Novità delle Dynamic Tables: più velocità e flessibilità


Migliaia di clienti scelgono le Dynamic Tables per un approccio moderno e veloce alla trasformazione dei dati. Grazie a una latenza end‑to‑end delle pipeline di pochi minuti e a un efficiente motore di elaborazione incrementale, le Dynamic Tables offrono un approccio moderno e scalabile alle pipeline autonome. Nell’ultimo anno Snowflake ha rilasciato una serie di aggiornamenti che rendono le Dynamic Tables più veloci, più espressive e più interoperabili con gli strumenti che già utilizzi.
Al Summit, Sergey Labetsik, senior data engineer presso Wind Creek Hospitality, ha mostrato come il suo team sia riuscito a erogare buoni pasto agli ospiti entro un minuto dal momento in cui ne maturavano il diritto. Migrando un processo batch dbt a una pipeline di Dynamic Tables, hanno ridotto la latenza end‑to‑end a meno di un minuto, un netto miglioramento rispetto alla pianificazione di 30 minuti con cui il processo veniva eseguito.
Ecco le novità delle Dynamic Tables e perché sono importanti per le tue pipeline.
Benchmark che indicano un refresh fino a 2,8 volte più veloce

La velocità è la base su cui si costruisce tutto il resto. Abbiamo eseguito benchmark sui pattern di Dynamic Table più diffusi da maggio 2025 a maggio 2026 e abbiamo rilevato prestazioni di refresh fino a 2,8 volte più veloci. Questo risultato è frutto degli aggiornamenti che abbiamo introdotto a livello tecnico per accelerare le prestazioni delle Dynamic Tables, tra cui funzioni di aggregazione di primo livello, QUALIFY row/rank = 1 (SCD-1), operazioni cluster-by e join, tutto misurato su warehouse Gen2.
Questi miglioramenti derivano da ottimizzazioni delle prestazioni sviluppate appositamente per le Dynamic Tables abbinate ai warehouse Gen2. I refresh incrementali elaborano meno dati, terminano prima e liberano capacità di calcolo per il resto del tuo workload. Se non hai ancora spostato i tuoi workload Dynamic Table sui warehouse Gen2, è il momento di farlo.
Design pattern: come sviluppare al meglio con le Dynamic Tables
Torniamo alle basi e ripassiamo le best practice per sviluppare pipeline efficienti con le Dynamic Tables:
Concatena più Dynamic Tables tra loro: suddividi le pipeline complesse in una catena di due o più Dynamic Tables, ciascuna dedicata a un singolo passaggio logico. Molti team utilizzano il vocabolario medallion: bronze (raw landing), silver (TARGET_LAG = DOWNSTREAM), gold (aggregato con un lag basato sul tempo). Nel mondo delle Dynamic Tables, il layer bronze rappresenta la tabella raw landing, il layer silver è la Dynamic Table in cui pulisci i dati e il layer gold è dove arricchisci i dati, pronti per essere serviti alle tue app downstream.
Distribuisci join e aggregazioni su Dynamic Tables separate: metti prima i join, poi le aggregazioni. Ogni passaggio si aggiorna così in modo incrementale, sommando i vantaggi in termini di efficienza e migliorando la gestibilità.
Adotta una strategia a doppio warehouse: imposta INITIALIZATION_WAREHOUSE per le reinizializzazioni (scansioni complete, a forte consumo di risorse) e un warehouse più piccolo per i refresh incrementali continui.
Non utilizzare mai REFRESH_MODE = AUTO in produzione: utilizza la modalità di refresh automatico in sviluppo per scoprire se la tua pipeline viene eseguita in modo incrementale o richiede un refresh completo. Poi imposta esplicitamente il refresh_mode in produzione.
I nuovi aggiornamenti rendono i refresh ancora più veloci
Deduplicazione SCD-1 con QUALIFY row/rank = 1
Per le pipeline CDC in cui la tabella di base riceve record append-only, QUALIFY ROW_NUMBER() = 1 (è in GA) è il modo più pulito per conservare in modo incrementale solo la riga più recente per ogni business key. La window function seleziona la riga corretta indipendentemente dall’ordine di ingestion, gestendo gli arrivi fuori sequenza senza logica aggiuntiva.
Inoltre, se utilizzi il pattern SELECT * EXCLUDE, ottieni anche l’evoluzione automatica dello schema: le colonne aggiunte o rimosse dalla tabella di base si propagano automaticamente a valle senza dover modificare la definizione della Dynamic Table.
