Aufbau des Interoperable Lakehouse: Kontrolle über Ihre Daten


KI stellt jede Architekturentscheidung auf die Probe. Wenn Teams Daten nicht dort nutzen können, wo sie gespeichert sind, kopieren sie sie. Pipelines wuchern, die Governance zersplittert, Kosten steigen und KI-Agenten arbeiten letztendlich mit veralteten, isolierten Daten anstatt mit den kontrollierten, semantisch reichhaltigen Daten, die sie benötigen.
Das Open Lakehouse versprach, die Datenfragmentierung zu lösen, ohne alle auf eine einzige Plattform zu zwingen. Aber für die meisten Unternehmen kam das Format, bevor Governance und semantische Fragmentierung angegangen werden konnten. Das ändert sich heute. Das Interoperable Lakehouse von Snowflake, das auf Apache Iceberg™, Apache Polaris™ und Open Semantic Interchange (OSI) basiert, ist allgemein verfügbar. Es bietet ein neues Konzept für die Verbindung, den Zugriff, die Verwaltung und die Nutzung einer einzigen, verwalteten Kopie Ihrer Daten, unabhängig von ihrem Speicherort und ohne Lock-in-Effekt. Indem Sie die Kontrolle an die Dateneigentümer und nicht an die Anbieter zurückgeben, erlangen Sie die Kontrolle über Ihre Daten, senken dabei die Architekturkosten und stützen jede KI-Initiative auf ein Fundament, dem Sie wirklich vertrauen können.
Daten am Speicherort nutzen
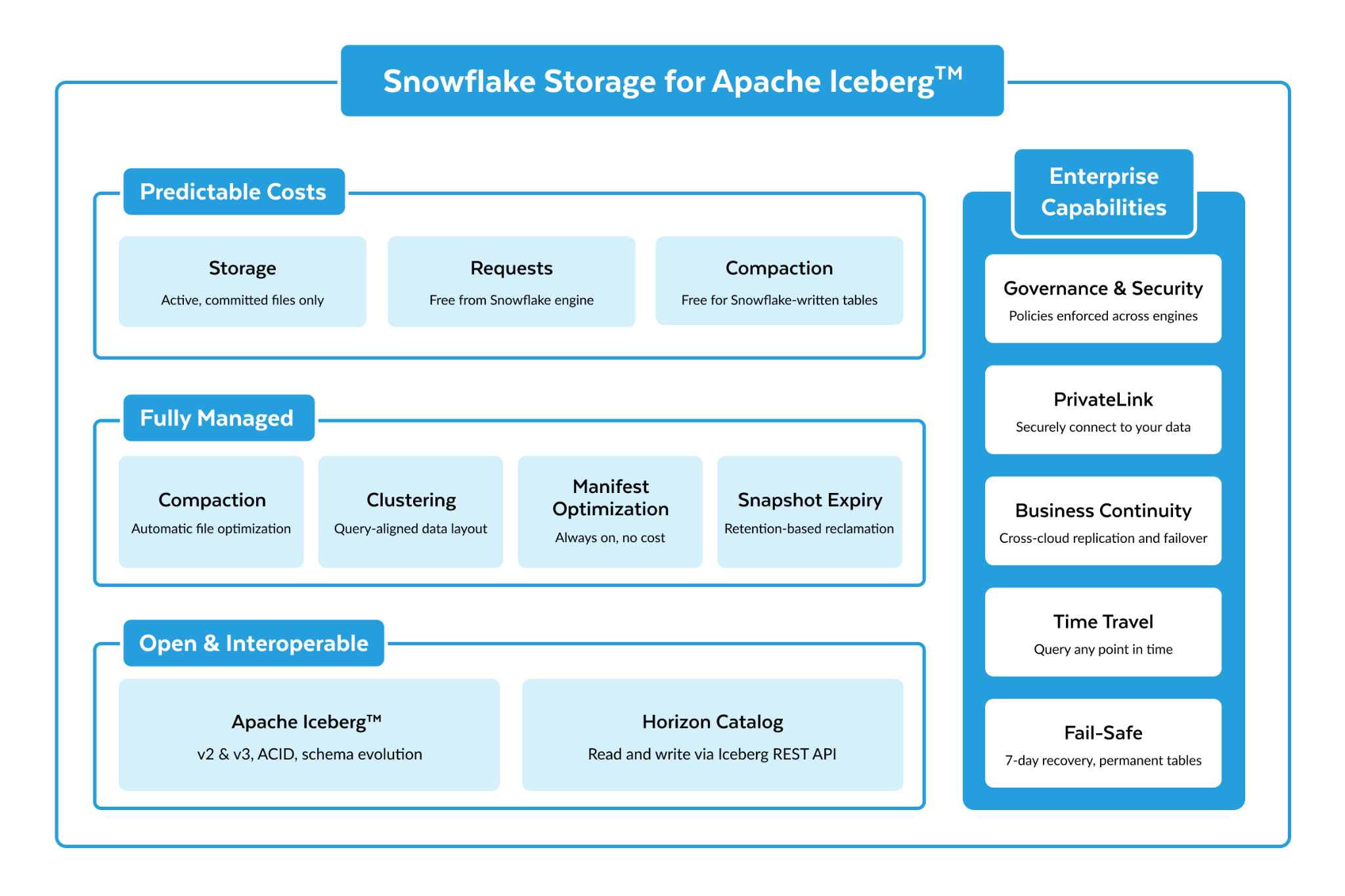
Die Kontrolle über Ihre Daten beginnt mit einer vernetzten Datengrundlage – einem einzigen Ort, an dem Sie jedes Dataset für jeden Vorgang nutzen können, ohne es zu kopieren. Mit diesem Launch erweitert Snowflake diese Grundlage über jede Zugriffsebene hinweg. Die Unterstützung von Snowflake für Apache Iceberg v3 ist allgemein verfügbar und produktionsbereit. Sie bietet die derzeit umfangreichsten v3-Funktionen auf dem Markt, die tief in die gesamte Plattform integriert sind, um eine größere Interoperabilität zu ermöglichen. Snowflake Storage für Apache Iceberg™-Tabellen macht verwaltetes Iceberg so einfach wie CREATE TABLE. Zero-Copy-Integrationen binden Ihre Systems-of-Record mit intakter Semantik in die Grundlage ein. Horizon Context verbindet die Geschäftsdefinitionen, mit denen jedes Team und jeder KI-Agent arbeitet. Mehr Daten. Mehr Kontext. Eine einzige verwaltete Kopie.
