JUL 29, 2025|約6分で読めます
Apache Spark用Snowpark Connect™のパブリックプレビューを開始、お使いのSparkクライアントをSnowflakeでサポート

バージョン3.4では、Apache Spark™コミュニティがSpark Connectを導入しました。クライアントとサーバーを分離したアーキテクチャにより、ユーザーのコードがSparkクラスターから切り離されます。この新しいアーキテクチャにより、Snowflakeウェアハウス内でSparkコードを実行できるようになり、Sparkクラスターのプロビジョニングとメンテナンスが不要になりました。
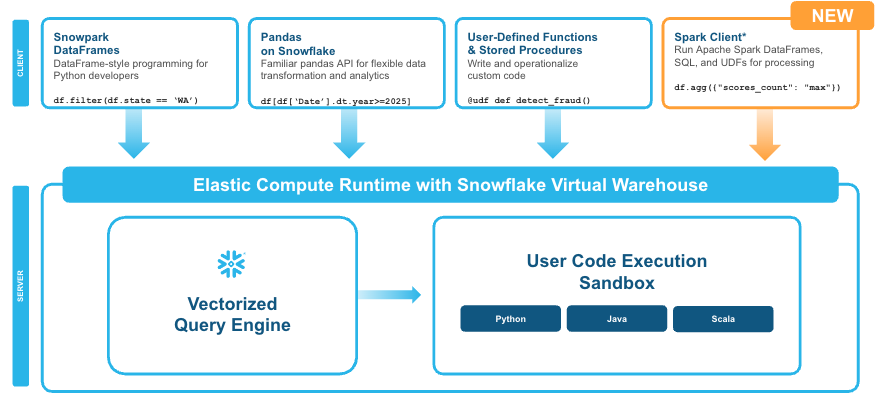
Spark用Snowpark Connectのパブリックプレビュー開始をお知らせします。お客様はSnowpark Connectを使用して、依存関係の管理、バージョンの互換性、アップグレードなど、Spark環境を個別に維持またはチューニングする複雑さを回避しながら、強力なSnowflakeのベクトル化エンジンをSparkコードで活用できます。Snowflakeでは、最新のSpark DataFrame、Spark SQL、ユーザー定義関数(UDF)コードをすべて実行できるようになりました。
Spark用Snowpark Connectは、仮想ウェアハウスでSnowflakeの伸縮性のあるコンピュートランタイムを使用することで、SnowflakeのエンジンのパワーとSparkコードの使い慣れた使用という両方のメリットを提供しながら、コストを削減して開発を加速します。組織では専用のSparkクラスターが不要になります。互換性のあるSpark SQL、DataFrame、UDFを記述して、Snowflakeプラットフォーム上で直接実行できます。Snowflakeはすべてのパフォーマンスチューニングとスケーリングを自動的に処理するため、開発者はSparkの管理に伴う運用オーバーヘッドから解放されます。さらに、データ処理をSnowflakeに持ち込むことで、アップストリームで堅牢な単一のガバナンスフレームワークを確立できるため、冗長な作業なしにライフサイクル全体にわたってデータの一貫性とセキュリティを確保できます。
Snowparkクライアントを使用してPython、Java、Scala言語でデータパイプラインを作成しているお客様は、平均して以下を実現しています。
マネージドSparkと比較してパフォーマンス速度が5.6倍向上
マネージドSparkと比較してコストを41%節約
Spark用Snowpark Connectのリリースにより、Sparkに慣れているユーザーであれば、コードを変換してSnowparkクライアントを使用する必要もなく、またSnowpark Client APIに慣れる必要もなく、Snowpark実行のメリットを得られます。
“VideoAmp has a long history of leveraging both Spark and Snowflake. We've migrated a large portion of our workloads to Snowpark directly, but Snowpark Connect takes us one step further in achieving code interoperability. Having Snowflake meet us where our code already resides is nothing but a clear win and the early results we've seen are extremely promising. The best part is that we didn't have to sacrifice critical engineering time to migrate workloads with Snowpark Connect — they just worked.”
