Arctic RL: A Unified, Open Source RL Backend for Enterprise Post-Training

Reinforcement learning (RL) is critical for modern AI but remains inefficient and expensive due to redundant computation and the lack of a unified system backend.
Arctic RL is an open-source library that provides this missing infrastructure layer, owning GPU orchestration and system optimizations to deliver portable performance gains across RL frameworks.
Key takeaways:
- Arctic RL integrates with VeRL and SkyRL today; enable ZoRRo with one config flag, no code changes required
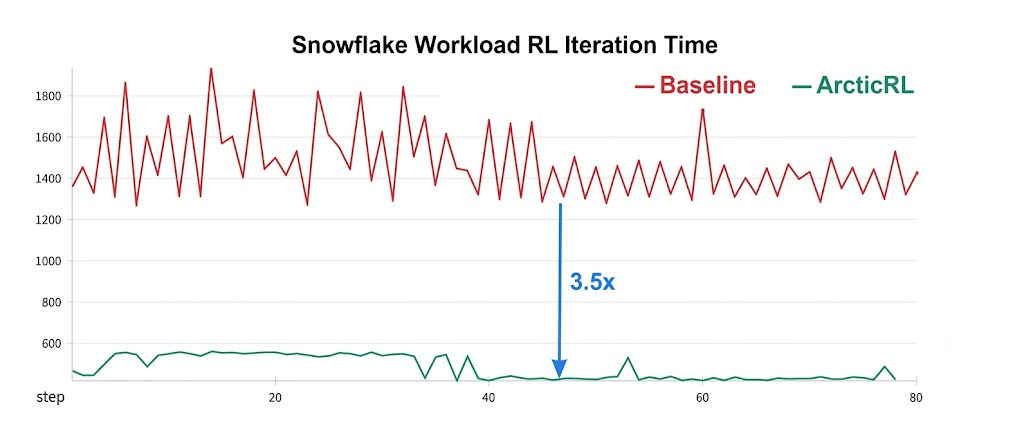
- ZoRRo delivers up to 6x actor-update acceleration and a 3.5x end-to-end training speedup, reducing Arctic-Text2SQL-R2 training from ~5 days to ~36 hours on 32 H200 GPUs
- Arctic-Text2SQL-R2 achieved higher accuracy scores (48.7) than Gemini 3.1 Pro (47.9) and Claude 4.7 (47.3) on Snowflake's evaluated enterprise SQL benchmark under the tested conditions
- Two open source recipes ship with this release: a text-to-SQL recipe that improved BIRD dev accuracy from 59.92% to 70.35%, and a multi-hop QA recipe that improved average accuracy from 69.6% to 72.3%
The following sections explore the Arctic RL architecture, detailed system optimizations, and our integrations with major frameworks. We also share open source training recipes and demonstrate the performance portability of our solution.
Why RL post-training needs a unified backend
RL training is uniquely inefficient: rollout generation, log-prob computation and actor updates perform significant redundant computation. Yet RL is the only major LLM workload with no unified, open source system backend (unlike pre-training, which has DeepSpeed and Megatron-LM, or inference, which has vLLM and SGLang). Every framework reimplements the same system layer independently, so optimizations cannot be shared.
As a result, RL frameworks must be deeply GPU-aware — they integrate training and inference engines directly, manage cross-engine memory sharing/weight synchronization and handle the low-level orchestration between actor updates, rollout generation and log-prob computation (for example, router-replay (a method to cache MoE routing decisions) for MoE). This tight coupling makes system innovations difficult to share and forces every framework to solve the same optimization, integration and orchestration problems independently.
Arctic RL is our answer to the above problems. Arctic RL is a fully open source RL backend designed from the ground up to be the unified open source system layer for RL post-training.
This separation is a paradigm shift for RL. Holistic system optimizations like ZoRRo become portable because they live in the backend, not scattered across multiple frameworks. And RL libraries can focus on RL algorithms while Arctic RL handles optimizations as well as the distributed GPU orchestration.
