Inside the ArcticSwarm Architecture: How ArcticSwarm Improves Deep Research


Many enterprise questions don't stop at "what happened?" — they demand to know why, what shifted outside the warehouse, and whether the evidence is stable enough to support a high-stakes decision. To answer them, an AI system has to connect private records with the messy, fast-moving outside world. That long-horizon, cross-source research is a coordination problem that traditional multi-agent architectures struggle with.
The root problem: Long-horizon search is not coding
Many of today's multi-agent system designs are heavily inspired by software engineering paradigms. This mapping makes intuitive sense for code generation: developer agents operate inside a clean workspace with concrete toolsets and highly deterministic feedback loops. They can edit a file, run a unit test, read a stack trace and use the compiler as an explicit, absolute signal to determine if their next step is correct.
Open-ended, long-horizon search possesses no such safety net.
A complex research workflow rarely provides a clean pass/fail signal. The ground truth is routinely buried across fragmented web pages, messy corporate PDFs, stale system status reports and ambiguous entity aliases. In this environment, the most dangerous failure mode is not that an agent finds nothing at all. Instead, catastrophic failures happen when an agent uncovers something highly plausible too early and simply stops looking.
This exposes the fundamental divide between the coding and search paradigms:
- Coding is driven by execution. The core metric is binary and deterministic: Does a code modification successfully clear a test suite?
- Search is driven by coordination under uncertainty. The core metric is evidence-weighted and judgment-based: Did the system uncover a diverse pool of evidence, cross-examine competing hypotheses and accurately calibrate its confidence before committing?
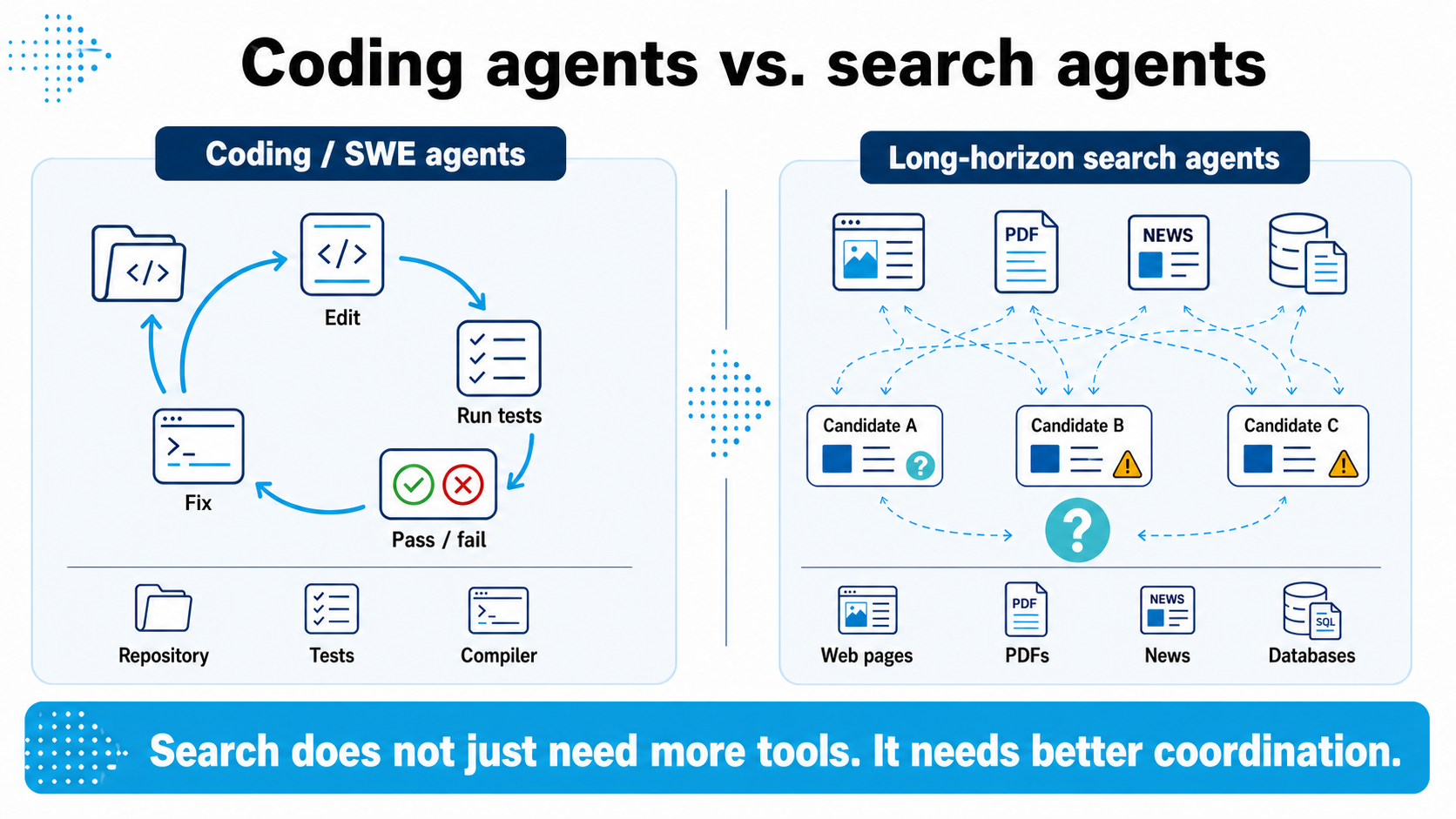
Coding agents receive executable feedback, such as tests, compilers, and stack traces. Long-horizon search agents must coordinate under uncertainty, comparing partial evidence, conflicting candidates, and ambiguous sources without a single pass/fail signal.
