

AIの台頭により、あらゆるアーキテクチャの決定が試練に立たされています。データが存在する場所でチームがデータにアクセスして活用できない場合、データはコピーされます。その結果、パイプラインが乱立し、ガバナンスが断片化し、コストが膨れ上がります。さらにAIエージェントは、本来必要とするガバナンスが効いたセマンティクスが豊富なデータではなく、古く分断されたデータに基づいて推論を行うことになります。
オープンなレイクハウスは、全員にシングルプラットフォームを強制することなく、データの断片化を解決することを約束しました。しかし、ほとんどの組織にとって、ガバナンスやセマンティクスの断片化に対処できるようになる前に、フォーマットが先行して導入されてしまいました。しかし、今日からは違います。Apache Iceberg™、Apache Polaris™、Open Semantic Interchange(OSI)を基盤として構築されたSnowflakeの相互運用可能なレイクハウスが一般提供されました。これにより、データがどこにあってもロックインされることなく、ガバナンスが効いた単一のデータコピーに接続、アクセス、管理、操作するための新しいブループリントが提供されます。ベンダーではなくデータ所有者にコントロールを取り戻すことで、データに対する主体性を確立できます。その過程でアーキテクチャのコストを削減し、すべてのAIイニシアチブを真に信頼できる基盤に根付かせることが可能になります。
データをその場で活用
データに対する主体性は、接続されたデータファウンデーションから始まります。これは、データをコピーすることなく、あらゆる操作のためにすべてのデータセットを1か所で活用できる場所です。今回のリリースにより、Snowflakeはアクセスのすべてのレイヤーにわたってそのファウンデーションを進化させます。SnowflakeによるApache Iceberg v3のサポートが一般提供され、本番環境で利用可能になりました。これにより、プラットフォーム全体に深く統合された、現在市場で最も幅広いv3機能セットが提供され、より高い相互運用性が実現します。Apache Iceberg™テーブル向けのSnowflakeストレージにより、マネージドIcebergをCREATE TABLEと同じくらい簡単に利用できます。ゼロコピー統合により、セマンティクスを維持したまま、記録システムをファウンデーションに取り込むことができます。Horizon Contextは、ビジネス定義を統合し、すべてのチームとAIエージェントをつなぎます。より多くのデータを。より多くのコンテキストを。ガバナンスが効いた唯一のデータコピーを実現します。