John Adams
SVP of Architecture at VideoAmp
Spark Connectを基盤とした構築
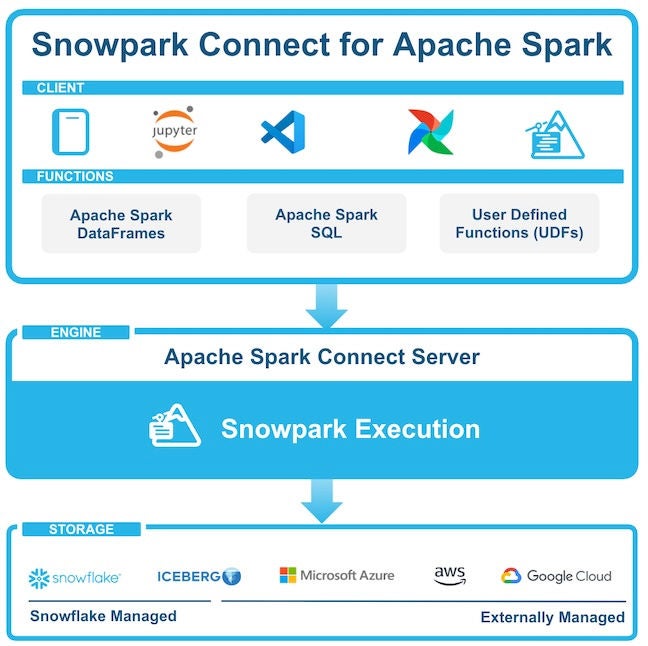
Sparkクライアントとサーバーを分離するSpark Connectのリリースは、あらゆるアプリケーションからSparkを簡単に使用できるように設計されています。Spark Connectを使用する前は、アプリケーションとメインのSparkドライバーを一緒に実行する必要がありましたが、現在は別々に実行できます。お使いのPythonスクリプトやデータノートブックなどのアプリケーションは、未解決の論理プランをリモートSparkクラスターに送信するだけです。これにより、さまざまなツールへのSparkの接続性が向上し、モダンアプリ開発に適合できるようになりました。
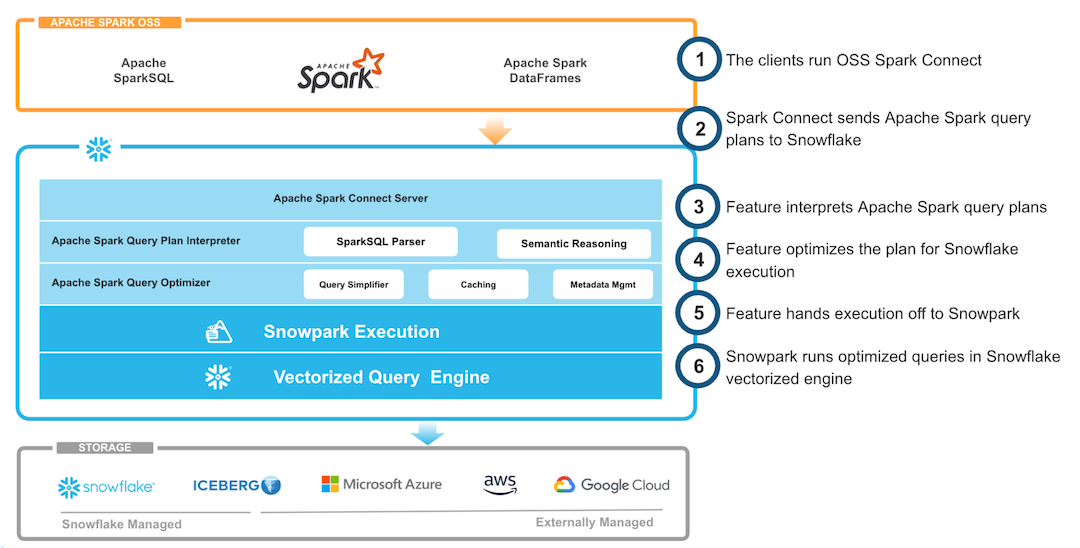
Snowparkはもともと、クライアントとサーバーを分離するという同じ前提で構築されていました。Spark Connectと組み合わせることによって、Snowflakeプラットフォームの使いやすさ、パフォーマンスのメリット、信頼性を、Sparkワークロードに簡単に提供できるようになりました。Snowpark Connectでは、Snowflakeウェアハウス内でSparkコードを実行できます。これにより、負荷の高い作業をすべて実行できるため、Sparkクラスターのプロビジョニングやメンテナンスが不要になります。Snowpark Connectは現在、Spark 3.5.xのバージョンをサポートしているため、これらのバージョンに含まれる機能や改善点と互換性があります。
SnowflakeデータへのSparkコードの取り込み
これまで、Snowflakeを使用している多くの組織は、Sparkコネクタの使用を選択し、SparkコードでSnowflakeデータを処理していました。しかし、このためにデータ移動が発生し、コスト、レイテンシー、ガバナンスが複雑化していました。Snowparkへの移行は、パフォーマンスの改善、ガバナンスの拡大、コストの削減をもたらしましたが、それでも多くの場合、コードの書き換えが必要となり、開発の遅延につながりました。Snowpark Connectにより、組織はデータ移動やレイテンシーを排除しながら、これらのワークロードを見直してコード変換なしにSnowflakeで直接データを処理するという新たな機会を得られます。
オープンデータレイクハウスでの作業
Spark用Snowpark Connectは、外部マネージドIcebergテーブルやカタログリンクデータベースなど、Apache Iceberg™テーブルにも対応しています。これにより、データの移動やSparkコードの書き換えなしに、Snowflakeプラットフォームのパワー、パフォーマンス、使いやすさ、ガバナンスを活用できるようになりました。
開始方法
データがSnowflake内にあるか、Snowflakeからアクセスできるかを試すのは簡単です。Spark DataFrameが現在実行されているSpark Connectクライアント環境を使用し、次のようにSnowflakeと連携することができます。
import pyspark
import os
from snowflake import snowpark_connect
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
from pyspark.sql.functions import to_timestamp, current_timestamp
from pyspark.sql import SparkSession
from pyspark.sql import Row
from pyspark.sql import SparkSession
os.environ["SPARK_CONNECT_MODE_ENABLED"] = "1"
snowpark_connect.start_session() # Start the local |spconnect| session
spark = snowpark_connect.get_session()
spark = snowpark_connect.get_session()
# -------------------------------------------
## Displaying Data from a table in Snowflake which is already available via share
# -------------------------------------------
orders = spark.read.table("SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS")
