Novidades das Dynamic Tables: Mais rápidas e flexíveis


Milhares de clientes recorrem às Dynamic Tables em busca de uma abordagem moderna e rápida para transformar dados. Com latência de pipeline completo em minutos e um mecanismo de processamento incremental eficiente, as Dynamic Tables oferecem uma abordagem moderna e dimensionável para pipelines autônomos. No último ano, a Snowflake lançou uma série de atualizações que tornaram as Dynamic Tables mais rápidas, mais expressivas e mais interoperáveis com as ferramentas que você já usa.
No Summit, Sergey Labetsik, engenheiro de dados sênior da Wind Creek Hospitality, demonstrou como sua equipe conseguiu entregar vouchers de alimentação aos hóspedes em menos de um minuto após a elegibilidade. Ao migrar um job em lote do dbt para um pipeline de Dynamic Tables, eles reduziram a latência completa para menos de um minuto, uma grande melhoria em relação à programação de 30 minutos em que o job vinha rodando.
Veja a seguir as novidades das Dynamic Tables e por que elas são importantes para os seus pipelines.
Benchmarks com atualizações até 2,8 vezes mais rápidas

A velocidade é a base sobre a qual tudo o mais se constrói. Avaliamos os padrões mais populares de Dynamic Tables de maio de 2025 a maio de 2026 e medimos uma performance de atualização até 2,8 vezes mais rápida. Isso reflete atualizações que fizemos nos bastidores para acelerar a performance das Dynamic Tables, incluindo funções de agregação de nível superior, QUALIFY row/rank = 1 (SCD-1), operações cluster-by e joins, tudo medido em warehouses Gen2.
Esses ganhos vêm de otimizações de performance criadas especificamente para as Dynamic Tables combinadas com warehouses Gen2. As atualizações incrementais processam menos dados, terminam mais cedo e liberam capacidade de processamento para o restante da sua carga de trabalho. Se você ainda não migrou suas cargas de trabalho de Dynamic Tables para warehouses Gen2, agora é a hora.
Padrões de design: Como construir bem com Dynamic Tables
Vamos voltar ao básico e revisar as melhores práticas para criar pipelines eficientes com Dynamic Tables:
Use várias Dynamic Tables encadeadas: Divida pipelines complexos em uma cadeia de duas ou mais Dynamic Tables, cada uma cuidando de uma etapa lógica. Muitas equipes usam o vocabulário medallion: bronze (raw landing), prata (TARGET_LAG = DOWNSTREAM) e ouro (agregado com lag baseado em tempo). No mundo das Dynamic Tables, a camada bronze representa a tabela de raw landing, a camada prata é a Dynamic Table onde você limpa os dados e a camada ouro é onde você enriquece os dados, prontos para serem servidos às suas Applications downstream.
Decomponha joins e agregações em Dynamic Tables separadas: Coloque os joins primeiro e as agregações em seguida. Cada etapa então atualiza incrementalmente, somando os ganhos de eficiência e melhorando o gerenciamento.
Use uma estratégia de warehouse duplo: Defina INITIALIZATION_WAREHOUSE para reinicializações (full scans, que exigem muitos recursos) e um warehouse menor para as atualizações incrementais contínuas.
Nunca use REFRESH_MODE = AUTO em produção: use o modo de atualização automática em desenvolvimento para descobrir se o seu pipeline roda incrementalmente ou requer uma atualização completa. Depois, defina o refresh_mode explicitamente em produção.
Novas atualizações tornam as atualizações ainda mais rápidas
Deduplicação SCD-1 com QUALIFY row/rank = 1
Para pipelines de CDC em que sua tabela base recebe registros append-only, QUALIFY ROW_NUMBER() = 1 (GA) é a forma mais limpa de manter incrementalmente apenas a linha mais recente por chave de negócios. A função de janela escolhe a linha correta independentemente da ordem de ingestão, lidando com chegadas fora de ordem sem lógica adicional.
Além disso, se você usar o padrão SELECT * EXCLUDE, também ganha evolução de schema automática: colunas adicionadas ou removidas da tabela base se propagam automaticamente para o downstream sem alterar a definição da Dynamic Table.