Apache Icebergはもともと巨大な分析データセット向けに設計されていましたが、半構造化データ、小規模な更新、地理空間アナリティクス、変更追跡パイプラインを伴うワークロードに対するサポートは最適ではありませんでした。Apache Iceberg v3は、そのギャップを解決します。本日より、Snowflakeは最も幅広いv3機能を本番環境に提供します。これには、半構造化データ向けのVARIANTサポート、エンジン間の変更追跡のための行リネージ、パフォーマンスの高い行レベルの削除を実現する削除ベクトル、高頻度のテレメトリや財務ワークロード向けのナノ秒タイムスタンプ、デフォルト値、地理空間型が含まれます。これにより、より多くのワークロードで相互運用性への明確な道筋が開かれます。
しかし、優れたフォーマットであっても、ストレージ管理の運用上の負担がなくなるわけではありません。Apache Iceberg™向けSnowflakeストレージテーブルは、AWSとAzureで一般提供されており、Google Cloudでもまもなくプライベートプレビューが開始されます。これにより、最初からオープンで、Horizonカタログを通じてガバナンスが効き、Iceberg互換のあらゆるエンジンで読み書き可能な、フルマネージドのIcebergエクスペリエンスが提供されます。Azureで独自のストレージを管理しているチーム向けには、Azure DFSサポートが一般提供されており、ネイティブのAzure Data Lake Storage Gen2エンドポイントを通じて完全な相互運用性を提供します。
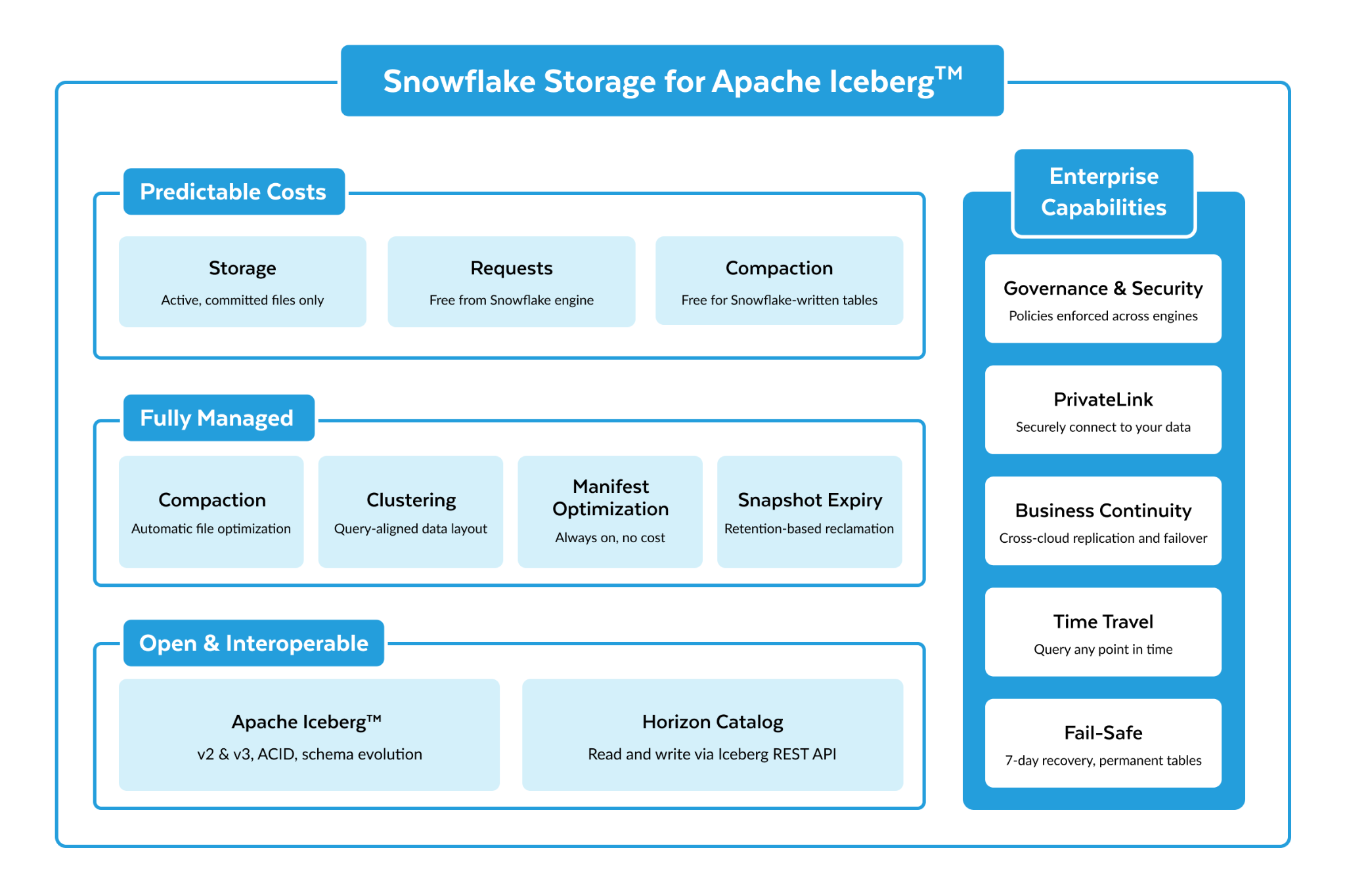
既存のデータを取り込むために、移行や変換が必要になるべきではありません。Parquet Direct(プライベートプレビュー中、まもなく一般提供予定)を使用すると、既存のParquetファイルをIcebergクラスのパフォーマンスでクエリできるようになります。Google Cloudレイクハウス統合が一般提供されました。これにより、自動テーブル検出とクロスクラウドでの読み書きアクセスを備えた、Googleのクロスクラウドレイクハウス環境向けのカタログリンクデータベースが作成されます。外部でマネージドされるIceberg向けのジャストインタイムリフレッシュ(プライベートプレビュー中)は、クエリの実行時に古いメタデータを検出し自動的にリフレッシュするため、スケジュールされたリフレッシュを設定する必要がなくなります。
エンタープライズプラットフォームは、最も価値のあるエンタープライズデータが存在する場所であり、パイプラインの負担が常に最も重い場所でもあります。ゼロコピー統合により、ETLパイプラインやセマンティックコンテキストの再構築を必要とせずに、重要なビジネスデータをSnowflakeエコシステム内でほぼリアルタイムに利用できるようになります。これらは現在、SAP(一般提供)、Salesforce、Workday(プライベートプレビュー)向けに提供されています。さらに、AVEVAおよびIBMとの新たなパートナーシップにより、このモデルはさらに拡張されます。AVEVA CONNECTからのオペレーショナルテクノロジーと産業データ、そしてIBMからのエンタープライズデータプラットフォームが加わることで、ビジネス定義とコンテキストが統合され、より一貫性のあるAI-readyなデータが実現します。
