Intelligenza artificiale nei servizi finanziari: quali ostacoli e come superarli


In tutti i servizi finanziari, l’intelligenza artificiale non si limita più a eseguire analisi predittive di base: prende decisioni complesse sulla base di vasti set di dati. I modelli di rischio operano in autonomia. Gli agenti rispondono a richieste normative. I sistemi di trading agiscono in base a segnali generati da modelli che non si fermano mai a chiedersi che cosa significhino davvero i dati sottostanti.
Questo è il problema. L’intelligenza artificiale non opera solo su dati grezzi e modelli linguistici di grandi dimensioni. Opera su un livello semantico: la rappresentazione del significato dei dati, delle relazioni tra i concetti e delle domande che è legittimo porre a quei dati. Quando questo livello è solido, l’intelligenza artificiale funziona. Quando non lo è, l’intelligenza artificiale non fallisce in modo evidente. Produce con sicurezza risposte errate a domande che non era mai stata progettata per risolvere.
Per le aziende dei servizi finanziari che stanno accelerando l’adozione dell’intelligenza artificiale, il livello semantico non è più una nota a piè di pagina dell’architettura. È una superficie di rischio.
Gli standard hanno fatto molta strada, ma non abbastanza
L’Open Semantic Interchange (OSI) punta ad affrontare questa sfida di lunga data: il modo in cui tecnologie diverse rappresentano e scambiano informazioni semantiche. Per la prima volta, ci stiamo avvicinando a un mondo in cui la semantica, non solo i dati, può spostarsi tra piattaforme in modo coerente.
Si tratta di un progresso significativo.
Ma i servizi finanziari hanno imparato, più volte, che accordarsi sul contenitore non equivale ad accordarsi su ciò che contiene.
L’interoperabilità di cui nessuno parla
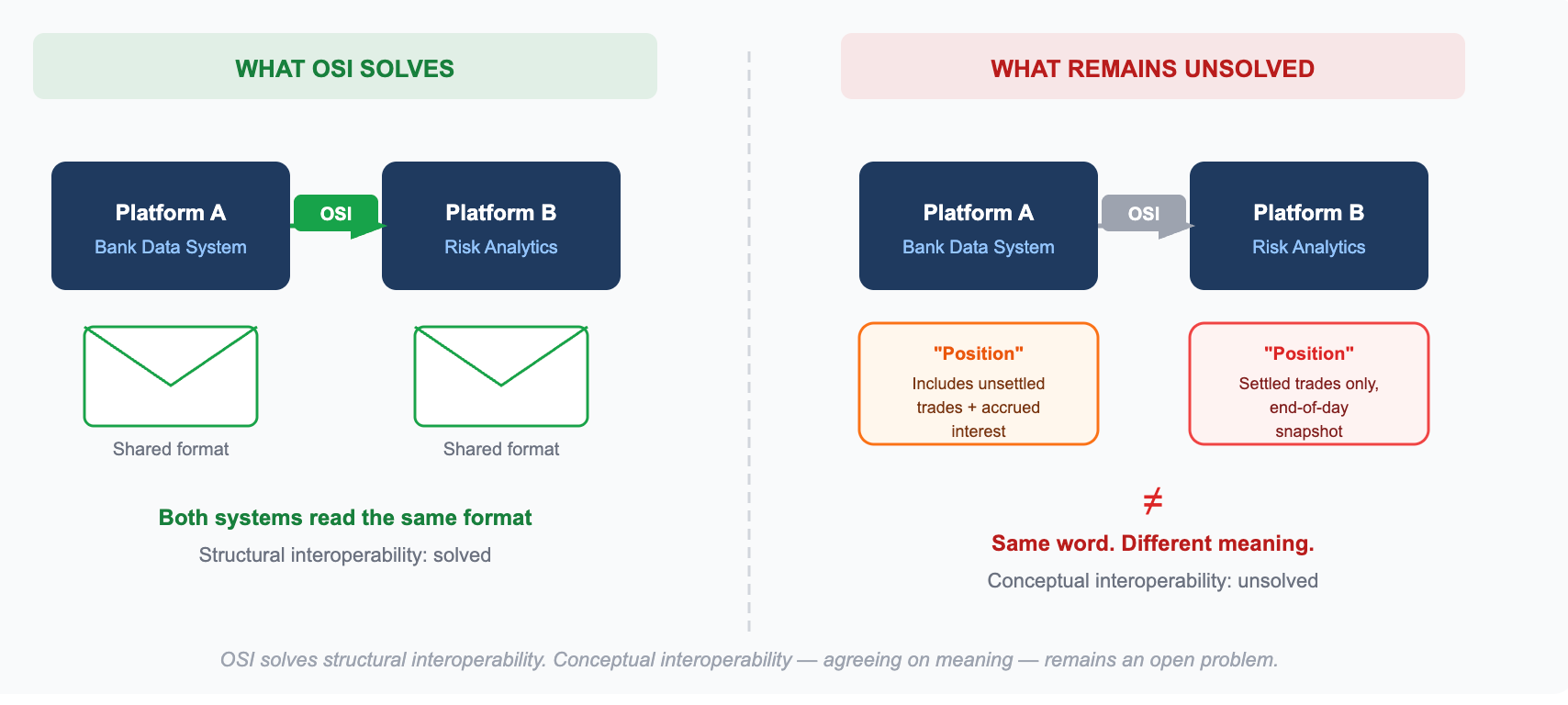
In parole semplici: abbiamo standardizzato il modo in cui i sistemi scambiano modelli semantici, non il significato di quei modelli.
L’interoperabilità strutturale si chiede: “I sistemi possono scambiare modelli in un formato leggibile da entrambe le parti?” Questo è un problema di engineering. Ha una soluzione di engineering. OSI lo risolve.
L’interoperabilità concettuale si chiede: “Entrambe le parti concordano su che cosa significhi davvero il modello?” Questo non è un problema di engineering. È un problema di coordinamento, che richiede ad aziende, vendor e provider di dati di allinearsi su definizioni condivise prima ancora di scrivere la prima riga di codice.
OSI ha affrontato intenzionalmente prima l’interoperabilità strutturale. Era la sequenza giusta. Ma oggi il settore sta scoprendo che l’interoperabilità strutturale, senza interoperabilità concettuale, non basta.
Il problema che ogni istituzione sta risolvendo in silenzio, ancora e ancora
Se trascorri abbastanza tempo all’interno di banche, società di asset management, assicurazioni o provider di dati, emerge uno schema ricorrente.
Ogni organizzazione modella gli stessi concetti fondamentali: trade, posizioni, strumenti, conti, esposizioni al rischio, piattaforma di investimento, FIBO e altro ancora. E ogni organizzazione li definisce in modo leggermente diverso. Non in modo radicale, ma abbastanza da fare la differenza quando i dati attraversano un confine.
Considera alcuni esempi:
“Posizione”. In una grande banca, una posizione include i trade non regolati, cioè transazioni concordate ma non ancora regolate, oltre agli interessi maturati. In un’altra, comprende solo i trade regolati, rilevati come snapshot di fine giornata.
FIBO: Uno strumento finanziario fungibile, negoziabile e rappresentativo di una qualche forma di valore finanziario.
Queste definizioni sono coerenti al loro interno, ma la differenza nella formulazione crea tre problemi:
Tutti abbiamo duplicato gli sforzi
L’intelligenza artificiale non li tratterà allo stesso modo senza un lavoro aggiuntivo
Dovremo dedicare tempo alla mappatura e alla normalizzazione dei nostri livelli semantici

Ma quando un modello di aggregazione del rischio basato sull’intelligenza artificiale attinge a entrambe le fonti, produce valori di esposizione sostanzialmente diversi per lo stesso portafoglio, senza alcun avviso, senza alcun segnale e senza alcun modo per risalire a quale definizione sia stata applicata in ciascuna fase. Il modello non fallisce. Produce semplicemente, in silenzio, la risposta sbagliata.
I concetti sono coerenti. Le definizioni dei concetti sono incoerenti.
Quindi, ogni volta che i dati si spostano tra sistemi, all’interno dell’organizzazione o tra aziende diverse, i team sono costretti a riconciliare le differenze o a ridefinire la semantica.
Questo lavoro è raramente visibile. Non compare nei diagrammi di architettura né nelle demo dei vendor. Vive nei thread email, nei fogli di calcolo per la riconciliazione e nella memoria istituzionale dell’analista che è lì da abbastanza tempo da ricordare perché i numeri non coincidevano mai del tutto.
Ma è ovunque. Ed è costoso.
Perché questo divario oggi conta più di prima
Questo non è un problema nuovo. I servizi finanziari hanno sempre avuto una semantica frammentata: ogni azienda, ogni sistema, ogni vendor con le proprie definizioni degli stessi concetti fondamentali.
La novità è il costo di lasciarlo irrisolto.
1. L’intelligenza artificiale non contiene l’ambiguità: la rende operativa
Quando un analista umano incontra una discrepanza definitoria, si ferma, la segnala e la risolve, oppure la riconcilia in silenzio traducendo una semantica debole nel significato corretto. La riconciliazione è lenta, ma resta circoscritta. Quando un sistema di intelligenza artificiale incontra la stessa discrepanza, non si ferma. Incorpora l’incoerenza nel proprio output, la propaga a valle e la ricombina con altre incoerenze in migliaia di decisioni prima che qualcuno si accorga che qualcosa non va. E anche se fosse in grado di riconciliare, proprio come nella versione umana, introdurrebbe fragilità e aggiungerebbe lavoro (token).
Il problema non è cambiato. È cambiata la velocità con cui si amplifica.
2. Ogni confine dei dati è ormai un confine semantico
Le aziende non operano più in isolamento. Oggi un singolo workflow di rischio di credito può coinvolgere un vendor di market data, una piattaforma di rischio di terze parti, un servizio per il reporting normativo e due dataset interni, ciascuno con la propria definizione degli stessi concetti di base. Ogni integrazione è una nuova occasione di deriva semantica. E la deriva si amplifica: un piccolo divario definitorio in fase di ingestion diventa una discrepanza sostanziale quando raggiunge il livello AI.
Un piccolo disallineamento semantico in fase di ingestion diventa una grande differenza quando arriva al layer AI.
3. La velocità di integrazione è ormai una variabile competitiva
Le aziende che chiudono accordi più rapidamente, inseriscono più rapidamente i partner dati e si adattano più rapidamente ai cambiamenti normativi sono quelle con fondamenta semantiche più solide. Il disallineamento semantico introduce attrito proprio qui. È la tassa nascosta su ogni nuovo data product, ogni iniziativa di intelligenza artificiale e ogni collaboration tra aziende.
La novità sta nella scala e, quindi, nell’urgenza.
Il settore lo sa già, ma non dispone di una soluzione pratica
Il settore è consapevole di questo problema da decenni. I tentativi di risolverlo sono reali, ben finanziati e animati dalle migliori intenzioni.
La Financial Industry Business Ontology (FIBO) è l’esempio più rilevante. Sviluppata da EDM Council e oggi mantenuta come standard open, FIBO offre un vocabolario completo e formalmente strutturato per i concetti finanziari: migliaia di classi, proprietà e relazioni che coprono ogni aspetto, dalle entità giuridiche agli strumenti derivati.
L’ambizione è assolutamente corretta. La domanda di un vocabolario condiviso è reale, ma il meccanismo di adozione non ha funzionato. Così il ciclo si ripete: azienda dopo azienda, integrazione dopo integrazione, progetto di intelligenza artificiale dopo progetto di intelligenza artificiale.
Dalla consapevolezza all’azione
La data foundation esiste già e OSI ne abilita il trasporto. I significati semantici condivisi descritti nelle sezioni precedenti sono il tassello mancante, e costruirlo è solo in parte un problema tecnologico. È soprattutto un problema di coordinamento.
Questo significa che il percorso da seguire assomiglia meno a un ente di standardizzazione che produce una specifica e più a un gruppo di lavoro di settore che realizza qualcosa di immediatamente utilizzabile: un vocabolario di riferimento.
Cosa comporta davvero questo lavoro:
Per prima cosa, definire qual è il problema, in modo preciso e condiviso. Non tutte le aziende vivono il disallineamento semantico allo stesso modo, e il lavoro inizia mappando dove i divari sono più costosi e più frequenti.
Poi, definire che aspetto ha una soluzione, cosa copre il layer condiviso, cosa non copre e cosa significa “completato” per la prima iterazione.
Quindi, procedere in modo incrementale. Un concetto alla volta, un gruppo di lavoro alla volta, con qualcosa di utilizzabile a ogni passaggio invece di un framework completo che arriva anni dopo.
Chi deve essere coinvolto:
Data provider che distribuiscono dati finanziari oltre i confini delle singole aziende e assorbono il costo del disallineamento semantico ogni volta che la definizione di un cliente diverge dalla loro.
Istituzioni finanziarie i cui team di architettura dati ricostruiscono le stesse mappature progetto dopo progetto e i cui programmi di intelligenza artificiale stanno fallendo in silenzio a causa di incoerenze definitorie che ancora non riescono a identificare.
Fornitori di piattaforma i cui strumenti di modellazione semantica si collocano nel punto in cui vengono create le definizioni a livello aziendale e che sono nella posizione migliore per rendere il layer condiviso referenziabile all’interno dei workflow esistenti.
Cosa offre concretamente un allineamento parziale:
L’obiettivo non è raggiungere il consenso su tutto. È raggiungere il consenso su quanto basta. Anche allinearsi su 20 concetti chiave riduce l’ampiezza di ogni integrazione successiva. I team che oggi impiegano sei mesi per mappare “position” su tre sistemi possono farlo in due settimane. Il modello di intelligenza artificiale che prima aggregava in silenzio definizioni incompatibili ora dispone di una divergenza dichiarata con cui operare. La segnalazione regolamentare che richiedeva tre cicli di riconciliazione viene inviata correttamente al primo tentativo.
L’effetto cumulativo funziona in entrambe le direzioni. Il disallineamento si accumula e genera errori. L’allineamento si accumula e genera velocità.
Se questo lavoro è rilevante per il tuo ruolo, che tu stia creando modelli semantici, valutando piattaforme dati o guidando un programma dati per l’intelligenza artificiale in un’azienda FSI, questa conversazione è già in corso.
Scopri gli insight più recenti su come si sta evolvendo l’intelligenza artificiale. Partecipa a Snowflake Summit dal 1 al 4 giugno a San Francisco.
Vuoi entrare a far parte dell’Open Semantic Interchange? Scopri come puoi partecipare.

