

As a platform, Snowflake supports your data modeling technique of choice including Data Vault, Kimball dimensional modeling, Inmon, some combination of techniques, or whatever you choose to build on your own. In Part 1 of this two-part post, we explain how to work with SAP data in Snowflake Cloud Data Platform as part of an ELT workflow.
After HVR has replicated the data out of SAP into Snowflake (which is typically the most challenging part of working with SAP data), you can work with and model the data in any way you prefer. Here in Part 2, we describe how to transform the replicated data into a star schema using views that encapsulate the business logic required. When these views have been created, they can be directly queried by BI tools or materialized into tables that can be queried.
The following procedure uses a very simple table, MARA (General Material Data), but the concepts apply to any table being replicated from SAP into Snowflake. At the end of the blog you’ll see a screenshot of a simple SAP Sales and Distribution (SAP SD) data mart.
Below is a high-level architecture of the process:
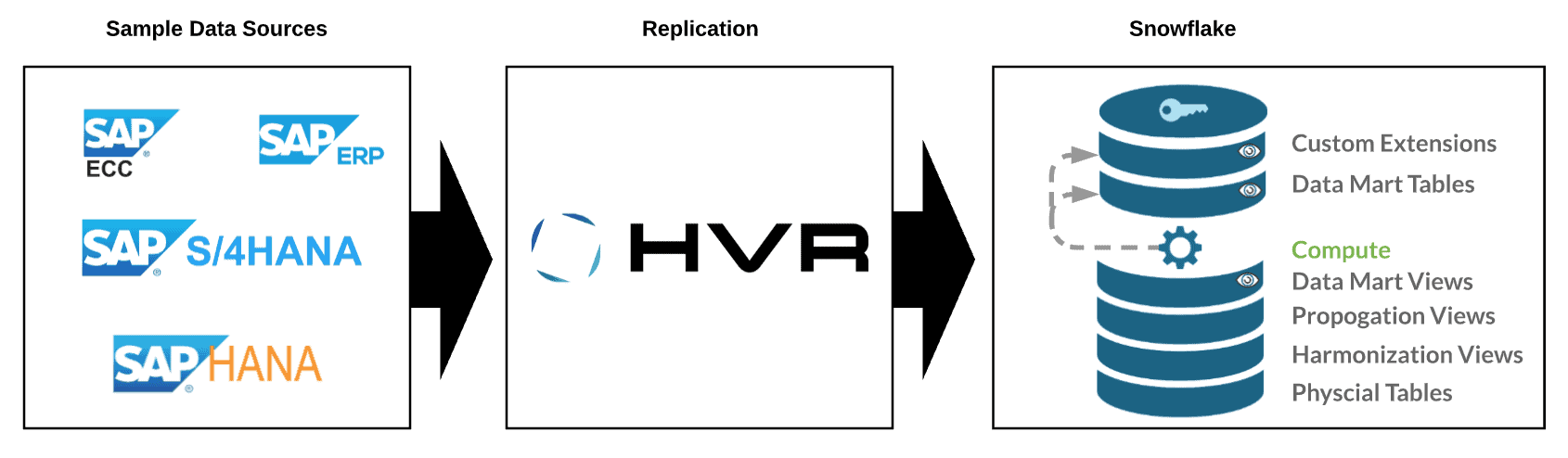
One of the nice things about using HVR is that it can replicate data out of SAP applications regardless of the underlying database.
Step 1: Create and load the physical table
The first step is to create the target table using HVR as part of the initial load from SAP into Snowflake.
In this procedure, all SAP tables reside in a schema called PHYSICAL_TABLES in the SAP_ERP_SHARE database.