システムが接続されているからといって、必ずしも意味が接続されているとは限りません。定義自体が1つの接続されたレイヤーに存在しない限り、収益、チャーン、顧客数は、3つの異なる場所で3つの異なる意味を持ち続けます。Horizon Contextは、まさにそのレイヤーです。データベース、データレイク、BIツールに分散しているビジネス定義をリンクさせることで、Snowflakeの内外のすべてのチーム(およびAIエージェント)が、エンタープライズの真実の同じ定義に基づいて推論できるようにします。PostgreSQL、Microsoft SQL Server、Tableau、Microsoft Power BI、dbtなどの外部データベース、BI、データパイプラインシステムに接続し、スキーマ、クエリログ、ダッシュボード定義などでメタデータを強化します(プライベートプレビュー中)。Horizon Contextは、統合された一連の機能を通じてこのファウンデーションを実現します。
- すぐに使えるコネクタ:PostgreSQL、Microsoft SQL Server、Tableau、Microsoft Power BI、dbtなどのツールに接続し、クエリログ、人気度、スキーマなどの豊富なコンテキストを多数のソースから収集して、検索可能な1つのカタログにまとめることができます。
- エンドツーエンドの列レベルのリネージ:データアセットが互いにどのように関連しているかを理解する上で、リネージは重要な役割を果たします。Horizon Contextは、Snowflakeや外部データベースのクエリログ、BIシステム、OpenLineageフィードからリネージ情報を抽出し、それらをすべてつなぎ合わせて、完全なエンドツーエンドのリネージグラフを作成します。
- プライベートプレビュー中のSemantic Studioは、Snowflake Workspaces内のAI支援型IDEです。これにより、チームはSQLの専門知識がなくても共有ビジネスロジックを定義、テスト、公開できます。また、Snowflake CoCoとの統合や、バージョン管理のためのGit同期も備えています。
- Semantic View Autopilot(一般提供)は、既存のクエリパターンを分析してセマンティックビューを自動的に生成および改良し、データや用途の進化に合わせてコンテキストレイヤーを常に最新の状態に保つことができます。CoCoは、検索、SQL生成、複雑な分析のためのビジネスコンテキストを取得できるようになりました(一般提供)。
