
注:本記事は(2022年10月10日)に公開された(Combat AI Bias with Data Diversity and Data Collaboration)を翻訳して公開したものです。
AIの採用が増えています。PwCの調査によると、52%の企業がコロナ禍においてAIプロジェクトを促進しており、25%が広く普及したAIの採用により完全に有効化されたプロセスを保有している、と答えています。また、AIが自社の「メインストリームテクノロジー」となるだろう、と答えた回答者は全体の86%に上ります。

AIのユースケースは、予測から意思決定をサポートする提案まで幅広く、機械により生成されたインサイトと人による介入の間でバランスをとっています。
- スポーツの試合の勝敗、病気の蔓延、不正行為、メンテナンスニーズといった、アウトカム予測や特定のアウトカムおよび現象の可能性予測。
- 広告配置やデータアプリケーションにおける互換性プロファイル向けの、Look Alikeやオーバーラップ分析のような最適な職場配置や治験の決定。
- セグメントや個人に特有の情報に基づく具体的な製品やサービス、医療行為、ラーニングパス、その他の行為の推奨。
- 一般的なパターンや相関関係を特定して選択を合理化し意思決定プロセスを促進することによる、ユースケースにまたがる意思決定サポート
しかし、心配事も尽きません
AIを採用したリーダーたちにとって、眠れない夜は共通の問題のようです。懸念事項は多々あり、その内容も、テクノロジーの成熟度やデータの品質不足からスキルギャップや信頼の欠如まで、多岐にわたっています。政治家や国民が言及する永続的な懸念事項は、アルゴリズム的バイアスおよび差別や意図しない結果に対するリスクです。

AIの効果に対する懸念は、AI倫理や規制の提唱者によって声高に叫ばれていますが、問題へのアプローチ方法にはばらつきがあります。さらに、既存の規制やガイドライン、これらの草案を寄せ集めたことで、意見が多岐に分かれる状況を生み出しています。Algorithm Watchによると、倫理的なAIに向けたガイドラインやフレームワーク、167件が政府、企業、学者により公開されています。しかし、この喧騒を打ち破る1つのソリューションがあります。
2021年、EUは世界に影響する可能性を持つAI法を提唱しました。GDPRと同じように、EUによるAI法は他の管轄地域における規制のモデルとなる可能性がありました。この法令は「潜在的に…行動を著しく歪め…個人情報操作の重大な可能性があり…有害となる」ような行為を禁止するもので、EUが定めた初期のEthics Guidelines of Trustworthy AI(信頼できるAIのための倫理ガイドライン)と同様、新しい規制も、容認できない、高リスク、限定リスク、リスクなし、といったリスクカテゴリーを、例やプロジェクト評価用試験とともに設定することになりました。例えば、求職者をランク付けするCVスキャンツールは高リスクに分類され、特定の法的要件が適用される予定です。