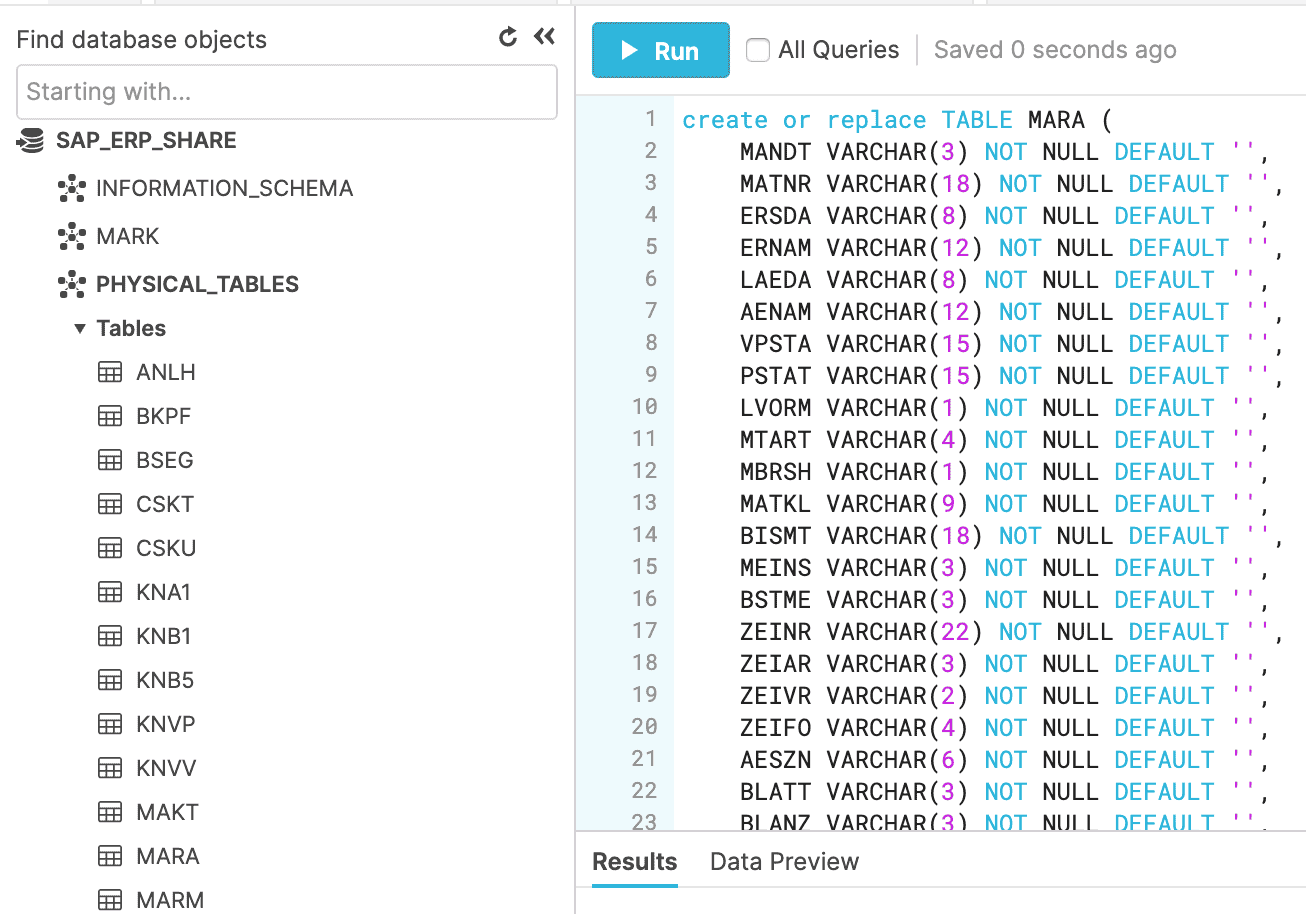
Notice that the tables are loaded into Snowflake as is with all the available columns. This follows an extract and load everything / transform what is necessary model.
Step 2: Build the semantic layer
One of the hardest parts of working with SAP data is understanding what the cryptic table and column names actually mean. Start by creating a semantic layer that translates SAP table and column names to something more meaningful. This requires an understanding of how the table and column translation works. Most SAP SMEs understand this, and if you have access to SAP documentation or an SAP system where you can run SE11, you can build this out on your own.
There are also many websites that do a great job defining this. Personally, I like to use https://www.sapdatasheet.org/ since it has both table and column information as well as an ERD diagram of SAP tables and the various table relationships.
Another great resource is SAP’s HANA Live. If you are familiar with this, you could use the underlying code as a basis for understanding how tables are joined and some of the transformational logic required to build out or model in Snowflake.