- そして、Open Semantic Interchange(OSI)を通じて、これらの定義はSnowflakeの枠を超え、54社の参加ベンダーと公開された仕様を伴う、より広範なBIおよびAIエコシステムへと広がります。
データへの質問は、シンプルに機能するべきです。相互運用可能な基盤が連携して機能することで、それが実現します。Agentic Queries(一般提供)を使用すると、チームはSnowflake、データレイク、および外部リレーショナルシステム(プライベートプレビュー)全体に対して、自然言語で質問できるようになります。Horizon Contextは、ガバナンスの効いた回答をほぼ瞬時に返します。
これはほんの始まりにすぎません。オープンフォーマットを含む共有データも、同様に対話型であるべきです。パブリックプレビュー中のAuto-gen Agents for Data Shares and Listingsは、手動での開発を必要とせず、あらゆるデータリスティングやセキュアなデータ共有からセマンティックビューとエージェントを瞬時に生成します。次に、パブリックプレビュー中のCortex Agent Sharingが、マーケットプレイスを通じて、社内チーム、パートナー、またはより広範なエコシステムに対して、Snowflakeアカウント全体にそのエージェントを展開します。これらの機能を組み合わせることで、対話型のエクスペリエンスを通じて、同じガバナンスの効いたデータセットの新たなオーディエンスとユースケースが開拓されます。コンシューマーは、共有データと自社のファーストパーティデータを組み合わせて、より豊富なインサイトを得ることもでき、これらはすべて標準でガバナンスが適用されます。
普遍的なガバナンス
データをその場で処理するだけでは、問題の半分しか解決しません。そのための構築を始めた瞬間に、より大きな問題が明らかになります。それは、誰が、どこで、どのようにデータをガバナンスするかということです。マルチカタログ環境では、ポリシーが断片化します。マルチエンジンアクセスは課題を増大させ、回避策を講じるたびにデータに対する主体性が損なわれます。1つのユニバーサルカタログでアクセスポリシーを1回設定するだけで済むとしたらどうでしょうか。Icebergエコシステム全体の接続に役立つ、Horizonカタログ(Apache Polaris™ベース)の新機能を発表いたします。これにより、SnowflakeマネージドのIcebergだけでなく、環境内のすべてのIcebergテーブルをガバナンスできるようになります。Horizonで設定されたユニバーサルガバナンスは、すべてのIRC互換エンジンで尊重され、ロックインもありません。
