
Enterprises are experiencing an explosive growth in their data estates and are leveraging Snowflake to gather data insights to grow their business. This data includes structured, semi-structured, and unstructured data coming in batches or via streaming. Alongside our extensive ecosystem of ETL and data ingestion partners who help move data into the Data Cloud, Snowflake offers a wide range of first party methods to meet the different data pipeline needs from batch to continuous ingestion, which include but are not limited to: INSERT, COPY INTO, Snowpipe, or the Kafka Connector. Once that data is on Snowflake is when you can take advantage of powerful Snowflake features such as Snowpark, secure Data Sharing, and more to derive value out of data to send to reporting tools, partners, and customers. At Snowflake Summit 2022, we also made the latest announcements around Snowpipe Streaming (currently in private preview), and the new Kafka connector (currently in private preview) built on top of our streaming framework for row-set low latency streaming.

In this blog series, we will explore the ingestion options and the best practices of each. Let’s start with the simplest method of data ingestion, the INSERT command. This is a suitable approach to bringing a small amount of data, it has some limitations for large data sets exceeding the single digit MB range, particularly around ease of use, scalability, and error handling. For larger data sets, data engineers typically have the option to use a variety of ETL/ELT tools to ingest data, or preferably use object storage as an intermediate step alongside COPY INTO or Snowpipe. Customers who need to stream data and use popular Kafka-based applications can use the Snowflake Kafka Connector to ingest Kafka topics into Snowflake tables via a managed Snowpipe. Snowflake also allows data engineers to query data stored in external stages using the External Table options. An in-depth description of all the available ingestion options, fitting a variety of use cases, is a topic for follow-up blog posts.
This blog post will cover the two most widely used and recommended file based data ingestion approaches: COPY INTO and Snowpipe. We will outline the similarities and differences between both and recommend best practices informed by the experience of over 5,000 customers loading data to the Snowflake Data Cloud.
COPY INTO vs. Snowpipe
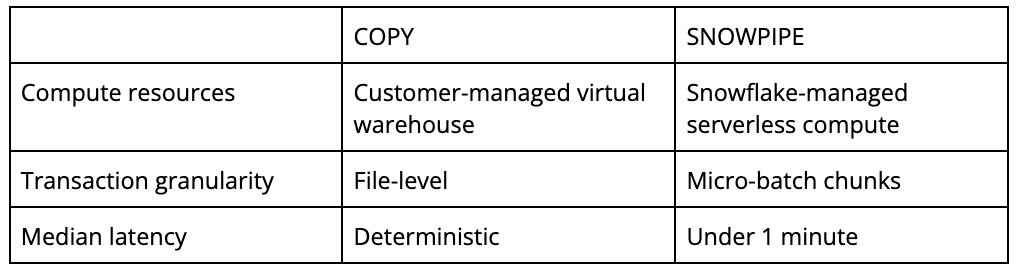
The COPY command enables loading batches of data available in external cloud storage or an internal stage within Snowflake. This command uses a predefined, customer-managed virtual warehouse to read the data from the remote storage, optionally transform its structure, and write it to native Snowflake tables.
These on-the-fly transformations may include:
- Column reordering
- Column omission
- Casts
- Text truncation
COPY fits nicely in an existing infrastructure where one or more warehouses are managed for size and suspension/resumption to achieve peak price to performance of various workloads, such as SELECT queries or data transformations. In the absence of such an existing infrastructure managing warehouses, Snowpipe should be considered for simplicity and convenience.
COPY provides file-level transaction granularity as partial data from a file will not be loaded by default ON_ERROR semantics. Snowpipe does not give such an assurance as Snowpipe may commit a file in micro-batch chunks for improved latency and availability of data. When you are loading data continuously, a file is just a chunking factor and is not seen as a transaction boundary determinant.
Snowpipe is designed for continuous ingestion and is built on COPY, though there are some differences in detailed semantics listed in the documentation. In distinction to COPY, Snowpipe runs a serverless service, meaning that there are no virtual warehouses to manage, with Snowflake-managed resources instead that automatically scale to changing workloads. This frees you from the burden of managing your warehouse, scaling it for a variable load, and optimizing it for the best cost-performance balance. It also shifts the burden of monitoring file loading from the customer to Snowflake.
