Partner Solution
Build LLM Apps with Snowpark Container Services and NVIDIA
NVIDIA Staff
Overview
This solution architecture helps you understand how to build an LLM app powered by Snowpark Container Services and NVIDIA NeMo Inference Service (NIM)
- Download an open source foundation model such as Mistral-7b-instruct from HuggingFace
- Shrink the model size to fit in a smaller GPU (A10G->GPU_NV_M) for inference
- Generate a new model using a model generator on NIM Snowpark container
- Publish Mistral Inference App as internal Snowflake Native Application, that uses Streamlit for the app UI
Solution Architecture: LLM App Powered By NVIDIA on Snowpark Container Services
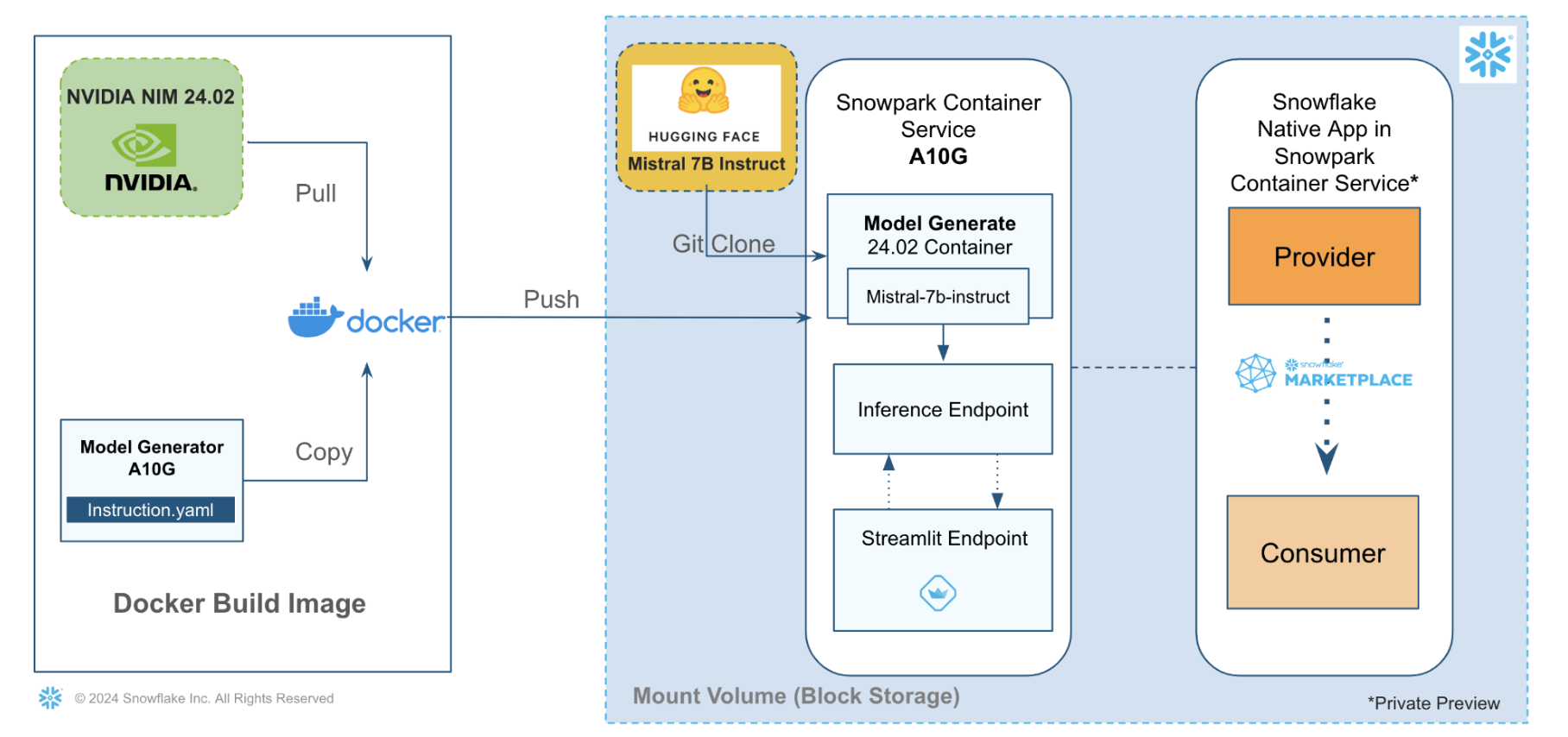
- In this use-case, we leverage Snowpark Container Services to run a Model Generator container. It downloads the Mistral-7b-Instruct from HuggingFace and shrinks it using NVIDIA NIM,
- We build a Streamlit app for the model inference endpoint for the Model Generator
Get Started
Updated 2026-04-29
This content is provided as is, and is not maintained on an ongoing basis. It may be out of date with current Snowflake instances