これは、本番環境に対応した相互運用可能な基盤を提供することから始まります。Horizonカタログでは、外部エンジンからの読み取りおよび書き込みアクセスの両方が一般提供されました。これにより、Iceberg RESTプロトコルで定義されたオープンなセキュリティメカニズムである発行済み認証情報を介して、SnowflakeマネージドのIcebergテーブルに対する完全な双方向の相互運用性が提供されます。Spark、Trino、PyIceberg、およびその他の互換性のあるエンジンは、Snowflakeユーザーが使用するのと同じ、ガバナンスの効いたコピーに対して読み取りと書き込みを行うことができます。1つのカタログ、1つのポリシーセットにより、好みのエンジンの使用とガバナンスポリシーの一元管理の間でトレードオフが生じることはありません。
ほとんどの企業が複数のカタログを所有している場合、統一されたガバナンスコントロールを設定するにはコストと手間がかかります。ユニバーサルガバナンスを実装するには、コストのかかる移行を行うか、すべてのカタログでガバナンス、監査、監視のコントロールを重複させて、複雑さと運用コストをデータチームに押し付けるかの選択を迫られます。このような選択を強いられることで、データに対するコントロールが損なわれます。昨年、データをその場で処理するという原則に基づき、Snowflakeからすべての外部Icebergテーブルを自動的に検出し、セキュアに読み書きするためのカタログリンクデータベース(一般提供)をリリースしました。本年は、その原則を拡張して、その場でのデータのガバナンスを含めることで、強制的な移行の必要性を排除します。現在プライベートプレビュー中ですが、読み取りと書き込みの両方の操作に対してHorizon Iceberg REST Catalog APIを使用して、これらの外部Icebergテーブルへのセキュアなエンジンアクセスを管理できるようになり、HorizonカタログがすべてのIcebergテーブルのユニバーサルガバナンスレイヤーへと進化しています。あらゆるエンジンからのすべての操作に対する包括的なガバナンス機能、監査、およびオブザーバビリティを1か所で得ることができます。
カタログが断片化するもう1つの一般的な理由は、きめ細かいアクセス制御が単一エンジンに関連付けられたカタログに限定されていることです。この制限により、データチームにとってマルチエンジン環境を管理する運用上の負担が増大し、ポリシーの設定ミスによるデータ漏洩のリスクが高まります。今回、Iceberg REST Scan Plan APIのサポート(プライベートプレビュー)により、この制限が排除されます。この機能により、きめ細かいアクセスポリシーがクエリの実行場所を問わずデータに適用されるため、SnowflakeマネージドのIcebergテーブルに対してHorizonカタログで定義された行アクセスポリシーとダイナミックデータマスキングポリシーを、外部エンジンからのアクセス時にも適用できるようになります。最後に、新しいSnowflake Connector for Apache Spark(一般提供)は、すでにSparkを実行しているチームに対してこれらのポリシーを適用し、本番環境ですぐに利用できるソリューションを提供します。
