (54.1). The four systems cluster within nine points on OfficeQA Pro, but on the analytical search data sets Cortex Agent without analytical search (RAG agent) collapses to 5.6 (Logistics) and 17.2 (arXiv), while Cortex Agent with analytical search excels at 66.7 and 71.3.
Figure 3 above shows results across all three data sets for Claude Opus 4.6. Three things stand out.
- On OfficeQA Pro, all three Cortex systems comfortably beat the reported baseline (54.1) and cluster within seven points of each other (65.0, 67.1, 71.1). This is the per-document extraction shape — locate the right chunk, pull values from a table, do the arithmetic. Analytical search wins, but it does not need to win by much; the dataset is not built around corpus-wide aggregation.
- On the analytical data sets, the gap opens dramatically. RAG agent collapses to 5.6% on Logistics Documents and 17.2% on arXiv Papers. These are not "weaker numbers" — the agent is failing to get the full context. The corpus has too many relevant documents for top-k retrieval to surface, and once the agent has only a handful of chunks, there is nothing left to aggregate, count, or compare. CoCo does materially better (51.2 / 59.6) because it can plan and run SQL, but it still trails Cortex Agent with analytical search (66.7 / 71.3) by 10–15 points.
- The ordering holds with double-digit margins on both analytical data sets: Cortex Agent with analytical search > Snowflake CoCo > Claude Code > RAG agent. The same arrangement of components that systematizes the analytical loop; search to prune, AI functions to filter and classify and extract, SQL to aggregate, adaptive depth to right-size the work, is what closes the gap. A general agent can improvise that loop on every question and partially succeed; a system designed around it does the work more reliably and at lower cost.
Why Snowflake is a natural place for Analytical Search
Analytical Search is an orchestration workflow that needs an agent that can plan and tool-call, run scalable retrieval over unstructured data and execute semantic processing close to the data — all in the same governed system. Snowflake provides each piece. Cortex Agent plans the workflow and orchestrates the calls. Cortex Search retrieves over unstructured documents and applies filters on associated structured attributes. Cortex AI functions are semantic operators that compose directly with SQL. SQL provides the execution substrate. Language becomes an operator inside a single, governed query plan.
That matters for trust. In enterprise settings, a plausible paragraph is not enough. Users need to understand what was searched, filtered, counted, excluded and how the final number was derived. Analytical search makes those steps explicit and inspectable, instead of hiding them inside a chain of thought.
From unstructured data to value
The highest-value questions customers ask about unstructured data are often not answered by a single passage. They require reading across contracts, invoices, support notes, research papers, call transcripts, filings and PDFs; applying semantic judgment; and then doing real analysis. The winning systems will not be the ones that stuff more chunks into a prompt. They will be the ones that combine retrieval, semantic functions, planning, adaptive depth and database execution into one coherent loop.
Analytical search is our bet on that future: search for pruning, AI for semantic understanding, SQL for rigor, and Snowflake for scale and governance. Analytical search introduces the fastest path to go from unstructured data to insights.
Here is how you begin:
- Create a Search Service (or repurpose an existing one)
- Add the Search Service to a Cortex Agent
- Start Prompting Cortex CoWork



