Lakehouse interoperabile per un controllo totale sui dati


L’intelligenza artificiale mette alla prova ogni decisione architetturale. Quando i team non possono agire sui dati dove risiedono, li copiano. Le pipeline si moltiplicano, la governance si frammenta, i costi aumentano e gli agenti AI finiscono per ragionare su dati obsoleti e disconnessi anziché sui dati governati e semanticamente ricchi di cui hanno bisogno.
L’open lakehouse prometteva di risolvere la frammentazione dei dati senza obbligare tutti a una singola piattaforma. Ma per la maggior parte delle organizzazioni il formato è arrivato prima che si potessero affrontare la frammentazione della governance e quella semantica. Oggi tutto questo cambia. L’Interoperable Lakehouse Snowflake, basato su Apache Iceberg™, Apache Polaris™ e Open Semantic Interchange (OSI), è in GA. Offre un nuovo modello per connettere, accedere, governare e operare su un’unica copia governata dei tuoi dati, ovunque essi risiedano e senza lock-in. Restituendo il controllo ai proprietari dei dati, e non ai vendor, ottieni il pieno controllo sui tuoi dati e, allo stesso tempo, riduci i costi architetturali e fondi ogni iniziativa di intelligenza artificiale su una data foundation di cui ti puoi davvero fidare.
Agire sui dati dove risiedono
Il controllo sui tuoi dati parte da una data foundation connessa: un unico posto in cui agire su ogni data set, per qualsiasi operazione, senza copiarlo. Con questo lancio, Snowflake rafforza tale data foundation su ogni livello di accesso. Il supporto Snowflake per Apache Iceberg v3 è in GA e pronto per la produzione, offrendo la più ampia gamma di funzionalità v3 oggi sul mercato, profondamente integrate nell’intera piattaforma per sbloccare una maggiore interoperabilità. Snowflake Storage for Apache Iceberg™ tables rende la gestione di Iceberg semplice quanto un CREATE TABLE. Le Zero-Copy Integrations portano i tuoi sistemi di registrazione nella data foundation con la semantica intatta. Horizon Context connette le definizioni di business su cui si basano ogni team e ogni agente AI. Più dati. Più contesto. Un’unica copia governata.
Apache Iceberg è stato originariamente progettato per enormi data set analitici, ma offriva un supporto non ottimale per i workload che coinvolgono dati semi‑strutturati, piccoli aggiornamenti, analisi geospaziale e pipeline di change-tracking. Apache Iceberg v3 colma questo divario. Da oggi, Snowflake porta in produzione la più ampia gamma di funzionalità v3, tra cui il supporto VARIANT per i dati semi‑strutturati, la row lineage per il change tracking tra engine, i deletion vector per eliminazioni performanti a livello di riga, i timestamp al nanosecondo per la telemetria ad alta frequenza e i workload finanziari, i valori di default e i tipi geospaziali. Ora un numero maggiore di workload dispone di un percorso pulito verso l’interoperabilità.
Un formato potente, tuttavia, non elimina il costo operativo della gestione dell’archiviazione. Snowflake Storage for Apache Iceberg™ tables, in GA per AWS e Azure e presto in private preview per Google Cloud, offre un’esperienza Iceberg completamente gestita: open fin dall’inizio, governata tramite Horizon Catalog, leggibile e scrivibile da qualsiasi engine compatibile con Iceberg. Per i team che gestiscono la propria archiviazione su Azure, il supporto Azure DFS è in GA e offre una piena interoperabilità attraverso gli endpoint nativi di Azure Data Lake Storage Gen2.