When we apply traditional coding structures to search workflows, the lack of an uncertainty safety net leads to premature convergence. The moment an agent surfaces an initial lead that satisfies even a few surface-level constraints, it often immediately fixates.
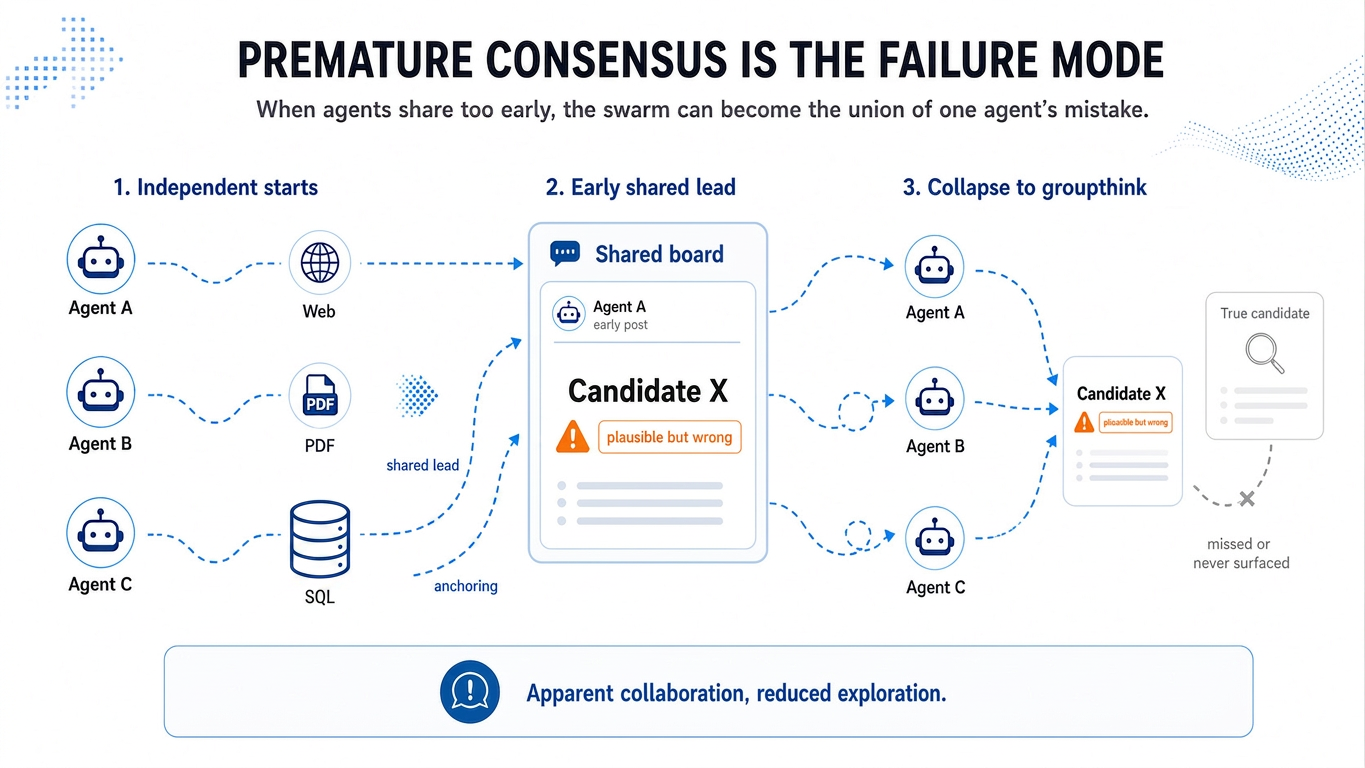
If multiple agents are embedded in an unstructured, always-on chat topology, this single-agent's fixation quickly mutates into groupthink. When one agent posts an early, flawed lead to a shared thread, parallel workers abandon their own unique trajectories to free-ride on the visible discovery. They exhaust their token budgets confirming the early lead rather than independently challenging it. Ultimately, the agents' collective intelligence collapses into the union of a single agent's mistakes.
Core design principle of ArcticSwarm: Defer consensus, independent search
To break the anchoring cycle, ArcticSwarm operates on a foundational system principle: Explore independently first. Review together second. Commit only after evidence survives disagreement. Instead of allowing unconstrained peer-to-peer chatter, the architecture is engineered to preserve maximum disagreement early in a subtask's lifecycle, delaying consensus until evidence from multiple independent paths has survived a rigorous audit. The workflow executes across three distinct behavioral modes:
- Isolation Mode: Structurally maximizes independent search paths to guarantee evidence diversity.
- Review Mode: Structurally maximizes useful disagreement to surface conflicting assumptions and gaps.
- Commitment Mode: Forces a unified, evidence-backed final agreement only after constraints are cross-verified.
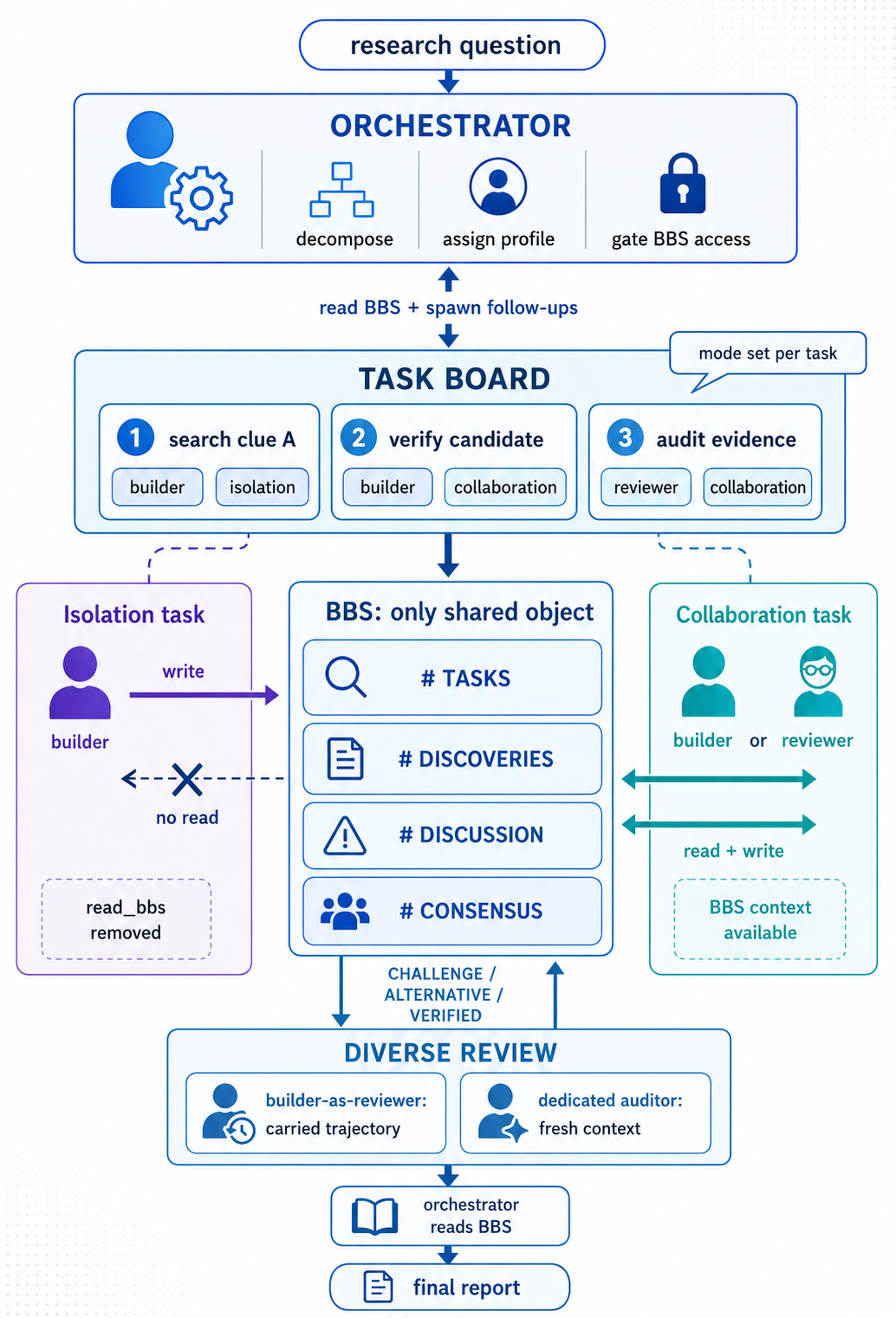
The core engine powering this gated workflow is a single, centralized communication framework: the Gated Bulletin Board System (BBS).
Gated BBS: Communicate later, explore more independently
In ArcticSwarm, agents do not begin by pooling their guesses. They begin by separating their search paths.
The orchestrator breaks each question into profiled tasks (e.g., one agent retrieves sources, another reasons over candidate consistency, another searches for counterexamples) and assigns each task a communication mode. Tasks flagged as isolated get write-only access to the board: the agent can post discovered candidates and citations, but cannot read peer posts while it works. That keeps each agent's tool calls, queries and reasoning track entirely decoupled.
