
AI adoption is on the rise. A study by PwC found that 52% of companies have accelerated their AI projects during the pandemic, and 25% now have processes fully enabled by AI with widespread adoption. Of all the respondents in the survey, 86% said that AI would become a “mainstream technology” at their company.

The use cases of AI are extensive, ranging from predictions to recommendations to decision-support that balances machine-generated insights and human intervention. Examples include:
- Predicting outcomes or the likelihood of specific outcomes or phenomena, such as win or loss in sports, disease outbreaks, fraudulent activity, or maintenance needs.
- Determining best fit for job placement or clinical trials, including techniques like look alike or overlap analysis for ad placement or compatible profiles on data apps.
- Recommending specific products or services, medical treatments, learning paths, or other actions based on information specific to a segment or individual.
- Supporting decisions across use cases by identifying general patterns and correlations to streamline choices and facilitate decision-making.
But what still keeps us up at night?
Sleepless nights are apparently not uncommon among leaders adopting AI. The list of concerns is long, and ranges from the maturity of technology and insufficient data quality to skills gaps and lack of trust. A perennial concern expressed by politicians and the public is algorithmic bias and the risk of discrimination and unintended consequences.

Concerns about the effects of AI are loudly voiced by advocates of AI ethics and regulation. Approaches to the problem vary, however. And, the patchwork of existing and draft regulations and guidelines reflect this diversity of opinion. According to Algorithm Watch, 167 guidelines and frameworks for ethical AI have been published by governments, companies, and academics. But there is one that is poised to break through the noise.
In 2021 the EU proposed AI legislation with a potentially global influence. Like GDPR, the EU AI Act has the potential to be a model for regulation in other jurisdictions. Similar to the earlier EU Ethics Guidelines of Trustworthy AI, which prohibits practices that “have a significant potential to manipulate persons … subliminally … in order to materially distort their behavior … causing harm,” the new regulation would establish risk categories—unacceptable, high-risk, limited-risk, no risk—with examples and tests for evaluating projects. For example, a CV-scanning tool that ranks job applicants would be considered high-risk and would be subject to specific legal requirements.
With much of the other regulations calling for studies and falling back on past “fair” practices legislation, like “fair housing” and “fair credit,” the EU regulation is likely to be the one most widely adopted, as it applies to anyone doing business in Europe. And with that comes enforcement and penalties. The maximum fines are up to 6% of global turnover or a $36M maximum, whichever is higher—exceeding GDPR’s maximum penalty of only 4%.
Address concerns about AI bias with data diversity
Obviously, AI is complex and concerns must be addressed on multiple fronts. However, one of the best ways to address potential AI bias is to ensure data diversity. A variety of data sources helps prevent bias inherent in a specific data set. As such, data of all kinds is important to business.
Big data enables businesses to sort through massive amounts of data such as transaction data or sensor data, and derive insights that improve understanding of customers or operations. However, the most important factor is not always the size of the data but rather its diversity. Alibaba’s Ant Group in China uses over 3,000 variables to evaluate loans to small businesses. The process, which has delivered funds to over 16 million businesses, has a default rate so far of about 1%, as reported by Fortune. The number of variables used to train the models represents extremely diverse, or wide, data. But not all companies have access to thousands of data points about their customers.