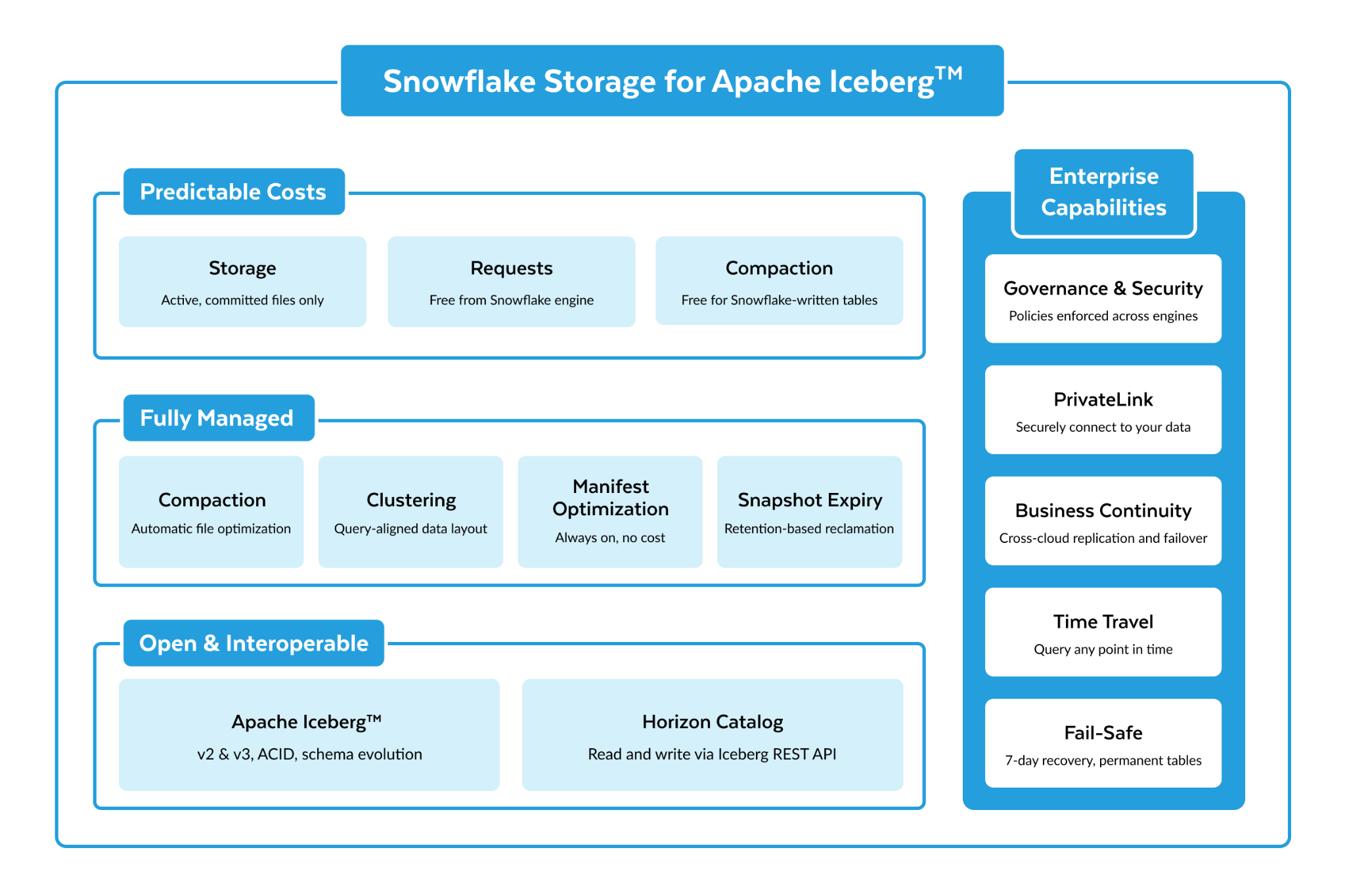
Portare i dati esistenti all’interno non dovrebbe richiedere migrazione o conversione. Parquet Direct, in private preview e con la general availability in arrivo a breve, rende i file Parquet esistenti interrogabili con prestazioni di livello Iceberg. La Google Cloud Lakehouse integration è in GA e crea Catalog Linked Databases per l’ambiente lakehouse cross-cloud di Google, con rilevamento automatico delle tabelle e accesso in lettura e scrittura cross-cloud. Il Just-in-time refresh per Iceberg gestito esternamente, in private preview, rileva i metadati obsoleti al momento della query e li aggiorna automaticamente, eliminando la necessità di configurare refresh pianificati.