オープンなデータシェアリングの適用範囲を拡大し、お客様がカタログリンクデータベースを使用してフェデレーションカタログを共有(まもなく一般提供)できるようにしています。また、オープンなデータシェアリングが強化(パブリックプレビュー)され、Snowflakeアカウントがなくても、IRC互換の外部エンジンであればすべてのデータ共有をコンシュームできるようになったことも発表いたします。これら2つの機能を組み合わせることで、お客様は任意の外部エンジンを使用して、Horizonを通じてアクセス可能なあらゆるオープンテーブルフォーマットにセキュアにアクセスできるようになります。
接続自体がセキュアであるため、ポリシーは適用されたままになります。外部カタログおよびストレージへのプライベートリンクが一般提供され、Snowflakeが外部レイクに接続する際にデータがパブリックインターネットに公開されるのを防ぎます。
これが機能するのは、基盤となる標準がオープンであるためです。Apache Polarisは現在、Apache Software Foundationのトップレベルプロジェクトとなっており、SnowflakeのエンジニアはScan Planning APIの仕様をApache Icebergプロジェクトに提供しました。ユニバーサルガバナンスは、単なるSnowflakeの機能ではなく、エコシステムのソリューションとなります。
標準でエンタープライズ対応
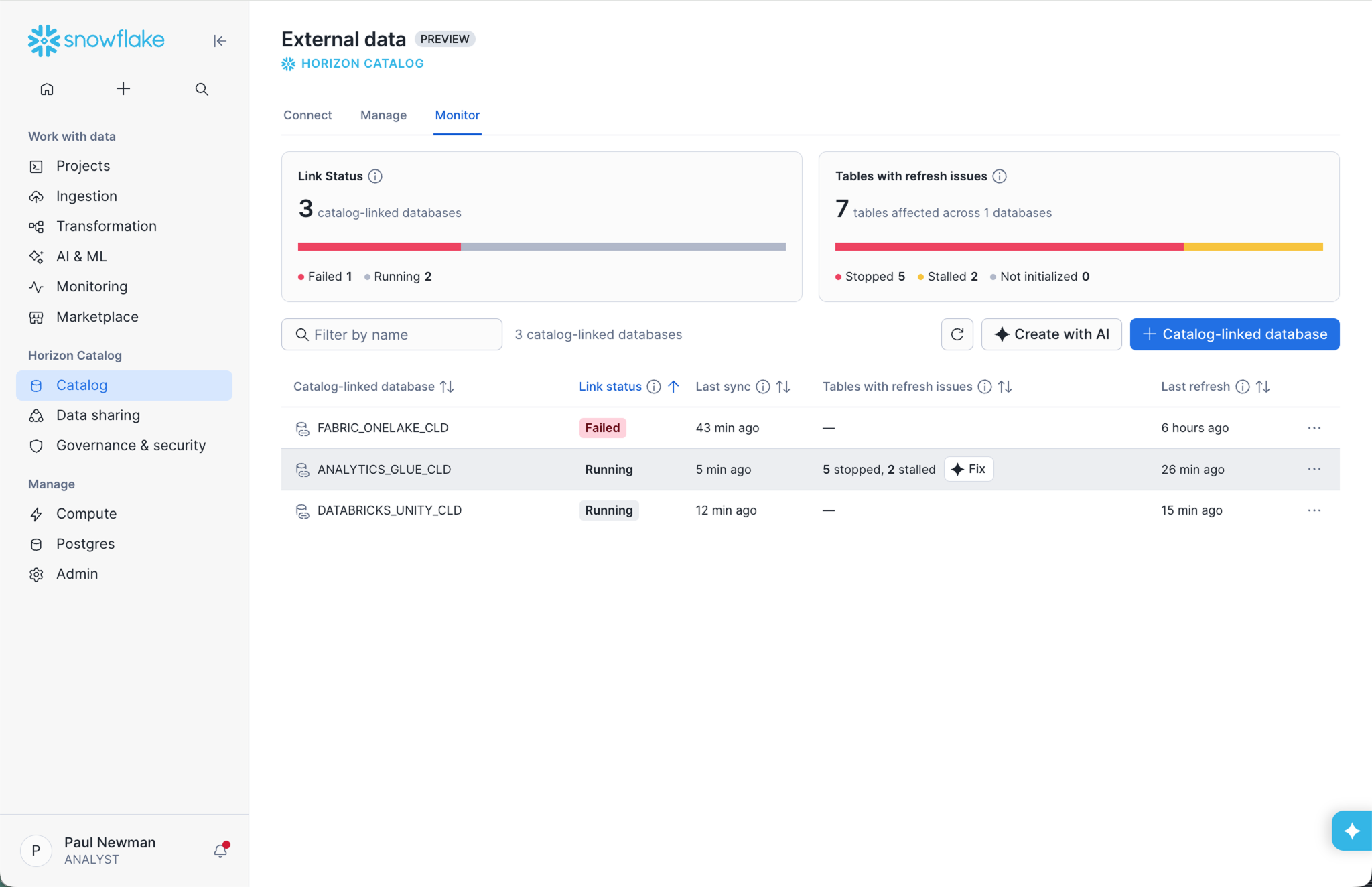
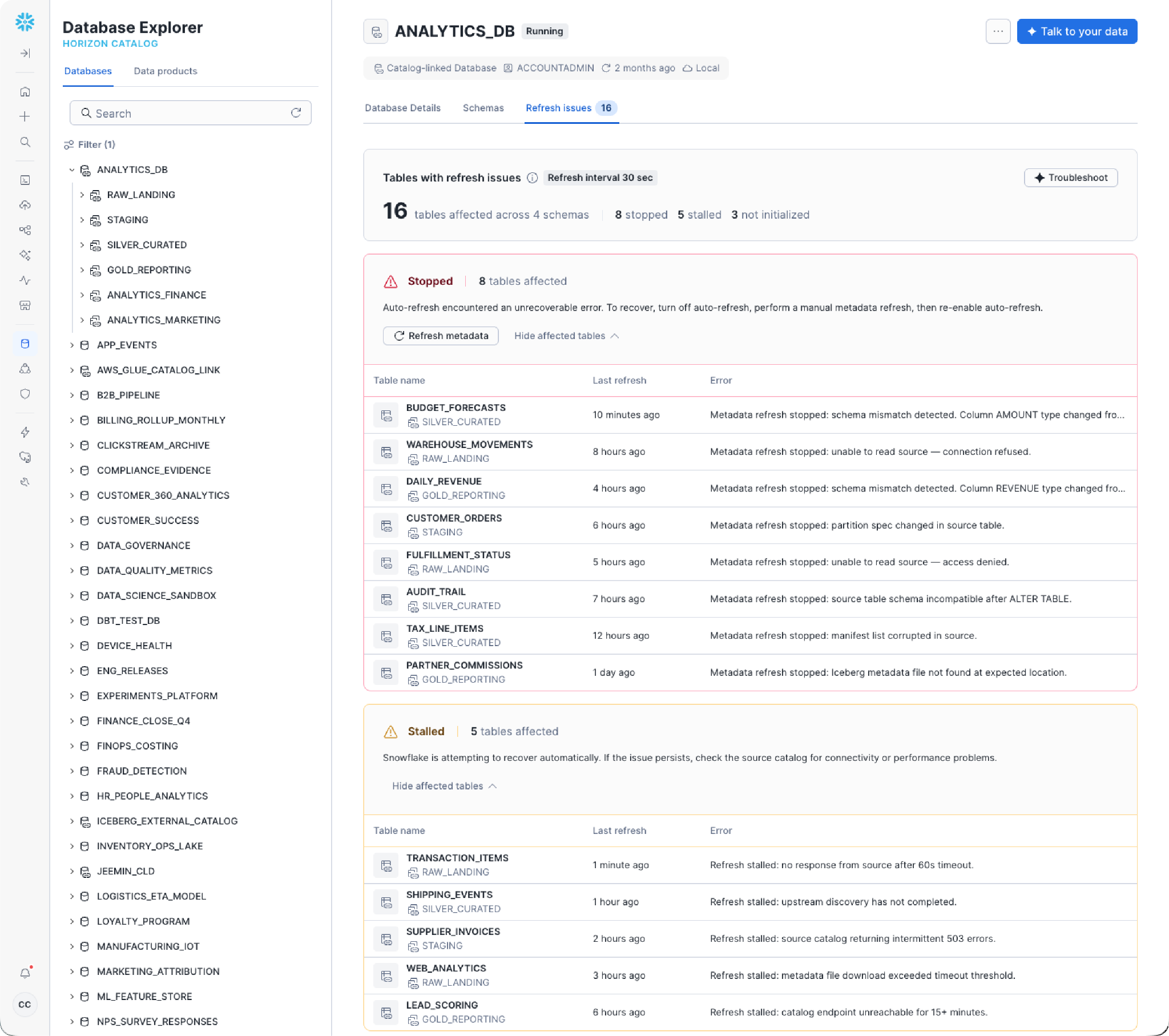
データを所定の場所で操作し、包括的なガバナンスを適用することが、このアーキテクチャの基本です。それを本番環境で運用するのは、お客様のチームの責任です。ほとんどのレイクハウスアーキテクチャでは、その責任がアーキテクトに委ねられます。たとえば、ヘルスチェックの計装、複数エンジン間での監査ログの照合、後付けのレジリエンスなどです。今日では、その運用上の負担はなくなります。プライベートプレビュー中のアクセス履歴における包括的な監査機能は、すべての外部エンジンの操作をSnowflakeのアクセス履歴内に直接記録します。これにより、コンプライアンスチームやセキュリティチームは、使用されたエンジンやアクセスされたテーブルに関係なく、ユーザーレベルでのすべてのテーブル操作に関する単一の統合された記録を取得できます。プライベートプレビュー中の、カタログ統合データベース内の外部マネージドIcebergテーブルに対する運用ヘルスモニタリング機能により、鮮度やリフレッシュの問題が本番環境に影響を及ぼす前に把握できます。さらに、まもなく一般提供されるマネージドIcebergレプリケーションにより、このオープンな基盤はデフォルトで障害に対するレジリエンスを備えるようになります。統合プロジェクト不要でエンタープライズ対応を実現
