Support Multiple Data Modeling Approaches with Snowflake


PLEASE NOTE: This post was originally published in 2019. It has been updated to reflect currently available products, features, and functionality.
Since I joined Snowflake, I have been asked multiple times what data warehouse modeling approach Snowflake best supports. Well, the cool thing is that Snowflake supports multiple data modeling approaches equally.
Turns out we have a few customers who have existing data warehouses built using a particular approach known as the Data Vault modeling approach, and they have decided to move into Snowflake.
So the conversation often goes like this:
Customer: “Can you do Data Vault on Snowflake?”
Me: “Yes, you can! Why do you ask?”
Customer: “Well, your name is Snowflake so we thought that might mean you only support Snowflake-type schemas.”
Me: “Well, yes, I can understand your confusion in that case, but the name has nothing to do with data warehouse design really. In fact, we support any type of relational design, including Data Vault.”
What is Data Vault modeling?
For those of you who have not yet heard of the Data Vault System of Business Intelligence or simply Data Vault (DV) modeling, it provides (among other things) a method and approach to modeling your enterprise data warehouse (EDW) to be agile, flexible, and scalable.
This is the formal definition, according to the inventor Dan Linstedt:
The DV is a detail-oriented, historical tracking and uniquely linked set of normalized tables that support one or more functional areas of business.
It is a hybrid approach encompassing the best of breed between 3rd normal form (3NF) and star schema. The design is flexible, scalable, consistent, and adaptable to the needs of the enterprise. It is a data model that is architected specifically to meet the needs of today’s enterprise data warehouses.
The main point here is that DV was developed specifically to address agility, flexibility, and scalability issues found in the other mainstream data modeling approaches used in the data warehousing space. It was built to be a granular, non-volatile, auditable, historical repository of enterprise data.
At its core is a repeatable modeling technique that consists of just three main types of tables:
- Hubs: Unique list of business keys that represent business objects
- Links: Unique list of associations/transactions that represent the unit of work of a business process
- Satellites: Descriptive data for hubs and links (Type 2 with history)
Because hubs are repositories of business object identifiers (the business key), this makes hubs business-driven because business objects themselves are the focus of business capabilities.
Now, source systems can be thought of as the automation engines of business processes, which in turn track a business object’s relationships and data state (e.g., on, off, active, inactive, balance, etc.). For an enterprise that will have multiple source systems, these business objects and their descriptive data are easily tracked through semantic integration by business keys. We call this technique “passive integration.”
Links are designed to be many-to-many structures that give you the flexibility to absorb any cardinality and business rule changes without re-engineering (and therefore without reloading any data).
Satellites give you the adaptability to record history at any interval you want, plus unquestionable auditability and traceability to your source systems.
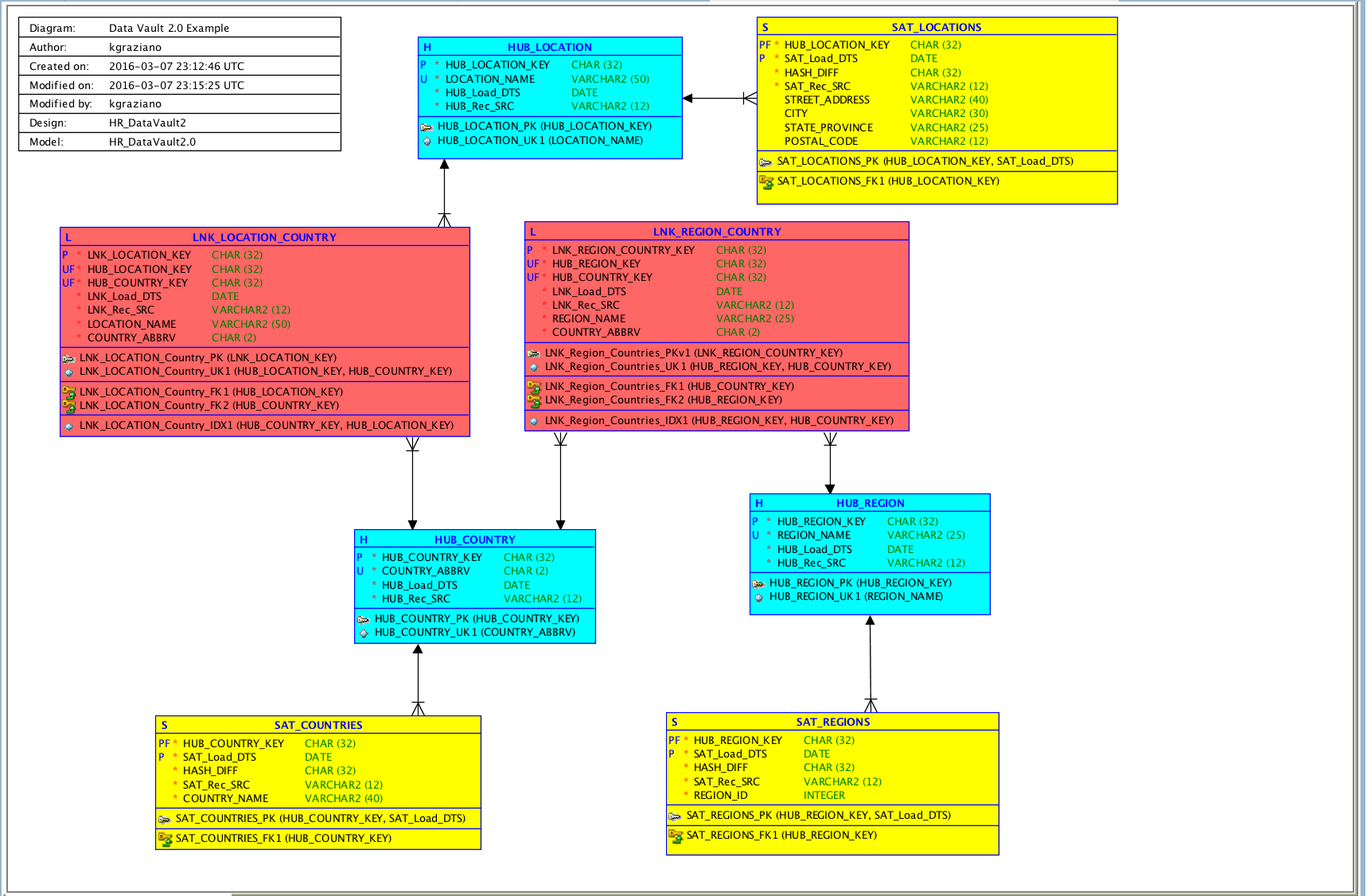
Here is a simple example of what a Data Vault 2.0 model looks like:

Snowflake features to use in a Data Vault
Snowflake is an ANSI SQL RDBMS with consumption-based pricing, and supports tables and views like all the relational solutions on the market today. Because, from a data modeling perspective, Data Vault (DV) is a specific way and pattern for designing tables for your data warehouse, there are no issues implementing one in Snowflake.
In fact, with Snowflake’s combination of MPP compute clusters, optimized columnar storage format, and adaptive data warehouse technology, I think you will get better results with your DV loads and queries with less effort than you get today on your legacy data warehouse solutions. Remember that with Snowflake you don’t need to pre-plan partitioning or distribution keys, or build indexes to get great performance. That is all handled as part of Snowflakes’s dynamic query optimization feature that uses its secure, cloud-based metadata store and sophisticated feedback loop to monitor and tune your queries based on data access patterns and resource availability, among other things.
Because Snowflake customers are getting improved query performance (in some cases, up to 100x improvement), I think Snowflake can be a great place to try virtualizing your information mart (i.e., reporting) layer that you expose to your BI tools.
Data Vault 2.0
For those of you interested in implementing the DV 2.0 specification, Snowflake can handle that as well. It has a built-in MD5 hash function so you can implement MD5-based keys and do your change data capture using the DV 2.0 HASH_DIFF concept.
Not only does Snowflake support DV 2.0 use of hash functions, but you can also take advantage of Snowflake’s multi-table insert (MTI) when loading your Data Vault Logarithmic point-in-time (PIT) tables. With this feature, you can load multiple PIT tables in parallel from a single join query from your Data Vault.
DV resources
If you are interested in learning more about DV, there is a website dedicated to it as well as a few books on the subject that you might want to peruse:
- Introduction to Agile Data Engineering by Kent Graziano (me)
- The Data Vault Guru by Patrick Cuba
- Intro to DV – free white paper on my personal blog
- Free DV intro videos - from the inventor Dan Linstedt
- Building a Scalable Data Warehouse with DV 2.0 by Dan Linstedt
- Dan Linstedt’s blog
Hopefully, this post answers the basic questions about doing DV on Snowflake (yes, you can). If you want to start using Snowflake, feel free to take advantage of our on-demand offer with up to $400 in free usage.
Keep an eye on the Snowflake blog and Twitter and LinkedIn accounts for updates on all the action and activities here at Snowflake.
Additional resources

{kind=link}
The Demand and the Design: Navigating Data Engineering's Two Great Shifts

Data Engineering in the AI Era: New Snowflake Tools Built for Smart Pipelines

Hybrid Tables Just Got Up To 8x Faster
