Certified Solution
Advance Snowflake Native Code Deployment
Snowflake Staff
Overview
The Solution Installation Wizard helps package code (e.g. Native Apps, Streamlit UIs, and more) securely and safely into consumers’ Snowflake environments. This wizard is listed in the Snowflake Marketplace for any consumer to install and leverage.
Examples of where one might want to implement the Solution Installation Wizard include:
- Deploying a Native App to a partner as a Provider back to your Snowflake account
- Deploying your Streamlit App to a Consumer through an easy wizard
- Sharing scripts, procedures, or functions that assist a Consumer in getting set up with logic that you wish to provide
Solution Architecture: Solution Installation Wizard
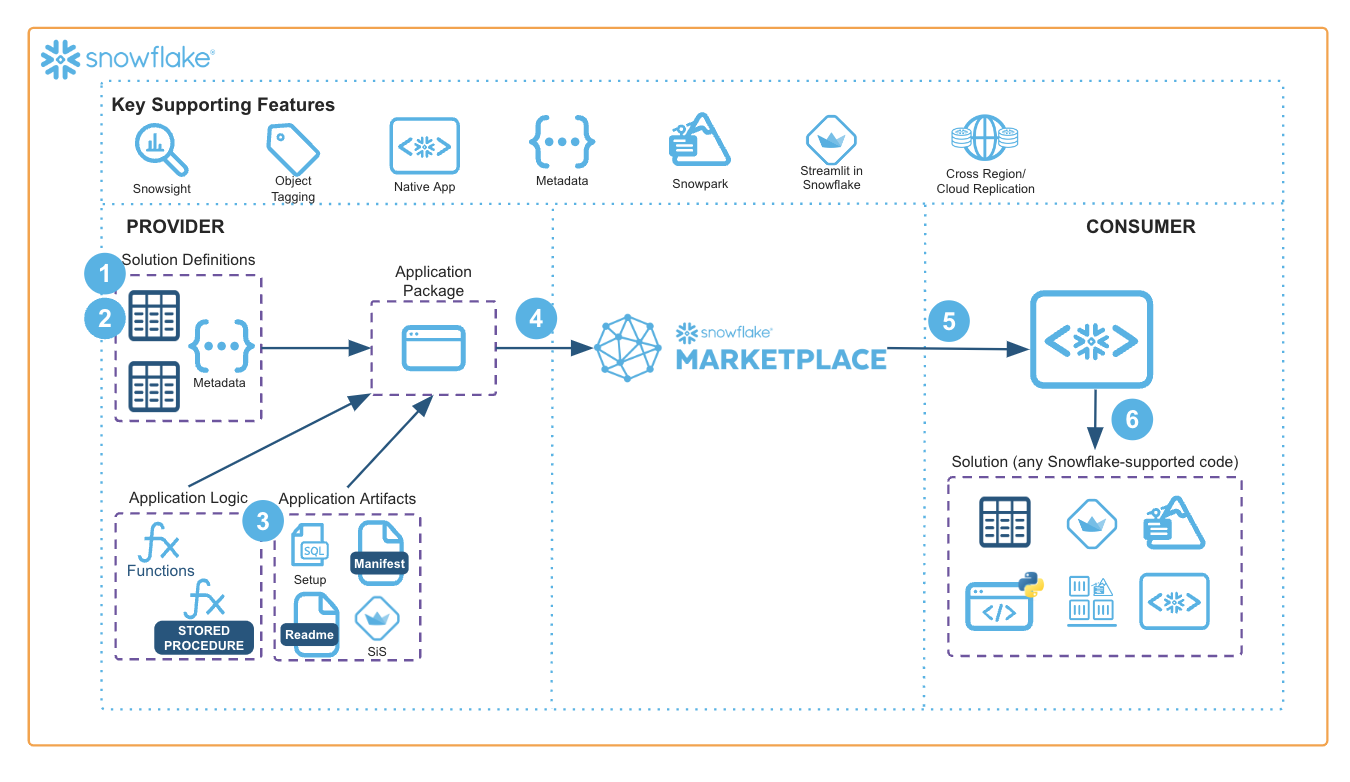
- The Provider configures script steps into metadata tables and wraps them into a Native App
- The Provider publishes the Native App to the Snowflake Marketplace
- The Consumer installs the Native App into their Snowflake instance
- The Consumer launches the included Streamlit interface and is walked through the installation process
Get Started
Updated 2026-05-11
This content is provided as is, and is not maintained on an ongoing basis. It may be out of date with current Snowflake instances