“Modern” Data Architectures
If you asked almost any current leader in data engineering to draw a “modern” data architecture on a whiteboard (or you searched online for one), you would most certainly get something like the following:
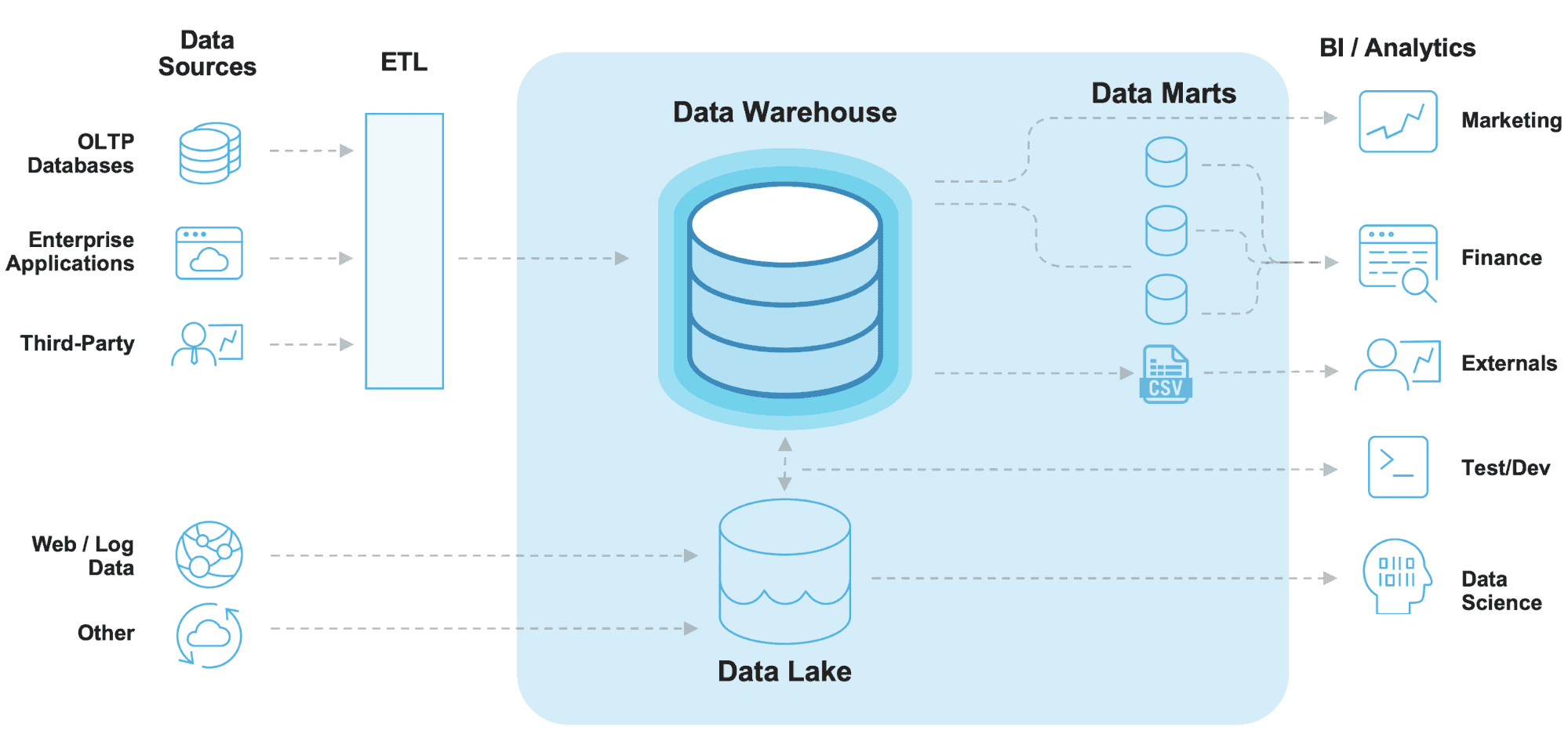
But what’s so modern about this systems-based architecture? It’s been around for almost 10 years and hasn’t changed much. This architecture is composed of three major components:
- The data warehouse
- The data lake
- The data marts (or serving layer)
First there was the data warehouse. The need to have separate data marts and data lakes arose because those traditional data warehouses couldn’t scale to meet the different, competing workloads placed on them. Data marts came about because the central data warehouse couldn’t scale to meet the different workloads and high concurrency demands of end users. Then came data lakes because the enterprise data warehouse wasn’t able to store and process big data (in terms of volume, variety, and velocity).
