
General Data Protection Regulation (GDPR) governs how personal data must be collected, processed, and erased, among other requirements. Here’s an introduction to GDPR, common “right to be forgotten” options supported by Snowflake, common reference architecture patterns, and best practices for implementing architecture that can help support your GDPR compliance obligations in your organization using powerful and easy-to-use features in Snowflake.
Why is GDPR relevant?
GDPR is a European Union (EU) regulation governing the protection and processing of EU personal data. GDPR focuses on securing personal data, regulating how the data will be handled, and monitoring how the entities processing the data will do so—always with the data subject’s rights at the forefront.
But, it’s not only European countries that need to follow these regulations. If your business touches EU data in any capacity, by providing goods or services to EU citizens, tracking for intent-based marketing tactics, data sharing, or any other data processing, it is likely you are legally obligated to satisfy the requirements of GDPR. Should a business not comply, penalties can be steep, including fines of up to 20 million euros or 4% of global annual revenue from the previous year.
Who does GDPR protect?
GDPR protects natural persons (i.e., individuals, and not entities) within the EU. GDPR covers any personal data or information that may be used to identify a person, whether directly or indirectly. Pseudonymous data (tokenized or encrypted) is still considered personal data since pseudonymization can be reversed.
EU citizens living outside the EU are still protected under the scope of GDPR.
GDPR key terms
Data subject: An identifiable living person, resident in the EU or UK on whom personal data is held by a business or organization or service provider
Processor: The entity that processes the data on the instructions of the controller (e.g., Snowflake)
Controller: The entity that determines the purposes and means of processing personal data (e.g., Snowflake customer)
Responsibilities of the processor vs. controller
Organizations must consider GDPR as a part of the reference architecture design process, not an afterthought. As a processor, Snowflake provides several features to help enable an organization’s compliance with GDPR, but ultimately, it is an organization’s responsibility, as the controller, to design architecture that supports their GDPR compliance obligations.
Snowflake customers are responsible for complying with GDPR independent of Snowflake. Snowflake provides customers with several controls that may be deployed to retrieve, correct, delete, or restrict personal data. These help enable customers to meet their compliance obligations within GDPR, including the obligation to respond to requests coming from data subjects or applicable data protection authorities with respect to data in Snowflake. Beyond the technical functionality, a customer and Snowflake will also agree to data protection terms that outline each party’s obligations under GDPR, including limitations on the use of data by Snowflake as the processor, security obligations and incident response, listing sub-processors of the service and updates to that list, and support to enable completion of data subject requests.
High-level features
Snowflake features that are commonly used to better enable GDPR compliance include time travel, cloning, data classification, swap, row access policies, dynamic masking policies, secure views, anonymization techniques, and enterprise SIEM integration.
Think of these individual features as building blocks. Depending on organizational requirements, a company can leverage one or several of them to build the solution needed.
Common reference architecture patterns and solutions
GDPR compliance can be extremely challenging without a well-thought-out database architecture, especially for handling the “right to erasure (right to be forgotten.)” Once an individual’s personal data is requested, organizations generally have 30, but in some cases up to 90 days, to delete the individual’s personal data from their database.
Organizations have to determine how data is forgotten, flagged, anonymized, or deleted, and they must have clear guidelines in place for data audits.
The foundation of a preparation effort should start with tagging all data, whether it is sensitive, non-sensitive, personal data, etc. Object tagging and data classification features of Snowflake can help you easily determine which data is important and tag it accordingly. Large organizations with massive volumes of data across multiple data lakes need an effective cataloging strategy to easily identify the personal data when the situation arises.
Any data architecture should be able to easily identify the personal data. There are multiple ways to do this. The most common approach is to organize the personal data in a separate account, database, schema, or at the table level.
For example, if a Snowflake customer’s table has 300 columns and 50 of them contain data the customer has identified as personal data, the customer can create two different tables (Customer_personal_data and Customer_Non_personal_data), and link them by using an unintelligent key. This way, the Customer_personal_data table can be dropped and all personal data deleted without compromising the Customer_Non_personal_data. Setting these parameters ahead of time saves the business from costly updates to an all-encompassing data table.
