Designing a Modern Big Data Streaming Architecture at Scale (Part One)


Back in September of 2016, I wrote a series of blog posts discussing how to design a big data stream ingestion architecture using Snowflake. Two years ago, providing an alternative to dumping data into a Hadoop system on premises and designing a scalable, modern architecture using state of the art cloud technologies was a big deal. Fast forward to 2018 and it’s time to revisit loading data with some new capabilities.
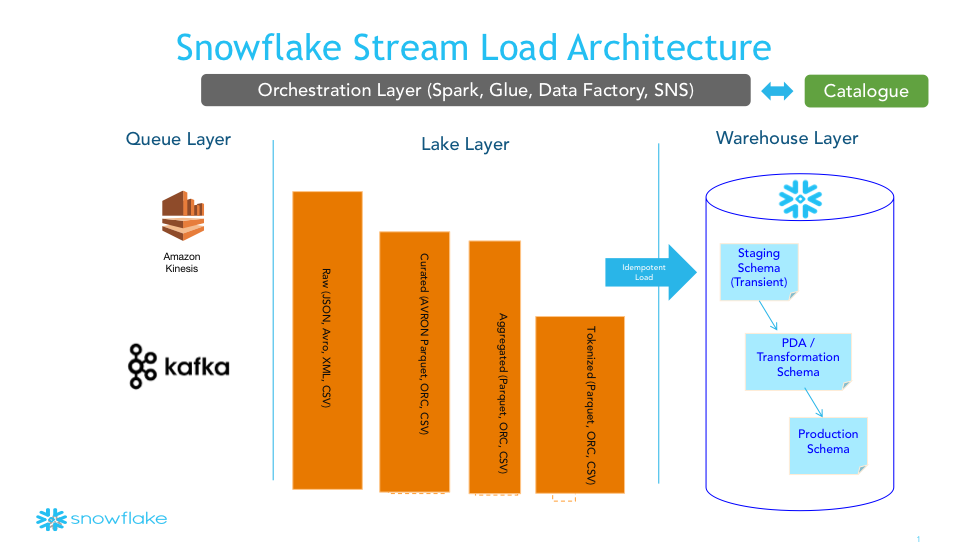
In this two-part post, I’ll start by focusing on scaling the Snowflake architecture to accommodate ingesting higher volumes of data while providing quicker access to data analytics. In the illustration below, note that I have divided the architecture into four major sections:
- The Queuing Layer
- The Lake Layer
- The Orchestration Layer
- The Warehouse Layer
From left to right, the flow provides information for selecting which streaming architecture to follow: Kappa (one stream) versus Lambda (two streams). When working with Snowflake, either Lambda or Kappa will work fine; however, when considering the evolution of Snowflake’s features for high speed/volume data load, Kappa aligns more naturally. By simplifying into a single stream architecture, there is the possibility for fewer layers and a faster time to analytics.
Queue Layer
Whether your data flows in from IOT applications (e.g., sensors or security logs), you’re dealing with massive volumes of data. Very few of the customers I work with throw their data away, which I support. Why? Because retaining data provides a mechanism to manage the ordering of high-volume data sets without losing track of what information has or hasn't been processed. It is also creates the opportunity to perform event-based analytics on the sub sections of the data stream and look for anomalies (or specific conditions) that trigger notifications like a security alert.
With Snowflake, the value of the queue layer comes through its usefulness for controlling the size, format and placement of data in the data lake layer. It’s important to be cognizant of the limitations of the underlying cloud environment, including file size limitations and search conditions (e.g., trying to list 10 million files in a single call). As a best practice, it’s better to load files above 100 Mb and below 1 Gb than it is to load many smaller files for both load and query performance.
Lake Layer
Working with customers gives me the opportunity to observe many different Hadoop and cloud data lake storage implementations. The biggest trend I’m seeing is the advent of “zones” or “layers” in the cloud storage environment. I’ve called out four different zones in the architecture illustration show above, but there really isn’t a limit. The interaction between the lake layer and the warehouse layer requires careful consideration about whether to pursue an ETL or ELT approach. It also requires consideration about what types of analytics and BI tools to employ for accessing the various layers. There are three primary considerations that can impact working in Snowflake:
File type standard
Each zone in the Kappa architecture can accommodate different types of data, with the raw layer typically allowing for almost any data format. As you move across the layers (left to right in the illustration), it becomes important to standardize and apply some type of configuration management so end users know what data is available and how up to date it is.
At this stage, you need to decide which layers you want to load into Snowflake and how to create a lineage (lifecycle) of the data as it moves through the layers. I recommend using a catalogue (see illustration), especially as your data volumes and sources increase. Snowflake can natively ingest JSON, AVRO, XML, Parquet, ORC and CSV/TSV, so if you are looking to get near real time access to your data, loading directly from the raw layer is the way to go.
Load policies
Not all data moves between each layer and data transformation can happen before, during or after loading into a layer. Typically controlled by an Orchestration Layer, Snowflake works with many third party ETL/ELT vendors and Spark implementations to optimize high volume data loads (Terabytes per hour).
Some customers I work with have a policy stating that all data flowing into Snowflake is first persisted in the lake layer. Other customers prefer line of business (LOB) autonomy for loading data with the tool of their choice. Regardless of policies and preferences for tool sets, at this stage you need to consider how frequently you want or need to load data between the lake layers into the warehouse layer, as well as how to retain control over what data to present to end users. Snowflake offers different load options and copy parameters with different latency characteristics, so choose an approach based on your analytic window and specific requirements for keeping historical data.
Load methodology
Load methodology is an area where Snowflake has evolved significantly over the last few years. We now offer Snowpipe, a serverless load service that you can set up without client side code. You can also use it programmatically to auto ingest data from AWS S3 Storage. Auto ingest gives designers the flexibility to use event-based or schedule-based data in a idempotent way, which means whether you load the same file once or a hundred times you get the same result.
Conclusion
Idempotence is a powerful concept that I’ll cover in more detail in the next post (Part Two). I’ll also pick up the thread of this post by delving into the warehouse layer and the various schemas, including PDA /transformation and production schemas, that you can employ for loading data, running analytic queries and preparing data on production for optimal performance. In addition, I'll go over the orchestration layer and provide some advice on which tools to use for setting up workflows.