Data lakes and data marts were created to address a real need in the data engineering space at the time. And even today, data warehouses continue to be unable to support all the varied workloads found in the enterprise. This is true even for the newer cloud data warehouses. The result of these disparate data systems is siloed data, which is very challenging to derive business value from and to govern securely.
But Snowflake Cloud Data Platform has dramatically changed the data landscape and eliminated the need to have separate systems for each of your workloads. Snowflake can be your data warehouse, data marts, and data lake. And that requires us in the data engineering space to think differently about what we’ve been doing. It requires us to understand why we’ve been doing things a certain way and to challenge our assumptions.
Thinking Differently About Data
Over the past couple of years, I’ve noticed that as data architects begin to work with Snowflake, they continue to fall back on that legacy systems–based data architecture design, using Snowflake only as a data warehouse or maybe expanding it a bit to include some data marts. And most continue to argue for maintaining a separate file-based data lake outside of Snowflake, even when building one from the ground up. But why continue to think this way when Snowflake can replace all of these systems?
In order to move forward, we need to stop thinking about data in terms of existing types of systems, such as legacy data warehouses, data marts, and data lakes. Doing that is not helpful and it introduces an unnatural and artificial boundary in an enterprise data landscape.
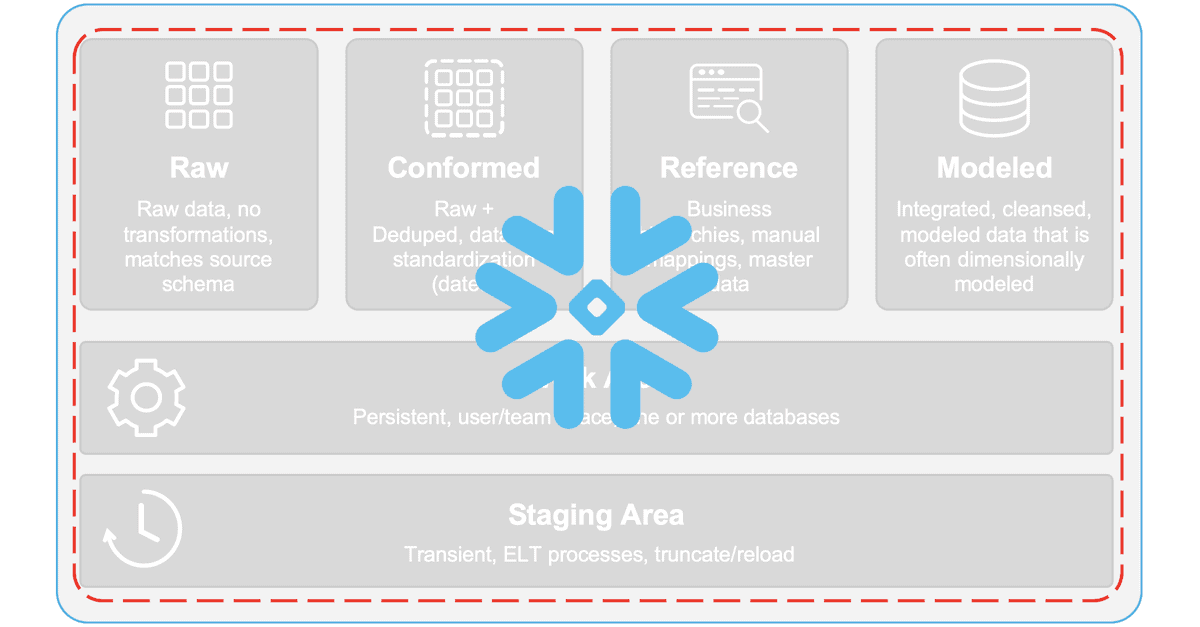
Here is a suggestion for how to think about data differently. At a high level, you can group all enterprise data into the following logical data zones:
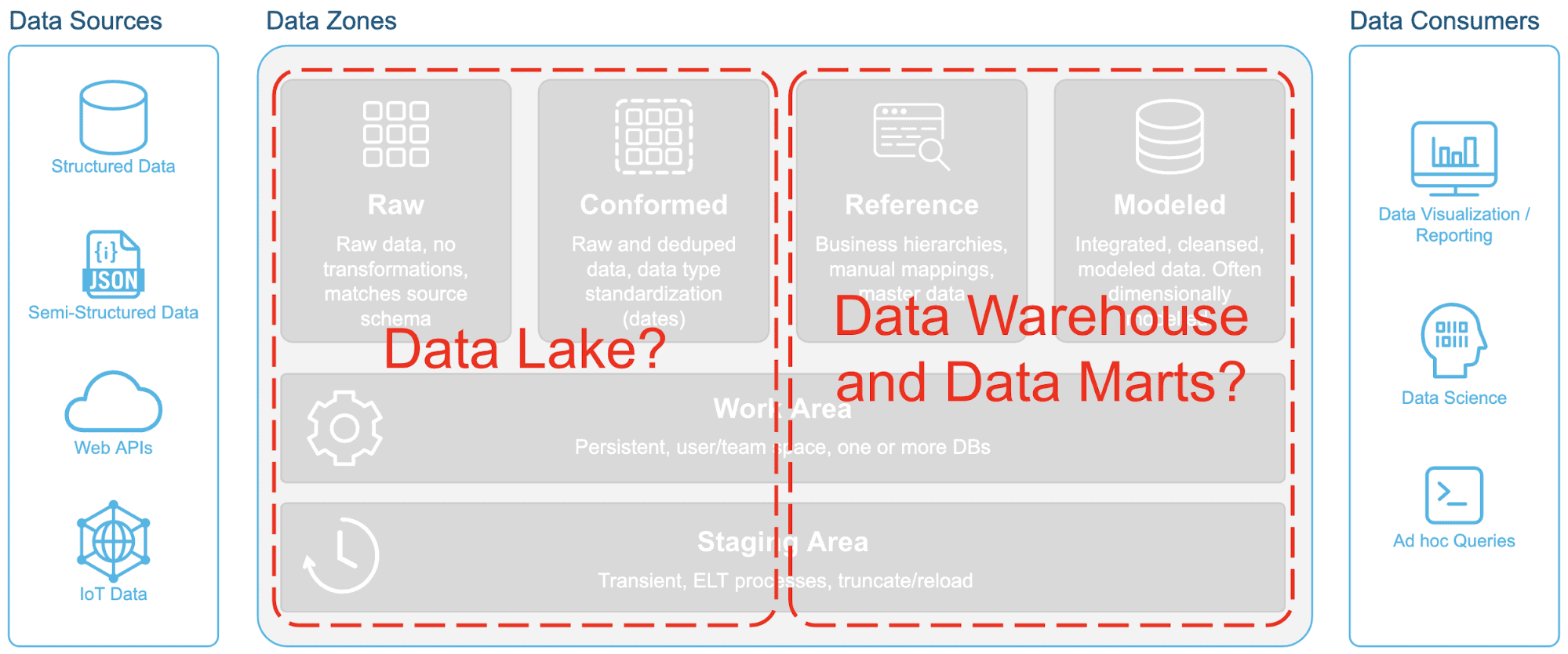