For example, the semantic layer for MARA (General Material Data) looks like this in our scenario:
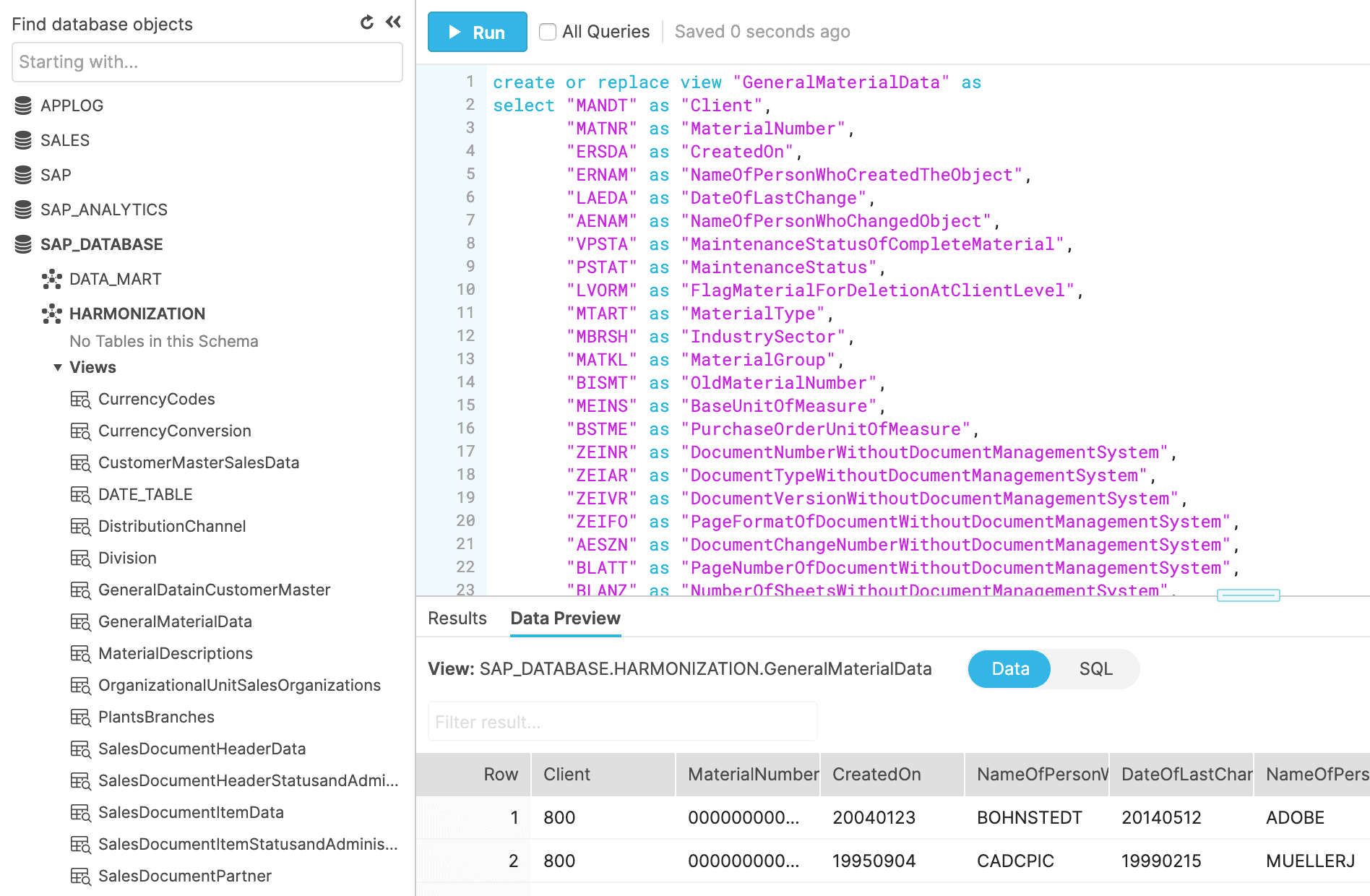
This DDL lives in a schema called HARMONIZATION as a view named GeneralMaterialData. (The table MARA has 236 columns in this example, so not all of them are shown in the figure above). For our purposes, all columns from MARA are included in the semantic layer. This allows downstream processes to access whatever columns they need in a conformed format.
Notice that there are only two things taking place in this statement:
- Translation of MARA to a view called GeneralMaterialData
- Mapping of column abbreviations to English descriptions
The main goal of the harmonization layer is to transform the SAP tables into something meaningful to most people.
Step 3: Build the propagation layer
Now that we have a view with meaningful column names, the next step is to propagate the columns that will be used in the data mart layer and enrich the data if needed.
This can include such things as:
- Handling data type conversions
- Adding calculated columns
- Transforming date fields
- Filtering data
- Performing other miscellaneous transformations
The goal with this step isn’t to perform wholesale transformation. Instead, this step cleans up the data while keeping a 1:1 mapping from the replicated data through the semantic layer and into the clean view.