Arctic RL is already integrated end-to-end with VeRL and SkyRL today, with PrimeRL integration ongoing. If you are already using VeRL or SkyRL, you can gain the full ZoRRo optimization suite by simply selecting the arctic-rl backend in your training script. You can achieve similar performance gains across all integrated frameworks (Figure 1). No code change or reimplementation required.
In Snowflake production testing, Arctic RL reduced training time for Arctic-Text2SQL-R2 by up to 3.5x relative to the evaluated VeRL baseline configuration (Figure 1).
Arctic RL architecture
An RL post-training step looks different from the outside than from the inside. From the outside, it is a sequence of high-level operations: generate rollouts, score them, compute log-probs, then take a gradient step. From the inside, each is a multi-engine, multi-GPU dance involving a training engine, an inference engine, weight transfer between them, micro-batching and sequence packing. Every post-training framework today has to handle both.
Arctic RL inverts this: the library handles only the outside view; the backend owns the inside view as a single, holistic system (Figure 2). This is what makes the system optimizations portable, because the optimization happens below the abstraction, on the side that owns the GPUs.
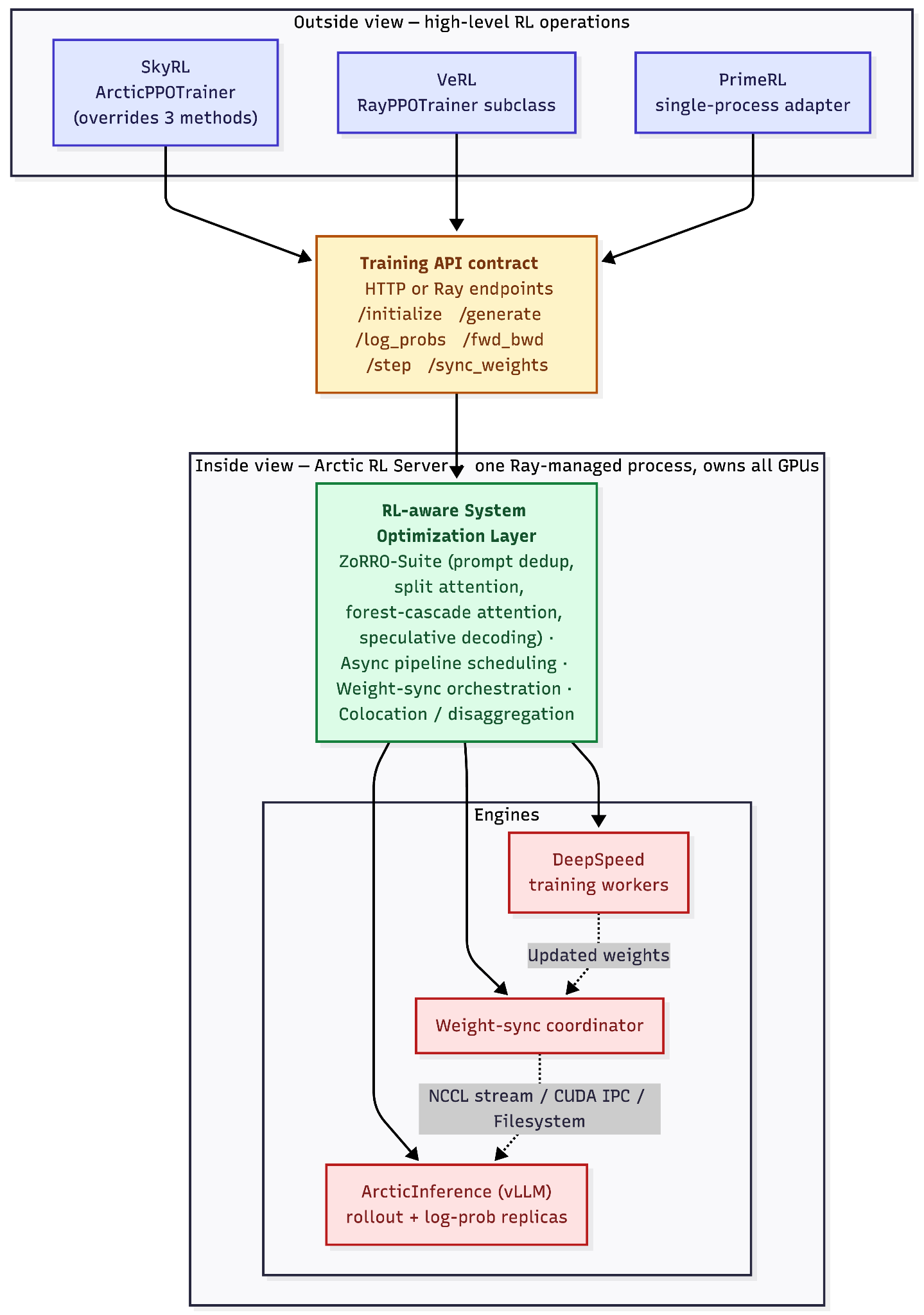
Arctic RL architecture comprises of three layers:
- A unified training and inference server backend, Arctic RL launches DeepSpeed training workers and ArcticInference (vLLM) sampling and log-prob replicas behind a single set of training API. The server backend owns the distributed GPU stack and orchestration of training and rollout components.
- An RL-aware system optimization layer. Arctic RL treats the full RL loop holistically and applies optimizations across training, inference and modeling boundaries. This is where ZoRRo lives. These optimized implementations are invisible to the framework above but deliver multiplicative speedups. Because these optimizations sit in the backend, they are portable — every framework that integrates Arctic RL can access them.
- A GPU-agnostic, RL-aware client. Post-training frameworks integrate Arctic RL through a thin client library that runs entirely on CPU. The client adapter translates framework-specific RL abstractions into Arctic RL API calls, and stays agnostic to the backend optimizations or distributed GPU implementation details.