Considerations for COPY
The COPY command relies on a customer-managed warehouse, so there are some considerations to consider when choosing the appropriate warehouse size. The most critical aspect is the degree of parallelism as each thread can ingest a single file at a time. The XS Warehouse provides eight threads, and each increment of warehouse-size doubles the amount of available threads. The simplified conclusion is that for a significantly large number of files, you would expect optimal parallelism for each given warehouse size—meaning halving the time to ingest the large batch of files for every upsize step. However, this speedup can be limited by factors such as networking or I/O delays in real-life scenarios. These factors should be considered for larger ingestion jobs and might require individual benchmarking during the planning phase.
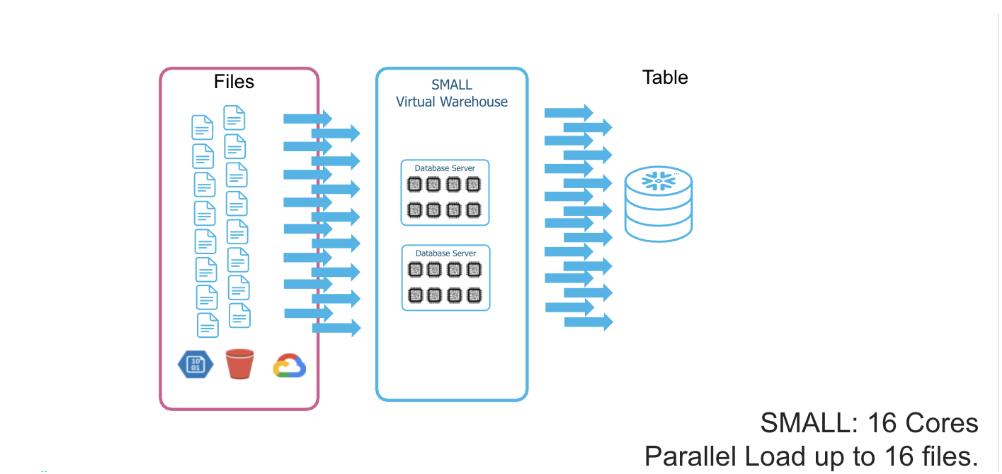
The unique capabilities of Snowflake isolating warehouses, their individual sizing, and the per-second billing make it fast, efficient, and fault-tolerant to ingest separate tables in parallel. The number of files, the size, or the format can vary between the table sources when loading multiple tables. In this case, we suggest choosing the appropriate warehouse size according to the considerations for each data characteristic.
Snowpipe API vs. auto-ingest Snowpipe
The Snowflake-provided serverless resources can operate for all operation types: batched, micro-batch, and continuous.
For most use cases, especially for incremental updating of data in Snowflake, auto-ingesting Snowpipe is the preferred approach. This approach continuously loads new data to the target table by reacting to newly created files in the source bucket.
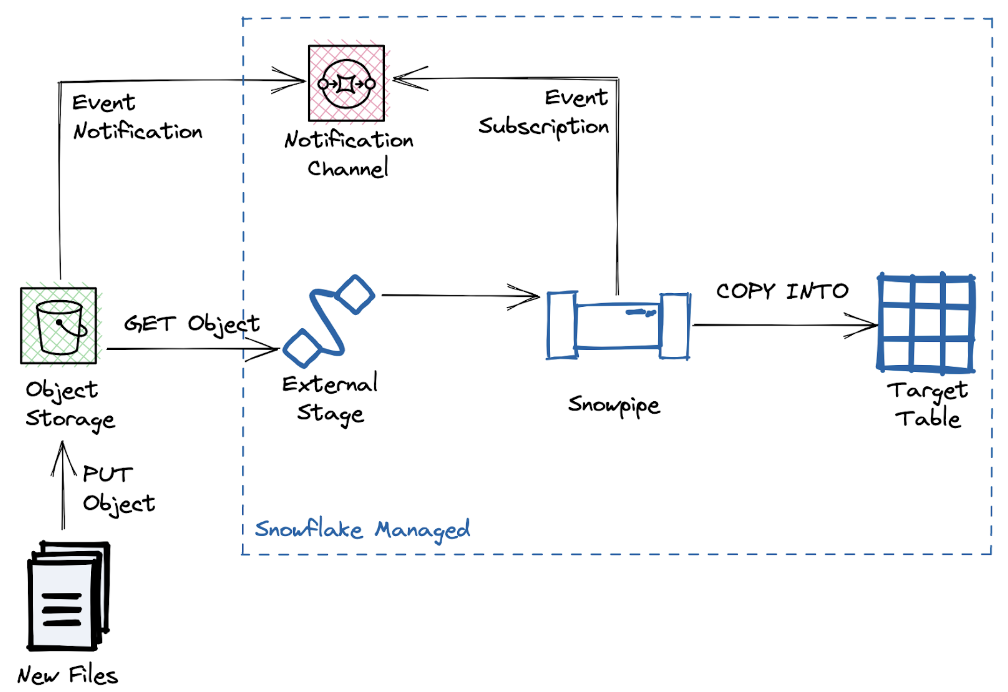
Snowpipe relies on the cloud vendor-specific system for event distribution, such as AWS SQS or SNS, Azure Event Grid, or GCP Pub/Sub. This setup requires corresponding privileges to the cloud account to deliver event notifications from the source bucket to Snowpipe.