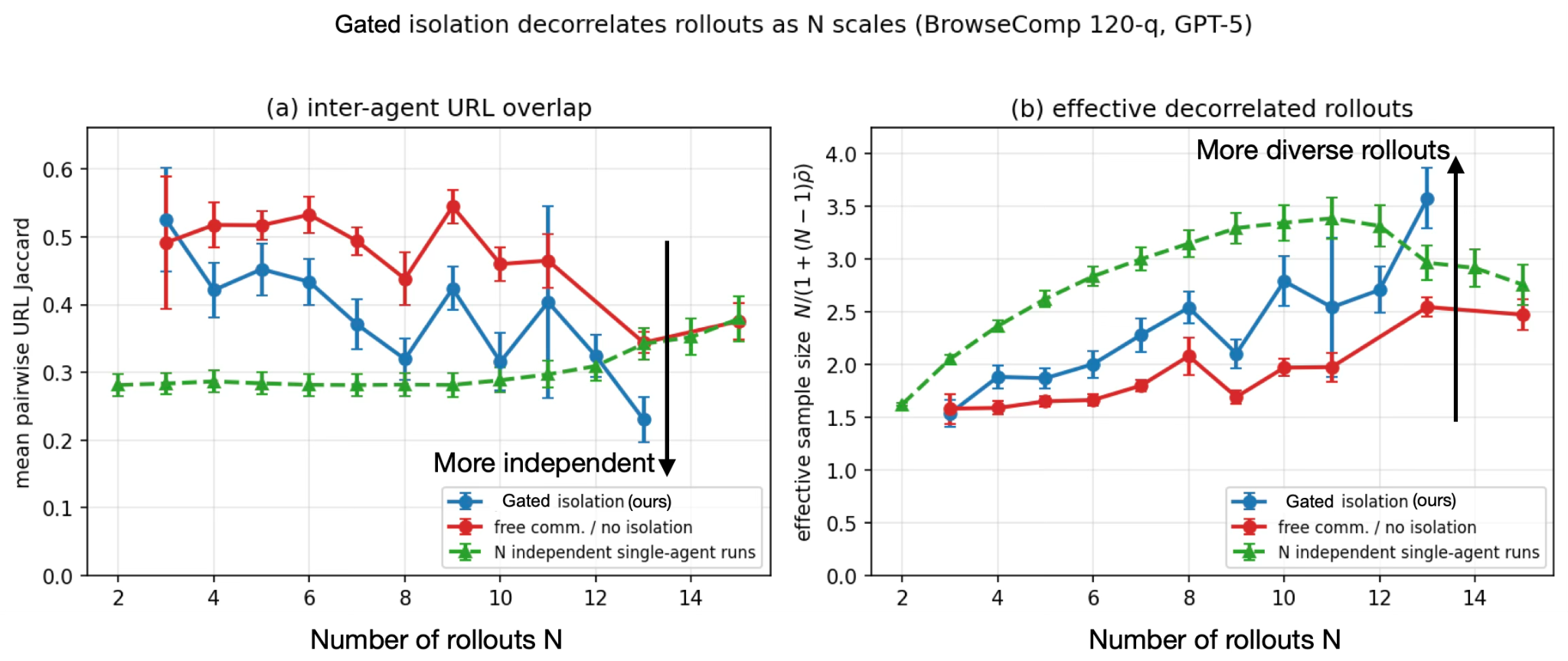
We verified the read-barrier with an isolation ablation study on the BrowseComp 120-question subset with GPT-5, comparing the Gated BBS against free communication and independent single-agent runs. For each pair of agents we computed the Jaccard overlap of fetched URLs (lower = more distinct evidence) and summarized it as an effective sample size (ESS), which characterizes how many genuinely distinct investigators the agent system behaves like.
As the ArcticSwarm scaled, the Gated BBS produced the lowest URL overlap and the highest ESS, whereas free communication caused agent trajectories to heavily correlate.
Reviewers: Robust evaluation on diverse perspectives
Exploration alone is not enough. A swarm can uncover the correct candidate and still fail to commit if it lacks the structural guardrails to verify evidence constraint by constraint. ArcticSwarm introduces Review Mode to handle this verification step.
Crucially, ArcticSwarm does not rely on a single, centralized verifier model. The reviewer pool is structurally diverse by construction, drawing from two distinct profiles:
- Builders-as-reviewers: Active investigators whose primary search tasks have concluded. They transition into reviewers, bringing their direct search trajectories, failed candidates and source judgments along to audit their peers.
- Dedicated reviewers: Independent evaluator agents that enter the workflow from outside any investigator's track, evaluating claims with fresh context.
Reviewers drop their individual read-barriers, audit the shared board, and publish highly specific, per-constraint verdicts directly back into the active search channels:
- CHALLENGE: a candidate fails a constraint or relies on weak evidence.
- ALTERNATIVE: another candidate better satisfies the constraints.
- VERIFIED: specific evidence supports the candidate against the required constraints.
