
참고: 이 내용은 2022. 5. 10에 게시된 컨텐츠(Combat AI Bias with Data Diversity and Data Collaboration)에서 번역되었습니다.
AI를 도입하는 사례가 증가하고 있습니다. PwC의 한 연구에 따르면 52%에 달하는 기업들이 팬데믹 당시 AI 프로젝트에 박차를 가했으며 기업의 25%는 현재 널리 사용 중인 완전한 AI 지원 과정을 보유하고 있습니다. 전체 설문 응답자의 86%는 AI가 다니는 회사에서 ‘주류 기술’로 자리매김할 것이라고 말했습니다.

AI를 사용하는 사례는 예측에서 조언, 기계가 만들어낸 인사이트와 인간의 개입 사이의 균형을 유지하는 의사 결정에 대한 지원에 이르기까지 그 범위가 넓습니다. 예시는 다음과 같습니다.
- 스포츠의 승패와 질환 발생, 사기 행위 또는 유지 보수 활동의 필요성과 같은 특정한 결과 혹은 현상이 벌어질 가능성이나 결과를 예측합니다.
- 데이터 앱 내 광고 배치나 호환 가능한 프로필을 대상으로 한 유사성이나 중복 분석과 같은 기술을 이용해 직업 소개나 임상 시험 시 적합한 결정을 내립니다.
- 특정한 부문이나 개인에 대한 정보에 기초하여 특정 제품이나 서비스, 의학적 치료와 학습 경로, 기타 조치에 대한 조언을 제공합니다.
- 선택을 간단하게 만들고 의사 결정을 촉진하도록 일반 패턴과 연관성을 알아내어 사용 사례 전반에 대한 의사 결정을 내리는 데 도움을 줍니다.
그렇지만 무엇이 우리를 밤중에 깨어 있게 하나요?
분명 AI를 도입한 리더들이 밤중에 깨어 있는 것은 드문 일이 아닙니다. 기술의 성숙도부터 불충분한 데이터 품질, 기술 격차와 신뢰 부족에 이르기까지 우려되는 사항이 너무나도 많습니다. 대중과 정치인들은 알고리즘 편향과 차별 및 의도하지 않은 결과로 인한 위험에 대한 우려를 지속적으로 제기하고 있습니다.

AI 윤리 및 규제를 옹호하는 층에서 AI의 영향력에 대한 우려를 크게 표명하고 있습니다. 그렇지만 문제를 접근하는 방식은 다양합니다. 그리고 기존 및 초안으로 작성된 규제 및 지침이 바뀌어 나가는 데에는 이러한 의견의 다양성이 반영되어 있습니다. Algorithm Watch에 따르면 여러 정부와 기업 및 학계에서 윤리적 AI를 위한 167개에 달하는 지침과 체계를 발표한 바 있습니다. 그렇지만 이러한 복잡한 상황을 돌파할 준비를 갖춘 한 가지 건의가 있습니다.
지난 2021년 전 세계에 영향을 미칠 가능성이 있는 AI 법안의 건의가 EU에서 있었습니다. GDPR과 마찬가지로 EU의 AI 법률은 다른 관할 권역에서도 규제 역할을 하는 모델이 될 가능성이 있습니다. 신뢰할 수 있는 AI에 대한 기존의 EU 윤리 지침과 비슷하게 해당 법안은 ‘개인을 조종할 중대한 가능성이… 잠재 의식처럼 있는 경우… 실질적으로 사람들의 행동을 바꾸기 위해… 해를 입힐 가능성이 있는’ 관행을 금지하는 새로운 규제는 용납 불가, 고위험, 제한적으로 위험, 위험 없음 등의 범주를 설정하게 될 것입니다. 예를 들어, 구직자를 평가하는 이력서 검사 도구는 고위험 도구로 간주될 것이며 특정한 법적 요건의 적용을 받게 됩니다.
여러 연구를 필요로 하며 ‘공정한 주택 공급’과 ‘공정한 신용 거래’와 같은 과거의 ‘공정한’ 관행을 지키는 법률 제정으로 되돌아가려는 여러 규제로 인해 EU 규제는 가장 널리 채택되는 규제가 될 가능성이 높으며, 이는 유럽의 모든 비즈니스에 적용될 것입니다. 이러한 조치에는 집행과 벌금이 따릅니다. 벌금의 최대치는 글로벌 매출의 최대 6% 또는 최대 $3천 6백만 달러 중 더 높은 금액에 해당하며, 이는 GDPR의 최대 벌금인 4%를 초과하는 수치입니다.
데이터 다양성으로 AI 편향에 대한 우려 해결하기
확실히 AI는 복잡하며 다양한 측면에 존재하는 우려 사항을 해결해야만 합니다. 그렇지만 AI 편향의 가능성을 해결하는 가장 좋은 방법 중 한 가지는 바로 데이터 다양성을 확보하는 것입니다. 다양한 데이터 소스는 특정한 데이터 세트가 품고 있는 편향을 방지하는 데 도움이 됩니다. 그러므로 모든 유형의 데이터가 비즈니스에 중요한 것입니다.