So let’s start thinking about data in terms of zones such as this, not as systems. The old systems-based thinking will continue to keep data engineering professionals locked into old ways of doing things and will continue to fragment the data landscape. With Snowflake, there is no need to divide the data zones into disparate, siloed data systems such as this:
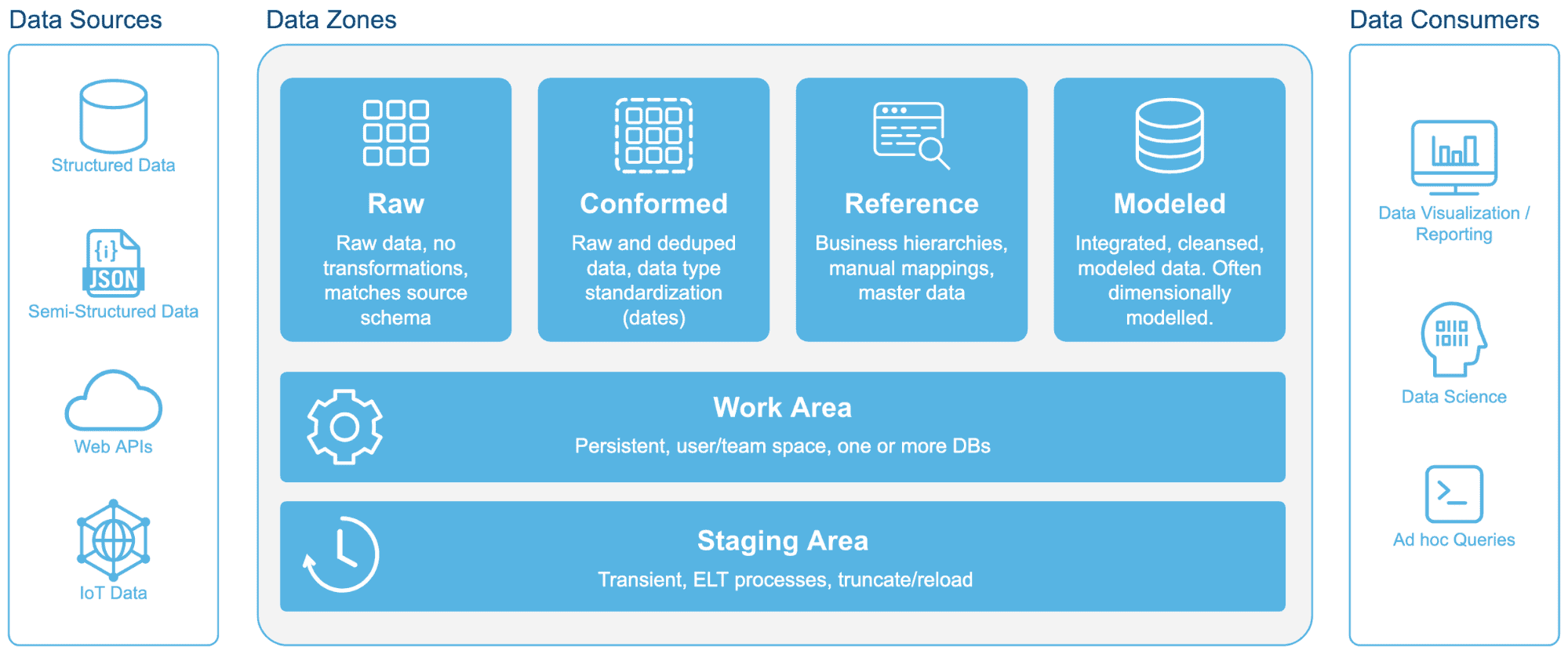
Why think along those lines any longer when a single platform such as Snowflake can break down these silos? Instead of thinking along system lines, we should consider a single platform for all enterprise data such as this:
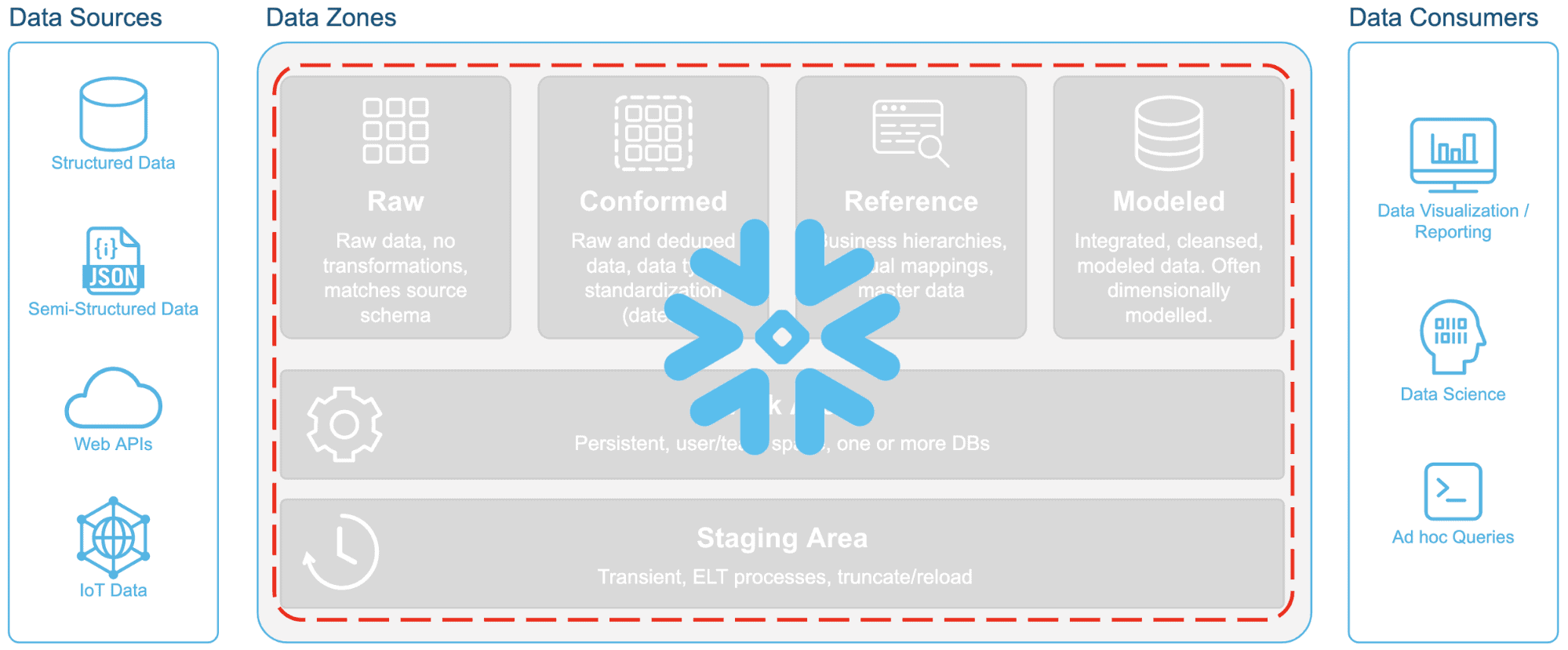
One Platform for All Enterprise Data
Several names are used today to identify where data is located and how it is used, including operational data store (ODS), corporate information factory (CIF), data warehouse, data mart, and many more. Each term represents a different way to group data within the enterprise. But unfortunately, today those different groups of data represent different data systems. Let’s start thinking about data in terms of zones (or types of data) not as systems.