SELECT * EXCLUDE _metadata_cols
FROM raw_events
QUALIFY ROW_NUMBER() OVER (
PARTITION BY id
ORDER BY updated_at DESC
) = 1Primary key: gestire elegantemente gli insert-overwrite
Ecco una situazione comune: hai una pipeline incrementale che funziona alla perfezione. Poi un INSERT OVERWRITE colpisce una tabella di base e azzera i metadati di change tracking. Oppure c’è un’aggregazione complessa che richiede un refresh completo. Ora ogni tabella downstream rielabora tutto da zero. Ora puoi risolvere questa situazione con un semplice vincolo PRIMARY KEY RELY (è in GA) sulla tabella di base.
ALTER TABLE dim_customers
ADD PRIMARY KEY (customer_id) RELY;In questo modo dici a Snowflake: “fidati di questa chiave per il rilevamento delle modifiche. Non basarti sulle colonne di change tracking”.
| Vantaggio | Dettagli |
|---|---|
| Propagazione a tutta la pipeline | dichiarala una sola volta sulla tabella di base; il vantaggio si estende a tutte le Dynamic Tables downstream. Nota: Primary Key RELY non si applica retroattivamente. dopo averla aggiunta, esegui CREATE OR REPLACE sulle Dynamic Tables downstream per attivare il vantaggio. |
| Chiavi derivate | Snowflake legge automaticamente le colonne SELECT, GROUP BY e le partizioni QUALIFY ROW_NUMBER(), che diventano la chiave univoca. |
| Sorgenti Apache Iceberg™ v2 | migliorano notevolmente le prestazioni di update/delete per le tabelle nel cloud storage. |
| Interrompe la dipendenza a cascata | le Dynamic Tables downstream restano INCREMENTAL anche quando leggono da un parent con refresh FULL. |
Modalità di refresh adattivo
E se non puoi utilizzare le primary key, ma la tua pipeline incrementale incontra occasionalmente condizioni in cui un ricalcolo completo risulterebbe in realtà più conveniente? È proprio il problema che risolve la modalità di refresh adattivo (in public preview).
Pensala come incrementale, ma più intelligente. Snowflake integra euristiche che a ogni refresh valutano se elaborare in modo incrementale o reinizializzare, in base a ciò che offre il miglior rapporto prezzo-prestazioni in quel momento.
CREATE DYNAMIC TABLE my_table
REFRESH_MODE = ADAPTIVE
TARGET_LAG = '10 minutes'
WAREHOUSE = my_warehouse
AS
SELECT ... FROM source_table;Guardrail integrati per la modalità di aggiornamento adattivo: le funzioni ad alto consumo di risorse (Cortex AI Functions e funzioni definite dall’utente) non vengono mai reinizializzate in modo imprevisto. Se la definizione di una Dynamic Table non supporta l’aggiornamento incrementale, la creazione viene bloccata in modo proattivo. Questo contribuisce a ridurre i comportamenti inattesi in fase di esecuzione.
Masking e policy di accesso righe nelle Dynamic Tables incrementali
Se operi nei servizi finanziari, nel settore sanitario o in qualsiasi settore regolamentato, probabilmente utilizzi policy di masking o di accesso righe. In precedenza, alcune funzioni delle policy richiedevano un refresh completo anche quando la query era idonea all’elaborazione incrementale.
Con la general availability (in arrivo a breve), tutte le policy di accesso righe o di masking che concedono l’accesso completo ai dati al ruolo owner della Dynamic Table dovrebbero supportare i refresh incrementali, eliminando così le scansioni complete superflue.
Maggiore espressività: crea modelli più sofisticati con le Dynamic Tables
Frozen region: smetti di pagare per dati che non cambiano
Immagina cinque anni di dati storici sugli ordini nella tua pipeline. A ogni refresh, Snowflake li rielabora tutti, comprese le righe del 2020 che non cambieranno mai. Le frozen region (è in GA) ti permettono di dichiarare quali righe possono essere congelate con un semplice predicato. Snowflake salta le righe congelate a ogni refresh. Viene ricalcolata solo la finestra mutabile contenente i nuovi dati.
