
FEB 18, 2025|Lettura: 4 min

Nonostante l’avvento di nuovi formati di dati come JSON, Avro e Parquet, l’XML (eXtensible Markup Language) rimane uno standard dati fondamentale nei servizi finanziari. Dai sistemi di core banking realizzati tra gli anni ’90 e 2000 fino al reporting normativo moderno, l’XML è profondamente integrato nel tessuto operativo del settore. Standard come FpML (Financial Products Markup Language) per i derivati, XBRL (eXtensible Business Reporting Language) per il reporting normativo, ISO 20022 per pagamenti e titoli e persino alcune implementazioni del FIX Protocol si basano ampiamente su XML.
Gli istituti finanziari generano, scambiano e inviano regolarmente documenti XML per supportare funzioni critiche quali:
Comunicazioni interbancarie tramite SWIFT
Processi di trading e settlement
Segnalazioni normative in preparazione dello statunitense Financial Data Transparency Act (FDTA) e a enti attuali come SEC, FINRA, ESMA, Federal Reserve, OCC e FDIC
Scambi di messaggi di pagamento
Formati dei file di dati di mercato
Sebbene la rigorosa applicazione degli schemi e la struttura documentale di XML offrano chiari vantaggi per i dati complessi e strutturati, la sfida per i data engineer e i data analyst consiste nel rendere questi dati facilmente accessibili e utilizzabili per i moderni flussi di lavoro di analytics, reporting e integrazione. Storicamente, il parsing di XML richiedeva un’infrastruttura dedicata, risorse di sviluppo specializzate o pipeline di estrazione, trasformazione e caricamento (ETL) personalizzate, con conseguenti ostacoli, costi e ritardi.
Con la recente introduzione delle funzionalità di elaborazione XML native, Snowflake colma il divario tra i formati di dati legacy e le moderne esigenze di analytics, consentendo agli istituti finanziari di sfruttare appieno il valore dei propri dati XML senza sacrificare l’agilità o la scalabilità.
Con Snowflake, le organizzazioni ora possono:
Caricare XML direttamente in Snowflake senza bisogno di pre-elaborazione esterna
Interrogare i dati XML con SQL standard, sfruttando potenti funzioni integrate per la navigazione, l’estrazione e la trasformazione
Integrare XML in modo trasparente con JSON, dati relazionali e analytics su dati semi-strutturati
Applicare governance, sicurezza e data lineage in modo uniforme a dati strutturati e semi-strutturati
Abilitare workload di data science e AI/ML direttamente su data set derivati da XML
Il supporto XML nativo di Snowflake trasforma XML da un formato di archiviazione in silos a un asset attivo e interrogabile, perfettamente integrato con l’ecosistema dell’AI Data Cloud di Snowflake.
Gli istituti finanziari possono ora ripensare i propri flussi di lavoro basati su XML in un’ampia gamma di funzioni mission-critical.
Le organizzazioni possono caricare direttamente in Snowflake la documentazione XBRL, i modelli XML normativi o i documenti da presentare alla SEC. Con il parsing e la trasformazione basati su SQL, i team che si occupano di conformità possono automatizzare la generazione di report, convalidare la documentazione confrontandola con i dati interni e accelerare i cicli di presentazione.
Conferme di trading, eventi del ciclo di vita dei derivati (tramite FpML) e messaggi FIXML possono essere caricati, parsati e integrati nelle pipeline di analytics di trading e del rischio, riducendo la latenza nella riconciliazione e nel reporting.
I messaggi XML ISO 20022 per pagamenti, transazioni in titoli e gestione dei conti possono essere facilmente archiviati, parsati e analizzati in Snowflake. Banche e stanze di compensazione possono arricchire i dati di pagamento, monitorare i flussi delle transazioni e identificare le anomalie senza un’infrastruttura di parsing personalizzata.
Modernizzando l’elaborazione XML all’interno dell’AI Data Cloud Snowflake, gli istituti di servizi finanziari ottengono:
Time-to-insight più rapido: Eseguire il parsing e l’interrogazione di XML rapidamente, senza attendere processi ETL esterni.