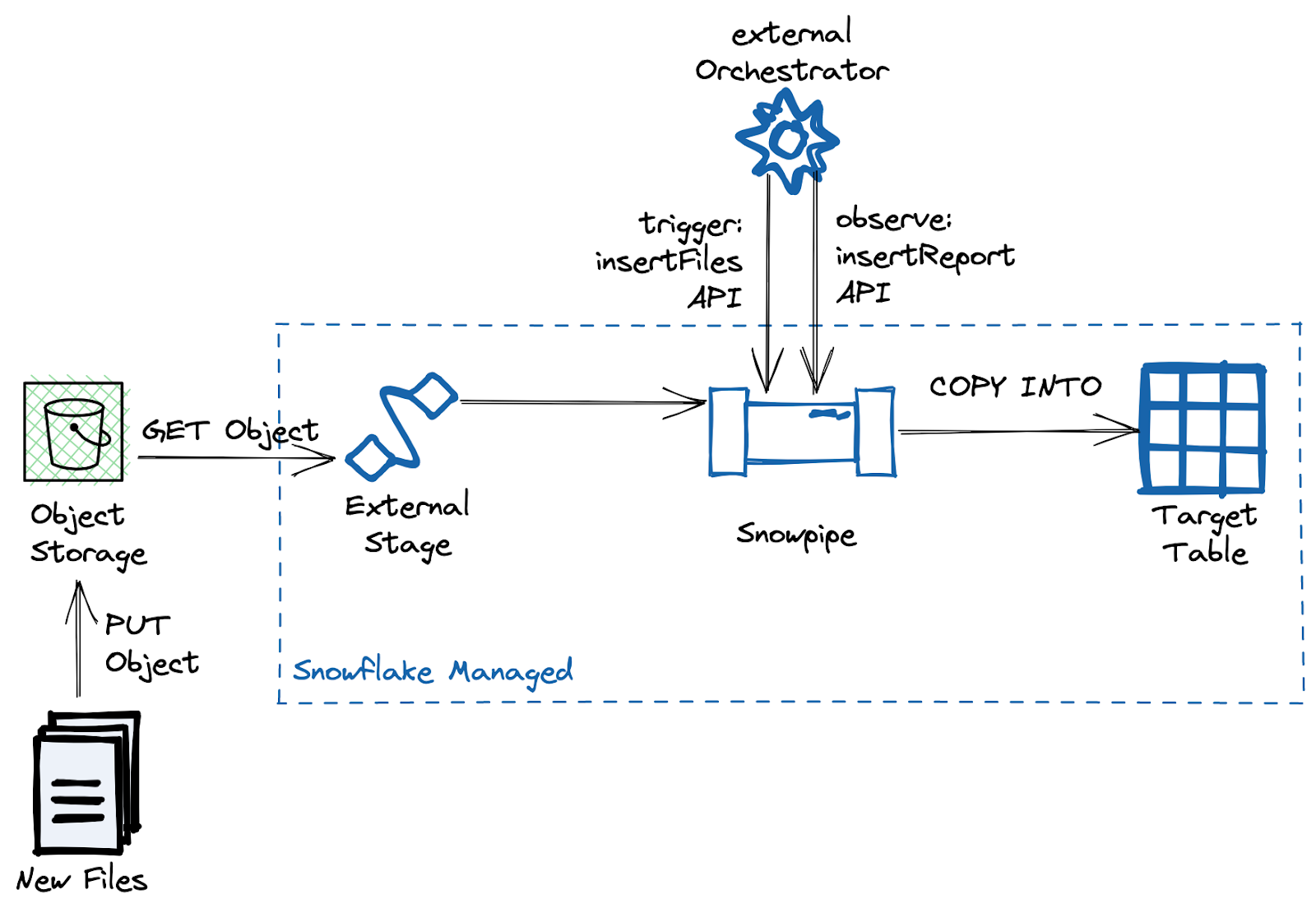
Whenever an event service can not be set up, or an existing data pipeline infrastructure is in place, a REST API-triggered Snowpipe is a suitable alternative. It is also currently the only option if an internal stage is used for storing the raw files. Most commonly, the REST API approach is used by ETL/ELT tools that don’t want to put the burden of creating object storage on the end user and instead use a Snowflake-managed Internal Stage.