The entire data modeling of this is beyond the scope of this blog post. This overview is just to give an idea of the art of the possible and is mostly applicable for greenfield implementations.
Deletion of data
Deletion of data is a legal interpretation requiring the deletion of records from the data warehouse from online tables during an ETL process. Depending on your requirements, this can be achieved by setting the time travel/data retention time setting on the table level, and simply deleting the data in a timeframe that fulfills your obligations under GDPR.
Snowflake has three types of tables:
- Permanent tables: Set data retention time to 32 days (plus fail-safe of 7 days)
- Transient tables: Set data retention time to 1 day (no fail-safe)
- Temporary tables: Set data retention time to 1 day (no fail-safe)
Consider doing the batch deletions once a month with the help of some audit tables that mark what data needs to be deleted.
Conserving data for audits
There’s a method of deletion of data that requires deleting records from the data warehouse during an ETL process while keeping a separate version of the “forgotten” data for auditing purposes:
- Create a transient table (e.g., cust_phi_clone), cloning a production table containing personal data (e.g., customer_phi). You can choose to set zero time travel.
- Make a copy (in or out of Snowflake) of the data that needs to be kept.
- Remove the data under investigation from both tables. This data does not remain. This method eliminates the data from time travel as well. The only place to recover this data would be from a backup snapshot for audit purposes.
- SWAP both the tables. Swapping essentially removes the time travel from the production table.
- Restrict the access to cust_phi_clone to only admins.
Use secure views and row access policies to deal with logical deletion patterns or patient opt-outs. In cases where a patient wants to opt out of sharing their information, the prescriber does not want to reveal the information, or any information for patients under the age of 18 cannot be shared, this is the one way to handle it.
To help meet personal data anonymization requirements that may be part of regulations, customers can implement row access policies that restrict access to certain rows based on the role of the user login; for example, someone from the marketing department would not be able to see sales data.
Additionally, dynamic data masking policies are an option. Depending on the role the user logs in with, data can be masked or redacted; for example, someone in human resources is allowed to only see salary details.

Setup audit control framework:
You can also maintain an audit control framework that tracks the data subject requests (who has requested, when, what data was deleted, rolled back, etc.). This can help for your audit requests and also helps to delete the personal data in case of accidental rollbacks, etc. Snowflake’s new feature, Access History, also helps you to easily determine who has accessed what data, and when (with high-level data lineage). This feature helps organizations respond to audit requests quickly and confidently.
Backing up of databases
Some customers wanted to keep the backup of the data for auditing purposes. As an example, keep the time travel for main customer data to be 32 days.
Use scheduled tasks to create a monthly backup as follows:
CREATE OR REPLACE TRANSIENT DATABASE prd_ent_presentation_db_bu_2020_01
CLONE prd_ent_presentation_db AT (TIMESTAMP =>
to_timestamp_tz('01/01/2020 00:00:00', 'mm/dd/yyyy hh24:mi:ss'))
DATA_RETENTION_TIME_IN_DAYS = 0;- Restrict the access to backup databases to only a set of administrators/stewards.
- Develop an automatic process to purge the older databases (based on the organization’s policy/GDPR restrictions).
DROP DATABASE prd_ent_presentation_db_bu_2020_01; --This data is
instantly and irrevocably removed from Snowflake.Note: Some of these examples don’t delete a user’s data (i.e., physical deletion). Rather, logical deletions were used to allow auditing, “unforgetting” information, and more. Each company’s legal team should determine whether this is sufficient given the legal and regulatory requirements to which they are subject.
Secure Data Sharing helps to mitigate GDPR risk
Secure Data Sharing ensures no data has to be copied or transferred between accounts in a business ecosystem to allow access. Instead, everyone has access to a live, highly governed data set.