CREATE DYNAMIC TABLE orders_enriched
FROZEN WHERE order_date < CURRENT_DATE() - 1
TARGET_LAG = '1 hour'
WAREHOUSE = my_warehouse
AS
SELECT o.*, c.region
FROM orders o
JOIN customers c ON o.customer_id = c.id;| Vantaggio | Cosa significa |
|---|---|
| Paghi solo per le modifiche | le righe congelate vengono saltate a ogni refresh. |
| I delete vengono ignorati | l’eliminazione delle righe sorgente non si propaga all’output congelato. |
| Stabilità delle dimensioni | i risultati dei join congelati non vengono ricalcolati anche se le dimensioni cambiano. |
| Risparmi sui refresh completi | le Dynamic Tables con refresh completo e frozen region si comportano come refresh incrementali per i dati storici. |
| Evoluzione delle query | vengono ricalcolate solo le nuove righe quando fai evolvere la query. |
Backfill: esegui la migrazione senza rielaborazioni
Stai creando una nuova pipeline, ma hai già anni di dati storici puliti? BACKFILL FROM clona in modalità zero-copy i dati esistenti direttamente nella frozen region senza alcun ricalcolo (è in GA).
CREATE DYNAMIC TABLE new_pipeline_table
FROZEN WHERE event_date < CURRENT_DATE()
BACKFILL FROM existing_historical_table
TARGET_LAG = '1 hour'
WAREHOUSE = my_warehouse
AS
SELECT * FROM raw_events;Migra le pipeline esistenti alle Dynamic Tables in pochi minuti, non ore, senza rielaborare anni di dati. Quindi, se hai dati storici, ti consigliamo vivamente di utilizzare le frozen region fin dall’inizio. I clienti ci segnalano inoltre che occasionalmente vogliono allinearsi a eventuali modifiche dei dati storici o hanno un caso d’uso GDPR di eliminazione di righe specifiche. Ora puoi utilizzare comandi DML in queste regioni congelate per mantenere aggiornata la tua Dynamic Table senza sostenere il costo della ricomputazione.
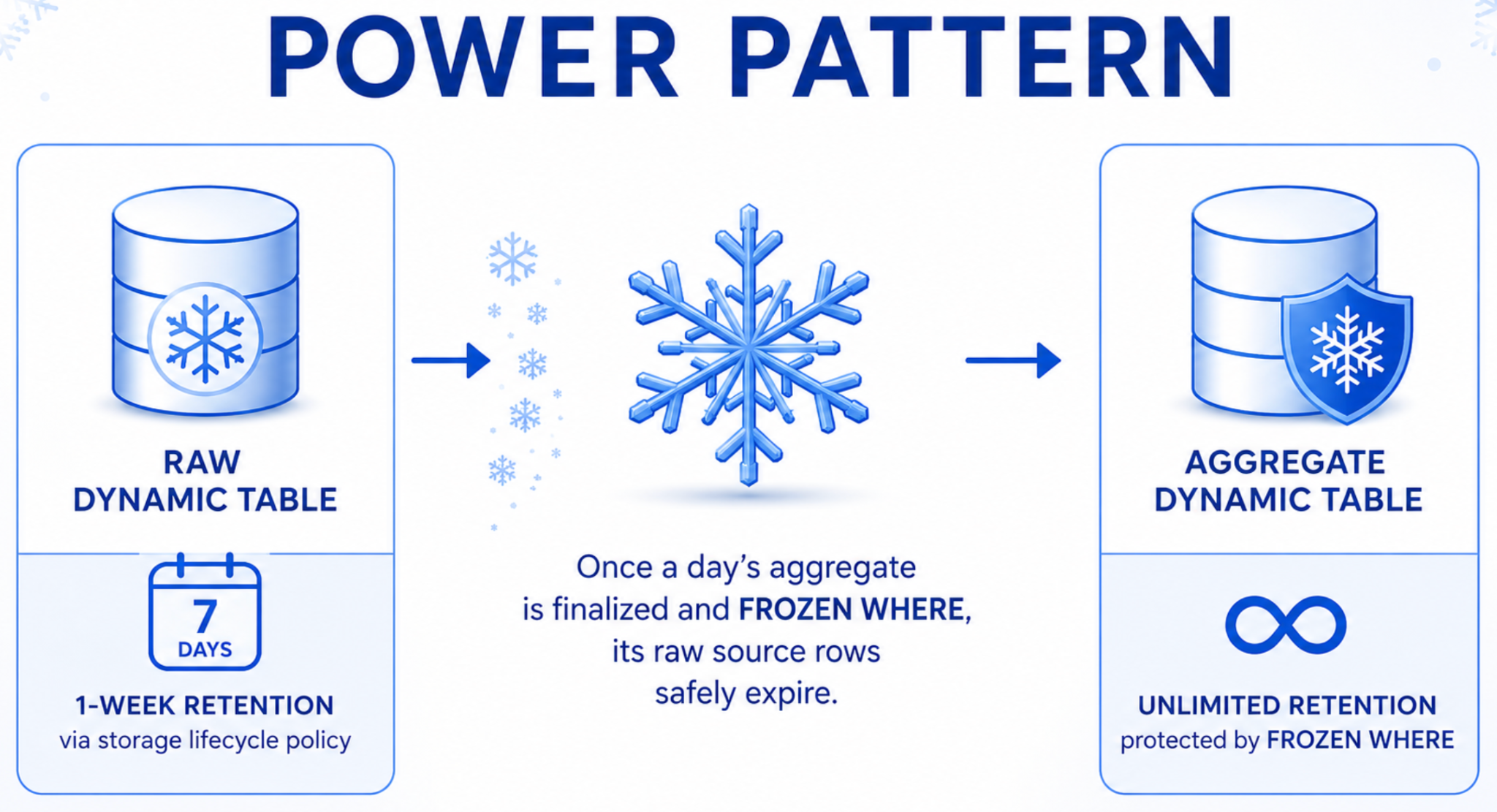
