

金融サービス全体において、AIはもはや基本的な予測分析を行うだけではなく、膨大なデータセットに基づいて複雑な意思決定を行っています。リスクモデルは自律的に稼働しています。エージェントは規制に関するクエリに応答しています。取引システムは、基盤となるデータが実際に何を意味するのかを問うことなく、モデルが生成したシグナルに基づいて行動しています。
これが問題なのです。AIは、生データと大規模言語モデルだけで機能するわけではありません。AIはセマンティックレイヤー、つまりデータが何を意味するのか、概念がどのように関連しているのか、そしてそのデータに対してどのような質問が妥当であるのかを表現するものに基づいて機能します。このレイヤーが強固であれば、AIは本来のパフォーマンスを発揮します。そうでない場合、AIが分かりやすく失敗することはありません。解決する能力を備えていない質問に対して、自信満々に間違った答えを出すのです。
AIの導入を加速させている金融サービス企業にとって、セマンティックレイヤーはもはやアーキテクチャの補足事項ではありません。それはリスクサーフェスなのです。
標準化の大きな進展と残された課題
Open Semantic Interchange(OSI)は、異なるテクノロジーがセマンティック情報をどのように表現し、交換するかという、長年の課題に対処することを目指しています。データだけでなくセマンティクスも、一貫した方法でプラットフォーム間を移動できる世界に、私たちは初めて近づきつつあります。
これは意義深い進歩です。
しかし、金融サービス業界は、外枠の共通化が中身の共通化と同じではないということを、何度も学んできました。
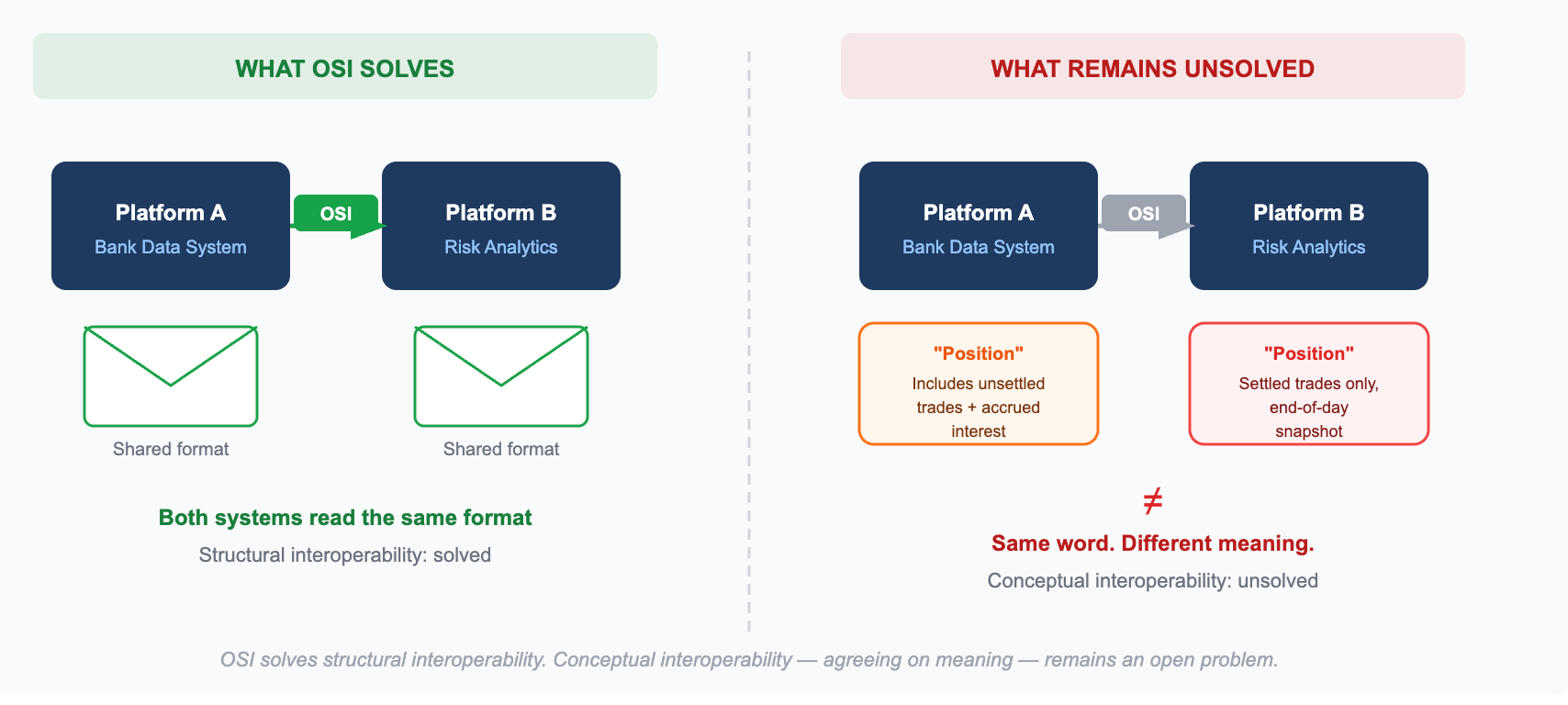
誰も語らない相互運用性の半分
簡単に言えば、システムがセマンティックモデルを交換する方法は標準化されましたが、それらのモデルが何を意味するかは標準化されていないのです。
構造的な相互運用性が問うのは次の点です。「双方が読み取れるフォーマットで、システム間でモデルを交換できるか」これはエンジニアリングの問題です。エンジニアリングによる解決策が存在します。OSIはこれを解決します。
概念的相互運用性が問うのは次の点です。「モデルが実際に何を意味するかについて、双方が合意しているか」これはエンジニアリングの問題ではありません。これは調整の問題です。つまり、最初のコードが書かれる前に、各金融機関、ベンダー、データプロバイダーが共通の定義に合意する必要があるのです。
OSIは意図的に、まず構造的な相互運用性に取り組みました。その順序は正解でした。しかし業界は現在、概念的な相互運用性を伴わない構造的な相互運用性だけでは不十分であることに気づき始めています。
あらゆる金融機関が何度も密かに解決している問題
銀行、資産運用会社、保険会社、データプロバイダーの内部で十分な時間を過ごすと、あるパターンが見えてきます。
どの組織も、取引、ポジション、金融商品、口座、リスクエクスポージャー、投資プラットフォーム、FIBOなど、同じコア概念をモデル化しています。そして、どの組織もそれらを少しずつ異なる方法で定義しています。根本的に違うわけではありませんが、データが境界を越える際に無視できない問題となります。
いくつかの例を考えてみましょう。
ポジションある大手銀行では、ポジションには未決済の取引(合意済みだが未清算の取引)と未収利息が含まれます。別の銀行では、決済済みの取引のみを対象とし、1日の終わりのスナップショットとして取得されます。
FIBO:代替可能かつ譲渡可能であり、何らかの種類の財務的価値を表す金融商品です。
これらの定義は内部的には一貫していますが、表現の違いによって3つの問題が生じます。
私たちは皆、労力を重複させている