SELECT * EXCLUDE _metadata_cols
FROM raw_events
QUALIFY ROW_NUMBER() OVER (
PARTITION BY id
ORDER BY updated_at DESC
) = 1Chaves primárias: resolva insert-overwrites com elegância
Veja uma história comum: você tem um pipeline incremental rodando com elegância. Então um INSERT OVERWRITE atinge uma tabela base e redefine os metadados de change-tracking. Ou há uma agregação complexa que exige uma atualização completa. Agora, toda tabela downstream está reprocessando tudo do zero. Você pode resolver isso com uma simples restrição PRIMARY KEY RELY (GA) na tabela base.
ALTER TABLE dim_customers
ADD PRIMARY KEY (customer_id) RELY;Isso diz à Snowflake: "Confie nesta chave para detecção de mudanças. Não dependa das colunas de change-tracking."
| Benefício | Detalhes |
|---|---|
| Propagação por todo o pipeline | Declare uma vez na tabela base; o benefício flui para todas as Dynamic Tables downstream. Observação: a Primary Key RELY não se aplica retroativamente. Depois de adicioná-la, execute CREATE OR REPLACE nas Dynamic Tables downstream para ativar o benefício. |
| Chaves derivadas | A Snowflake lê automaticamente suas colunas SELECT, GROUP BY e partições QUALIFY ROW_NUMBER() que se tornam a chave única. |
| Fontes Apache Iceberg™ v2 | Melhora significativamente a performance de update/delete para tabelas no armazenamento na nuvem. |
| Quebra a dependência em cascata | As Dynamic Tables downstream permanecem INCREMENTAL mesmo ao ler de um pai com atualização FULL. |
Modo de atualização adaptativo
E se você não puder usar chaves primárias, mas seu pipeline incremental ocasionalmente atinge condições em que uma recomputação completa seria, na verdade, mais barata? Esse é o problema que o modo de atualização adaptativo (versão preliminar pública) resolve.
Pense nele como incremental, mas mais inteligente. A Snowflake tem heurísticas integradas que avaliam, a cada atualização, se devem processar incrementalmente ou reinicializar, com base no que oferecerá a melhor relação custo-performance naquele momento.
CREATE DYNAMIC TABLE my_table
REFRESH_MODE = ADAPTIVE
TARGET_LAG = '10 minutes'
WAREHOUSE = my_warehouse
AS
SELECT ... FROM source_table;Guardrails built in for adaptive refresh mode: Expensive functions (Cortex AI Functions, user-defined functions) are never reinitialized unexpectedly. If a Dynamic Table definition can't support incremental refresh, creation fails proactively. This helps reduce unexpected runtime behavior.
Mascaramento e Row Access Policies em Dynamic Tables incrementais
Se você atua em serviços financeiros, saúde ou qualquer setor regulado, provavelmente usa políticas de mascaramento ou de acesso a linhas. Anteriormente, certas funções de política exigiam uma atualização completa mesmo quando a própria consulta era elegível para processamento incremental.
Quando ficar disponível ao público (em breve), espera-se que quaisquer Row Access Policies ou políticas de mascaramento que concedam acesso total aos dados à função de proprietário da Dynamic Table passem a oferecer suporte a atualizações incrementais, eliminando full scans desnecessários.