Le piattaforme enterprise sono dove risiedono i dati aziendali più preziosi e dove il costo delle pipeline è sempre stato più elevato. La Zero-copy integration rende i dati di business critici disponibili nel tuo ecosistema Snowflake in tempo quasi reale, senza pipeline ETL e senza dover ricostruire il contesto semantico. Queste integrazioni sono ora disponibili per SAP (in GA), Salesforce e Workday (private preview), e le nuove partnership con AVEVA e IBM estenderanno ulteriormente questo modello, con la tecnologia operativa e i dati industriali di AVEVA CONNECT e le piattaforme di dati enterprise di IBM, unendo definizioni di business e contesto per ottenere dati più coerenti e pronti per l’intelligenza artificiale.
Avere sistemi connessi non si traduce necessariamente in un significato connesso. Ricavi, churn e numero di clienti continuano a significare tre cose diverse in tre posti diversi finché le definizioni stesse non risiedono in un unico livello connesso. Horizon Context è quel livello. Collega definizioni di business sparse tra database, data lake e strumenti di BI, in modo che ogni team dentro e fuori Snowflake (e gli agenti AI) ragioni a partire dalla stessa definizione di verità aziendale. Connettiti a database esterni, sistemi di BI e di pipeline di dati, tra cui PostgreSQL, Microsoft SQL Server, Tableau, Microsoft Power BI e dbt, e arricchisci i metadati con schemi, log delle query, definizioni delle dashboard e altro ancora (in private preview). Horizon Context abilita questa data foundation attraverso una serie di funzionalità integrate:
- Connettori pronti all’uso: connettiti a strumenti come PostgreSQL, Microsoft SQL Server, Tableau, Microsoft Power BI e dbt che ti permettono di raccogliere un contesto ricco (log delle query, popolarità, schemi e altro) da numerose fonti in un unico catalogo ricercabile.
- Lineage end‑to‑end a livello di colonna: la lineage è fondamentale per capire come gli asset di dati sono correlati tra loro. Horizon Context estrae informazioni di lineage dai log delle query di Snowflake e dei database esterni, dai sistemi di BI e dai feed OpenLineage, e le unisce per creare un grafo di lineage completo ed end‑to‑end.
- Semantic Studio, in private preview, è un IDE assistito dall’intelligenza artificiale all’interno di Snowflake Workspaces che permette ai team di definire, testare e pubblicare logica di business condivisa senza competenze SQL, con l’integrazione di Snowflake CoCo e la sincronizzazione Git per il controllo delle versioni.
- Semantic View Autopilot (in GA) analizza i pattern di query esistenti per generare e affinare automaticamente le viste semantiche, contribuendo a mantenere aggiornato il tuo livello di contesto man mano che i dati e l’utilizzo evolvono. CoCo ora recupera il contesto di business per la ricerca, la generazione di SQL e le analisi complesse, ed è in GA.
- E attraverso l’Open Semantic Interchange (OSI) queste definizioni viaggiano oltre Snowflake fino al più ampio ecosistema di BI e intelligenza artificiale, con 54 vendor partecipanti e una specifica pubblicata.
Porre una domanda ai tuoi dati dovrebbe semplicemente funzionare. Con una data foundation connessa e interoperabile alla base, funziona. Le Agentic Queries (in GA) permettono ai tuoi team di porre domande in linguaggio naturale su Snowflake, sui data lake e, in private preview, sui sistemi relazionali esterni. Horizon Context restituisce la risposta governata quasi istantaneamente.