On top of the GeneralMaterialData view, a view called GeneralMaterialDataActive is created with the following DDL:
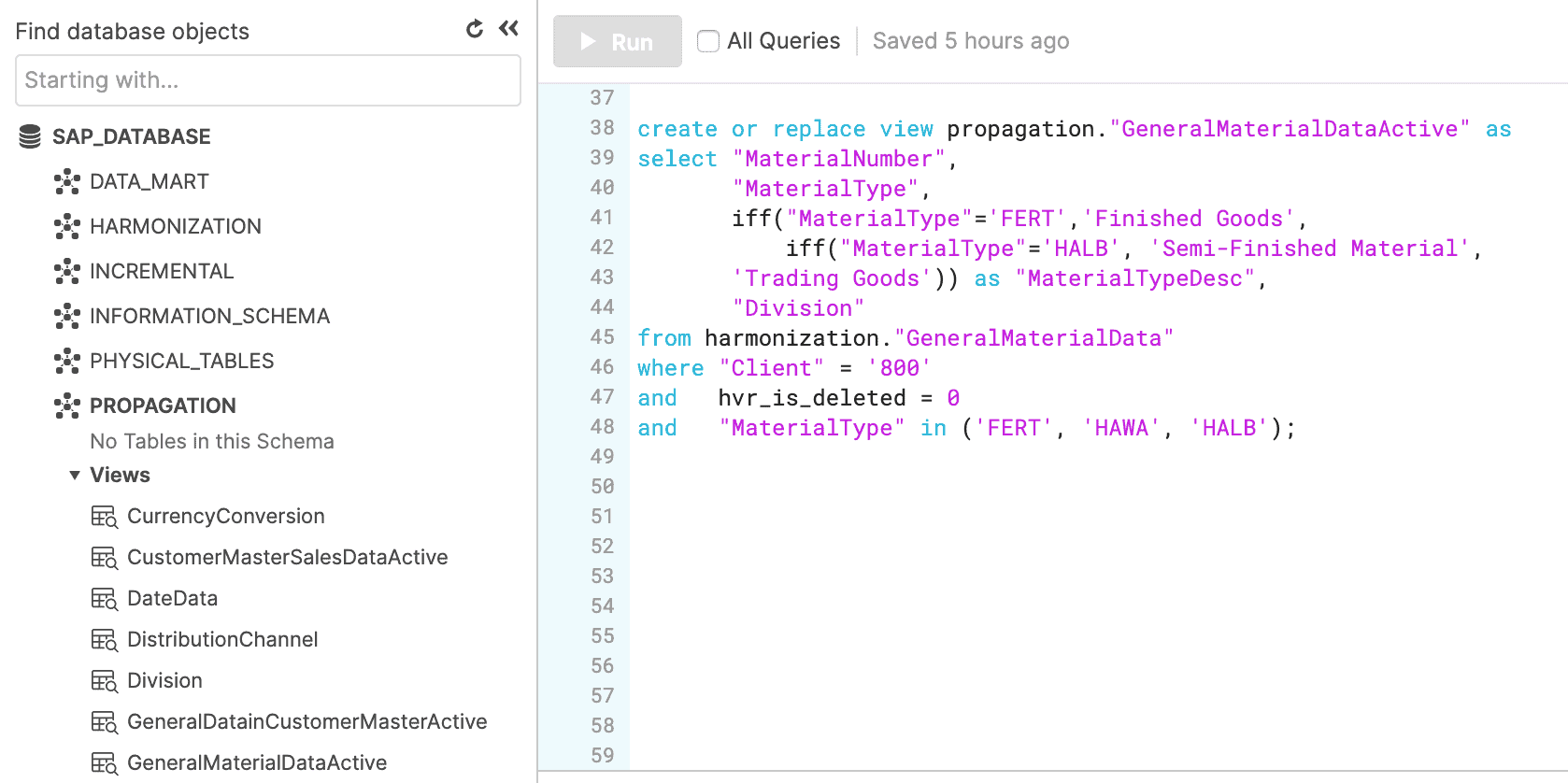
For example purposes, the following actions were included:
- Filtering only for data that hasn’t been deleted
- Filtering on specific MaterialType data
- Filtering on Client 800
- Calculating on MaterialType to provide a description
Step 4: Build the data mart layer
The next layer is the data mart layer. This layer takes data from the propagation layer and processes it into the dimensions or facts that create the dimensional model.
The GeneralMaterialData view is used to create a dimension for product data called SD.ProductDim, shown below.