AIは特別な処理を行わない限り、これらを同じものとして扱わない
セマンティックレイヤーのマッピングと正規化に時間を費やすことになる

しかし、AIリスク集約モデルが両方のソースからデータを抽出する場合、同じポートフォリオに対して実質的に異なるエクスポージャーの数値が生成されます。しかも、警告やフラグはなく、どの段階でどの定義が適用されたかを追跡する方法もありません。モデルが失敗するわけではありません。単に、間違った答えを気づかれないように生成するだけです。
概念は一貫しています。概念の定義が一貫していません。
そのため、社内であれ企業間であれ、システム間でデータが移動するたびに、チームは違いを調整したり、セマンティクスを再定義したりすることを余儀なくされます。
この作業が目に見えることはめったにありません。アーキテクチャ図やベンダーのデモに表示されることもありません。それは、Eメールのスレッド、照合用のスプレッドシート、そして数字がなぜか合わなかった理由を覚えているほど長く在籍しているアナリストの組織的な記憶の中にのみ存在します。
しかし、それは至る所に存在します。そして、多大なコストがかかります。
このギャップが以前よりも重要になっている理由
これは新しい問題ではありません。金融サービスでは常にセマンティクスが断片化されており、すべての企業、すべてのシステム、すべてのベンダーが同じ中核概念に対して独自の定義を持っています。
新しいのは、それを未解決のまま放置することによるコストです。
1.AIは曖昧さを内包するのではなく、運用化する
人間のアナリストは、定義の不一致に直面すると、作業を一時停止してフラグを立て、解決します。あるいは、不十分なセマンティクスを真の意味に変換することで、静かに調整を行います。この調整作業は時間がかかりますが、影響は限定的です。AIシステムが同じ不一致に直面した場合、作業を一時停止することはありません。誰かが異常に気付く前に、不一致を出力に組み込み、下流に伝播させ、何千もの意思決定にわたって他の不一致と再結合させます。そして、人間のバージョンのように調整できたとしても、脆弱性をもたらし、作業(トークン)を追加することになります。
問題自体は変わっていません。変わったのは、それが複合化するスピードです。
2.あらゆるデータ境界がセマンティックな境界になっている
企業はもはや孤立して事業を展開しているわけではありません。今日の単一の信用リスクワークフローは、市場データベンダー、サードパーティのリスクプラットフォーム、規制報告ユーティリティ、および2つの内部データセットにまたがる可能性があります。そして、それぞれが同じ基礎となる概念に対して独自の定義を持っています。すべての統合は、セマンティックドリフトの新たな機会となります。そして、ドリフトは複合化します。取り込み時の小さな定義のギャップが、AIレイヤーに到達する頃には重大な不一致になります。
取り込み時の小さな定義のギャップが、AIレイヤーに到達する頃には重大な不一致になります。
3.統合のスピードが競争上の変数に
取引をより早く成立させ、データパートナーのオンボーディングをより早く行い、規制の変更により早く適応する企業は、よりクリーンなセマンティック基盤を持つ企業です。セマンティックの不一致は、ここに摩擦をもたらします。これは、すべての新しいデータプロダクト、すべてのAIイニシアチブ、およびすべての企業間コラボレーションに対する隠れた負担のようなものです。
新しいのは、その規模であり、それゆえの緊急性です。
業界はすでにこの問題を認識しているが、実用的な解決策が欠如している
業界は何十年も前からこの問題に気付いていました。それを解決しようとする試みは現実的であり、十分な資金が提供され、善意に基づいています。