These structured verdicts function as live, mid-search control signals. For instance, logging a CHALLENGE instantly triggers targeted "rival-sweep" tasks, redirecting the swarm's remaining token budget to resolve the conflict.
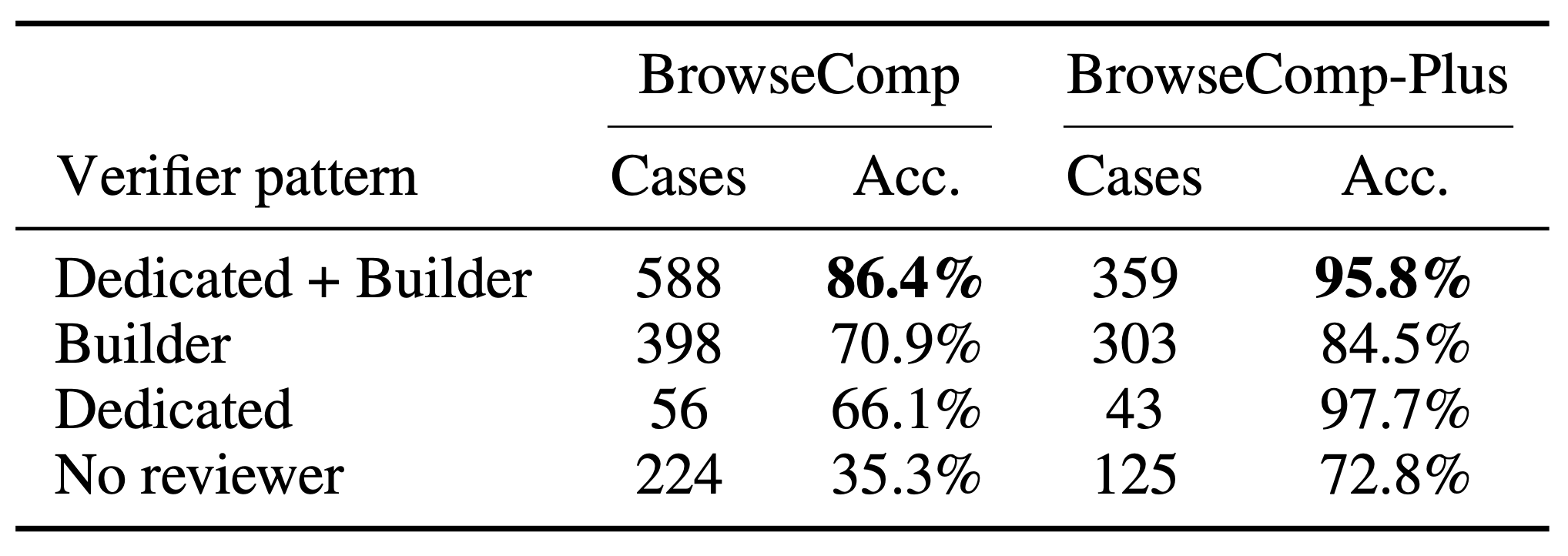
The empirical results validate this adversarial dynamic. Looking at full-set evaluation runs with GPT-5, accuracy scales dramatically based on reviewer composition:
- On the BrowseComp full set (1,266 questions): Cases that secured `VERIFIED` verdicts from both builder and dedicated reviewer sources reached 86.4% accuracy, compared to 70.9% for builder-only, 66.1% for dedicated-only and a dismal 35.3% when no reviewer consensus appeared.
- On the BrowseComp-Plus full set (830 questions): The directional pattern held even firmer. Dual-source verified cases achieved 95.8% accuracy, while the no-reviewer bucket dropped to 72.8%.
While these represent observational buckets rather than a randomized removal of reviewers, they underscore why multi-source reviewer diversity is foundational to the architecture's stability.