Expressividade aprimorada: crie modelos mais sofisticados com Dynamic Tables
Frozen regions: pare de pagar por dados que não mudam
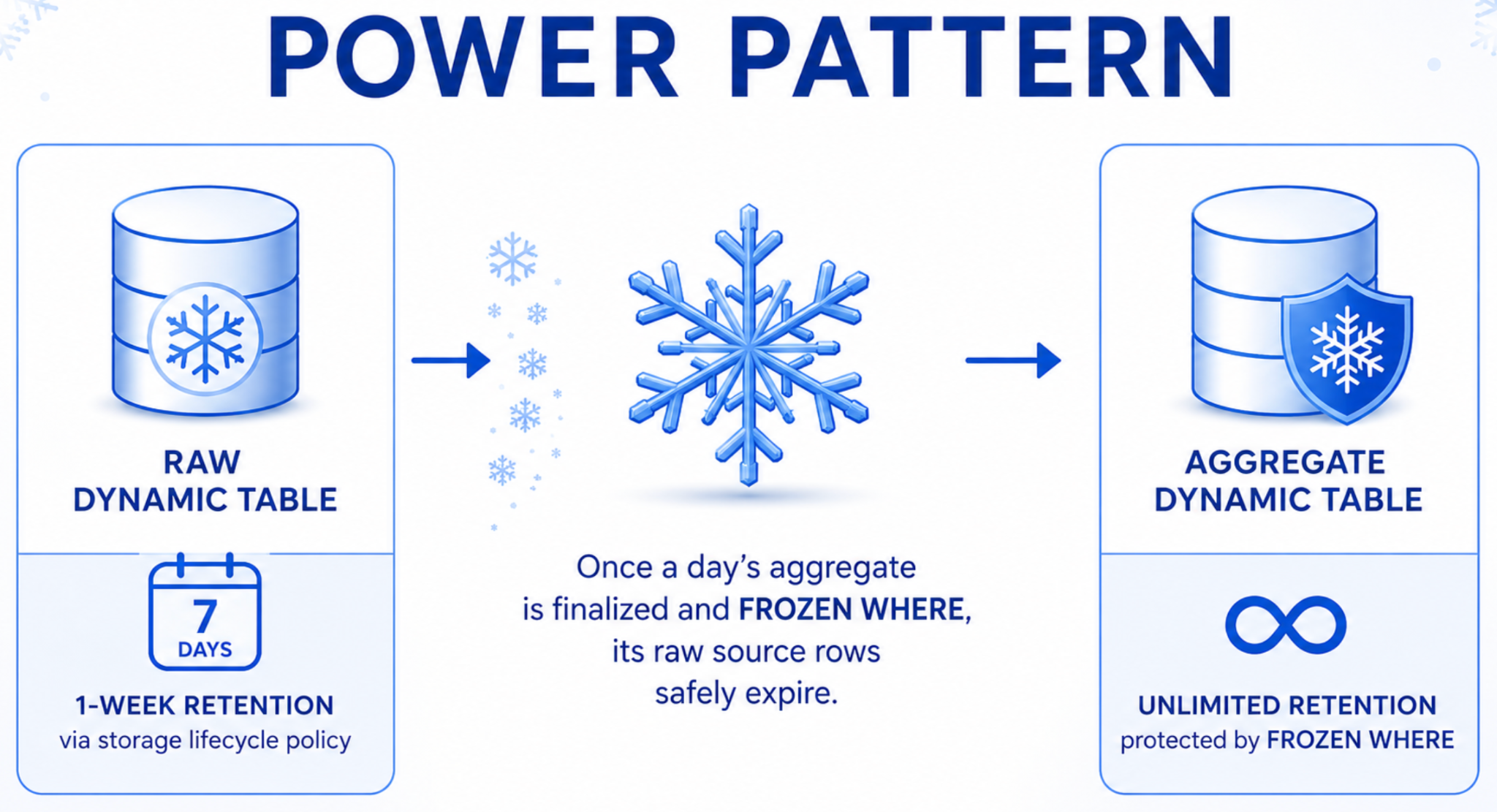
Imagine cinco anos de dados históricos de pedidos no seu pipeline. A cada atualização, a Snowflake reprocessa tudo, incluindo as linhas de 2020 que nunca vão mudar. As frozen regions (GA) permitem declarar quais linhas podem ser congeladas com um predicado simples. A Snowflake ignora as linhas congeladas em cada atualização. Apenas a janela mutável com dados novos é recomputada.
CREATE DYNAMIC TABLE orders_enriched
FROZEN WHERE order_date < CURRENT_DATE() - 1
TARGET_LAG = '1 hour'
WAREHOUSE = my_warehouse
AS
SELECT o.*, c.region
FROM orders o
JOIN customers c ON o.customer_id = c.id;| Benefício | O que significa |
|---|---|
| Pague apenas pela mudança | As linhas congeladas são ignoradas em cada atualização. |
| Os deletes são ignorados | A exclusão de linhas de origem não se propaga para a saída congelada. |
| Estabilidade de dimensão | Os resultados de join congelados não são recomputados, mesmo que as dimensões mudem. |
| Economia em atualizações completas | As Dynamic Tables com atualização completa e frozen regions se comportam como atualizações incrementais para dados históricos. |
| Evolução de consultas | Apenas as linhas novas são recomputadas quando você evolui a consulta. |
Backfill: migre sem reprocessamento
Está criando um novo pipeline, mas já tem anos de dados históricos limpos? O BACKFILL FROM faz a clonagem com cópia zero dos dados existentes diretamente na frozen region, sem recomputação (GA).