金融の専門用語や、その意味、用語間の関係性を定義した共通概念モデル(FIBO)は、その最も顕著な例です。EDM Councilによって開発され、現在はオープンスタンダードとして維持されているFIBOは、金融概念のための包括的で正式に構造化された語彙を提供します。これには、法人からデリバティブ商品まで、あらゆるものを網羅する何千ものクラス、プロパティ、および関係が含まれます。
その志はまさに正しいものです。共有語彙に対する需要は現実のものですが、その提供メカニズムは機能していません。そのため、企業ごと、統合ごと、AIプロジェクトごとに、同じサイクルが繰り返されます。
認識から行動へ
構造的な基盤は存在し、OSIがトランスポートを提供します。前セクションで説明した共有のセマンティックな意味合いこそが、欠けているピースです。そして、その構築においてテクノロジーの問題は一部にすぎません。その大部分は、調整の問題です。
つまり、今後の道のりは、標準化団体が仕様を作成するというよりも、業界のワーキンググループがすぐに使えるもの、すなわちリファレンスボキャブラリを作成するようなものになります。
実際の作業内容:
第一に、問題が何であるかについて、正確かつ全体で合意することです。すべての企業が同じようにセマンティクスの不一致を経験しているわけではありません。そのため、どこでギャップが最もコストを要し、最も頻繁に発生しているかをマッピングすることから作業が始まります。
次に、解決策がどのようなものか、共有レイヤーが何をカバーし、何をカバーしないのか、そして最初のイテレーションにおける「完了」が何を意味するのかについて合意します。
その後、段階的に構築を進めます。数年後に完成する完全なフレームワークを目指すのではなく、各ステップで使えるものを生み出しながら、1つの概念、1つのワーキンググループごとに進めていきます。
参加が求められるステークホルダー:
データプロバイダー:企業の境界を越えて金融データを配信し、クライアントの定義が自社の定義と異なるたびに、セマンティクスの不一致によるコストを負担する企業。
金融機関:データアーキテクチャチームがプロジェクトのたびに同じマッピングを再構築し、まだ特定できていない定義の不一致により、AIプログラムが密かに失敗している機関。
プラットフォームベンダー:企業レベルの定義が作成されるポイントでセマンティックモデリングツールを提供しており、既存のワークフロー内から共有レイヤーを参照可能にするのに最適な立場にあるベンダー。
部分的なすり合わせがもたらす実際の効果:
目標は、すべてにおいてコンセンサスを得ることではありません。十分な範囲でコンセンサスを得ることです。20のコア概念をすり合わせるだけでも、その後のすべての統合における影響範囲を縮小できます。3つのシステム間で「ポジション」をマッピングするのに6か月費やしていたチームが、代わりに2週間で済むようになります。互換性のない定義を密かに集約していたAIモデルは、明確に宣言された相違点に基づいて機能するようになります。3回の照合が必要だった規制当局への報告も、1回目の処理でクリーンに提出できるようになります。
この複利効果は、両方向に働きます。不整合はエラーを増幅させ、整合はスピードを加速させるのです。
セマンティックモデルの構築、データプラットフォームの評価、金融サービス機関(FSI)でのAIデータプログラムの主導など、この取り組みが貴社の役割に関連している場合、まさに今、その議論が行われています。
AIがどのように進化しているかについて、最新のインサイトを入手していただけます。6月1日〜4日にサンフランシスコで開催されるSnowflake Summitにぜひご参加ください。
Open Semantic Interchangeへの参加にご興味をお持ちのお客様は、参加方法についてこちらをご覧ください。