Un patrimonio di dati unificato: Combinare dati XML, JSON, Parquet e relazionali in un’unica piattaforma governata.
Sicurezza di livello enterprise: Applicare controlli granulari di accesso, conformità e governance a livello enterprise ai workload XML.
Scalabilità: Scalare automaticamente le risorse di calcolo per il parsing di grandi volumi di file XML.
Condivisione e collaborazione sui dati: Condividere i data set XML analizzati tra i team o con i partner esterni utilizzando le funzionalità di Secure Data Sharing.
Snowflake elimina la complessità tradizionalmente associata ai flussi di lavoro XML, aiutando le società di servizi finanziari a rimanere agili, conformi e basate sugli insight.
La modernizzazione dell’elaborazione XML con Snowflake sfrutta le funzionalità native della piattaforma per archiviare, eseguire il parsing, interrogare e gestire i dati XML semi-strutturati, il tutto utilizzando le familiari funzionalità SQL e native di Snowflake. Snowpark XML fornisce un’esperienza di programmazione ai data engineer che utilizzano Python.
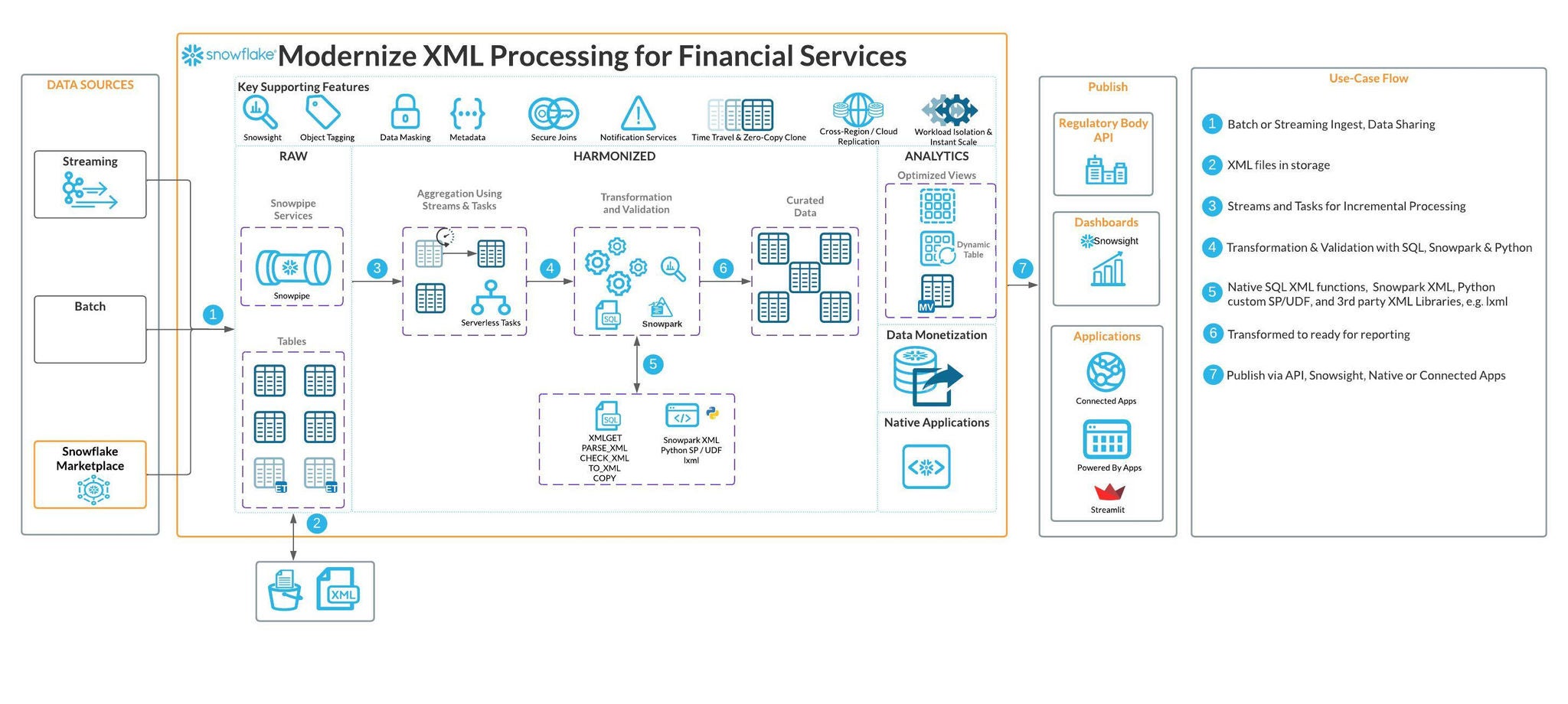
Snowflake tratta l’XML come un dato semi-strutturato attraverso il tipo di dati VARIANT, consentendo una perfetta integrazione nei flussi di lavoro di analytics senza richiedere trasformazioni esterne.