コンプライアンスチームはこれまで、複数のエンジン間で監査ログを照合する必要がありました。プライベートプレビュー中のアクセス履歴における包括的な監査機能は、すべての外部エンジンの操作をSnowflakeのアクセス履歴内に直接記録するため、このような作業は不要になります。すべてのアクセスイベントは、誰が、いつ、どこで、何にアクセスしたかという、単一の信頼できる記録として保存されます。アーキテクトは、1か所で監査に対応できます。
プライベートプレビュー中のSnowsightのIceberg Health Insightsは、プラットフォームチームに外部マネージドIceberg環境の統合された運用ビューを提供します。これにより、クラウドコンソールを切り替えたりカスタムモニタリングを構築したりすることなく、自動リフレッシュのステータス、テーブルの検出、鮮度のシグナルを確認できます。カタログ統合データベースで古いメタデータが検出されたり、リフレッシュパイプラインが停止したりした場合でも、チームはそれを1か所で確認し、下流のクエリが古い結果を返す前に解決できます。この機能が一般提供に向けて拡張されるにつれて、Iceberg環境全体(Snowflakeマネージドと外部の両方)に適用されるようになります。これにより、本番環境のレイクハウスアーキテクチャに求められる運用上の信頼性がもたらされます。
レジリエンスは個別のプロジェクトではなく、基盤に組み込まれるべきものです。まもなく一般提供されるSnowflakeのマネージドIcebergレプリケーションおよびフェイルオーバーは、アカウントレプリケーションとフェイルオーバーをSnowflakeマネージドIcebergテーブルに拡張します。これにより、チームはオープンなデータファウンデーションの障害に対するレジリエンスを高めることができます。現在パブリックプレビュー中のフェイルオーバーグループ向けの新しいレプリケーション機能である最適化されたリフレッシュにより、レジリエンスはさらに強化されます。Snowflakeの次世代ログベースレプリケーションエンジン上に構築された最適化されたリフレッシュは、変更の発生を追跡し、更新が必要なものだけを適用します。プレビューを利用したお客様は、1.6倍から22倍のレプリケーションパフォーマンスの向上を経験しました。これにより、複製されるデータの量に基づく予測可能なコストを維持しながら、ミッションクリティカルなワークロードの目標復旧時点(RPO)の目標を引き下げることができます。
これらの機能がSnowflakeプラットフォームに組み込まれているため、チームは環境を再構築することなく、最小限の運用上の摩擦でデータ、アプリケーション、パイプラインをフェイルオーバーできます。これにより、組織は重要なワークロードに必要な運用上のレジリエンスを犠牲にすることなく、自信を持ってIcebergに全面移行できます。