Apache Iceberg wurde ursprünglich für riesige analytische Datensätze entwickelt, bot jedoch eine suboptimale Unterstützung für Workloads mit semistrukturierten Daten, kleinen Updates, Geodaten-Analytics und Change-Tracking-Pipelines. Apache Iceberg v3 schließt diese Lücke. Ab heute bringt Snowflake die umfassendsten v3-Funktionen in die Produktion, darunter VARIANT-Unterstützung für semistrukturierte Daten, Row Lineage für das Change Tracking über Engines hinweg, Deletion Vectors für performante Löschungen auf Zeilenebene, Nanosekunden-Zeitstempel für hochfrequente Telemetrie und Finanz-Workloads, Standardwerte und Geodatentypen. Mehr Workloads haben nun einen klaren Weg zur Interoperabilität.
Ein leistungsfähiges Format beseitigt jedoch nicht den operativen Aufwand für die Speicherverwaltung. Snowflake Storage for Apache Iceberg™-Tabellen, die allgemein für AWS und Azure verfügbar sind und bald in Private Preview für Google Cloud zur Verfügung stehen, bieten ein vollständig verwaltetes Iceberg-Erlebnis: von Anfang an offen, über den Horizon Catalog verwaltet und von jeder Iceberg-kompatiblen Engine les- und schreibbar. Für Teams, die ihren eigenen Speicher auf Azure verwalten, ist die Azure DFS-Unterstützung allgemein verfügbar und bietet volle Interoperabilität durch native Azure Data Lake Storage Gen2-Endpunkte.
Das Einbringen bestehender Daten sollte keine Migration oder Konvertierung erfordern. Parquet Direct, derzeit in Private Preview und bald allgemein verfügbar, macht bestehende Parquet-Dateien mit einer Performance auf Iceberg-Niveau abfragbar. Die Google Cloud Lakehouse-Integration ist allgemein verfügbar und erstellt Catalog Linked Databases für die cloudübergreifende Lakehouse-Umgebung von Google mit automatischer Tabellenerkennung und cloudübergreifendem Lese- und Schreibzugriff. Just-in-Time-Refresh für extern verwaltetes Iceberg, in Private Preview, erkennt veraltete Metadaten zur Abfragezeit und aktualisiert sie automatisch, wodurch die Notwendigkeit entfällt, geplante Aktualisierungen zu konfigurieren.
