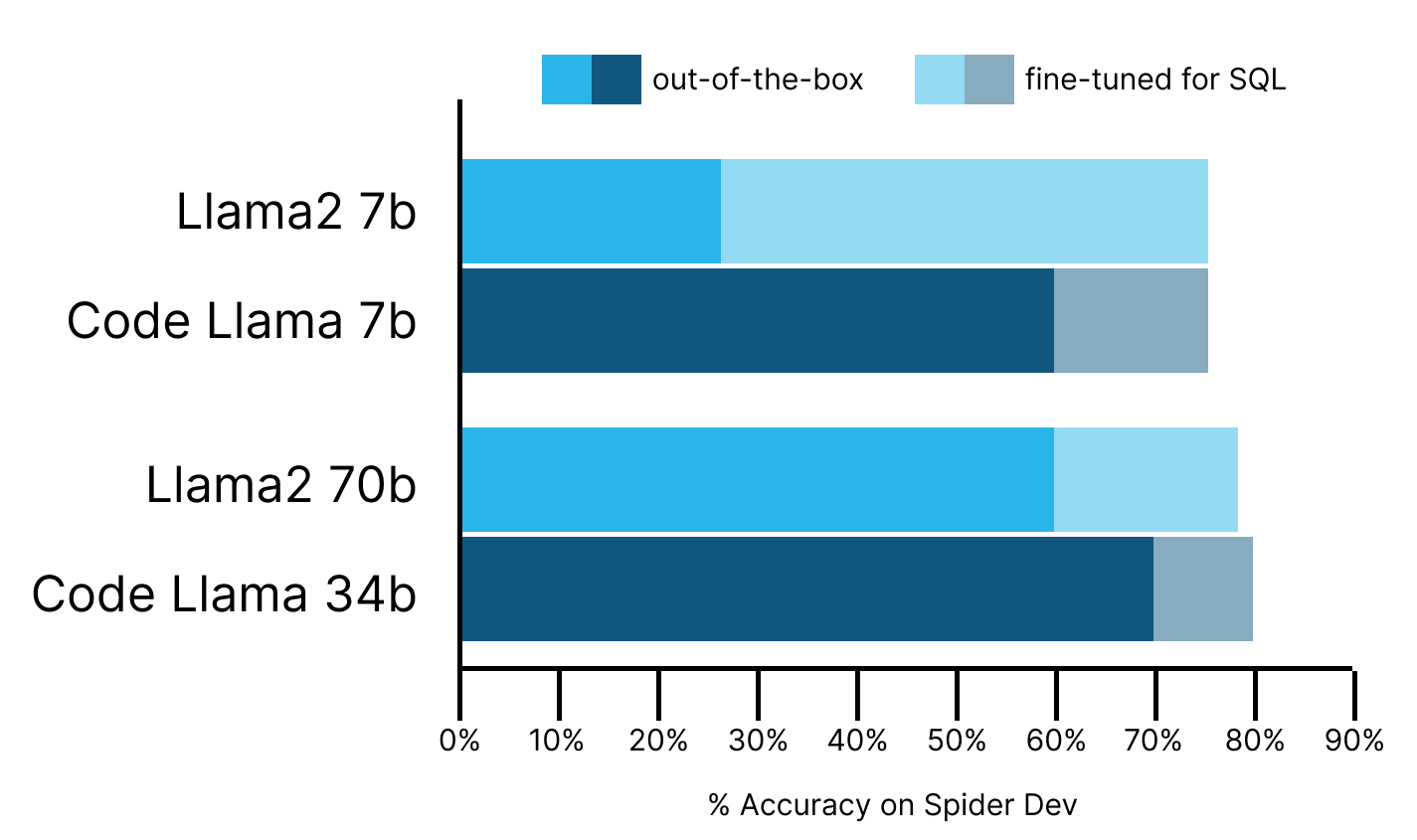
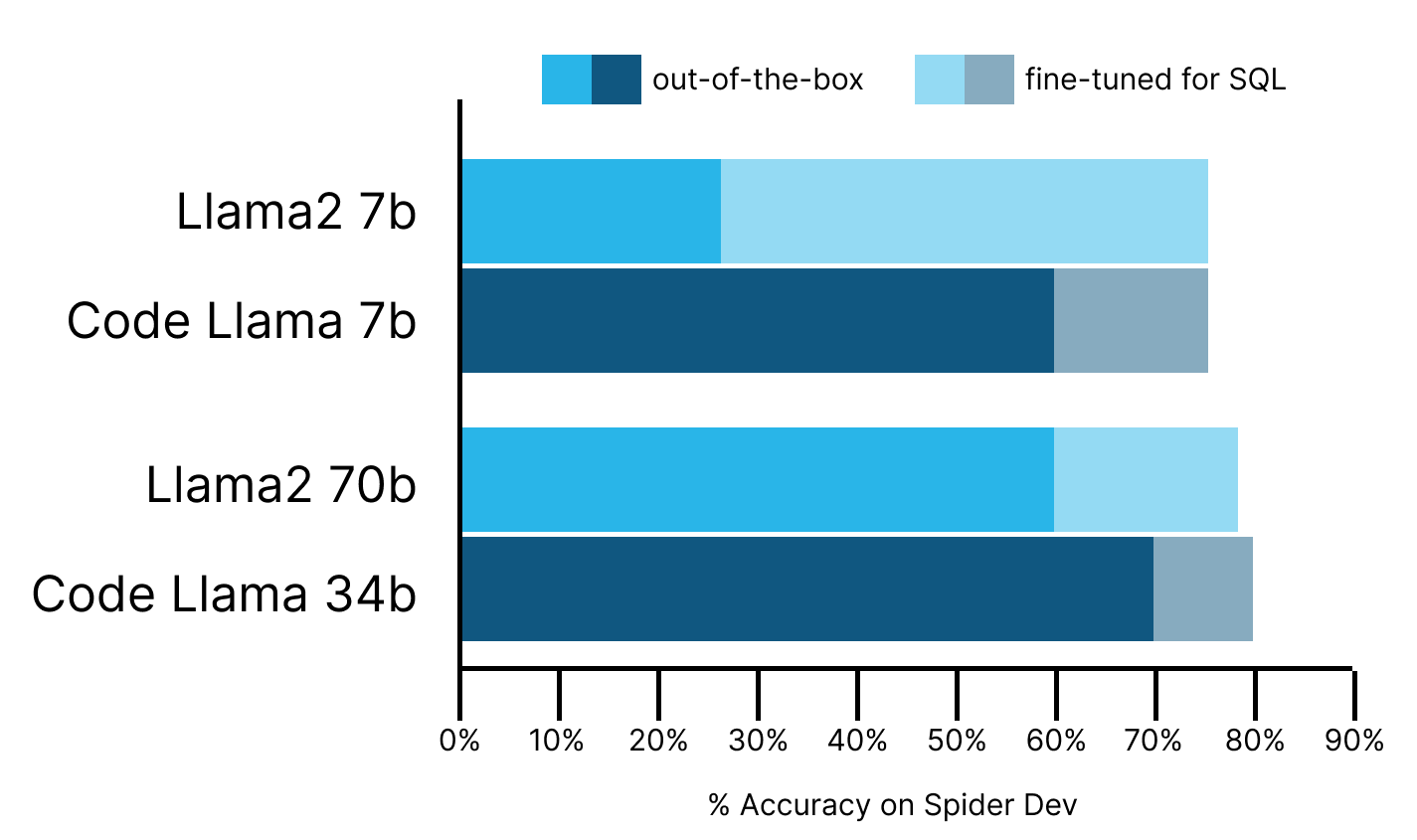
Based on Snowflake’s testing, Meta’s newly released Code Llama models perform very well out-of-the-box. Code Llama models outperform Llama2 models by 11-30 percent-accuracy points on text-to-SQL tasks and come very close to GPT4 performance. Fine-tuning decreases the gap between Code Llama and Llama2, and both models reach state-of-the-art (SOTA) performance.
The Llama2 family of models is one of the seminal developments of the LLM era. Representing the first large-scale foundation models released by a large corporation permissible for commercial use, Llama2 has led to an explosion of experimentation. On Hugging Face alone, the Llama2 family was downloaded over 1.4 million times last month and inspired over 2,400 related models as of August 23.
On August 24, Meta released Code Llama, a new series of Llama2 models fine-tuned for code generation. Along with the model release, Meta published Code Llama performance benchmarks on HumanEval and MBPP for common coding languages such as Python, Java, and JavaScript. SQL—the standard programming language of relational databases—was not included in these benchmarks. As part of our vision to bring generative AI and LLMs to the data, we are evaluating a variety of foundational models that could serve as the baseline for text-to-SQL capabilities in the Data Cloud. We tested the out-of-the-box SQL performance of Code Llama before fine-tuning our own version.
