Loading Terabytes Into Snowflake: Speeds, Feeds and Techniques


Today, Snowflake customers take in massive amounts of data to gain timely insights. However, as data volumes continue to explode, our customers often have questions about the most efficient way to achieve swift and efficient data ingestion.
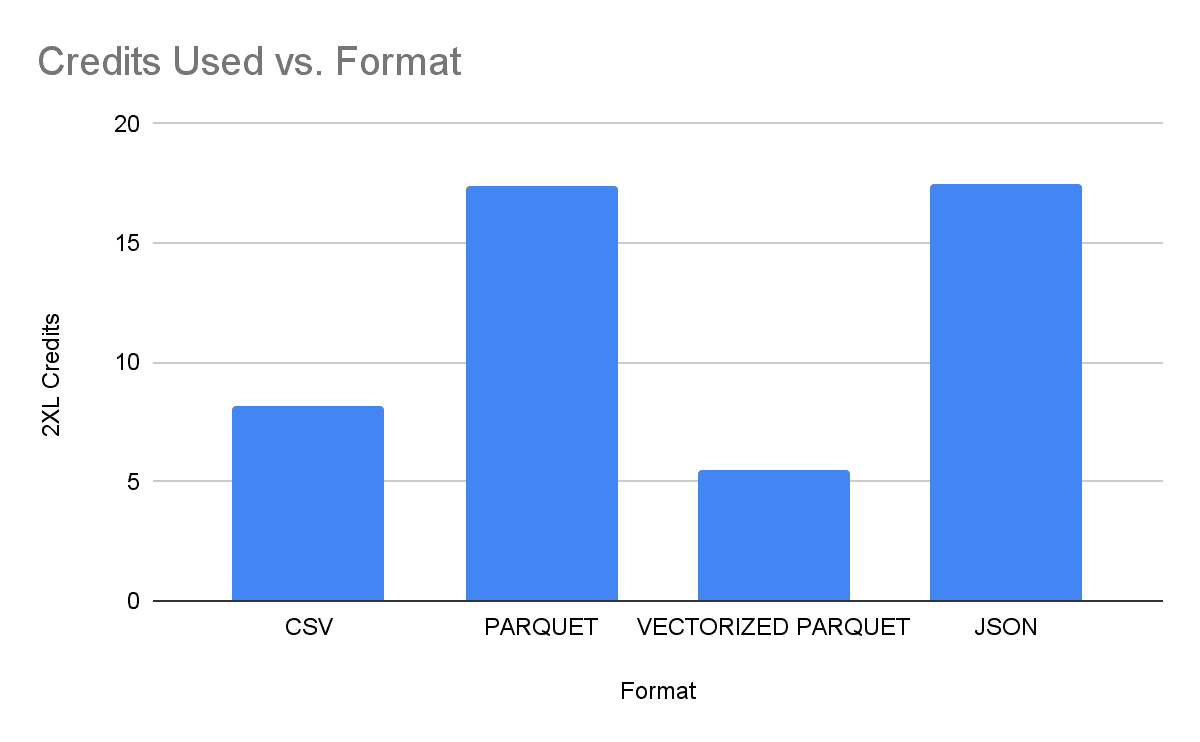
Snowflake has released a new vectorized scanner that was able to improve performance of ingest for Parquet-formatted data by 69% during our testing. This new scanner, which can significantly decrease the time and cost to ingest data into Snowflake, makes Parquet the most efficient format to use when ingesting data into Snowflake — better than CSV and JSON, which have also seen performance improvements. However, since time to ingest is just one aspect of the overall data pipeline, it is recommended to use the format of your source data without complex conversions, as Snowflake continuously improves its ingestion capabilities.
Tests were done by loading the data from the SNOWFLAKE_SAMPLE_DATA.TPCDS_SF10TCL.STORE_SALES table into a new table using several popular formats.
| Format | Compression | Total Time (sec) | 2XL Exec Time (sec) | 2XL Credits |
|---|---|---|---|---|
| CSV | zstd | 1,063 | 926 | 8.2 |
| Parquet | snappy | 2,022 | 1,959 | 17.4 |
| Vectorized Parquet | snappy | 626 | 614 | 5.5 |
| JSON | zstd | 2,057 | 1,972 | 17.5 |
Table 1. Time and credits needed to ingest STORE_SALES table.