Auf Enterprise-Plattformen befinden sich die wertvollsten Unternehmensdaten – und dort war der Pipeline-Aufwand schon immer am größten. Die Zero-Copy-Integration macht kritische Geschäftsdaten in Ihrem Snowflake-Ökosystem in nahezu Echtzeit verfügbar, ohne ETL-Pipelines oder die Notwendigkeit, den semantischen Kontext neu aufzubauen. Diese existieren nun für SAP (GA), Salesforce, Workday (Private Preview), und neue Partnerschaften mit AVEVA und IBM werden dieses Modell weiter ausbauen – operative Technologie und Industriedaten von AVEVA CONNECT sowie Enterprise-Datenplattformen von IBM – und Geschäftsdefinitionen und Kontext für konsistentere, KI-bereite Daten zusammenführen.
Verbundene Systeme bedeuten nicht zwangsläufig auch eine verbundene Bedeutung. Umsatz, Abwanderung und Kundenzahlen bedeuten an drei verschiedenen Orten immer noch drei verschiedene Dinge, bis die Definitionen selbst in einer verbundenen Schicht leben. Horizon Context ist diese Schicht. Es verknüpft verstreute Geschäftsdefinitionen über Datenbanken, Data Lakes und BI-Tools hinweg, sodass jedes Team innerhalb und außerhalb von Snowflake (und KI-Agenten) von derselben Definition der Unternehmenswahrheit ausgeht. Stellen Sie eine Verbindung zu externen Datenbank-, BI- und Daten-Pipeline-Systemen wie PostgreSQL, Microsoft SQL Server, Tableau, Microsoft Power BI und dbt her und reichern Sie Metadaten mit Schemas, Abfrageprotokollen, Dashboard-Definitionen und mehr an (in Private Preview). Horizon Context ermöglicht diese Grundlage durch eine Reihe integrierter Funktionen:
- Out-of-the-box-Konnektoren: Verbinden Sie sich mit Tools wie PostgreSQL, Microsoft SQL Server, Tableau, Microsoft Power BI und dbt, mit denen Sie umfassenden Kontext – Abfrageprotokolle, Beliebtheit, Schemas und mehr – aus vielen Quellen in einem durchsuchbaren Katalog zusammenführen können.
- End-to-End-Lineage auf Spaltenebene: Lineage ist der Schlüssel zum Verständnis, wie Daten-Assets miteinander in Beziehung stehen. Horizon Context extrahiert Lineage-Informationen aus Snowflake und externen Datenbankabfrageprotokollen, BI-Systemen und OpenLineage-Feeds und fügt sie zu einem vollständigen End-to-End-Lineage-Graphen zusammen.
- Semantic Studio, in Private Preview, ist eine KI-gestützte IDE innerhalb von Snowflake Workspaces, mit der Teams gemeinsame Geschäftslogik ohne SQL-Kenntnisse definieren, testen und veröffentlichen können, mit Snowflake CoCo-Integration und Git-Synchronisierung für die Versionskontrolle.
- Semantic View Autopilot (allgemein verfügbar) analysiert bestehende Abfragemuster, um Semantic Views automatisch zu generieren und zu verfeinern. So wird sichergestellt, dass Ihre Kontextschicht aktuell bleibt, während sich Ihre Daten und deren Nutzung weiterentwickeln. CoCo ruft nun den Geschäftskontext für die Suche, die SQL-Generierung und für komplexe Analysen ab (allgemein verfügbar).
- Und durch den Open Semantic Interchange (OSI) gelangen diese Definitionen über Snowflake hinaus in das breitere BI- und KI-Ökosystem mit 54 teilnehmenden Anbietern und einer veröffentlichten Spezifikation.
Eine Frage an Ihre Daten zu stellen, sollte einfach funktionieren. Mit einer vernetzten, interoperablen Grundlage im Hintergrund ist das der Fall. Mit Agentic Queries (allgemein verfügbar) können Ihre Teams Fragen in natürlicher Sprache über Snowflake, Data Lakes und, in Private Preview, externe relationale Systeme hinweg stellen. Horizon Context liefert die kontrollierte Antwort fast augenblicklich.
Das ist erst der Anfang. Geteilte Daten, auch in offenen Formaten, sollten sich ebenso dialogorientiert abfragen lassen. Auto-gen Agents für Data Shares und Listings, in Public Preview, generieren sofort ein Semantic View und einen Agenten aus einem beliebigen Data Listing oder Secure Data Share, ohne dass eine manuelle Entwicklung erforderlich ist. Cortex Agent Sharing, in Public Preview, stellt diesen Agenten dann über Snowflake-Konten hinweg für interne Teams, Partner oder das breitere Ökosystem über den Marketplace bereit. Zusammen erschließen diese Funktionen durch ein dialogorientiertes Erlebnis neue Zielgruppen und Anwendungsfälle für dieselben kontrollierten Datensätze. Datennutzer können geteilte Daten sogar mit ihren eigenen First-Party-Daten kombinieren, um tiefere Einblicke zu gewinnen – alles standardmäßig kontrolliert.
Universelle Governance
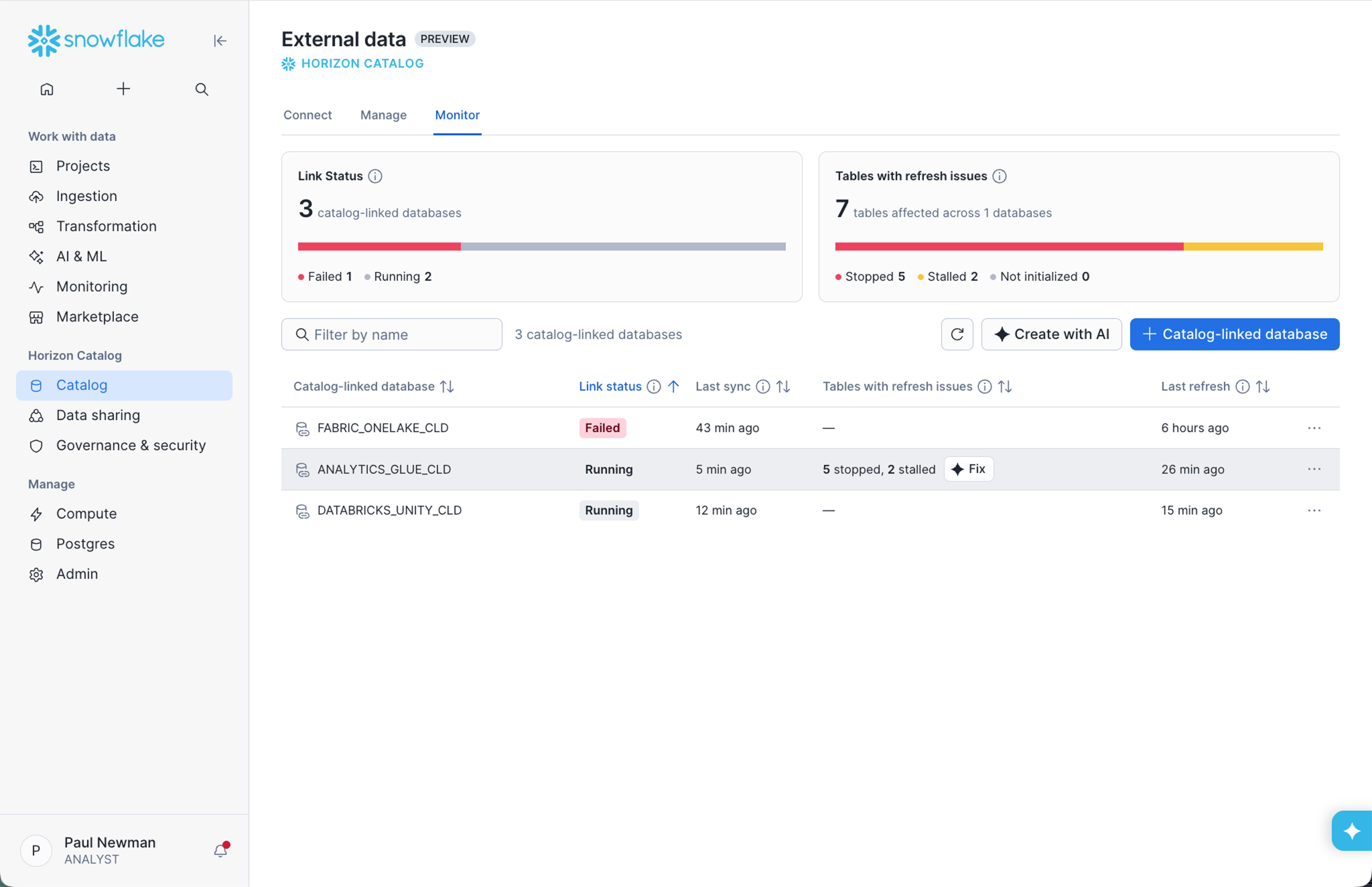
Daten direkt an ihrem Speicherort zu verarbeiten, löst nur die halbe Problematik. Das größere Problem wird in dem Moment offensichtlich, in dem Sie dafür entwickeln: Wer kontrolliert Ihre Daten, wo und wie. Umgebungen mit mehreren Katalogen fragmentieren Richtlinien. Der Zugriff über mehrere Engines vervielfacht die Herausforderungen und untergräbt mit jedem Workaround die Kontrolle über Ihre Daten. Was wäre, wenn Sie Zugriffsrichtlinien nur einmal in einem universellen Katalog festlegen müssten? Wir freuen uns, neue Funktionen in Horizon Catalog (basierend auf Apache Polaris™) ankündigen zu können, die dabei helfen, Ihr gesamtes Iceberg-Ökosystem zu vernetzen. Jetzt können Sie nicht nur von Snowflake verwaltete Iceberg-Tabellen kontrollieren, sondern jede Iceberg-Tabelle in Ihrer Umgebung. Die universelle Governance, die in Horizon festgelegt wird, wird von jeder IRC-kompatiblen Engine und ohne Lock-in respektiert.
Es beginnt mit der Bereitstellung einer interoperablen Grundlage, die für die Produktion bereit ist. Jetzt sind sowohl Lese- als auch Schreibzugriff von externen Engines allgemein verfügbar im Horizon Catalog und bieten vollständige bidirektionale Interoperabilität über Vended Credentials, die im Iceberg REST-Protokoll definierten offenen Sicherheitsmechanismen, für Snowflake-Managed Iceberg Tables. Spark, Trino, PyIceberg und jede kompatible Engine können auf derselben kontrollierten Kopie lesen und schreiben wie Ihre Snowflake-Benutzer. Ein Katalog, ein Satz von Richtlinien, kein Kompromiss zwischen der Nutzung Ihrer bevorzugten Engines und der zentralen Verwaltung von Governance-Richtlinien.