Arctic RL is an opinionated, yet flexible backend designed to support diverse, high-performance training workflows.
- Any model architecture. Arctic RL inherits the model coverage of its underlying engines — any architecture supported by DeepSpeed for training and ArcticInference/vLLM for inference works out of the box, including the full Hugging Face causal LM family. We have validated Qwen3 (0.6B through 32B) and Qwen2.5. Because the entire stack is open source, support for exotic architectures not yet covered by the underlying engines is a tractable contribution path — additions made to DeepSpeed or ArcticInference flow through to Arctic RL automatically.
- Custom loss functions. Arctic RL maintains an open source registry of loss functions where a new loss function is added via one decorator: @register_loss_fn("my_loss"). The default GRPO implementation covers the full feature set used by modern recipes — PPO clipping, M2PO masking, CISPO loss, decoupled proximal log-probabilities for off-policy training, etc.
- Custom post-processors. The same registration mechanism handles any per-token computation between the forward pass and the loss.
- Full-parameter training. Arctic RL is not LoRA-only. The default path is full-parameter training with DeepSpeed ZeRO. LoRA is an option, not a constraint.
System performance optimizations
Arctic RL ships with a portfolio of system-level optimizations targeting the dominant cost centers in modern RL workloads: redundant compute and memory in long-prompt training and rollout, end-to-end pipeline serialization, and inflexible GPU placement. Every optimization here lives in the server, behind the training API.
- ZoRRo (Zero Redundancy Rollouts): Deduplicates prompt computation using Split Attention (training) and Forest Cascade Attention (inference), achieving up to 6x actor-update acceleration.
- Asynchronous Pipelining: Overlaps generation and training via asynchronous APIs to maximize resource utilization and hide compute latency.
- Flexible Placement: Supports colocation or disaggregation of training and inference workers via a single config flag to optimize for memory or compute-bound workloads.
These optimizations compound. ZoRRo cuts the per-step compute and memory cost; async pipelining hides what compute remains behind generation; flexible placement removes contention. In Snowflake's evaluated production configuration, these optimizations reduced training duration from approximately five days to roughly 36 hours.
Integration with VeRL, SkyRL and PrimeRL
Integrating with Arctic RL is consistent across all frameworks. Each framework uses a centralized controller to manage orchestration, data loading, and reward scoring on the CPU, while delegating GPU-intensive operations—generate, log_probs, fwd_bwd, step, and sync_weights—to the Arctic RL training API.
Integration with VeRL, SkyRL, and PrimeRL is standardized through a thin, CPU-only client adapter. The framework maintains a central controller for orchestration and rewards, while delegating heavy GPU operations—such as generation, log-prob computation, and gradient steps—to the Arctic RL backend via unified training APIs.
Arctic RL for enterprise workloads
Arctic RL runs in production at Snowflake, and the workloads below are real recipes the community can reproduce.
Arctic-Text2SQL-R2
Arctic-Text2SQL-R2 outperforms Gemini 3.1 Pro and Claude 4.7 on Snowflake's Text-to-SQL benchmark despite being 30–150x smaller than other high-performing models. This benchmark is a deliberately difficult evaluation set where even the strongest frontier models struggle.
The recipe combines a Snowflake-first training corpus (real DDL, documentation and analytical scripts, regrounded to detach questions from any specific schema) with a collision-resistant execution reward that injects edge-case rows and tightens equivalence checks during RL.
Open source text-to-SQL recipe
To show the gains are not tied to proprietary data, we built a fully open source text-to-SQL recipe using only the public benchmark BIRD with Qwen3-32B as the base.
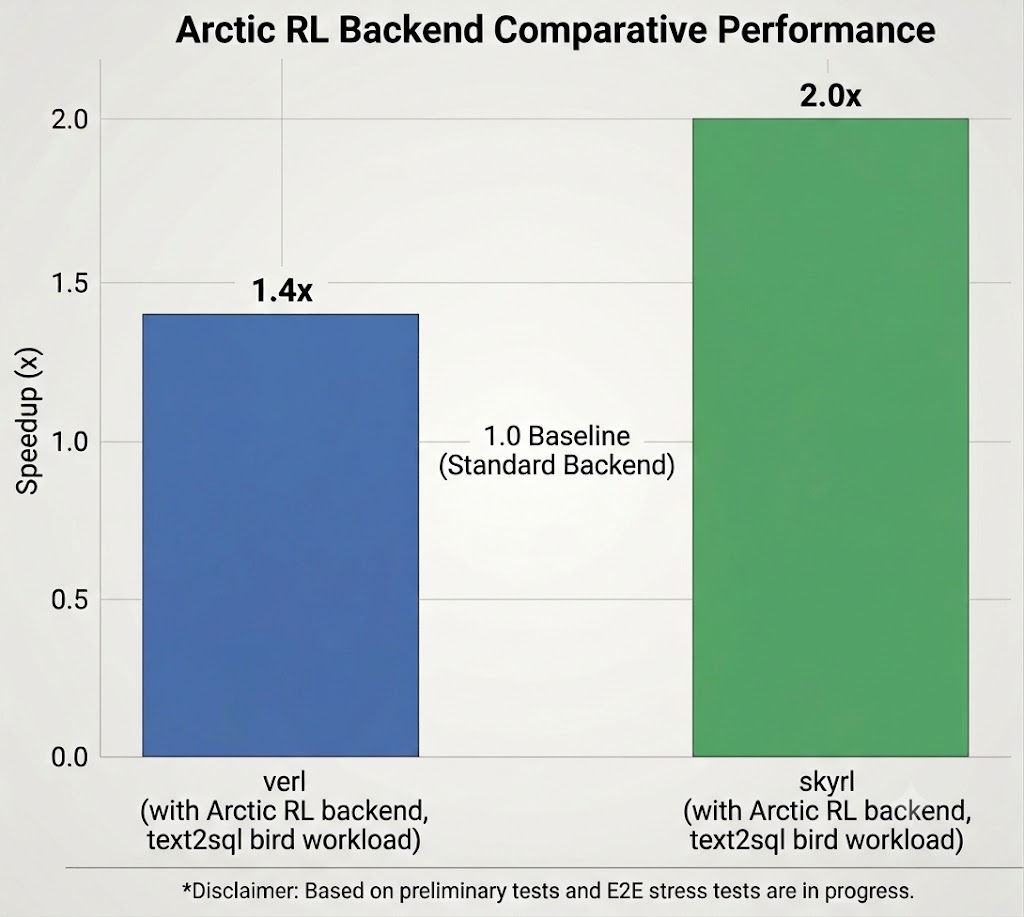
The recipe uses GRPO with an execution-match reward: Each predicted SQL is run against the real SQLite database and compared against the gold output. Using the evaluated GRPO training configuration, BIRD dev accuracy increased from 59.92% to 70.35% — a +10.43-point gain with no proprietary data, compared to the corresponding open source RL baseline. Arctic RL reduces time-to-result by 1.4x/1.5x vs. baseline VeRL/SkyRL on the same hardware.
