
At TCS, we help companies shift their enterprise data warehouse (EDW) platforms to the cloud as well as offering IT services. We’re extremely familiar with just how tricky a cloud migration can be, especially when it involves moving historical business data.
Choosing a migration approach involves balancing cloud strategy, architecture needs and business priorities. But there are additional considerations when dealing with historical business data. This data has typically undergone multiple cycles of redesign, changes and upgrades, and its volume is often measured in terabytes or petabytes. Business contextual frameworks and design patterns are tightly bound to existing data models, and regulatory requirements may demand that historical data be stored as is and remain readily available for auditing.
A “lift and shift” migration approach handles all of these requirements by moving the business workload and data together. This simplifies change management and reduces impact and downtime for the rest of the business. Migrating historical data with the right quality and format ensures readiness for reporting as well as data readiness for use in AI applications. By leveraging the data for AI, an enterprise can fast-track the journey around ML workloads—predictive, prescriptive, descriptive and cognitive analytics. And when moving to Snowflake, you get the advantage of the Data Cloud’s architectural benefits (flexibility, scalability and high performance) as well as availability across multiple cloud providers and global regions.
In this blog post, we’ll take a closer look at the details that can help decision-makers successfully plan and execute an optimal lift-and-shift cloud data migration strategy for their business. We’ll also present some best practices for overcoming common migration challenges and provide an overview of migrating historical data to Snowflake using the TCS Daezmo solution suite.
Tips for choosing the right migration approach
Identifying the best migration approach for your organization starts with a better understanding of your historical data environment. Information gathering is the first mandate; begin by asking stakeholders, application owners, DBAs and others questions like these:
- What is the driving force behind your EDW migration? Are there expiring licenses or other hard deadline dates you need to consider?
- How many tables and views will be migrated, and how much raw data?
- Are there redundant, unused, temporary or other types of data assets that can be removed to reduce the load?
- What is the best time to extract the data so it has minimal impact on business operations? Are there any upcoming release cycles that could affect the data model and workloads?
It’s critical for IT experts to be clear-eyed about bandwidth availability between on-premises data centers and cloud providers for the data migration, and to identify and factor in any workload dependencies. They should also designate all legacy data assets as hot, cold or warm to finalize the migration plan and the refresh and sync strategies.
At the same time, operations teams need to determine lead times for staging server procurement, as well as manage the security approvals needed to move data assets from on-premises servers.
Best practices for migrating data from legacy platforms to Snowflake
Once the initial tech and operational factors are solidified, there are four main steps in a migration plan: data extraction, transfer, upload and validation (see Figure 1).
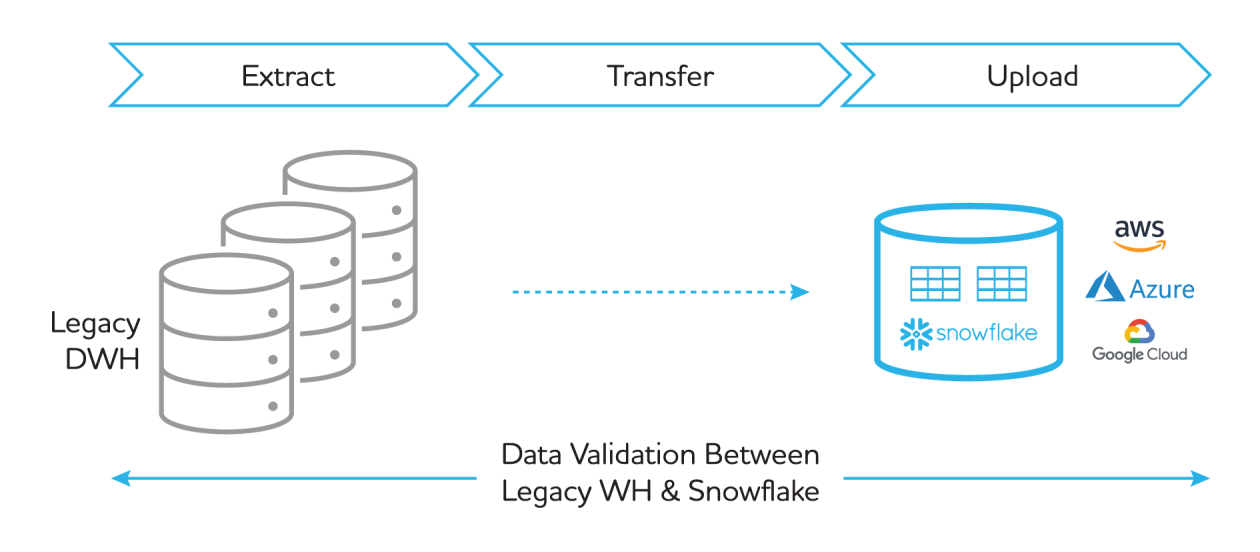
Figure 1: Extract, transfer, upload and validate are the four main steps of a data migration plan.