orders.show(2)
customers = spark.read.table("SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.CUSTOMER")
customers.show(2)
# --------------------------------------------------
## Top 10 Most frequent buyers and their order count
# ---------------------------------------------------
frequent_buyers = orders.join(customers, orders.o_custkey == customers.c_custkey, "inner") \
.groupBy(customers.c_name) \
.count() \
.orderBy("count", ascending=False)
frequent_buyers.show(10)
# # -------------------------------------------------------------------------------------
# 1. Read from the Managed Iceberg Table that you have created in the account using the tutorial
# -------------------------------------------------------------------------------------
iceberg_table = "iceberg_tutorial_db.PUBLIC.customer_iceberg" # Full table name
df = spark.sql(f"SELECT * FROM {iceberg_table}")
# -------------------------------------------
## Display Data
# -------------------------------------------
df.show(5)Snowflake Notebook、Jupyter Notebook、Snowflakeストアドプロシージャ、VSCode、Airflow、Snowpark Submitを通じて、Spark DataFrame、SQL、UDFコードをSnowflake上で実行できるようになりました。これにより、Snowflake、(Snowflake内または外部マネージドの)Iceberg、クラウドストレージの各オプションにおいて、異なるストレージ間でのシームレスな統合が可能になります。
考慮事項と制限事項
Snowpark Connectは現在、Spark 3.5.xのバージョンでのみ動作します。Spark DataFrame APIやSpark SQLのサポートも、このバージョンでのみ有効です。ただし、APIのカバレッジには注意すべき区別があります。たとえば、RDD、Spark ML、MLlib、ストリーミング、Delta APIは現在、Snowpark Connectのサポート対象機能に含まれていません。また、サポートされているAPIについては、Snowpark Connectのドキュメントに記載されているとおり、セマンティックの違いを考慮する必要があります。Snowpark Connectは現在、Python環境のみで利用でき、JavaとScalaのサポートは現在開発中です。
Spark用Snowpark Connectを特集した、特別セグメントのお客様向けのData Engineering Connectにご参加ください。貴社にとって、このソリューションが良い選択だとお考えの場合は、貴社の担当アカウントチームに問い合わせるか、担当チームについて直接弊社までお問い合わせください。カレンダーをマークして、9月10日のウェビナーにご登録ください。この機能について詳しくご紹介いたします。
12022年11月から2025年5月までの期間について、お客様の実稼働ユースケースと概念実証(PoC)の実践におけるSnowparkとマネージドApache Sparkサービスの速度とコストの比較結果に基づきます。調査結果はすべて、実データによる実際のお客様の結果を要約したものであり、ベンチマーク用に作られたデータセットを表すものではありません。
著者