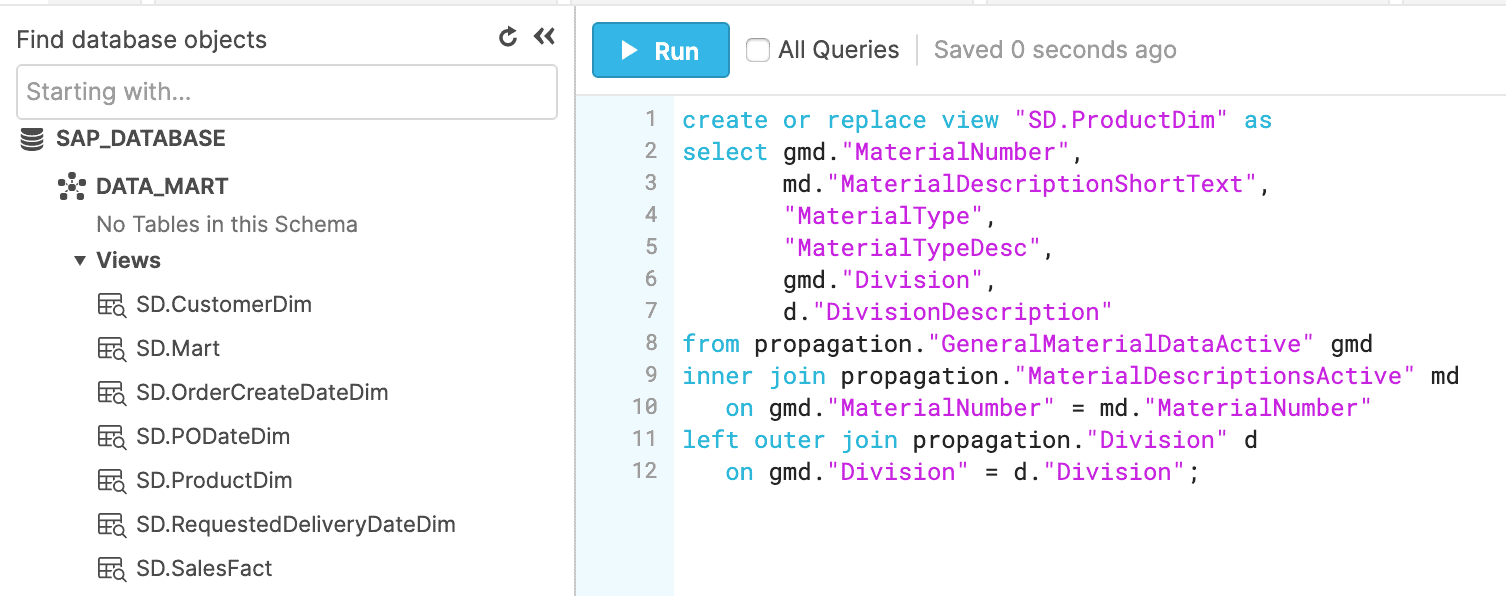
Step 5: Build additional extensions or consume dimensions and facts
At this point, the output of the previous step is a set of dimensions and facts based on the business process being modeled. From here, you can import the dimensions and facts metadata into BI tools to run analytics, materialize the dimensions and facts, or process the dimensions and facts further based on what your end users need.
Note: This blog demonstrated how this works with MARA, but I have run the same steps for many other tables as well with the output shown below. Details will vary based on your specific SAP SD environment, but you can apply the overall concept to SD or any other subject area.

Conclusion
In conclusion, we have run through a simple example to show conceptually how to model data from SAP ERP into Snowflake using HVR to replicate the data into Snowflake and views in Snowflake to transform the data. You can expand on these basic building blocks to build anything you want.
This process isn’t limited to SAP data. For most companies, SAP is just one source of data. You might also be using data from Salesforce, Workday, various manufacturing systems, or homegrown applications. The dimensions you build and facts you derive can include data from any of these sources.
Snowflake can be the data platform for storing all this data in one place so you can view SAP data in the full context of your environment.
Learn more by registering for our webinar: How-To: SAP Data to Snowflake. Co-hosted by Snowflake and HVR, this webinar takes a deep dive into the details about how these two solutions can enable a broader view of your business and real-time decision making.

Mark is the CTO of real-time data replication solution provider, HVR. Mark has a strong background in data replication as well as real-time Business Intelligence and analytics. Throughout his 15+ year career, Mark has expanded his responsibilities from consultant to product management and business development.

Why Marketers Need to Own Their AI Context Layer

Announcing OpenAI GPT 5.6 on Snowflake Cortex AI

Introducing ML Jobs in Snowflake Data Clean Rooms: Collaborative Training and Scoring Across Multiparty Data