E questo è solo il punto di partenza. Anche i dati condivisi, compresi quelli in formati open, dovrebbero essere altrettanto conversazionali. Gli Auto-gen Agents for Data Shares and Listings, in public preview, generano istantaneamente una Semantic View e un agente AI da qualsiasi prodotto in catalogo o condivisione sicura di dati, senza sviluppo manuale. Il Cortex Agent Sharing, in public preview, distribuisce poi quell’agente AI tra gli account Snowflake verso team interni, partner o il più ampio ecosistema tramite il Marketplace. Insieme, queste funzionalità aprono nuovi pubblici e casi d’uso per gli stessi data set governati attraverso un’esperienza conversazionale. I consumer possono persino combinare i dati condivisi con i propri dati first-party per ottenere insight più ricchi, il tutto governato fin da subito.
Governance universale
Agire sui dati dove risiedono risolve solo metà del problema. Il problema più grande diventa evidente nel momento in cui lo sviluppi: chi governa i tuoi dati, dove e come. Gli ambienti multi-catalogo frammentano le policy. L’accesso multi-engine moltiplica le sfide, erodendo il controllo sui tuoi dati a ogni workaround. E se bastasse impostare le policy di accesso una sola volta in un unico catalogo universale? Siamo entusiasti di annunciare nuove funzionalità in Horizon Catalog (basato su Apache Polaris™) che aiutano a connettere l’intero ecosistema Iceberg. Ora puoi governare non solo Iceberg gestito da Snowflake, ma ogni Iceberg Table del tuo patrimonio dati. La governance universale, impostata in Horizon, viene rispettata su ogni engine compatibile con IRC e senza lock-in.
Tutto parte dall’offrire una data foundation interoperabile e pronta per la produzione. Ora, l’accesso in lettura e scrittura dagli engine esterni è in GA in Horizon Catalog, offrendo una piena interoperabilità bidirezionale tramite le vended credentials, i meccanismi di sicurezza open definiti nel protocollo Iceberg REST, verso le Iceberg Tables gestite da Snowflake. Spark, Trino, PyIceberg e qualsiasi engine compatibile possono leggere e scrivere sulla stessa copia governata utilizzata dai tuoi utenti Snowflake. Un solo catalogo, un solo set di policy, nessun compromesso tra l’uso degli engine preferiti e il mantenimento delle policy di governance in un unico posto.
Quando la maggior parte delle aziende dispone di diversi cataloghi, impostare controlli di governance uniformi è costoso e complesso. Implementare una governance universale impone una scelta tra migrazioni costose o il trasferimento della complessità e del costo operativo ai tuoi team di dati, duplicando i controlli di governance, auditing e monitoraggio su ogni catalogo. Questa scelta forzata erode il controllo sui tuoi dati. L’anno scorso, basandoci sul principio di agire sui dati dove risiedono, abbiamo lanciato i Catalog-linked databases (in GA) per rilevare automaticamente e leggere e scrivere in modo sicuro su tutte le tue Iceberg Tables esterne da Snowflake. Quest’anno estendiamo tale principio per includere la governance dei dati dove risiedono, eliminando la necessità di migrazioni forzate. Ora, in private preview, puoi anche gestire l’accesso sicuro degli engine a queste Iceberg Tables esterne utilizzando le Horizon Iceberg REST Catalog API per operazioni sia di lettura sia di scrittura, facendo evolvere Horizon Catalog in un livello di governance universale per tutte le Iceberg Tables. Ottieni funzionalità complete di governance, auditing e osservabilità in un unico posto per tutte le operazioni provenienti da qualsiasi engine.
Un altro motivo comune alla base della frammentazione dei cataloghi è che i controlli di accesso granulari sono stati limitati al catalogo associato a un singolo engine. Questa limitazione aumenta il carico operativo della gestione di un ambiente multi-engine per i tuoi team di dati, accrescendo il rischio che una policy mal configurata provochi una fuga di dati. Ora, il supporto per la Iceberg REST Scan Plan API (in private preview) elimina questa restrizione. Con questa funzionalità, le policy di accesso granulari seguono i dati ovunque vengano interrogati, consentendo l’applicazione delle policy di row-access e di mascheramento dinamico dei dati definite in Horizon Catalog per le Iceberg Tables gestite da Snowflake anche quando vi si accede da engine esterni. Infine, il nuovo Snowflake Connector for Apache Spark (in GA) applica queste policy per i team che già operano su Spark, offrendo oggi una soluzione pronta per la produzione.