CREATE DYNAMIC TABLE new_pipeline_table
FROZEN WHERE event_date < CURRENT_DATE()
BACKFILL FROM existing_historical_table
TARGET_LAG = '1 hour'
WAREHOUSE = my_warehouse
AS
SELECT * FROM raw_events;Migre pipelines existentes para Dynamic Tables em minutos, não em horas, sem reprocessar anos de dados. Por isso, se você tem dados históricos, recomendamos fortemente que use frozen regions desde o início. Também ouvimos de clientes que ocasionalmente querem atualizar alguma mudança nos dados históricos ou têm um caso de uso de RGPD de excluir linhas específicas. Agora, você pode usar comandos DML nessas regiões congeladas para manter sua Dynamic Table atualizada sem pagar o custo da recomputação.
Políticas de ciclo de vida do armazenamento: expire dados brutos e mantenha agregações
Os dados de eventos brutos têm prazo de validade. Você não precisa de três anos de logs brutos ocupando espaço em uma tabela de pipeline em uso ativo. Mas a limpeza desses dados sem comprometer as agregações downstream pode se transformar em um projeto de engenharia à parte.
As Storage Lifecycle Policies (GA) permitem que você anexe uma regra de retenção com uma única cláusula. As linhas expiram automaticamente em seu próprio cronograma, de forma independente do refresh. Sem jobs personalizados. Sem instruções DELETE. Sem risco de reprocessar acidentalmente dados já removidos.
Limites de refresh: execute pipelines independentes
Por default, as Dynamic Tables em um pipeline compartilham o isolamento de snapshot, no qual todos os refreshes são sincronizados e leem a partir do mesmo ponto no tempo. Isso é ótimo para a consistência. Mas, às vezes, você precisa de independência.
Os limites de refresh (GA) permitem que você insira uma quebra suave no seu grafo acíclico dirigido (DAG), incluindo o padrão Dynamic Table → View → Dynamic Table, o que permite que subpipelines operem em seus próprios cronogramas de atualização.
| Caso de uso | Por que ajuda |
|---|---|
| Dimensões de lenta variação | Catálogos de produtos ou consultas geográficas não bloqueiam pipelines de pedidos de rápida variação. |
| Pipelines entre equipes | As falhas da equipe A não se propagam para a equipe B. |
| Data sharing | Você controla seu próprio cronograma de refresh, de forma independente do provedor de dados sobre o qual talvez não tenha controle. |
Dynamic Tables incrementais personalizadas
E se o seu pipeline precisar de uma lógica MERGE complexa, um join entre transmissão e dados estáticos, soft deletes ou acumuladores em execução? As Dynamic Tables padrão baseadas em SELECT nem sempre conseguem expressar isso de forma elegante, mas você ainda quer agendamento gerenciado, novas tentativas e monitoramento.