Storage lifecycle policy: fai scadere i dati grezzi, conserva gli aggregati
I dati grezzi degli eventi hanno una durata limitata. Non hai bisogno di tre anni di log grezzi in una tabella hot della pipeline. Ma eliminarli senza compromettere gli aggregati a valle può trasformarsi in un progetto di ingegneria a sé stante.
Le Storage Lifecycle Policy (in GA) ti permettono di applicare una regola di retention con una sola clausola. Le righe scadono automaticamente secondo la propria pianificazione, indipendentemente dal refresh. Nessun job personalizzato. Nessuna istruzione DELETE. Nessun rischio di riprocessare accidentalmente dati eliminati.
Refresh boundary: esegui pipeline indipendenti
Di default, le Dynamic Tables di una pipeline condividono lo snapshot isolation, in cui tutti i refresh sono sincronizzati e leggono dallo stesso istante temporale. Ottimo per la coerenza. Ma a volte serve indipendenza.
I refresh boundary (in GA) ti permettono di inserire un soft break nel tuo grafo aciclico diretto (DAG), incluso il pattern Dynamic Table → View → Dynamic Table, consentendo alle subpipeline di operare secondo le proprie pianificazioni di freshness.
| Caso d’uso | Perché è utile |
|---|---|
| Dimensioni a evoluzione lenta | Il catalogo prodotto o le ricerche geografiche non bloccano le pipeline di ordini a evoluzione rapida. |
| Pipeline cross-team | I fallimenti del Team A non si propagano al Team B. |
| Data sharing | Controlli la tua pianificazione di refresh, indipendentemente dal provider di dati su cui potresti non avere controllo. |
Dynamic Tables incrementali personalizzate
E se la tua pipeline necessita di una logica MERGE complessa, di uno stream-static join, di soft delete o di accumulatori progressivi? Le Dynamic Tables standard basate su SELECT non sempre riescono a esprimerlo in modo elegante, ma vuoi comunque pianificazione gestita, retry e monitoraggio.