Another example illustrates techniques of smaller, but also diverse, data. As covered by the Healthcare Payer Innovation Award Finalists Healthfirst and MHN, in the spring of 2020, the U.S. Centers for Disease Control and Prevention published a model predicting COVID risk. However, the model was trained initially on Medicare data alone, representing a predominantly elderly population. Several providers retrained the model on Medicaid data, representing poorer patients of all ages. The model was then open sourced and six other providers contributed to model training, uncovering new at-risk populations such as asthma patients who had not filled their prescriptions. The model helped these providers prioritize care and outreach for vulnerable populations.
« The most important factor is not always the size of the data but rather its diversity. »
Diverse data drives richer insights. Layers of data—of all sizes and kinds—improve accuracy of models, and impact of insights. For example, during the pandemic, consumer behavior changed, but new data sources also appeared. At 1-800-Flowers, new data was critical to assess the impact of changing COVID-19 infection and vaccination rates on its business at a hyper-local level to better predict supply and demand. In another example, 84.51, a subsidiary of Kroger, leverages first-party retail data from half of all U.S. households and from billions of transactions every year. By connecting its data with other companies’ data, the company provides insights to Kroger and CPG customers, for use cases such as updating supply chain forecasts or creating personalized experiences for online shoppers.
Data Economy Leaders are rare
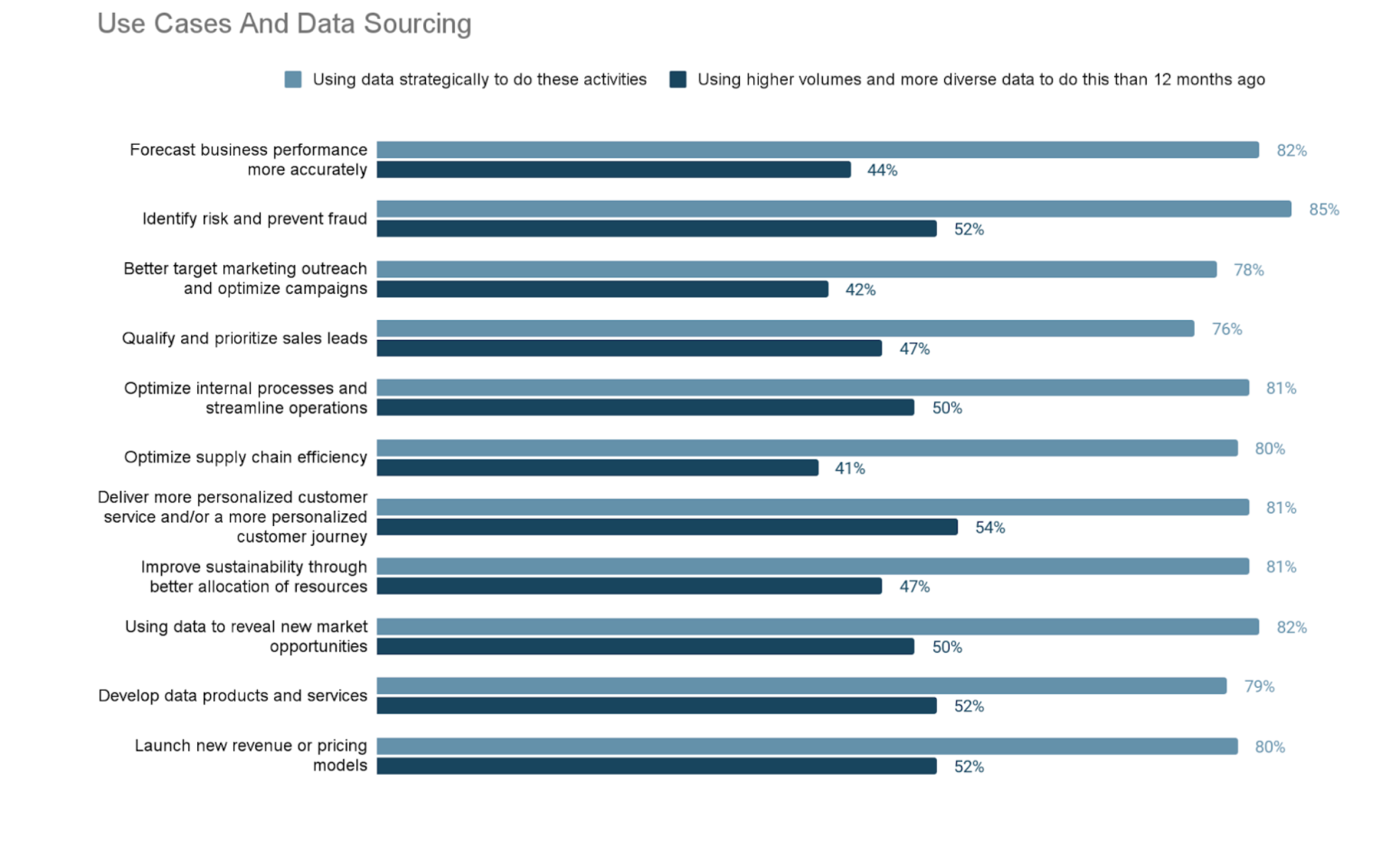
Businesses must look to all new sources of data to support their drive for fresh insights, and to fuel their accelerated adoption of AI. Most companies understand this, but few are successful at doing it. According to a 2021 study, 78% of companies planned to increase their budgets for external data acquisition.
Yet new research commissioned by Snowflake, How to Win in Today’s Data Economy 2022, discovered that only 6% of companies are truly Leaders. These companies report that most or all decisions are data driven, and use data to a great or significant extent to advance strategic business goals. And, they do this through ubiquitous access to their own data, no matter where it resides across the company, and by sharing and accessing data externally.
« Only 6% are leaders in the growing data economy, with ubiquitous access to internal data and the ability to share externally. »
According to the study, most companies plan to use data extensively across use cases. However, despite opportunities to share and source external data, only about half report using more data than last year.
As advanced analytics and AI become more ubiquitous, the best practices in data access and sharing must be adopted more widely. If not, we expect to see many sleep-deprived data and analytics leaders.