Stiamo ampliando la portata dell’Open Data Sharing consentendo ai clienti di condividere cataloghi federati utilizzando i Catalog Linked Databases (presto in GA). Annunciamo inoltre che l’Open Data Sharing è stato potenziato (public preview), così che qualsiasi engine esterno compatibile con IRC possa consumare tutte le condivisioni di dati senza bisogno di un account Snowflake. Combinate, queste due funzionalità permettono ai clienti di utilizzare qualsiasi engine esterno per accedere in modo sicuro a qualsiasi formato tabellare open accessibile tramite Horizon.
Le policy restano applicate perché le connessioni stesse sono sicure. Il Private Link verso cataloghi e archiviazione esterni è in GA e mantiene i dati al di fuori della rete internet pubblica quando Snowflake si connette a lake esterni.
Questo funziona perché gli standard alla base sono open. Apache Polaris è ora un Top-Level Project della Apache Software Foundation e gli ingegneri Snowflake hanno contribuito con la specifica della Scan Planning API al progetto Apache Iceberg. La governance universale diventa una soluzione di ecosistema, non solo una feature di Snowflake.
Pronto per l’enterprise di default
L’architettura consiste nell’operare sui dati nella loro posizione e governarli in modo universale. Eseguirla in produzione è responsabilità del tuo team. La maggior parte delle architetture lakehouse rimette questa responsabilità nelle mani dell’architetto: health check da strumentare, log di audit da riconciliare tra i motori, resilienza da aggiungere a posteriori. Oggi questo onere operativo scompare. L’auditing completo nella cronologia degli accessi, in private preview, registra ogni operazione dei motori esterni direttamente nella cronologia degli accessi di Snowflake, offrendo ai team di compliance e sicurezza un record unico e connesso di tutte le operazioni sulle tabelle a livello di utente, indipendentemente dal motore utilizzato o dalla tabella a cui si accede. Il monitoraggio dello stato operativo delle Iceberg Tables gestite esternamente nei catalog-linked database, in private preview, segnala i problemi di aggiornamento e di freschezza dei dati prima che raggiungano la produzione. Inoltre, la replica delle Managed Iceberg, presto in GA, rende la stessa data foundation open resiliente alle interruzioni di default. Pronta per l’enterprise, senza progetto di integrazione.
I team di compliance hanno sempre dovuto riconciliare i log di audit tra i motori. L’auditing completo nella cronologia degli accessi, in private preview, registra ogni operazione dei motori esterni direttamente nella cronologia degli accessi di Snowflake e pone fine a questo lavoro. Ogni evento di accesso confluisce in un unico record difendibile: chi ha avuto accesso a cosa, dove e quando. Gli architetti possono rispondere all’audit in un solo posto.
Iceberg Health Insights in Snowsight, in private preview, offre ai team di piattaforma una visione operativa connessa del loro patrimonio Iceberg gestito esternamente, con lo stato dell’aggiornamento automatico, il rilevamento delle tabelle e i segnali di freschezza dei dati, senza dover passare da una console cloud all’altra né creare sistemi di monitoraggio personalizzati. Quando un catalog-linked database segnala metadati obsoleti o una pipeline di aggiornamento si blocca, i team lo vedono in un solo posto e risolvono il problema prima che le query a valle restituiscano risultati non aggiornati. Con la progressiva espansione di questa funzionalità verso la general availability, essa coprirà l’intero patrimonio Iceberg, sia gestito da Snowflake sia esterno, garantendo la sicurezza operativa che le architetture lakehouse in produzione richiedono.