Here’s a look at the challenges you may face in each step, and how to overcome them:
Step 1: Efficiently extract data from the source system
Challenges: Efficient extraction is often stymied by low compression ratios of legacy data, long-running jobs or resource contention on certain tables, and restrictions on how many parallel connections can be opened on the source system.
Best practices
- Accelerate throughput by extracting data solely from read-only or secondary instances. If a read-only instance isn’t available, you can load backup files from production to a lower environment and extract from there.
- Increase extraction speed by using native extractors from the legacy system and staging extracted data on a staging server or NFS.
- Avoid data corruption during extraction by selecting the right text delimiter tool for the data set.
Step 2: Transfer data to the cloud
Challenges: Limited network bandwidth or highly variable throughput during peak and non-peak times pose a barrier to swift data transfer. High data volumes in each iteration can also affect data transfer rates. Moving files introduces the chance for data corruption, especially in large files.
Best practices
- Conduct a proof of concept during the analysis phase to identify windows of maximum throughput during peak, non-peak and weekend hours. Because network bandwidth is often shared between multiple projects, select the maximum available bandwidth instead of total bandwidth.
- Use compressed files when possible.
- If you have high data volumes, limited speed and overall low timelines, consider device-based data transfer (which may need additional organizational approvals).
Step 3: Upload data to the Snowflake Data Cloud
Challenge: If object storage is available within the customer subscription, you could use it as an external stage for data upload to Snowflake; if it’s not available, you’ll need to use the internal stage for data upload. High data volume growth in the legacy platform can also mean a shorter freeze period or cutover window, impacting the timing of incremental data synch-ups after the initial migration. Also, incorrectly sized clusters can increase your credit consumption rate.
Best practices
- Use native Snowflake data loader utilities for optimal throughput—and use the error-handling functionalities in Snowflake native loaders to quickly identify errors in the data load.
- Use separate data warehouses for cost-effective data loading. Size the warehouse based on your data volume and set auto-scaling policies configured with auto-suspend and resume capabilities. Create resource monitoring on the Snowflake account, and set compute, credit limit and notification triggers.
- When using native loaders, keep your file size between 100-250 MB for optimal throughput. Partition the data in the stage into logical paths to reduce the number of folders and sub-folders. Once files are loaded, move them out of the Snowflake stage (use the purge option within the copy command or remove command).
Step 4: Validate migrated data
Challenges: Manual validations and certifications are time-consuming and error-prone. Assessing data quality requires additional time and effort from the team.
Best practices
- Take advantage of custom-built frameworks, industry solutions and accelerators (including those from TCS) to perform validations faster and more efficiently.
- Perform checksum-based validation to verify that files were not corrupted during transfer, and make integrity checks referential to ensure data-level relationships are intact between tables.
- Hone analytics and reporting tools so they function properly in the new environment. Analytics and report testing must also be redirected, which entails careful testing in its own right. High-quality, validated data is key for reporting purposes as well as for AI/ML workloads.
- Capture validation output in a text report and retain it in case you need to do further analysis or take corrective measures.
Building a data migration framework with TCS Daezmo Data Migrator Tool
There are several options for migrating data and analytics to a modern cloud data platform like Snowflake. Using a data migration framework, however, allows you significant flexibility. This is where the TCS Daezmo solution suite comes in. It combines several migration approaches, methodologies and machine-first solution accelerators to help companies modernize their data and analytics estate to Snowflake. Daezmo has a suite of accelerators around data and process lineage identification, historical data migration, code conversion, and data validation and quality. TCS Data Migrator Tool has connectors for standard RDBMS, warehouse and file systems that you can leverage for historical data migration.