The goal was never to split the data landscape into multiple disparate systems, in particular, into the data warehouse, data marts, and data lakes. We need to stop doing things because “they’ve always been done that way” and rethink what we’re trying to accomplish. I would argue that the goal should be to have one platform for all enterprise data, for example, something like this:
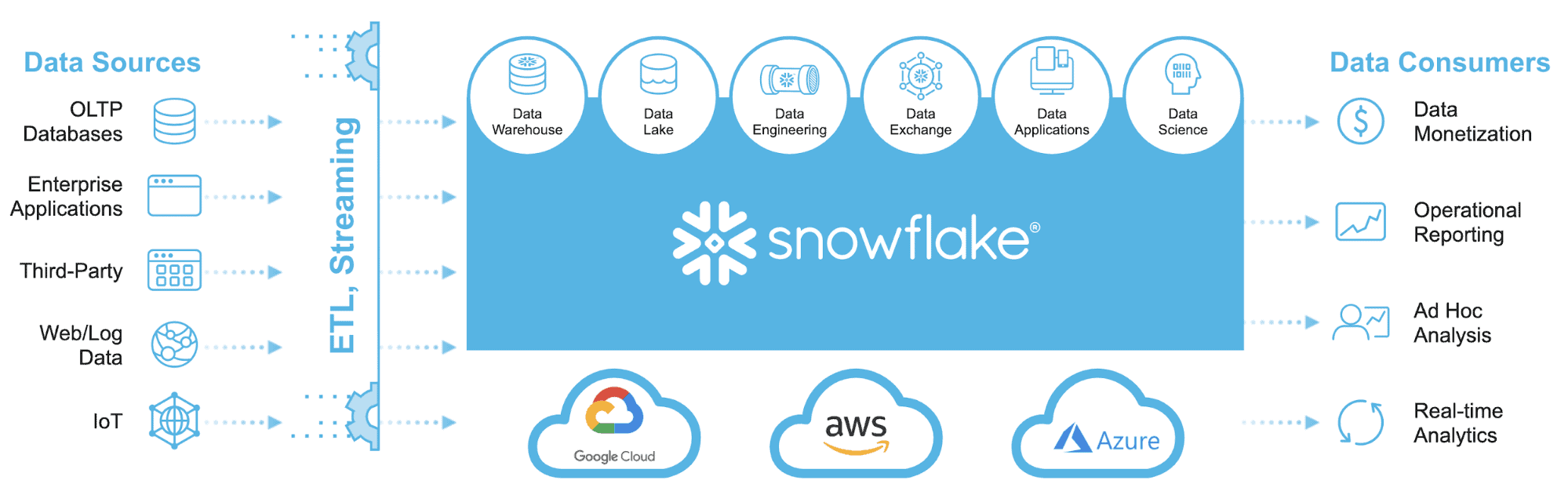
Snowflake Cloud Data Platform can support all your data warehouse, data lake, data engineering, data exchange, data application, and data science workloads. With support for just the first two of those workloads alone, you can consolidate your data warehouse, data marts, and data lake into a single platform.
Most other “cloud” data warehouses were designed 20+ years ago and have been moved to the cloud. They’re unable to truly leverage the scalability of the cloud. And those systems that have been designed more recently don’t offer a complete enterprise data management experience that offers governance, ACID-compliant transactions, live data sharing, a cross-cloud global footprint, a fully managed service, and so on. Snowflake is the only cross-cloud, global cloud data platform. It’s time to start thinking differently about our data.