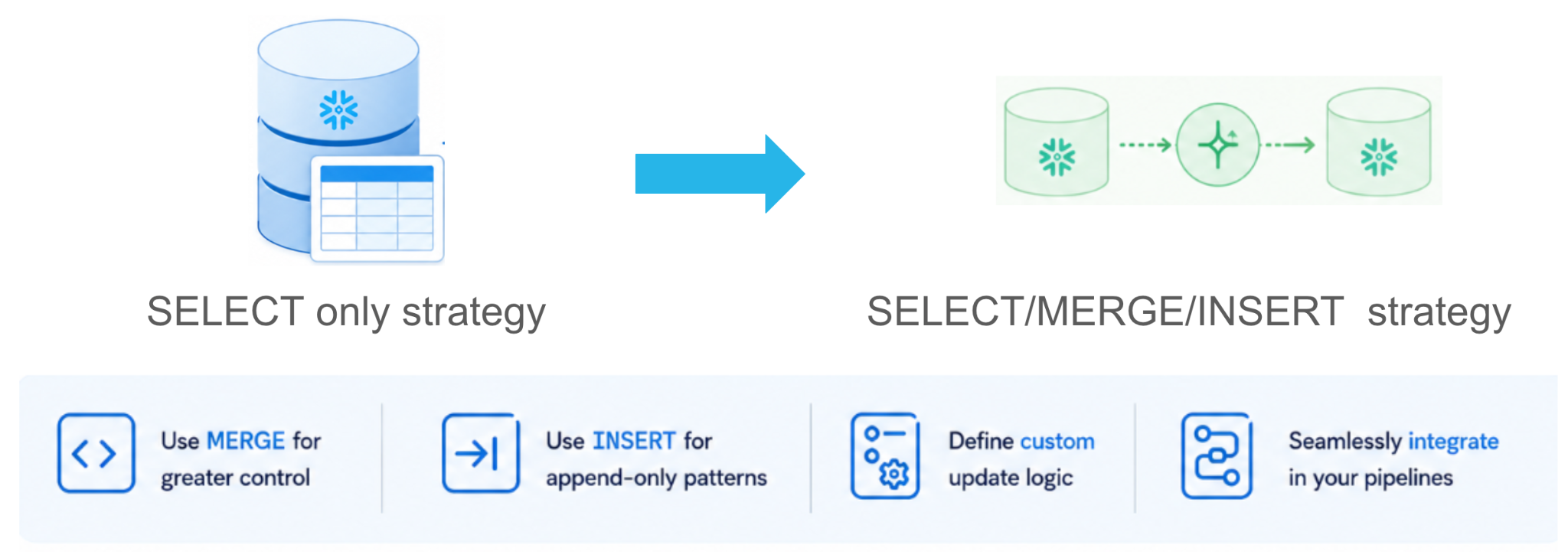
As Dynamic Tables incrementais personalizadas (em breve disponíveis ao público) levam você de uma estratégia exclusivamente SELECT para uma estratégia SELECT / MERGE / INSERT. Você obtém todo o poder expressivo enquanto o Snowflake continua controlando a execução (agendamento gerenciado, rastreamento de dependências, observabilidade e replicação), sem sacrificar a performance e o controle do processamento em lote imperativo.
CREATE DYNAMIC TABLE order_enriched
REFRESH_MODE = INCREMENTAL
TARGET_LAG = '5 minutes'
WAREHOUSE = my_warehouse
AS
MERGE INTO order_enriched t
USING (
SELECT s.order_id, s.amount, d.region
FROM orders_stream s
JOIN dim_customers d ON s.customer_id = d.id
) src ON t.order_id = src.order_id
WHEN MATCHED THEN UPDATE SET
t.amount = src.amount, t.region = src.region
WHEN NOT MATCHED THEN INSERT
(order_id, amount, region) VALUES (src.order_id, src.amount, src.region);As Dynamic Tables com incrementalização personalizada podem ser combinadas com Dynamic Tables padrão baseadas em SELECT no mesmo pipeline. Os casos de uso comuns envolvem:
| Padrão | Tipo de CI-DT |
|---|---|
| Enriquecimento de CDC com consulta de dimensão e propagação de delete | MERGE |
| Manter um leaderboard Top-K | MERGE |
| Enriquecimento de join entre transmissão e dados estáticos apenas com anexação | INSERT |
| Migrar de Tasks e Streams | MERGE ou INSERT |
Interoperabilidade
Skill CoCo para Dynamic Tables
Depurar pipelines não deveria exigir a leitura linha por linha dos logs de histórico de refresh. A nova skill de Dynamic Tables no Snowflake CoCo oferece orientação especializada para criar, otimizar, monitorar e solucionar problemas de Dynamic Tables diretamente no seu IDE.
Descreva seu objetivo, mencione as Dynamic Tables e a skill é acionada. Obtenha ajuda rápida com falhas de refresh, ajuste de lag, design de pipeline e otimização de performance.