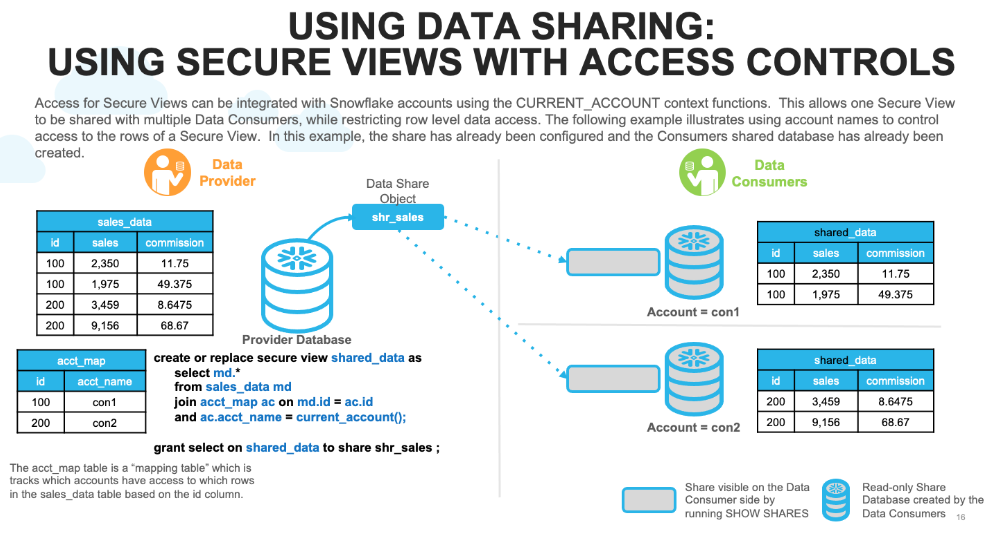
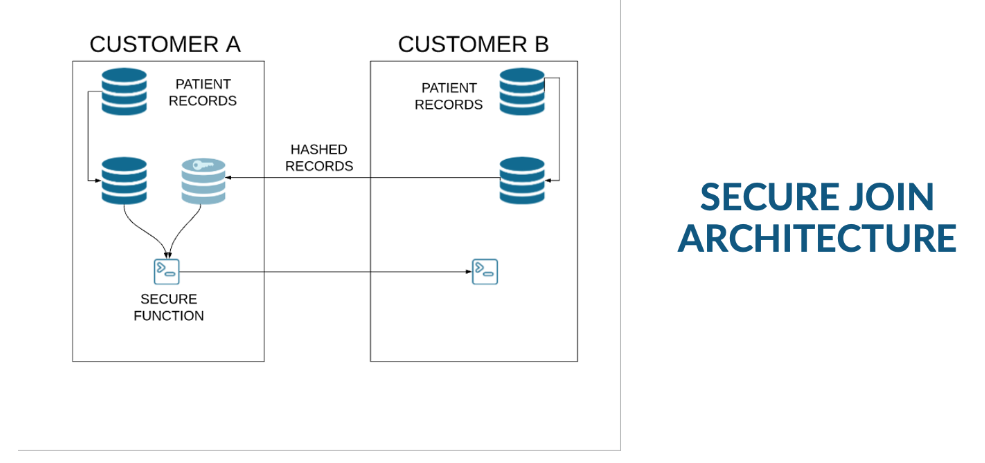
With Secure Data Sharing, data sets can be accessible in and out of the country or region. There are also architectures to deal with scenarios such as “this subject area data can not leave the country/region,” and others.

The patterns outlined above are options that Snowflake provides to help enable a customer with their compliance with GDPR. This is not legal advice. Nothing herein is intended to certify or otherwise guarantee that any specific methods will comply with a regulation, including GDPR. Each customer should review applicable privacy requirements and, based on review by your internal privacy and legal teams, determine acceptable data solutions. No guarantees will be made by Snowflake, either before, during, or after an engagement, that a specific solution will satisfy compliance with any applicable legal or regulatory requirements.