Partner Solution
Data Exploration & Analysis using Hex and Snowpark
Hex Staff
Overview
This solution architecture shows how to use Snowpark dataframes to analyze 20 million rows of Citibike dataset using Hex notebooks.
- Create Snowpark session to read data from Snowflake account in Hex notebook
- Use Snowpark dataframe API to run aggregations on the dataset
- Visualize the dataframe in Hex notebooks
Solution Architecture: Snowpark for Data Exploration with Hex
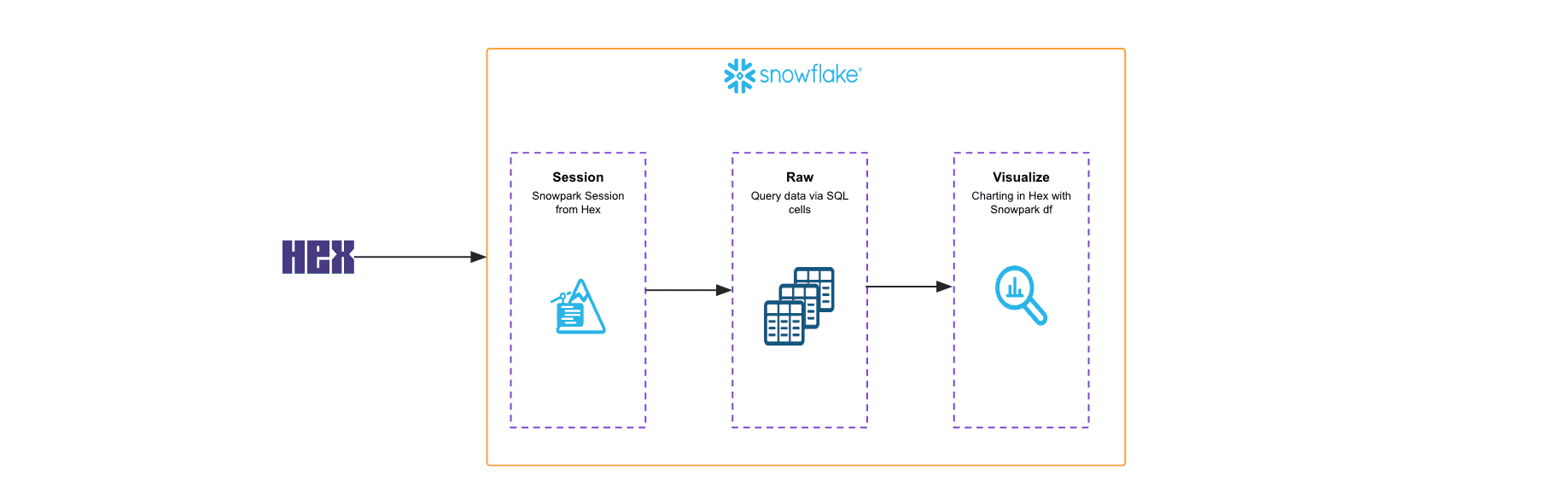
- In this use-case, you learn how to run data exploration and analysis using Snowpark dataframes in Hex notebooks.
- You will also learn how to visualize the dataframes in Hex.
Get Started
Updated 2026-04-28
This content is provided as is, and is not maintained on an ongoing basis. It may be out of date with current Snowflake instances