As Figure 1 and Table 1 show, the new vectorized scanner is not only faster but also more efficient than any other format.
The total time includes cloud services — which compiles the SQL, lists the blob store for files to ingest and plans the execution — along with warehouse execution time. Since Snowflake bills separately for cloud services and warehouse time, we are including both numbers. Most of the time, cloud services time fits in the free allocation of credits. The 2XL warehouse that was used in this test is billed by the second, after the first minute, at 32 credits per hour.
Many tests were run, but the most notable results were obtained in the Parquet tests. The pattern shown in the Parquet tests can be used to recreate all other tests in the charts.
Parquet testing and results
Parquet is the fastest growing format for big data. For this test we wanted to compare the new vectorized scanner to our standard scanner. Note the new vectorized scanner cannot be used for all use cases yet; view the documentation for differences between the standard scanner and the new vectorized scanner.
Loading to a Snowflake table with the standard scanner
Data was unloaded to an internal stage in Parquet format and loaded using the Parquet scanner. The total time for COPY loading Parquet files was 2,022 seconds, using 1,959 seconds on a 2XL warehouse. This was an incredible improvement of 35% over our previous testing without leveraging the vectorized scanner.
CREATE OR REPLACE STAGE PARQUET_TEST;
COPY INTO @PARQUET_TEST FROM
SNOWFLAKE_SAMPLE_DATA.TPCDS_SF10TCL.STORE_SALES
FILE_FORMAT = (TYPE=PARQUET COMPRESSION=SNAPPY)
MAX_FILE_SIZE = 32000000
HEADER=true
DETAILED_OUTPUT=true;
COPY INTO PARQUET_TEST_RESTORE
FROM @PARQUET_TEST
FILE_FORMAT=(TYPE=PARQUET)
match_by_column_name = case_sensitive;Loading to a Snowflake table with the vectorized scanner
To use the vectorized scanner we can set USE_VECTORIZED_SCANNER in the COPY. This currently needs to be manually set but will be the default scanner in the future.
Doing the same COPY with the vectorized scanner resulted in a load time of 626 seconds, using 614 seconds on a 2XL warehouse cluster. Our optimizations have made Parquet ingestion 80% faster than our previous Parquet testing and 69% faster than our current performance using the standard scanner!
CREATE OR REPLACE STAGE PARQUET_TEST;
COPY INTO @PARQUET_TEST FROM
SNOWFLAKE_SAMPLE_DATA.TPCDS_SF10TCL.STORE_SALES
FILE_FORMAT = (TYPE=PARQUET COMPRESSION=SNAPPY)
MAX_FILE_SIZE = 32000000
HEADER=true
DETAILED_OUTPUT=true;
COPY INTO PARQUET_TEST_RESTORE
FROM @PARQUET_TEST
FILE_FORMAT=(TYPE=PARQUET USE_VECTORIZED_SCANNER=TRUE)
match_by_column_name = case_sensitive;Performance comparison to June 2018
| Source Format | 2018 Total Time (sec) | 2024 Total Time (sec) | 2024 Execution Time (sec) | Improvement % |
|---|---|---|---|---|
| CSV (Gzip) | 1,104 | 1,065 | 944 | 4% |
| Parquet (Snappy, vectorized) | 3,095 | 626 | 614 | 80% |
Table 2. Improvement in time to ingest STORE_SALES data from testing in 2018 to 2024.
Our platform improvements over the last few years have made all of the above formats more efficient, most notably Parquet when vectorization is possible.
Conclusion
At Snowflake, we're on a continuous quest to enhance performance, with a particular focus on accelerating the core database engine, and we are proud to deliver these performance improvements through our weekly releases. In this blog post, we covered performance optimizations that are broadly applicable and highly impactful.
Any pipelines that are using Parquet today should be evaluated to see if they could benefit from the new vectorized scanner, which is now generally available to all customers.
To learn how Snowflake measures and prioritizes performance improvements, please read more about the Snowflake Performance Index here. For a list of key performance improvements by year and month, visit Snowflake Documentation.