Open source long-context multi-hop QA recipe
We extended Arctic RL to a very different challenge: long-context multi-hop QA, where the model must locate and chain evidence across lengthy documents.
Using GRPO and Qwen3-32B, we train on ~14K public examples from HotpotQA, MuSiQue and 2WikiMQA — contexts up to 16K tokens, both standard and needle-in-a-haystack distractor variants — with a substring exact-match reward. Inference extends the context window to 128K tokens via YaRN (a RoPE-based extension for long sequences).
In the evaluation LongBench v1 configuration, across five QA tasks (Qwen-Long evaluation setting), average accuracy increased from 69.6% to 72.3% — a +2.7-point gain, with the largest gains on the hardest multi-hop benchmarks: +7.5 on MuSiQue, +4.5 on HotpotQA, +3.5 on 2WikiMQA.
Performance portability
The chart below (Figure 3) shows the speedups that VeRL and SkyRL gain by integrating Arctic RL on the open source text-to-SQL workload, and running on 32 H200 GPUs. Arctic RL reduced end-to-end training time by 1.4x and 1.5x for VeRL and SkyRL respectively.
How to get started
To get started, see the Arctic RL README for installation instructions and reproducible run scripts.
What we are building next and how to contribute
Arctic RL is open source from day one. We invite the research community to build on this stack, integrate new post-training frameworks, and contribute optimizations back to the backend.
For Snowflake customers, Arctic RL's infrastructure efficiency drastically reduces the cost and time required to train specialized SQL reasoning models. Arctic RL enables organizations to build and maintain high-accuracy, domain-specific AI agents that adapt to their unique business context in hours, not days. Arctic RL ensures that as your business data evolves, your AI models can keep pace without requiring massive infrastructure overhead.
Contributors
Systems: Tunji Ruwase, Michael Wyatt, Stas Bekman, Karthik Ganesan, Thong Nguyen, Ye Wang, Reza Yazdani, Jaeseong Lee, Mert Hidayetoglu, Xinyu Lian, Jeff Rasley, Yuxiong He, Samyam Rajbhandari (lead)
Modeling: Zhewei Yao, Xiaodong Yu, Lukasz Borchmann, Krzysztof Jankowski, Yite Wang, Gaurav Nuti.
Integration partners: the VeRL, SkyRL and PrimeRL teams, without whom this work would not have been possible.
Benchmark / Comparative Methodology Disclosure
Performance results discussed in this post are based on internal testing under specific workload configurations and hardware environments. Actual performance may vary depending on model architecture, workload characteristics, configuration and infrastructure.
Forward-Looking Statements
This content contains forward-looking statements, including about future product offerings and integrations, which are subject to change and are not commitments to deliver functionality.
Comparative Demonstration Disclosure
Comparisons are based on evaluated benchmark conditions and publicly available or internally tested configurations.
Arctic RL: A Unified, Open Source RL Backend for Enterprise Post-Training

HybridDeepResearch: Enforcing Rigor Across SQL and Web Search for Enterprise Agents
Inside the ArcticSwarm Architecture: How ArcticSwarm Improves Deep Research