他の規制の多くが研究を要求し、過去の「公正な」法規、例えば「Fair Housing Act(公正住宅取引法)」や「Fair Credit Reporting Act(公正信用報告法)」に依存するようになっているため、EU規制は、ヨーロッパでビジネスを行う企業すべてに適用される、最も広く採用されている法規となりそうです。法規には施行と罰則が伴います。罰金の最高額はグローバルな売上高の最大6%または3600万ドルのどちらか高額な方となっており、GDPRの罰金の最高額である4%を超えるものとなっています。
データの多様性を使用したAIバイアスに関する懸念事項の解消
明らかに、AIとは複雑なものであり、懸念事項は多方面から対応する必要があります。けれども、潜在的AIバイアスに対応する最良の方法のひとつは、データ多様性の確保だと思います。さまざまなデータソースを有することは、特定のデータセットに固有のバイアスの防止に役立ちます。そのため、ビジネスにとってはあらゆる種類のデータが重要なのです。
ビッグデータは、トランザクションデータやセンサーデータといった膨大な量のデータの分類を可能にし、顧客やオペレーションに対する理解の向上につながるインサイトを生成してくれます。けれども、最も重要なファクターは必ずしもデータの規模ではなく、データの多様性です。中国に拠点を置くAlibabaのAnt Groupは、3,000以上の変数を用い小規模事業者の融資評価を行っています。本プロセスは、すでに1600万社を超える企業に資金を融通しているのですが、Fortuneの報告によると約1%の初期設定レートを適用しています。モデルのトレーニングに使用される数多くの変数は、非常に多様な、幅広いデータであることを示しています。しかし、すべての企業が顧客に関する何千ものデータポイントにアクセスできるわけではありません。

また別の例では、より小規模ながらも多様なデータに対するテクニックを説明しています。ヘルスケアペイヤーイノベーションアワードのファイナリストであるHealthfirstとMHNが言及したように、2020年春、米国疾病予防管理センターはCOVIDリスクの予測モデルを公開しました。しかし、本モデルは当初、医療データのみを使用してトレーニングされていたことから、そのほとんどが年配の人々を反映する結果となっていました。いくつかのプロバイダーが本モデルをMedicaidデータ上で再トレーニングし、あらゆる年齢層のより貧困な患者を反映するようにしました。その後、本モデルがオープンソース化され、別の6つのプロバイダーがモデルトレーニングを行い、処方箋の調合がなかったぜんそく患者といった、リスクにさらされている新たな患者層の発見につながりました。本モデルは、これらのプロバイダーにとって、治療の優先順位を決め、よりリスクの高い層に手を差し伸べる役に立っています。