기업들은 빅 데이터를 통해 거래나 감지 데이터와 같은 막대한 데이터를 분류하면서 고객이나 운영을 더욱 깊이 이해할 수 있는 인사이트를 얻을 수 있습니다. 그러나 가장 중요한 요인은 언제나 데이터의 크기가 아닌 다양성입니다. 중국 소재 알리바바의 앤트 그룹은 중소기업에 대한 대출을 평가할 때 3,000가지 이상의 변수를 이용합니다. 해당 프로세스는 1,600만 곳 이상의 기업에 자금을 제공했으며 채무 불이행으로 이어진 기업의 비율은 Fortune의 보고에 따르면 지금까지 약 1%에 불과합니다. 모델을 훈련하는 데 이용하는 변수의 개수는 극도로 다양하고 광범위한 데이터를 대표하는 것입니다. 그렇지만 아무 기업이나 고객 데이터에 담긴 수많은 지점을 활용할 수 있는 것은 아닙니다.

또 다른 예시가 규모가 작으나 다양한 데이터 기술을 보여줍니다. Healthcare Payer Innovation Award 최종 후보에 오른 Healthfirst와 MHN은 지난 2020년 봄 미국 질병 통제 예방 센터(US Centers for Disease Control and Prevention)에서 코로나 위험을 예측하는 모델을 발표한 바 있습니다. 그렇지만 이는 초기에 주로 노인 인구를 대표하는 Medicare 데이터만으로 훈련된 모델이었습니다. 여러 공급업체에서 모든 연령대의 빈곤한 환자를 대표하는 Medicaid의 데이터를 이용해 모델을 다시 훈련시켰습니다. 이러한 과정을 거친 후 이 모델은 오픈 소스로 공개되었으며 6곳에 달하는 여러 공급업체에서 모델의 훈련에 기여함에 따라 처방전을 조제하지 않은 천식 환자와 같은 위험에 처한 새로운 인구 집단을 발견할 수 있었습니다. 이 모델은 공급업체로 하여금 취약 인구 집단에 치료와 봉사 활동을 할 때 우선순위를 지정하는 데 도움이 되었습니다.
“가장 중요한 요인은 언제나 데이터의 크기가 아닌 다양성입니다.”
다양한 데이터가 더 풍부한 인사이트를 선사해 줍니다. 모든 규모와 유형의 데이터 계층은 모델의 정확성을 향상하며 인사이트가 미치는 영향을 증대시켜 줍니다. 예를 들어, 팬데믹 기간 동안 소비자 행동이 바뀌었으며 새로운 데이터 출처도 그 모습을 드러냈습니다. 1-800-Flowers에서는 수요와 공급을 더 잘 예측하기 위해 지역을 벗어난 수준에서 코로나19 감염 및 백신 접종률의 변화가 비즈니스에 미치는 영향을 평가하는 데 새로운 데이터가 중요한 역할을 차지했습니다. 다른 예시를 들자면 Kroger의 자회사인 84.51은 전체 미국 가구의 절반과 매년 수십억 건의 거래에서 얻은 자사의 리테일 데이터를 활용합니다. 자사의 데이터를 타사 데이터와 연결하여 회사는 Kroger 및 CPG 고객에게 공급망 예측이나 온라인 쇼핑객을 위한 맞춤형 경험 만들기 등의 이용 사례와 같은 인사이트를 선사해 줍니다.
드물게 존재하는 데이터 경제 리더
비즈니스에서는 모든 새로운 데이터 소스를 찾아서 새로운 인사이트를 얻기 위한 노력을 지원하고 AI 도입에 박차를 가할 수 있도록 해야 합니다. 대부분의 회사가 이러한 사실을 이해하고 있으나 실제로 성공을 거두는 회사는 드뭅니다. 2021년의 한 연구에 따르면 78%에 달하는 기업에서 외부 데이터 수집을 위한 예산 증액을 계획한 바 있습니다.
그러나 Snowflake가 용역을 맡긴 신규 연구 2022년 데이터 경제에서 승리하는 방법(How to Win in Today’s Data Economy 2022)에 따르면 6%에 불과한 기업만이 진정한 선도자 역할을 하고 있습니다. 이러한 기업은 모든 혹은 대부분의 의사 결정을 데이터에 기반해 진행하며 회사의 전략적인 사업 목표를 추구하기 위해 엄청난 양 혹은 상당한 양의 데이터를 사용한다고 보고한 바 있습니다. 또한 데이터의 위치와 상관없이 자체 데이터를 어디서나 사용할 수 있도록 하며, 외부적으로 데이터를 공유하고 접근함으로서 이러한 작업을 해나가고 있었습니다.