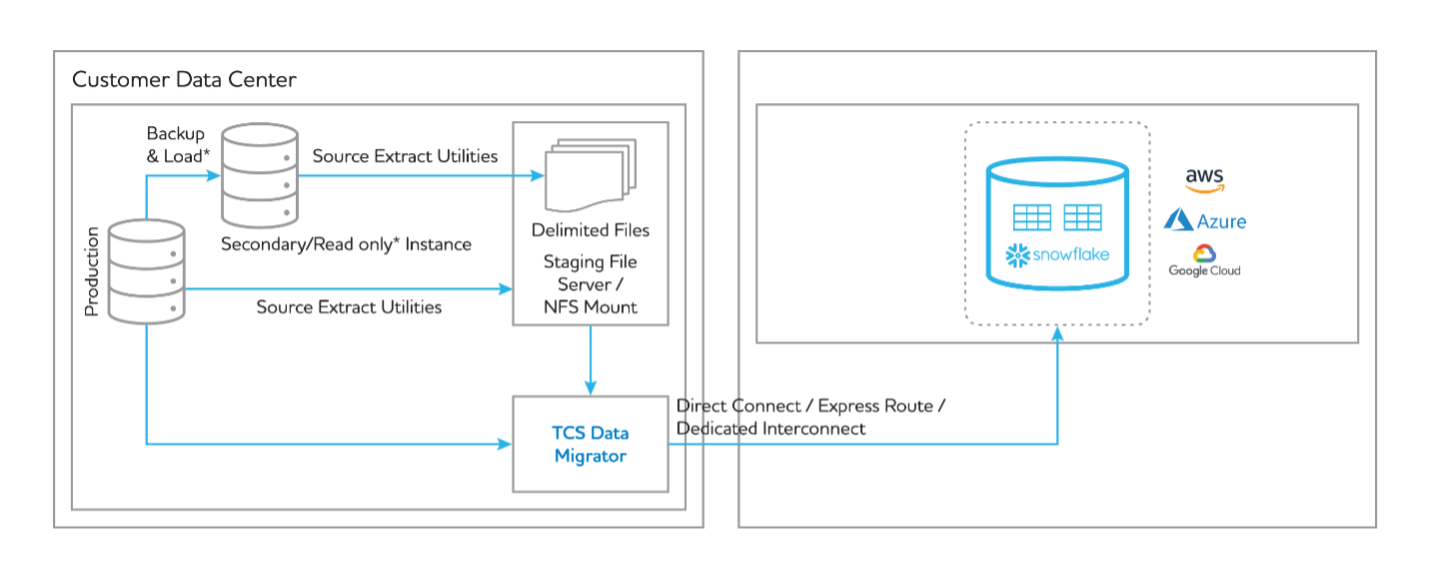
Figure 2: Historical data migration using TCS Daezmo Data Migrator Tool.
Here’s what the four-step migration process looks like with TCS Data Migrator Tool:
- Extract data using native extractors for the legacy platform. Use delimited text or other suitable data formats (preferably compressed, as noted in the earlier best practices) and store data in the staging server or NFS. Use your language of choice to build a generic framework that triggers native extractor scripts driven by metadata inputs to handle multiple tables and business conditions. As an alternative option for cases with low data volumes and a large migration window, you can extract data using TCS Data Migrator Tool and leveraging a JDBC driver.
- Use the TCS Data Migrator Tool SFTP connector to extract the data from the staging server/NFS and upload the data to Snowflake’s internal or external stage.
- Upload data to Snowflake tables using TCS Data Migrator Tool’s built-in integration with native loaders—COPY INTO for bulk load and MERGE INTO for incremental data loads.
- Validate your migrated data.
By streamlining the process of moving data into the Snowflake destination, TCS Data Migrator Tool helps fast-track historical data migration. The time savings can be especially crucial for organizations facing strict migration deadlines, such as a company facing a time-sensitive data migration due to a license expiration, for example.
One leading bank in the EU needed to move its large financial and regulatory data warehouse off of its RDBMS before the license expired in 14 months—and the data had to be migrated as is. The bank used TCS Data Migrator Tool to migrate historical data for non-production environments holding about 300 TB of data. Because of the high data volume, the team used TCS Data Migrator Tool’s integration with native platform utilities to complete the task. For the more than 1 petabyte of data in the production environment, the short migration timeline and network bandwidth limitations meant a device-based approach was the best choice. The team used an AWS Snowball storage device; after loading data into S3 buckets, they developed custom scripts to load data into Snowflake tables. The fully operational financial and regulatory platform was up and running on Snowflake within months.
Making data migrations as smooth as possible
Data-driven organizations know that careful data management is crucial to their success—perhaps doubly so when migrating enterprise data warehouse platforms to cloud-based platforms like Snowflake. Enterprise-level strategic and tactical decisions are driven by outcomes generated by analytics on top of historical data; therefore, historical data migration needs to be treated as of paramount importance. The best practices outlined in this post are the result of TCS’s significant experience with various migration approaches and options, and the capabilities of our TCS Daezmo data warehouse modernization solution. We are proud to work with Snowflake to make data migrations as smooth as possible for our customers.
Learn more about TCS and the TCS Daezmo solution suite here. To learn more about migrating to the Snowflake Data Cloud, visit snowflake.com/migrate-to-the-cloud