Compatibilidade com Apache Iceberg
As Dynamic Tables são totalmente compatíveis com Apache Iceberg em ambas as extremidades do seu pipeline.
| Caso de uso | O que você pode fazer com as Dynamic Tables |
|---|---|
| Ler do Apache Iceberg | Use tabelas Iceberg v2 gerenciadas externamente como fontes. As restrições PRIMARY KEY RELY melhoram significativamente a performance de update/delete aqui. |
| Gravar no Apache Iceberg | Crie Dynamic Iceberg Tables com saída em formato Iceberg em armazenamento externo gerenciado pelo Snowflake, legível diretamente pelo Apache Spark™, Trino e outros mecanismos. |
Os mesmos modos de refresh, o mesmo agendamento e a mesma semântica de pipeline, com uma saída em formato aberto.
A Wolt (parte da DoorDash) adotou o Apache Iceberg como padrão para nos dar a flexibilidade de rodar cada carga de trabalho na engine certa. Usamos as Snowflake Dynamic Iceberg Tables para enriquecer, preparar e atualizar automaticamente os dados em nosso data lake — definimos uma única query com uma recência alvo (target freshness) e o Snowflake gerencia as atualizações incrementais e a orquestração. Com as Dynamic Tables no Apache Iceberg, lançamos pipelines mais rápido, reduzimos o tempo de manutenção e diminuímos o overhead dos nossos pipelines incrementais.
Raimund Kämmerer
Dynamic Tables como uma materialização do dbt
Algumas equipes não precisam de refresh contínuo. Elas precisam de dados prontos às 5h, ou estão executando pipelines a partir do dbt ou do Airflow. O TARGET_LAG não funciona bem nesses casos.
Novos recursos do scheduler:
- desative o scheduler para pipelines orquestrados externamente
- Suporte a refresh síncrono com projetos do Snowflake Database Change Management (DCM)
dbt + Dynamic Tables: melhores juntos
O dbt cuida do seu fluxo de trabalho de engenharia. As Dynamic Tables cuidam da atualização dos seus dados. Juntos, eles eliminam o trade-off entre disciplina de pipeline e performance de pipeline.
A integração é uma substituição direta: A maioria dos modelos dbt já são instruções CTAS. Converta-os em Dynamic Tables sem nenhuma reescrita de lógica. Você mantém todo o seu grafo de linhagem, conjuntos de testes e documentação do dbt, enquanto ganha o comportamento automático de pular fontes inalteradas:
- sem reescritas de lógica para converter modelos existentes diretamente
- o Snowflake identifica fontes inalteradas e pula o refresh automaticamente
- linhagem, testes e documentação completos do dbt preservados
Você pode ler mais sobre essa combinação poderosa neste blog.
O que isso significa para os seus pipelines
Essas atualizações somam uma mensagem clara: as Dynamic Tables dão a você mais controle sem mais complexidade. Agora você pode:
- usar
MERGEeINSERTpara transformações que exigem lógica complexa - gerenciar Dynamic Tables no dbt e no Git
- armazenar resultados em formato Iceberg para interoperabilidade com Data Lake
- enriquecer dados com Cortex AI Functions de forma inline
- filtrar por horário atual para janelas móveis
- deixar os esquemas evoluírem automaticamente
- obter ajuda assistida por IA para criar e depurar pipelines
- executar refreshes mais rápido em warehouses Gen2
Comece agora
Experimente os novos recursos hoje mesmo:
- Documentação das Dynamic Tables
- Guia de incrementalização personalizada
- Adaptive Refresh Mode
- Dynamic Iceberg Tables
- Adaptador dbt-snowflake
- Cortex Code
Se você já está executando Dynamic Tables, faça a atualização do seu warehouse para a Gen2 e meça a diferença. Se você estava adiando por causa da complexidade de orquestração ou de lacunas de expressividade, esses obstáculos não existem mais.
Declarações prospectivas
Este conteúdo contém declarações prospectivas, inclusive sobre nossas futuras ofertas de produtos, e não representa um compromisso de entrega de quaisquer ofertas de produtos. Os resultados e as ofertas reais podem diferir e estão sujeitos a riscos e incertezas conhecidos e desconhecidos. Consulte nosso 10-Q mais recente para obter mais informações.

Impulsionando a empresa agêntica: transformando o contexto corporativo em ações agênticas governadas

Anunciando o Anthropic Claude Fable 5 no Snowflake Cortex AI

Proteger a empresa agêntica começa com os dados