Da die meisten Unternehmen über mehrere Kataloge verfügen, ist die Einrichtung einheitlicher Governance-Kontrollen kostspielig und komplex. Die Implementierung einer universellen Governance erzwingt die Wahl zwischen kostspieligen Migrationen oder der Übertragung der Komplexität und der Betriebskosten auf Ihre Datenteams, indem Governance-, Auditing- und Monitoring-Kontrollen über jeden Katalog hinweg dupliziert werden. Dieser erzwungene Kompromiss untergräbt die Kontrolle über Ihre Daten. Letztes Jahr haben wir, basierend auf dem Prinzip der direkten Datenverarbeitung am Speicherort, Catalog-Linked Databases (allgemein verfügbar) eingeführt, um alle Ihre externen Iceberg Tables von Snowflake aus automatisch zu erkennen und sicher zu lesen und zu schreiben. In diesem Jahr erweitern wir dieses Prinzip um die Governance von Daten am Speicherort, wodurch erzwungene Migrationen überflüssig werden. Jetzt, in Private Preview, können Sie auch den sicheren Engine-Zugriff auf diese externen Iceberg Tables verwalten, indem Sie Horizon Iceberg REST Catalog APIs für Lese- und Schreiboperationen verwenden, wodurch sich der Horizon Catalog zu einer universellen Governance-Schicht für alle Iceberg Tables entwickelt. Sie erhalten umfassende Governance-Funktionen, Auditing und Observability an einem Ort für alle Operationen von jeder Engine.
Ein weiterer häufiger Grund für die Katalogfragmentierung ist, dass feingranulare Zugriffskontrollen auf den Katalog beschränkt waren, der mit einer einzelnen Engine verknüpft ist. Diese Einschränkung erhöht den operativen Aufwand für die Verwaltung einer Multi-Engine-Umgebung für Ihre Datenteams und steigert das Risiko, dass eine falsch konfigurierte Richtlinie ein Datenleck verursacht. Jetzt beseitigt die Unterstützung für die Iceberg REST Scan Plan API (in Private Preview) diese Einschränkung. Mit dieser Funktion folgen feingranulare Zugriffsrichtlinien den Daten, wo immer sie abgefragt werden. Dadurch können Richtlinien für den Zeilenzugriff und Dynamic Data Masking, die im Horizon Catalog für Snowflake-Managed Iceberg Tables definiert sind, beim Zugriff durch externe Engines durchgesetzt werden. Schließlich setzt der neue Snowflake Connector for Apache Spark (allgemein verfügbar) diese Richtlinien für Teams durch, die bereits mit Spark arbeiten, und bietet schon heute eine produktionsbereite Lösung.