“성장 중인 데이터 경제에서 내부 데이터에 대한 유비쿼터스 액세스와 외부 공유 역량을 갖춘 리더는 고작 6%에 불과합니다.”
연구 결과에 따르면 대부분의 기업은 사용 사례 전반에 걸쳐 데이터를 광범위하게 사용할 계획을 갖고 있습니다. 그렇지만 외부의 데이터를 얻거나 공유할 기회가 있음에도 불구하고 그 중 약 절반의 기업만이 작년보다 더 많은 데이터를 사용하고 있다고 알렸습니다.
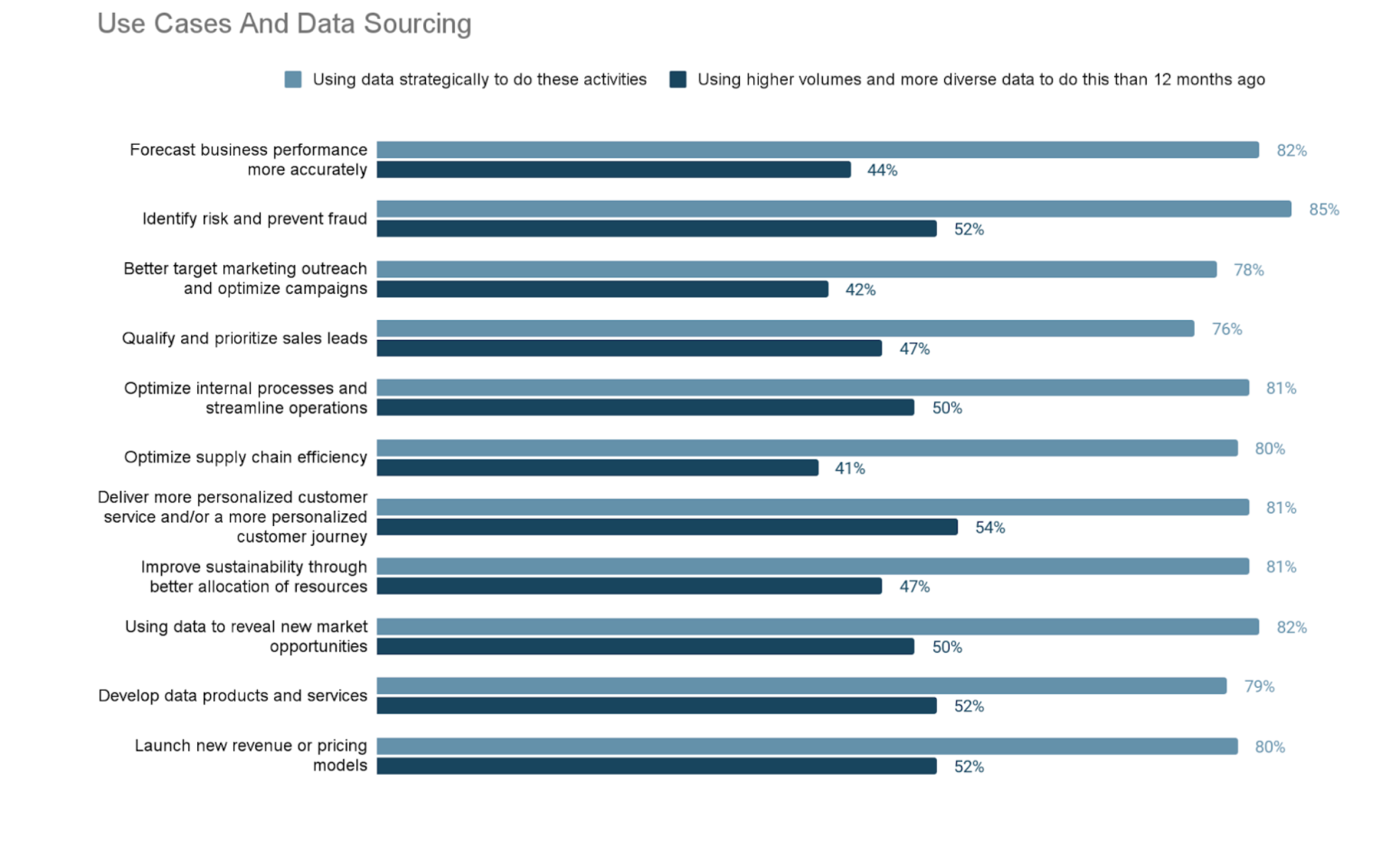
선진 분석 기법과 AI가 흔해짐에 따라서 데이터 액세스 및 공유에 대한 모범 사례가 더욱 널리 도입되어야 합니다. 그렇지 않다면 우리는 잠이 부족한 데이터 및 분석 분야의 리더를 아주 많이 보게 될 것입니다.