Key takeaways for SQL-generating tasks with Code Llama:
- Out of the box, Code Llama-instruct (7b, 34b) outperforms Llama2-chat (7b, 70b) by 30 and 11 percent-accuracy points, respectively, in a few-shot setting.
- Code Llama-34b-instruct comes very close to GPT4 performance few-shot and is only behind by 6 percent-accuracy points.
- The difference more or less vanishes with our fine-tuned Llama2 (7b, 70b) performing roughly on par with our fine-tuned Code Llama (7b, 34b).
- Our Code Llama fine-tuned (7b, 34b) for text-to-SQL outperforms base Code Llama (7b, 34b) by 16 and 9 percent-accuracy points respectively
Evaluating performance of SQL-generation models
Performance of our text-to-SQL models is reported against the “dev” subset of the Spider data set. Spider’s accessibility makes it possible to pressure-test our findings with externally published numbers. Using execution accuracy, we compared our expected results to the actual results of running the predicted SQL query against the Spider data set, roughly following the implementation here.
Out-of-the-box comparisons with few-shot learning
We started with comparing the Llama2 chat models with Code Llama instruct models using few-shot in-context learning. We tested their skills at SQL generation by using a few-shot prompt specified here. We tested the full range of model sizes by comparing Llama2-chat in 7b and 70b sizes, and Code Llama-instruct in 7b and 34b sizes. Since the larger models are not offered in exactly equivalent model sizes, we decided that the closest comparison is to compare the base Llama2-chat 70b to Code Llama-instruct 34b.
For prompting Llama2 chat versions, we used a version recommended here (see example below). For prompting Code Llama, we simplified this prompt, removing the system component.
We found that Code Llama-instruct-7b outperformed Llama2-chat-7b by 30 points—59% correct vs. 29% correct—interestingly, matching the performance of the 10 times larger Llama2-chat-70b. Code Llama-34b outperformed Llama2-chat-70b by 11 points, reaching execution accuracy of 70% correct, despite being half the size. Perhaps most notably, Code Llama-34b comes within striking distance of GPT4, which is at 76% in a single-call, few-shot setting, as reported by Numbers Station.
Example of SQL generation
To show the various models in action, we will use a generic SQL database (not specifically Snowflake, for this analysis) containing tables with singers, concerts, and stadiums, and evaluate the quality of the models’ proposed SQL statements. The full system and few-shot prompts, including multiple example schemas, are included in the appendix.
Let’s first try to answer the query:
What are the names, themes, and number of singers for every concert?Given this schema:
concert :
concert_ID [ INT ] primary_key
concert_Name [ TEXT ]
Theme [ TEXT ]
Stadium_ID [ TEXT ] concert.Stadium_ID=stadium.Stadium_ID
Year [ TEXT ]
singer :
Singer_ID [ INT ] primary_key
Name [ TEXT ]
Country [ TEXT ]
Song_Name [ TEXT ]
Song_release_year [ TEXT ]
Age [ INT ]
Is_male [ bool ]
singer_in_concert :
concert_ID [ INT ] primary_key singer_in_concert.concert_ID=concert.concert_ID
Singer_ID [ TEXT ] singer_in_concert.Singer_ID=singer.Singer_ID
stadium :
Stadium_ID [ INT ] primary_key
Location [ TEXT ]
Name [ TEXT ]
Capacity [ INT ]
Highest [ INT ]
Lowest [ INT ]
Average [ INT ]Llama2-7b-chat makes a good attempt but makes a mistake in assuming that there will never be two singers at the same concert with the same name (counting distinct Singer_IDs would be better and more efficient here), and it also produces an incorrect join between the Stadium_ID and Singer_ID fields.
select concert.concert_name, concert.theme, count(distinct singer.Name) as num_singers from concert inner join singer on concert.Stadium_ID = singer.Singer_ID inner join singer_in_concert on singer.Singer_ID = singer_in_concert.Singer_ID group by concert.concert_name, concert.theme;Llama2-70b-chat gets the distinct count on ID vs. Name right, and gets the joins right, but it adds an unnecessary join with the singer table and appends an ORDER BY clause that was not requested in the prompt. Also, we observed that sometimes it tacks on an explanation at the end (even if you ask it not to), which we discard when extracting executable SQL.