データに対する主導権
オープンなレイクハウスは、データの移動を減らし、より多くの価値を引き出すことを約束しました。しかし、ほとんどの企業にとって、オープン性はテーブルフォーマットにとどまっていました。ガバナンスは断片化し、セマンティクスはサイロ化され、本番環境の要件を満たすには依然としてカスタムプロジェクトが必要でした。AIの普及により、このガバナンスとセマンティクスの断片化は無視できないものになりました。古く分断されたデータに基づいて推論を行うエージェントは、チームが構築しているシステムそのものへの信頼を損ないます。
相互運用可能なレイクハウスは、フォーマットだけでは実現できなかったものを提供します。それは、ストレージからガバナンス、セマンティクスに至るすべてのレイヤーにおける相互運用性であり、それぞれが互いに強化し合う統合された基盤です。これは実際には何を意味するのでしょうか。エンジニアは、データを複製することなく、各ワークロードに最適なエンジンを選択できます。ガバナンスチームがポリシーを一度定義すれば、それがSnowflake、Apache Spark、Trinoなどにわたって適用されます。Iceberg環境は、個別の運用プロジェクトなしで、可観測性、監査可能性、レジリエンスを備えます。そして、AIのイニシアチブは、初日からガバナンスが効いたセマンティクス豊かなデータ上で実行されます。
これこそが、データに対する真の主体性です。これはスローガンではなく、運用原則です。ベンダーが許可するものではなく、ビジネスの要件とAIの要求に基づいてアーキテクチャを設計してください。
相互運用可能な基盤がここにあります。
この基盤の上に構築してください。
データに対する主体性を取り戻すには、Snowflakeの相互運用可能なレイクハウスのページにアクセスし、Snowflakeの提供する機能をご確認ください。詳細については、無料のeBookBuilding the Interoperable Lakehouse:Data Strategies for AI Leadersをダウンロードするか、Snowflake、プロダクトマネジメント担当ディレクター、James Roland-Jonesが出演するTDWIウェビナーをご覧ください。その後、バーチャルラボBuild a Multi-Engine Stack on Snowflake Storage for Iceberg and Horizon Catalogで実践的な操作をご確認ください。
将来予想に関する記述
このページには、Snowflakeが将来提供する製品に関する記述を含め、将来の見通しに関する記述が含まれていますが、これはいかなる製品の提供も約束するものではありません。実際の結果や提供内容は異なる場合があり、既知および未知のリスクや不確実性の影響を受けます。詳細については、最新の四半期報告書(10-Q)をご覧ください。