Empirical results: Why architecture matters
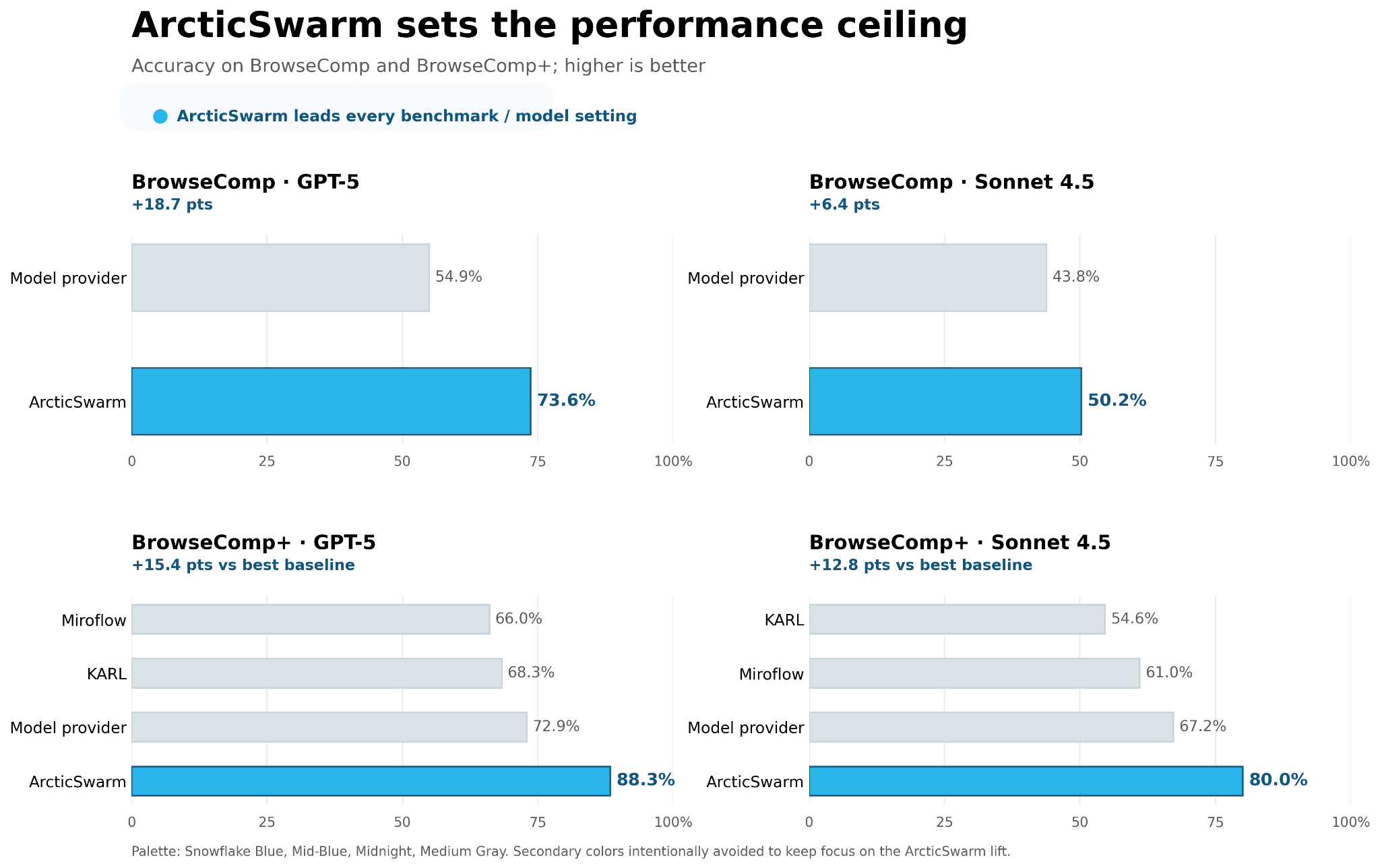
We evaluate ArcticSwarm on GPT-5 and Sonnet 4.5, on BrowseComp and BrowseComp-Plus. BrowseComp evaluates multi-constraint identification against the live web over 1,266 questions; BrowseComp-Plus evaluates retrieval over an approximately 100K-document corpus on 830 questions. Results are reported from research evaluations using provider APIs without additional model training or fine-tuning. We compare ArcticSwarm with the (1) Model provider reported numbers (e.g., Opus-4.5 System Card) reported scores, (2) KARL (a learned-policy single-agent baseline trained on BrowseComp-Plus), and (3) MiroFlow (a leading open source multi-agent framework). We use GPT-4.1 with official judging prompts for evaluation for all evaluated benchmarks. The headline performance metrics utilize the full benchmark sets, while communication topology ablations were executed over a representative 120-question subset.