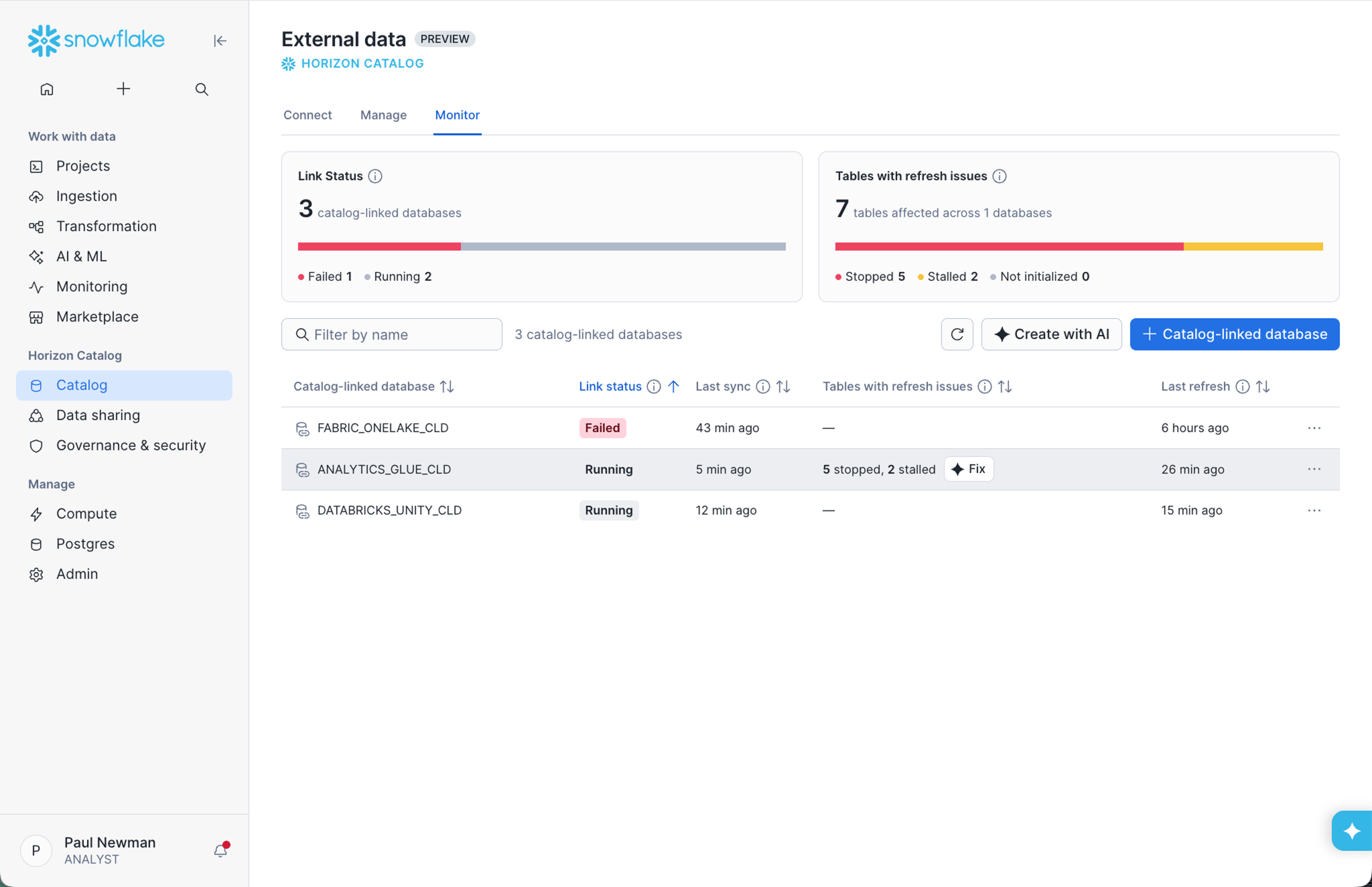
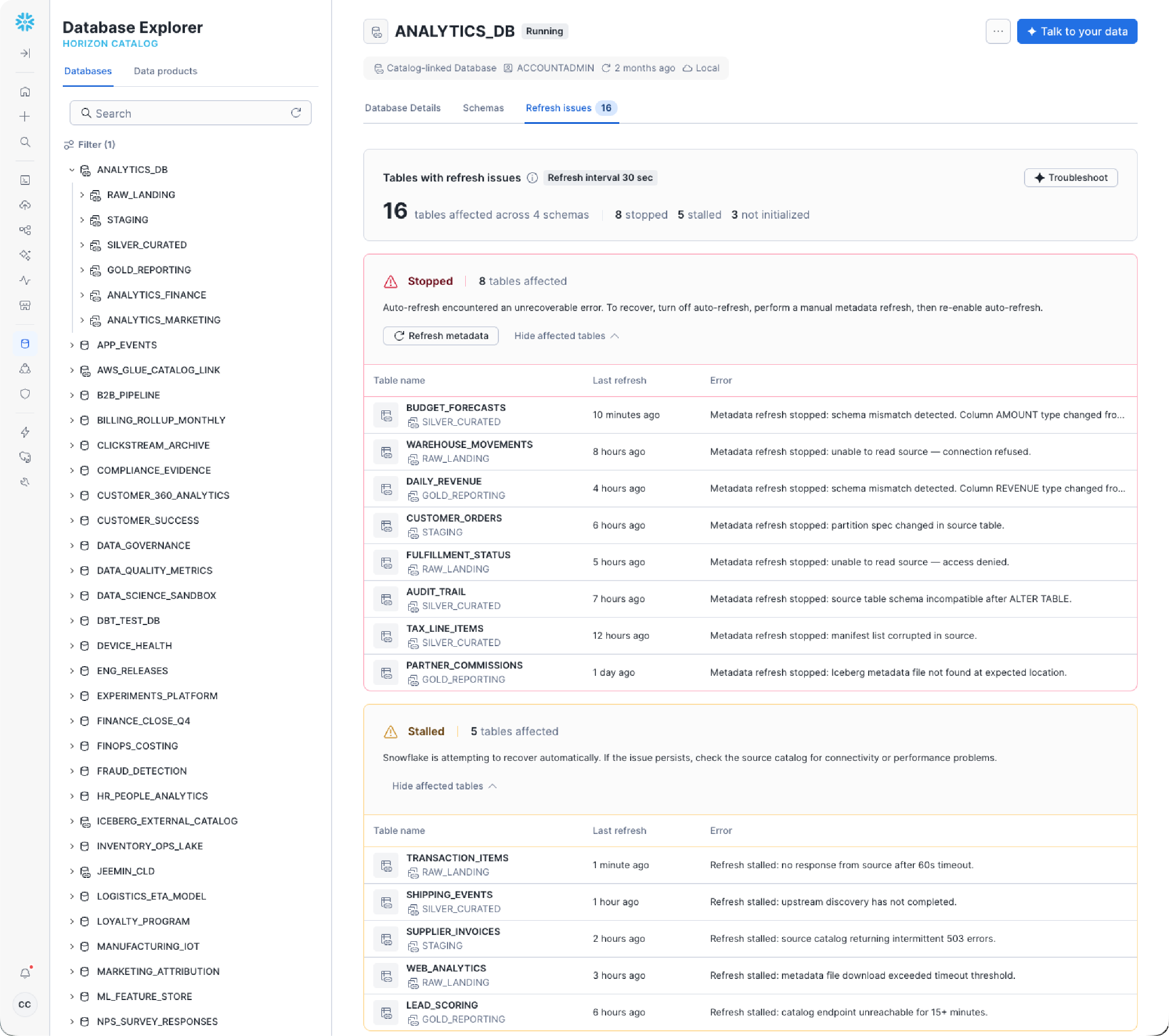
La resilienza appartiene alla data foundation, non a un progetto separato. La replica e il failover delle Managed Iceberg di Snowflake, presto in GA, estendono la replica e il failover degli account alle Iceberg Tables gestite da Snowflake, aiutando i team a rendere la loro data foundation open più resiliente alle interruzioni. La resilienza diventa ancora più solida con Optimized Refresh, una nuova feature di replica per i failover group ora in public preview. Basato sul motore di replica log-based di nuova generazione di Snowflake, l’optimized refresh traccia le modifiche nel momento in cui si verificano e applica solo ciò che deve essere aggiornato. I clienti in preview hanno registrato prestazioni di replica più rapide da 1,6 a 22 volte, aiutando i team a ridurre i target di Recovery Point Objective (RPO) per i workload mission-critical, mantenendo costi prevedibili in base al volume di dati replicati.