Wir erweitern die Reichweite von Open Data Sharing und ermöglichen es Kunden, föderierte Kataloge mithilfe von Catalog-Linked Databases zu teilen (in Kürze allgemein verfügbar). Wir kündigen außerdem an, dass Open Data Sharing erweitert wurde (Public Preview), sodass jede IRC-kompatible externe Engine alle Data Shares konsumieren kann, ohne ein Snowflake-Konto zu benötigen. In Kombination ermöglichen diese beiden Funktionen Kunden, jede externe Engine zu nutzen, um sicher auf jedes offene Tabellenformat zuzugreifen, das über Horizon zugänglich ist.
Richtlinien bleiben durchgesetzt, da die Verbindungen selbst sicher sind. Private Link zu externen Katalogen und Speichern ist allgemein verfügbar, wodurch Daten vom öffentlichen Internet ferngehalten werden, wenn Snowflake eine Verbindung zu externen Lakes herstellt.
Dies funktioniert, weil die zugrunde liegenden Standards offen sind. Apache Polaris ist jetzt ein Top-Level-Projekt der Apache Software Foundation, und Snowflake-Ingenieure haben die Spezifikation der Scan Planning API zum Apache Iceberg-Projekt beigetragen. Universelle Governance wird zu einer Ökosystem-Lösung, nicht nur zu einem Snowflake-Feature.
Standardmäßig Enterprise-ready
Die Verarbeitung von Daten an ihrem Speicherort und ihre universelle Governance bilden die Architektur. Der Betrieb in der Produktion liegt in der Verantwortung Ihres Teams. Die meisten Lakehouse-Architekturen geben diese Verantwortung an die Architekt:innen zurück: Integritätsprüfungen müssen instrumentiert, Audit-Protokolle über Engines hinweg abgeglichen und Ausfallsicherheit nachträglich integriert werden. Heute entfällt dieser betriebliche Aufwand. Umfassendes Auditing in Access History (in Private Preview) protokolliert jede Operation einer externen Engine direkt in der Access History von Snowflake und bietet Compliance- und Sicherheitsteams einen einzigen, zusammenhängenden Datensatz aller Tabellenoperationen auf Benutzerebene, unabhängig von der verwendeten Engine oder der aufgerufenen Tabelle. Die betriebliche Integritätsüberwachung für Externally Managed Iceberg Tables in mit Katalogen verknüpften Datenbanken (in Private Preview) deckt Probleme mit der Aktualität und Aktualisierung auf, bevor sie die Produktion erreichen. Und die Managed Iceberg-Replikation, die in Kürze allgemein verfügbar sein wird, macht dieselbe offene Grundlage standardmäßig widerstandsfähig gegen Ausfälle. Enterprise-ready, ganz ohne Integrationsprojekt.
Compliance-Teams mussten schon immer Audit-Protokolle über verschiedene Engines hinweg abgleichen. Umfassendes Auditing in Access History (in Private Preview), das jede Operation einer externen Engine direkt in der Access History von Snowflake protokolliert, macht dieser Arbeit ein Ende. Jedes Zugriffsereignis landet in einem einzigen, rechtssicheren Datensatz: wer, wo und wann auf was zugegriffen hat. Architekt:innen können das Audit an einem einzigen Ort beantworten.
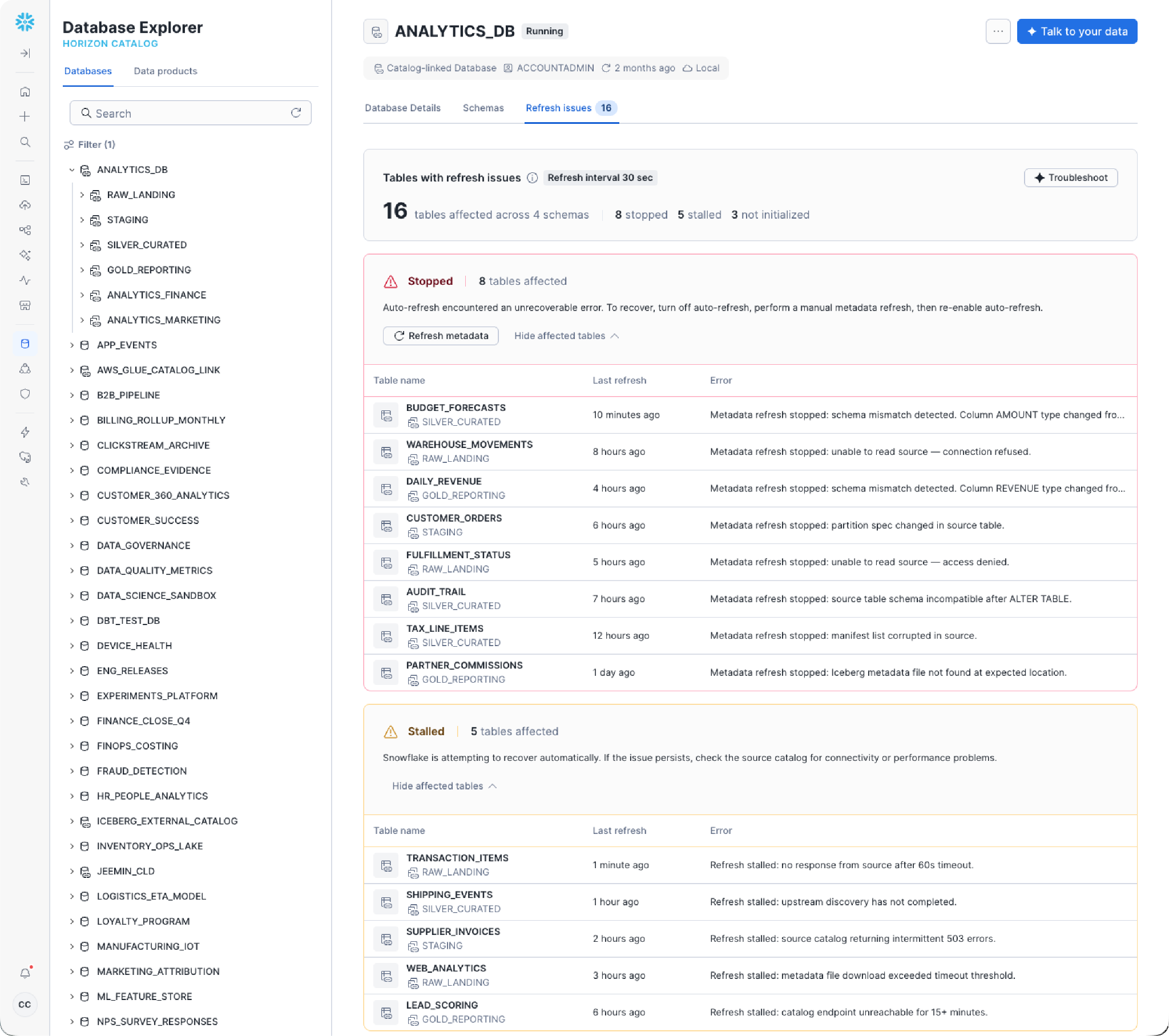
Iceberg Health Insights in Snowsight (in Private Preview) bietet Plattformteams eine vernetzte betriebliche Sicht auf ihren Bestand an Externally Managed Iceberg Tables – Auto-Refresh-Status, Tabellenerkennung und Aktualitätssignale –, ohne zwischen Cloud-Konsolen wechseln oder benutzerdefiniertes Monitoring erstellen zu müssen. Wenn eine mit einem Katalog verknüpfte Datenbank veraltete Metadaten aufweist oder eine Aktualisierungs-Pipeline ins Stocken gerät, sehen Teams dies an einem Ort und können das Problem beheben, bevor nachgelagerte Abfragen veraltete Ergebnisse liefern. Wenn diese Funktion in Richtung allgemeiner Verfügbarkeit erweitert wird, wird sie sich auf den gesamten Iceberg-Bestand (sowohl von Snowflake verwaltet als auch extern) erstrecken und die betriebliche Sicherheit bieten, die Produktions-Lakehouse-Architekturen erfordern.
Ausfallsicherheit gehört in das Fundament, nicht in ein separates Projekt. Die Managed Iceberg-Replikation und das Failover von Snowflake, die in Kürze allgemein verfügbar sein werden, erweitern Account Replication und Failover auf Snowflake-Managed Iceberg Tables und helfen Teams dabei, ihre Open Data-Datengrundlage widerstandsfähiger gegen Ausfälle zu machen. Die Ausfallsicherheit wird durch Optimized Refresh noch weiter gestärkt, ein neues Replikations-Feature für Failover-Gruppen, das sich jetzt in Public Preview befindet. Basierend auf der protokollbasierten Replikations-Engine der nächsten Generation von Snowflake verfolgt Optimized Refresh Änderungen in Echtzeit und wendet nur das an, was aktualisiert werden muss. Preview-Kunden erlebten eine 1,6- bis 22-mal schnellere Replikations-Performance, was Teams dabei hilft, die RPO-Ziele (Recovery Point Objective) für geschäftskritische Workloads zu reduzieren und gleichzeitig vorhersehbare Kosten basierend auf dem replizierten Datenvolumen beizubehalten.
Mit diesen in die Plattform von Snowflake integrierten Funktionen können Teams ein Failover von Daten, Anwendungen und Pipelines mit minimaler betrieblicher Reibung und ohne Umstrukturierung ihrer Umgebungen durchführen. Das gibt Unternehmen die Sicherheit, voll und ganz auf Iceberg zu setzen, ohne die betriebliche Ausfallsicherheit zu opfern, die ihre kritischen Workloads erfordern.
Kontrolle über Ihre Daten
Das Open Lakehouse versprach, dass Daten weniger verschoben werden und härter arbeiten. Doch für die meisten Unternehmen endete die Offenheit beim Tabellenformat. Die Governance war fragmentiert, die Semantik isoliert und jede Produktionsanforderung erforderte weiterhin ein maßgeschneidertes Projekt. KI machte es unmöglich, diese Governance- und semantische Fragmentierung zu ignorieren. Agenten, die auf der Grundlage veralteter, unzusammenhängender Daten schlussfolgern, untergraben das Vertrauen in genau die Systeme, die Ihre Teams aufbauen.
Das Interoperable Lakehouse bietet, was das Format allein nicht konnte: Interoperabilität auf jeder Ebene, von der Speicherung über die Governance bis hin zur Semantik, in einem vernetzten Fundament, in dem sich die einzelnen Elemente gegenseitig verstärken. Was bedeutet das in der Praxis? Ihre Engineers wählen die richtige Engine für jeden Workload, ohne Daten zu duplizieren. Ihr Governance-Team definiert eine Richtlinie einmalig, und sie gilt für Snowflake, Apache Spark, Trino und mehr. Ihr Iceberg-Bestand ist beobachtbar, überprüfbar und ausfallsicher, ohne dass ein separates Betriebsprojekt erforderlich ist. Und Ihre KI-Initiativen laufen vom ersten Tag an mit kontrollierten, semantisch reichhaltigen Daten.
Das ist echte Kontrolle über Ihre Daten. Kein Slogan – ein Funktionsprinzip. Gestalten Sie Ihre Architektur nach den Anforderungen Ihres Unternehmens und den Anforderungen von KI, nicht nach dem, was Ihr Anbieter zulässt.
Das interoperable Fundament ist da.
Bauen Sie darauf auf.
Um die Kontrolle über Ihre Daten zurückzugewinnen, besuchen Sie die Interoperable Lakehouse-Seite von Snowflake und entdecken Sie die Angebote von Snowflake. Erfahren Sie mehr, indem Sie das kostenlose E-Book „Building the Interoperable Lakehouse: Data Strategies for AI Leaders“ herunterladen oder sich das TDWI-Webinar mit James Roland-Jones, Director of Product Management bei Snowflake, ansehen. Werden Sie dann in diesem virtuellen Labor praktisch tätig: „Build a Multi-Engine Stack on Snowflake Storage for Iceberg and Horizon Catalog“.
Zukunftsgerichtete Aussagen
Dieser Inhalt enthält zukunftsgerichtete Aussagen, unter anderem über unsere künftigen Produktangebote, und stellt keine Verpflichtung dar, irgendwelche Produktangebote bereitzustellen. Die tatsächlichen Ergebnisse und Angebote können abweichen und unterliegen bekannten und unbekannten Risiken und Unsicherheiten. Weitere Informationen finden Sie in unserem jüngsten 10-Q-Formular.

Sicherheit für das Agentic Enterprise beginnt bei den Daten