Here is an example of how to trigger a Snowpipe API for ingestion: https://medium.com/snowflake/invoking-the-snowpipe-rest-api-from-postman-141070a55337
Checking status of ingestion
COPY INTO is a synchronous process which returns the load status as output. Whereas for Snowpipe, execution of the file ingestion is done asynchronously, so processing status needs to be observed explicitly.
For all Snowpipes as well as COPY INTO, the COPY_HISTORY view or the lower latency COPY_HISTORY function is available. Generally, files that fail to load need to be looked at by someone, so it is often good to check COPY_HISTORY less frequently than the typical file arrival rate. For all Snowpipes, error notifications are also available to publish events to your event handler of choice (AWS SNS, Azure Event Grid, or GCP Pub/Sub).
Additionally, for the API-triggered Snowpipes, you can use the insertReport and loadHistoryScan API endpoints to track the ingestion. While the insertReport endpoint returns events for the last 10 minutes only, this constraint can be configured using the loadHistoryScan endpoint. In any case, insertReport should be favored over the loadHistory as excessive usage of the latter tends to lead to API throttling.
Initial data loading
The three options introduced in this series can also be used for initial data loading. Like other use cases, each option has its advantages and drawbacks, but in general we suggest starting with the evaluation of auto-ingest first, mainly because of its simplicity and scalability.
Snowpipe auto-ingest relies on new file notifications. A common situation in which customers find themself is that the required notifications are not available. This is the case for all files already present in the bucket before the notification channel has been configured. There are several solution approaches to this. For example, we recently helped a large customer load hundreds of TB of data for an initial load where it made more sense to produce fake notifications to the notification channel pointing to the available files.
Where this approach is unfeasible, or especially for smaller buckets or where bucket listing is reasonable, you can trigger ingestion using the REFRESH functionality:
alter pipe <pipe_name> refresh PREFIX = ‘<path>’ MODIFIED_AFTER = <start_time>
This will list the bucket and begin ingesting files that were recently modified up to the last 7 days.
However, it is also possible to run COPY jobs and monitor them manually as the initial loading is typically a time-bound activity. The decision depends on the control vs. automation tradeoff and may be influenced by the cost considerations in the next section. Otherwise, COPY provides greater control with the attendant responsibility to manage the warehouse and the job duration. Here are 2 important considerations while using COPY for initial data loading:
- In the case of data skew, COPY jobs that don’t have enough files will not utilize the warehouse efficiently. For example, if you are only loading less than 8 files, an XS warehouse will be just as fast as a 2XL. Therefore it is important to consider the COPY degree of parallelism mentioned earlier.
- A single COPY job loading millions of files can potentially run for a long time, and the default job timeout is 24 hours. To avoid hitting this limit, you would need to split the overall job into smaller COPY jobs. You can leverage your data path partitioning whenever possible, as it is always more efficient for COPY to list and load data from the explicit path where your data exists rather than traverse the entire bucket.
Recommended file size for Snowpipe and cost considerations
There is a fixed, per-file overhead charge for Snowpipe in addition to the compute processing costs. We recommend files at least above 10 MB on average, with files in the 100 to 250 MB range offering the best cost-to-performance ratio.
At the single digit megabyte or lower range for average file size, Snowpipe is typically not the most cost-effective (in credits/TB) option. COPY may provide a better cost performance depending on the file arrival rate, size of warehouse used, and non-COPY use of the Cloud Services Layer. Ergo, there is no single correct answer below 10 MB, and further analysis is warranted. In general, larger file sizes of at least 100 MB are noticeably more efficient, such that an increase in file size does not change the credits/TB much. However, we also recommend not exceeding 5 GB in file size, to take advantage of parallelization and error handling capabilities. With a larger file, there is a higher likelihood of an erroneous record being found at the end of a large file that may cause an ingestion job to fail, which will later need to be restarted depending on the selected ON_ERROR option. Snowflake can and does handle much larger files, and customers have successfully loaded files larger in the TB range.
With these file size recommendations in mind, it should be noted that the per-file charge tends to be a small fraction of the overall cost.