Le funzioni SQL per XML includono:
Parsing XML: PARSE_XML converte il testo XML grezzo in formato VARIANT per l’archiviazione e l’interrogazione.
Recupero degli elementi: XMLGET estrae elementi XML specifici da strutture XML parsate.
Convalida XML: CHECK_XML verifica che le stringhe XML siano ben formate.
Generazione di XML: TO_XML serializza gli oggetti Snowflake ripristinando il formato di testo XML.
Caricamento XML: COPY permette di creare una copia di XML nel tipo di dati VARIANT di Snowflake.
Snowpark XML offre tre vantaggi principali:
Scalabilità per file di grandi dimensioni: Snowpark XML suddivide preventivamente i file XML di grandi dimensioni in blocchi basati su rowTag, consentendo ai clienti di caricare in modo selettivo solo i rowTag necessari nelle tabelle Snowflake, aggirando il limite di dimensione di VARIANT.
Interrogazione più semplice tramite VARIANT: Ogni record XML viene estratto come riga separata e ogni campo al suo interno diventa una colonna separata di tipo VARIANT. Questa struttura consente ai clienti di eseguire query utilizzando la notazione a punti o la funzione FLATTEN, senza concatenare funzioni XML come XMLGET.
API semplice e a passaggio unico: Il caricamento viene avviato tramite un’unica API intuitiva:
df = session.read.option("rowTag", "cik").xml("@mystage/EDGAR_PAID_CMBS_ABSEE_XML.xml")Questi miglioramenti semplificano l’onboarding per gli utenti di Spark e consentono una migrazione più rapida a Snowflake per i workload a elevata intensità di XML.
Oltre al parsing di base, le funzionalità della piattaforma Snowflake consentono di automatizzare, governare e analizzare i dati XML su vasta scala:
Elaborazione automatizzata e caricamento in tempo reale: Usa Tasks, Streams, Snowpipe, Dynamic Tables e Time Travel per creare pipeline event-driven, abilitare il caricamento dei dati in tempo reale, automatizzare gli aggiornamenti e controllare le modifiche storiche ai dati XML, garantendo le informazioni più aggiornate per l’analisi.
Automazione e gestione delle pipeline: Orchestra flussi di lavoro complessi con External Tables, stored procedure, funzioni definite dall’utente (UDF) e Tasks, abilitando pipeline di dati XML flessibili e gestibili.
Sicurezza e governance: Applica Row Access Policies, i criteri di Dynamic Data Masking, la governance basata su tag e Object Dependencies per proteggere i dati XML sensibili e gestire la conformità alle normative finanziarie e sulla privacy dei dati.
Integrazione di data engineering, advanced analytics e machine learning: Estendi i tuoi data set basati su XML con UDF Python/Java e Snowpark e connettili a strumenti di BI e ML per analytics predittiva, rilevamento delle anomalie e visualizzazioni avanzate per accelerare il processo decisionale.
Condivisione dei dati e integrazione API: Condividi in modo trasparente i data set derivati da XML tra gli account Snowflake o integrali con API esterne utilizzando External Functions, Database Replication e distribuzioni multi-regione per una copertura e una resilienza globali.
Per esempi di utilizzo, prova questi quickstart con SQL e Snowpark e scopri come:

