
How many new cases? Where are infection rates rising? How are governments responding? And, the most dreaded: How many more have died and who is at risk? These are all questions answered by the daily data collection and reporting on the COVID-19 virus.
But what kind of data, and in what form, is needed to predict what’s next for this global pandemic? Specifically, where will the next surge in cases be? Can those local health systems cope? How is COVID-19 trending in neighboring states and countries? How fast will it spread to surrounding areas, and which population groups will be hit the hardest?
Global businesses will ask: What actions and where do we need to protect our employees? Is our supply chain safe? What part of the chain is most vulnerable today, next week, and next month? If we have to shut down, how long will that be and what measures can we take to avoid a link in that chain breaking?
Starschema, a data services and technology company, has built a public data set on Snowflake’s Cloud Data Platform. It comprises a number of epidemiological, demographic and other data sources to help answer these questions, and many more. Most recently, Starschema added data specific to local counties in the United States.
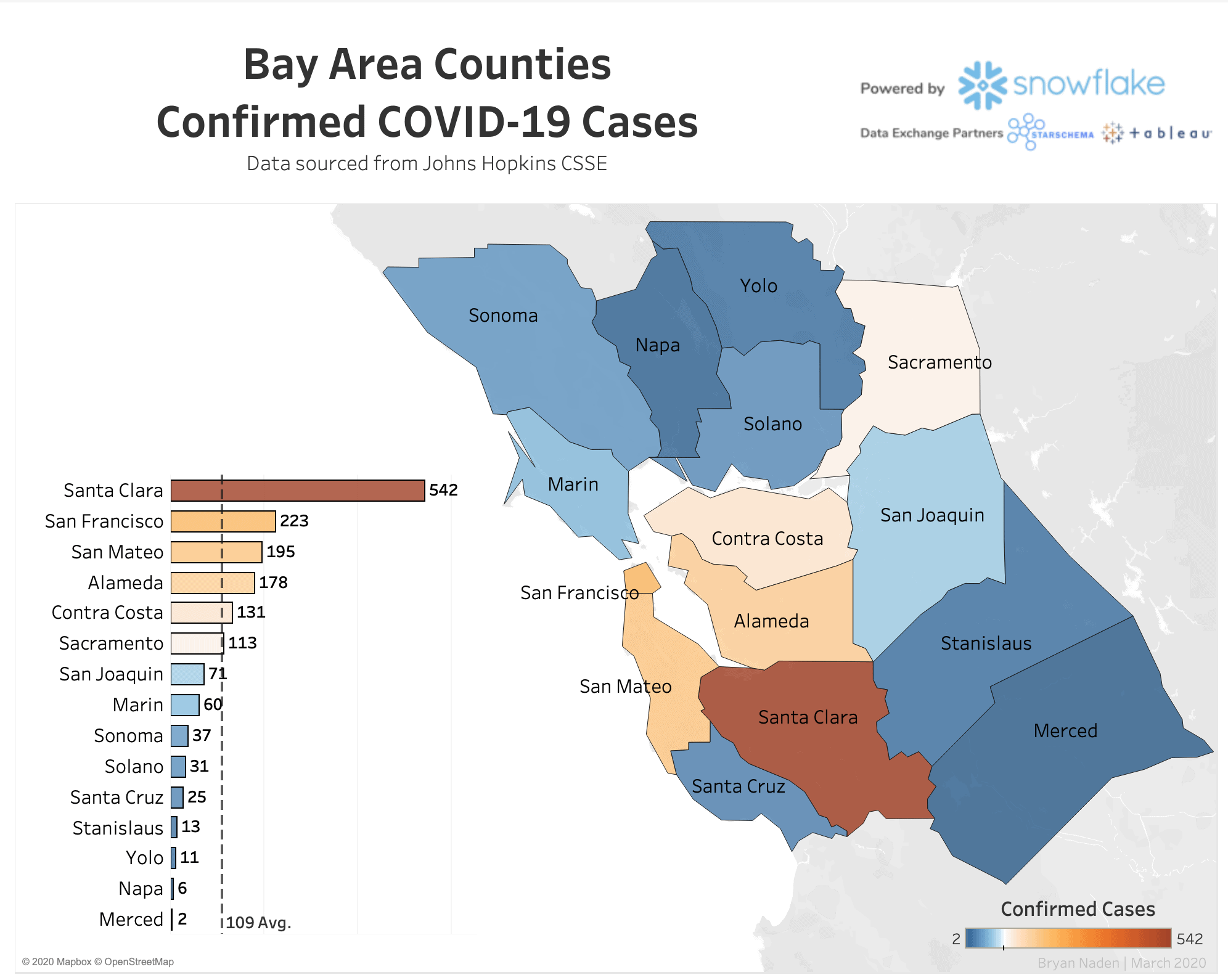
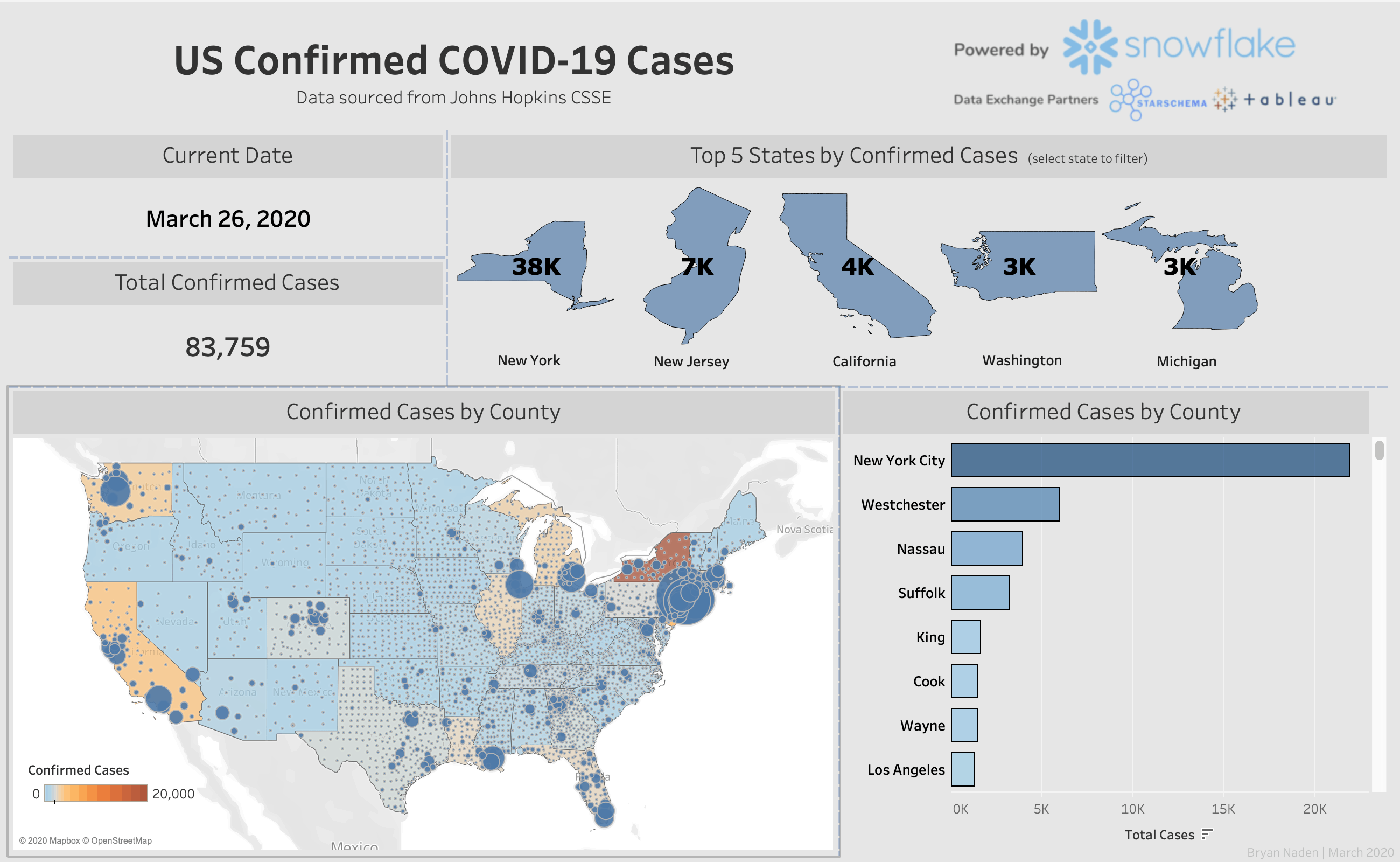
Starschema is also a Snowflake partner and has listed the data set for download, free of charge, on the Snowflake Data Exchange. The data is analytics-ready, with Starschema adding more data sources by the day.
Starschema’s VP of Special Projects, and an epidemiologist, Chris von Csefalvay, says public data about COVID-19 is available but much of it requires “a lot of love” before organizations can use it. “There are data sets that are extremely valuable that are not even remotely analytics-ready,” he says.
So, what does it mean to have this type of data readily available to the thousands of organizations that will likely rely on it? The team at Starschema has identified four elements to providing data that will produce quick, accurate, and impactful insights:
- First and foremost, the data set has to be stored in the cloud, and on a platform that can easily ingest different data types to form a single data set. Data engineering, which focuses on loading data into a repository, has to be simple but powerful to take the headache out of what can be a laborious process if managed manually.
- Second, the technology has to make it easy to add additional data sources to the original data set. Starschema will continue to enrich the COVID-19 data set but organizations that download it will gain even deeper insights by integrating it with their own data. “At the end of the day, the data itself is most useful when you’re using it with your existing data assets. And to unlock the full value, you need one single (data) engine,” Starschema’s CTO, Tamas Foldi said.
- Third, the technology has to be low- or no-maintenance. Many data solutions can require a lot of people to manage them and a lot of hours keeping them up and running. “We want to spend most of our time importing new data rather than maintaining what is already in there. So, maintenance and updating have to be as automated as possible,” Chris von Csefalvay says.
- And lastly, Starschema says there has to be a way to ubiquitously share the data set with anyone who wants it. The hosting data exchange must be cloud-based. It also has to enable the data provider to easily update the data set with additional data sources, so data consumers receive those updates in real time.
The impact of Starschema’s data set has yet to be revealed but hundreds of organizations are already using it. NGO’s, technology providers, financial institutions, and healthcare and manufacturing companies are just some of the industries that have accessed the data set. How big the data set will become, how it will be used, and the impact it will have will emerge as organizations across the globe take part in combating, and planning for, the impact of COVID-19 and other such viruses that may emerge in the future.
To request access to the free, public Starschema COVID-19 data set on the Snowflake Data Exchange, click here.