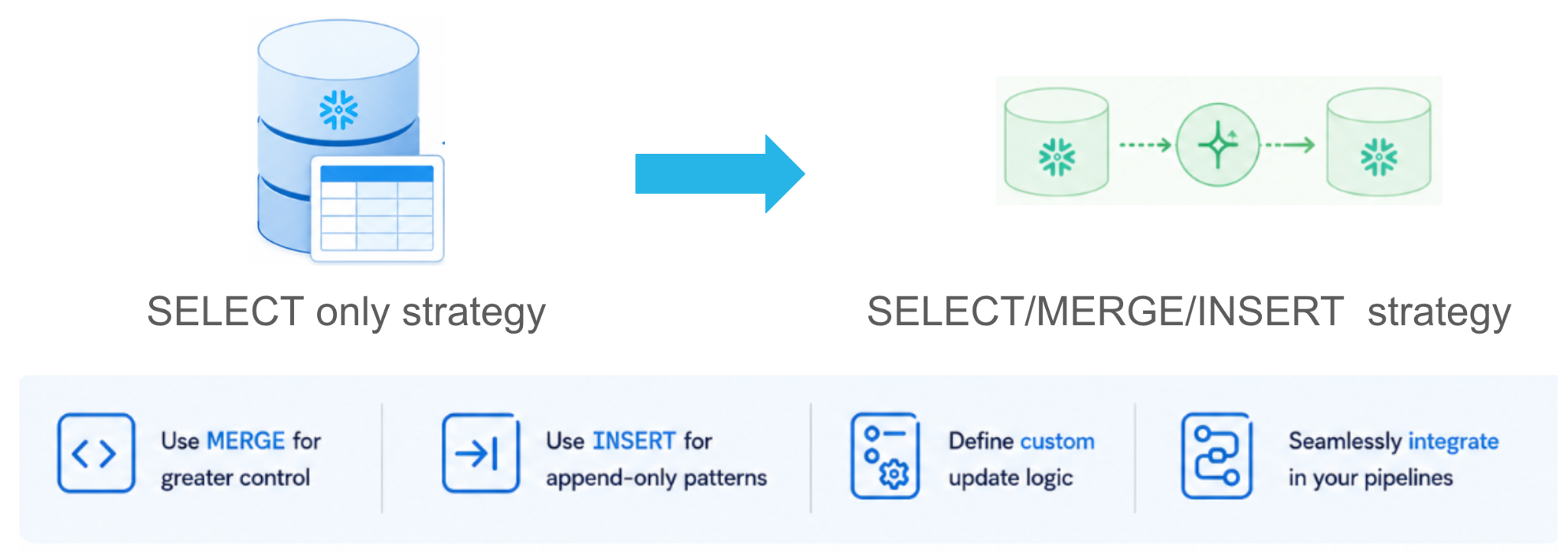
Le Dynamic Tables incrementali personalizzate (presto in GA) ti fanno passare da una strategia basata solo su SELECT a una strategia SELECT / MERGE / INSERT. Ottieni piena potenza espressiva mentre Snowflake continua a controllare l’esecuzione (pianificazione gestita, tracciamento delle dipendenze, observability e replica) senza sacrificare le prestazioni e il controllo dell’elaborazione batch imperativa.
CREATE DYNAMIC TABLE order_enriched
REFRESH_MODE = INCREMENTAL
TARGET_LAG = '5 minutes'
WAREHOUSE = my_warehouse
AS
MERGE INTO order_enriched t
USING (
SELECT s.order_id, s.amount, d.region
FROM orders_stream s
JOIN dim_customers d ON s.customer_id = d.id
) src ON t.order_id = src.order_id
WHEN MATCHED THEN UPDATE SET
t.amount = src.amount, t.region = src.region
WHEN NOT MATCHED THEN INSERT
(order_id, amount, region) VALUES (src.order_id, src.amount, src.region);Le Dynamic Tables con incrementalizzazione personalizzata possono essere combinate con le Dynamic Tables standard basate su SELECT nella stessa pipeline. I casi d’uso comuni includono:
| Pattern | Tipo di CI-DT |
|---|---|
| Arricchimento CDC con dimension lookup e propagazione delle delete | MERGE |
| Gestione di una leaderboard Top-K | MERGE |
| Arricchimento stream-static join append-only | INSERT |
| Migrazione da Task e Stream | MERGE o INSERT |
Interoperabilità
Skill CoCo per le Dynamic Tables
Il debug delle pipeline non dovrebbe richiedere la lettura riga per riga dei log della cronologia dei refresh. La nuova skill Dynamic Tables in Snowflake CoCo ti offre una guida esperta per creare, ottimizzare, monitorare e risolvere i problemi delle Dynamic Tables direttamente nel tuo IDE.
Descrivi il tuo obiettivo, menziona le Dynamic Tables e la skill viene invocata. Ottieni rapidamente aiuto su fallimenti dei refresh, tuning del lag, progettazione delle pipeline e ottimizzazione delle prestazioni.
Compatibilità con Apache Iceberg
Le Dynamic Tables sono pienamente compatibili con Apache Iceberg a entrambe le estremità della tua pipeline.
| Caso d’uso | Cosa puoi fare con le Dynamic Tables |
|---|---|
| Leggere da Apache Iceberg | Utilizza tabelle Iceberg v2 gestite esternamente come sorgenti. Qui i vincoli PRIMARY KEY RELY migliorano significativamente le prestazioni di update/delete. |
| Scrivere su Apache Iceberg | Crea Iceberg Tables dinamiche con un output in formato Iceberg su storage esterno gestito da Snowflake, leggibile direttamente da Apache Spark™, Trino e altri motori. |
Stesse modalità di refresh, stessa pianificazione, stessa semantica delle pipeline con un output in formato open.