File formats
All ingestion methods support the most common file formats out of the box:
- CSV
- JSON
- PARQUET
- AVRO
- ORC
- XML (currently in public preview)
Additionally, these files can be provided compressed, and Snowflake will decompress them during the ingestion process. Supported compression formats like GZIP, BZ2, BROTLI, ZSTD, SNAPPY, DEFLATE, or RAW_DEFLATE can be configured explicitly or detected automatically by Snowflake. In general, the ingestion of compressed files should always be preferred over uncompressed files, as the movement of external assets of the network also tends to become the limiting factor compared to local decompression.
Due to the large set of combinations, it’s not possible to predict the performance of the ingestion of a specific file format configuration exactly even given a file size. The most significant observed impact on data loading performance is the structure of the file (the number of columns or nested attributes in a single record), not the total file size.
With all that said, our measurement indicated that the ingestion of gzip’ed CSV files (.csv.gz) is not only the most widely used but usually the most performant configuration for ingestion. Further, the observations indicate the performance according to the file format listed above, starting with the fastest.
Most of the time the available file format and size is predefined by the source system or already available in object storage data. In this case, it’s not beneficial to split, merge, or re-encode existing files to a different format or size as the gain presumably will not pay back the efforts. The only notable exception for this is the loading of data across cloud regions or cloud vendors, where the transparent compression performed by Snowflake can make a massive difference in egress spending.
How long does it take to ingest and how much does it cost?
Both ingestion time and cost depend on various factors, including:
- Size of the file: the core ingestion time is relative to the content, so the costs tend to be proportional to number of records and file size but not an exact correlation.
- Amount of processing required by your COPY statement: some ingestion jobs invoke complex UDFs that take significant time per row and occasionally can even run out of memory if the data size is not correctly anticipated.
- File format, compression, nested structures, etc all play an impact on how efficiently we can decompress and load the data. An uncompressed file with a large number of columns may take the same amount of time as a compressed file with a small number of columns but has highly nested data structures.
Therefore, it is impossible to answer the above question correctly without measuring it for your specific case. Please note that we currently do not have an ingest-service-specific SLA. However, we have seen that on average P95 latency across deployments, customers, and a range of values for the above factors has been about one minute. This is, of course, a statistical measure, and specific performance for a given customer in a given unit of time may vary considerably.
10 best practices
- Consider auto-ingest Snowpipe for continuous loading. See above for cases where it may be better to use COPY or the REST API.
- Consider auto-ingest Snowpipe for initial loading as well. It may be best to use a combination of both COPY and Snowpipe to get your initial data in.
- Use file sizes above 10 MB and preferably in the range of 100 MB to 250 MB; however, Snowflake can support any size file. Keeping files below a few GB is better to simplify error handling and avoid wasted work. This is not a hard limit and you can always use our error handling capabilities such as ON_ERROR = CONTINUE.
- Keep max field size capped at 16 MB. Ingestion is bound by a Snowflake-wide field size limit of 16 MB.
- Keep your data ingestion process simple by utilizing our native features to ingest your data as is, without splitting, merging, or converting files. Snowflake supports ingesting many different data formats and compression methods at any file volume. Features such as schema detection and schema evolution (currently in private preview) can help simplify data loading directly into structured tables.
- Average measurements across customers are not likely to predict latency and cost. Measuring for a sample of your data is a much more reliable approach beyond the indicative numbers.
- Do check file loading success/failure for Snowpipe using COPY_HISTORY or other options, such as subscribing to Snowpipe error notifications. Also occasionally check SYSTEM$PIPE_STATUS for the health of the Snowpipe.
- Do not expect in-order loading with Snowpipe. Files are loaded concurrently and asynchronously in multiple chunks, so reordering is possible. If an order is essential, use event timestamp in data if possible, or use COPY and load sequentially.
- Leverage your existing object path partitioning for COPY when possible. Using the most explicit path allows COPY to efficiently list and load your data as quickly as possible. Even though Snowflake can scalably list and load large volumes of data; you can avoid wasted compute and API calls by using path partitioning, especially when you already loaded the previous days, months, and years data which will just be ignored for deduplication.
- Use cloud provider event filtering to reduce the amount of notification noise, ingestion latency, and costs from unwanted notifications with filtering on prefix or suffix events before it is sent to Snowpipe. Leverage the native cloud event filtering before using Snowpipe’s more powerful regex pattern filtering.
Thousands of customers and developers are using these best practices to bring in massive amounts of data onto the Snowflake Data Cloud to derive insights and value from that data. No matter which ingestion option you prefer, Snowflake will always be continuously improving its performance and capabilities to support your business requirements for data pipelines. While we focused mainly on file based data ingestion with COPY and Snowpipe here, part 2 of our blog post will go over streaming data ingestion.