On BrowseComp, ArcticSwarm reaches 73.6% with GPT-5, compared with 54.9% for OpenAI's deep-research baseline and 63.4% for MiroFlow. On BrowseComp-Plus, it reaches 88.3% with GPT-5, ahead of the published baselines reported in the paper. The same direction holds across multiple model families, including Sonnet 4.5 and Sonnet 4.6.
Isolated vs. unstructured communication modalities
To isolate exactly how coordination patterns alone affect success, we held all underlying model parameters fixed and ran ArcticSwarm against three alternative communication topologies on the 120-question BrowseComp subset using GPT-5:
- Single Agent (SA): A single model executes tools and commits to its first plausible hypothesis without an independent audit phase. (60.6% accuracy)
- Direct Messaging (DM): A decentralized topology allowing peer-to-peer chatter through unconstrained private channels. (56.7% accuracy)
- Duo: A tight, two-agent setup pairing a single investigator with one concurrent auditor. (70.0% accuracy)
- Gated BBS (ArcticSwarm): All multiparty interactions are strictly gated and routed through broadcast-and-isolate states on a centralized board. (73.0% accuracy)

The architectural conclusions drawn from the evaluation runs are as follows:
- Topology dictates swarm capability: Structured multi-agent topologies outperform single-agent baselines due to deeper source coverage, parallel decomposition and adversarial cross-examination.
- More communication channels create siloed noise: Unconstrained peer-to-peer communication degrades performance (e.g., DM at 56.7% vs. single-agent baseline at 60.6%), while structured, gated communication like the Gated BBS (73.0%) scales accuracy.
- Disagreement, then verification, is the real lever: Reviewer-profile diversity (both builder and dedicated reviewers) is key to reliability; cases verified by both sources scored 86.4% on BrowseComp, significantly higher than the 35.3% baseline.
- The primitive directly solves hybrid cross-modal friction: The core patterns (isolation during discovery, broadcast for review, managed disagreement) are transferable to hybrid research, enabling ArcticSwarm's decoupled evidence surface to preserve and reconcile distinct domains like web prose and SQL joins.
The new primitive: Designing for disagreement
The critical breakthrough for engineering reliable multi-agent systems is not simply adding more workers or throwing more tokens at a prompt. Instead, it is meticulously managing when, how and with whom information is shared.
By enforcing strict task-level isolation during early discovery and using trajectory-backed peer review for final validation, ArcticSwarm replaces traditional brittle, chat-driven agent behavior with disagreement by design.
For long-horizon deep research, agents need time and space to form independent hypotheses. They require a centralized, structured canvas to cross-examine evidence. They require reviewers with entirely different operational histories and viewpoints. And ultimately, they require a commitment protocol that treats analytical disagreement as a verification tool, rather than an obstacle to suppress.
ArcticSwarm's Gated BBS architecture turns that philosophy into an engineered reality. In complex enterprise domains where there is no compiler, no unit test and no simple pass/fail safety net, managing the information flow may be the most important coordination primitive of all.
To explore the product application narrative, enterprise safety architectures and real-world supply chain risk use cases of this technology, read our companion publication, ArcticSwarm: Transforming Hybrid Deep Research for Enterprise Intelligence.
Authors
Snowflake AI Research: Boyi Liu, Yite Wang, Xiaodong Yu, Yuxiong He, Zhewei Yao
Academic Collaborators: Soyoung Yoon (Seoul National University), Ruofan Wu (University of Houston), Fan Shu (University of Houston)