「最も重要なファクターは必ずしもデータの規模ではなく、データの多様性。」
多様なデータは、よりリッチなインサイトを推進します。あらゆる規模や種類のデータの層により、モデルの精度やインサイトのインパクトが向上します。例えば、コロナ禍の期間中、消費者行動は変化しましたが、新たなデータソースも出現しました。1-800-Flowersでは、変化し続ける新型コロナ感染症の感染率やワクチン接種率が同社のビジネスに与える影響をハイパーローカルレベルで評価し、需要と供給の予測の精度を向上させるためには、新たなデータが不可欠でした。別の例では、Krogerの子会社である84.51が、米国の全家庭の半数および毎年数十億件に及ぶ取引から得られたファーストパーティのリテールデータを活用しています。同社は、自社のデータを他社のデータと連携させることで、サプライチェーン予測の更新やオンライン購入者向けのパーソナライズされたエクスペリエンスの作成といったユースケースのために、KrogerやCPG顧客にインサイトを提供しています。
希少なデータエコノミーリーダー
企業は、新たなデータソースすべてに目を向けて、フレッシュインサイトの推進をサポートし、AI採用の加速化する必要があります。多くの企業はこの点を理解していますが、実際に成功を収めている企業はほとんどありません。 2021年の調査によると、企業の78%が外部データの取得にかける予算を増加させる計画を立てていました。
しかしながら、Snowflakeが委託した新たな調査、「How to Win in Today’s Data Economy 2022(現代のデータエコノミーの勝者になる方法)」によると、真のリーダーと言えるのはわずか6%の企業であるということです。このような企業は、ほとんどすべての意思決定がデータドリブンであり、戦略的ビジネス目標の推進の大部分、またはかなりの部分でデータを使用していると報告しています。こういった企業では、データが社内のどこに保存されているかに関係なく、データの共有や外部からのアクセスを通じて、自社データへのユビキタスアクセスを可能にしています。
「成長を遂げるデータエコノミーにおいて、自社データへのユビキタスアクセスや外部からのデータシェアリングが可能な真のリーダーと言える企業はわずか6%である。」
調査によると、ほとんどの企業は、ユースケースの垣根を越えて幅広くデータを使用する計画を立てています。しかし、外部データの共有やソーシングの機会があるにもかかわらず、昨年よりデータの使用量が増加したと報告しているのは約半数に留まっています。
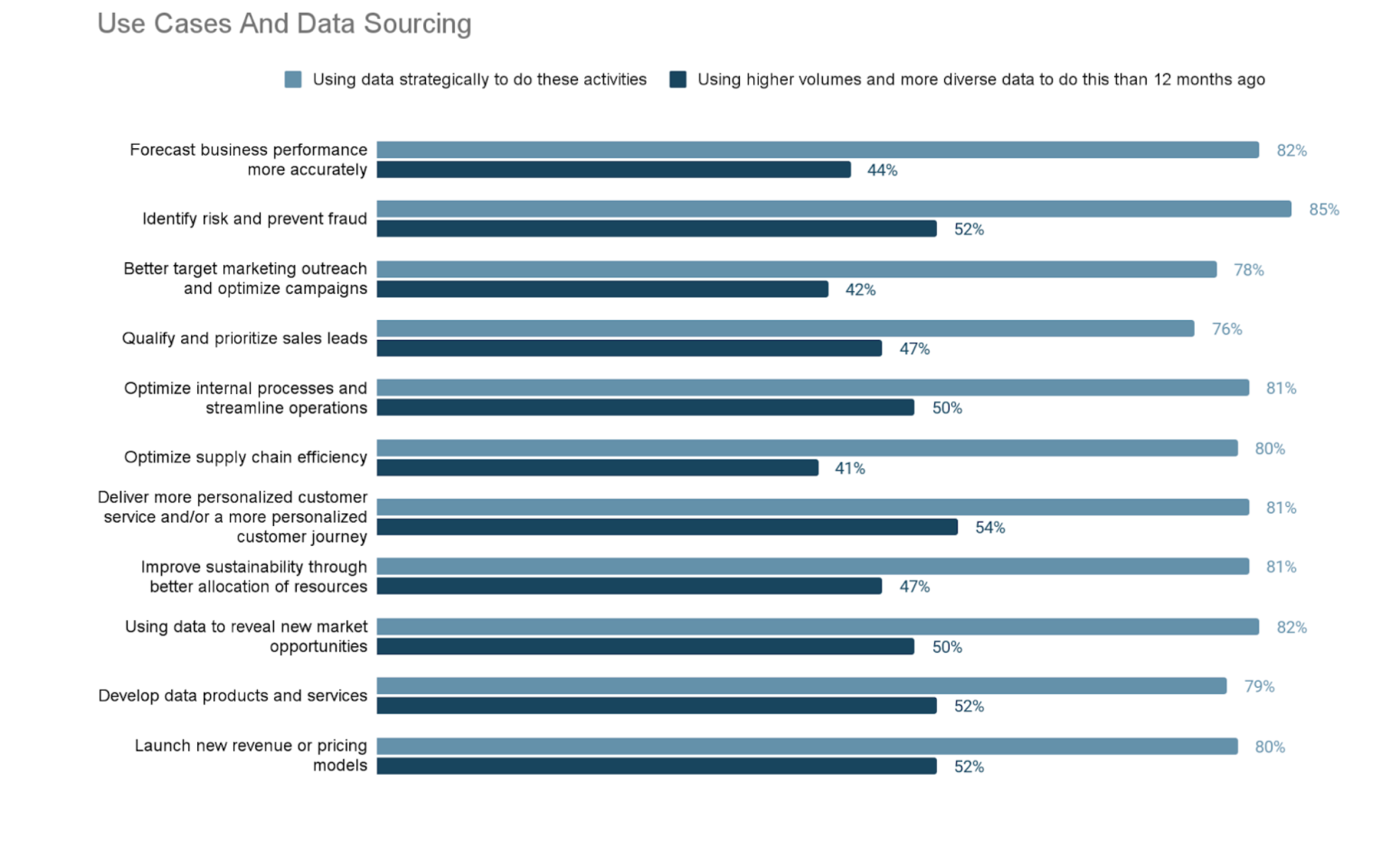
高度なアナリティクスやAIのユビキタス化が進むにつれ、データアクセスやデータシェアリングにおけるベストプラクティスをより幅広く採用する必要があります。これを怠ると、データやアナリティクスのリーダーたちは睡眠不足に悩まされることになるでしょう。