Wolt (parte di DoorDash) ha standardizzato Apache Iceberg per avere la flessibilità di eseguire ogni workload sul motore più adatto. Utilizziamo Snowflake Dynamic Iceberg Tables per arricchire, preparare e aggiornare automaticamente i dati nel nostro data lake: definiamo un’unica query con un obiettivo di aggiornamento dei dati e Snowflake gestisce gli aggiornamenti incrementali e l’orchestrazione. Grazie a Dynamic Tables su Apache Iceberg, abbiamo accelerato il lancio delle pipeline, ridotto i tempi di manutenzione e diminuito l’overhead associato alle pipeline incrementali.
Raimund Kämmerer
Dynamic Tables come materializzazione dbt
Alcuni team non hanno bisogno di un refresh continuo. Hanno bisogno di dati pronti alle 5:00, oppure orchestrano le pipeline da dbt o Airflow. TARGET_LAG non funziona bene in questi casi.
Nuove funzionalità dello scheduler:
- Disabilitare lo scheduler per le pipeline orchestrate esternamente
- Supporto per refresh sincrono con i progetti Snowflake Database Change Management (DCM)
dbt + Dynamic Tables: l’unione fa la forza
dbt gestisce il tuo workflow di engineering. Le Dynamic Tables gestiscono la freshness dei tuoi dati. Insieme, eliminano il compromesso tra disciplina della pipeline e prestazioni della pipeline.
L’integrazione è un drop-in replacement: La maggior parte dei modelli dbt è già costituita da istruzioni CTAS. Convertili in Dynamic Tables senza riscrivere alcuna logica. Mantieni l’intero grafo di lineage dbt, le suite di test e la documentazione, ottenendo al contempo un comportamento automatico di skip-on-unchanged-source:
- Nessuna riscrittura di logica per convertire direttamente i modelli esistenti
- Snowflake identifica le sorgenti invariate e salta automaticamente il refresh
- Lineage, testing e documentazione dbt completamente preservati
Puoi approfondire questa potente combinazione in questo blog.
Cosa significa per le tue pipeline
Questi aggiornamenti convergono in un messaggio chiaro: le Dynamic Tables ti offrono più controllo senza maggiore complessità. Ora puoi:
- utilizzare
MERGEeINSERTper trasformazioni che richiedono logiche complesse - gestire le Dynamic Tables in dbt e Git
- archiviare i risultati in formato Iceberg per l’interoperabilità con il data lake
- arricchire i dati con le Cortex AI Functions inline
- filtrare in base al tempo corrente per finestre mobili
- lasciare evolvere automaticamente gli schemi
- ottenere assistenza basata sull’AI per costruire e fare il debug delle pipeline
- eseguire refresh più veloci sui warehouse Gen2
Inizia subito
Prova oggi stesso le nuove funzionalità:
- Documentazione delle Dynamic Tables
- Guida all’incrementalizzazione personalizzata
- Adaptive Refresh Mode
- Iceberg Tables dinamiche
- Adapter dbt-snowflake
- Cortex Code
Se utilizzi già le Dynamic Tables, aggiorna il tuo warehouse a Gen2 e misura la differenza. Se finora hai rimandato a causa della complessità di orchestrazione o di lacune di espressività, quegli ostacoli non esistono più.
Affermazioni riferite al futuro
Questa pagina contiene affermazioni riferite al futuro, incluse dichiarazioni relative a future offerte di prodotto, che non costituiscono un impegno alla fornitura di tali offerte. Le offerte e i risultati effettivi potrebbero essere diversi ed essere soggetti a incertezze e rischi noti e non noti. Consulta il nostro più recente modulo 10‑Q per ulteriori informazioni.

Latenza in millisecondi su larga scala: perché il nostro ML Feature Store gira su Snowflake Postgres

I partner del Marketplace Snowflake generano 100 milioni di dollari nella prima metà del 2026: ed è solo l’inizio

Come il Marketing AI Council Snowflake ha trasformato un’organizzazione globale in un team AI-native