Grazie a queste funzionalità integrate nella piattaforma Snowflake, i team possono eseguire il failover di dati, applicazioni e pipeline con un impatto operativo minimo e senza riprogettare i loro ambienti. Questo dà alle organizzazioni la sicurezza di puntare tutto su Iceberg senza sacrificare la resilienza operativa richiesta dai loro workload critici.
Pieno controllo sui tuoi dati
L’open lakehouse prometteva che i dati si sarebbero spostati di meno e avrebbero lavorato di più. Ma per la maggior parte delle aziende, l’apertura si fermava al formato tabellare. La governance si frammentava, la semantica restava isolata in silos e ogni requisito di produzione richiedeva ancora un progetto personalizzato. L’AI ha reso impossibile ignorare questa frammentazione della governance e della semantica. Gli agenti che ragionano su dati obsoleti e scollegati minano la fiducia proprio nei sistemi che i tuoi team stanno costruendo.
Il lakehouse interoperabile offre ciò che il solo formato non poteva: interoperabilità a ogni livello, dall’archiviazione alla governance alla semantica, in una data foundation connessa in cui ogni elemento rafforza gli altri. Cosa significa questo nella pratica? I tuoi ingegneri scelgono il motore giusto per ogni workload senza duplicare i dati. Il tuo team di governance definisce le policy una sola volta e queste valgono su Snowflake, Apache Spark, Trino e altro ancora. Il tuo patrimonio Iceberg è osservabile, verificabile e resiliente senza un progetto operativo separato. E le tue iniziative di AI funzionano fin dal primo giorno su dati governati e semanticamente ricchi.
Questo è il vero pieno controllo sui tuoi dati. Non uno slogan, ma un principio operativo. Progetta la tua architettura in base a ciò che la tua azienda richiede e a ciò che l’AI esige, non a ciò che il tuo vendor consente.
La data foundation interoperabile è qui.
Sviluppa su di essa.
Per iniziare a riconquistare il pieno controllo sui tuoi dati, visita la pagina Interoperable Lakehouse sul sito Snowflake ed esplora le soluzioni Snowflake. Scopri di più scaricando l’ebook gratuito “Building the Interoperable Lakehouse: Data Strategies for AI Leaders” o guardando il webinar TDWI, con James Roland-Jones, Director of Product Management di Snowflake. Poi, mettiti alla prova con questo laboratorio virtuale, “Build a Multi-Engine Stack on Snowflake Storage for Iceberg and Horizon Catalog”.
Dichiarazioni previsionali
Questo contenuto contiene dichiarazioni previsionali, anche relative alle nostre future offerte di prodotto, e non costituisce un impegno a fornire alcuna offerta di prodotto. I risultati e le offerte effettivi potrebbero differire e sono soggetti a rischi e incertezze noti e ignoti. Per maggiori informazioni, consulta il nostro ultimo modulo 10-Q.

Apache Ossie (Incubating): il nuovo nome di Open Semantic Interchange

OpenAI GPT 5.6 è disponibile su Snowflake Cortex AI

Perché gli esperti di marketing devono possedere il proprio context layer per l’AI