Note that this query selects non-aggregated concert_Name and concert_Theme columns that are not in the GROUP BY, but some SQL databases do allow this construct when grouping by a table’s primary key.
select concert.concert_Name, concert.Theme, count(singer_in_concert.Singer_ID) as num_singers
from concert
inner join singer_in_concert on concert.concert_ID = singer_in_concert.concert_ID
inner join singer on singer_in_concert.Singer_ID = singer.Singer_ID
group by concert.concert_ID
order by concert.Year desc;Code Llama-7b-instruct does much better than Llama2-7b. It uses Singer_ID to count (perhaps because it has a better conception of “ids” being more unique than “names”), and it avoids extra joins. However, it does group by only Name and Theme incorrectly—there could be more than one concert with the same name and theme, say for a concert tour—but, in this case, it still happens to produce the right result. A perfect SQL statement would also group the results by concert_ID to handle such potential situations.
select concert.concert_Name, concert.Theme, count(singer_in_concert.Singer_ID) from concert inner join singer_in_concert on concert.concert_ID = singer_in_concert.concert_ID group by concert.concert_Name, concert.Theme;Then, we tried another prompt:
What are the names and locations of the stadiums that had concerts that occurred in both 2014 and 2015?This query is more difficult because there are many ways to get it wrong. And indeed we see a varying level of sophistication in responses from the models. The few-shot prompting structure is the same as shown in the appendix.
Both Llama2-7b-chat and Code Llama-7b-instruct get it wrong in a silly way—it’s impossible for a row in the concert table to have both year = 2014 and year = 2015 at the same time, so their proposed queries will incorrectly produce no results.
select Stadium.Name, Stadium.Location from Stadium inner join concert on Stadium.Stadium_ID = concert.Stadium_ID where concert.Year = 2014 and concert.Year = 2015;
Llama2-70b-chat does something better by using an “or” condition. On the other hand, it adds an unnecessary inner join with singer_in_concert, and it still does not produce correct results.
select stadium.Name, stadium.Location from stadium
inner join concert on stadium.Stadium_ID=concert.Stadium_ID
inner join singer_in_concert on concert.concert_ID=singer_in_concert.concert_ID
inner join singer on singer_in_concert.Singer_ID=singer.Singer_ID
where concert.Year='2014' or concert.Year='2015'
group by stadium.Name, stadium.Location
having count( concert.Year) = 2;Code Llama-34b-instruct does something quite clever. Instead of an “obvious” solution of taking the intersection of stadiums with concerts in both 2014 and 2015, it groups by name and location over all concerts held in any of 2014 or 2015 with a count condition of two.
select s.Name, s.Location from stadium s join concert c on s.Stadium_ID = c.Stadium_ID where c.Year in (2014, 2015) group by s.Name, s.Location having count( c.Year) = 2;Fine-tuning models for SQL generation approximates GPT4-level accuracy
After finding a wide gap in few-shot performance, we moved on to fine-tuning these models to see how much we could optimize performance. We fine-tuned the Llama2 and Code Llama base models on a combination of three data sets: Spider train, Bird and a small number of in-house SQL queries over synthetic schemas. In total, this amounts to roughly 26,000 text/SQL pairs. We fine-tuned 7b versions with full fine-tuning, and 70b and 34b with LoRA (without any quantization). Fine-tuning was fairly quick with the longest run (tuning Llama2 70b) taking 90 minutes per epoch on an NVIDIA H100.
It turns out that after fine-tuning, the difference between the two classes of model nearly vanishes (< 1 point difference). Both Llama2 70b and Code Llama 34b achieve close to 80% execution accuracy, which is the best that we’ve observed on a “single try” evaluation. This approximates the accuracy of GPT4’s text-to-SQL skills.
We’re excited about the further improvement that fine-tuning Code Llama demonstrates, and we plan to continue this approach going forward with increasingly larger amounts of fine-tuning training data.
The future of SQL, LLMs and the Data Cloud
Snowflake has long been committed to the SQL language. SQL is the primary access path to structured data, and we believe it is critical that LLMs are able to interoperate with structured data in a variety of ways. It is important to us that LLMs are fluent in both SQL and the natural language of business. Snowflake is leveraging our SQL expertise to provide the best text-to-SQL capabilities that combine syntactically correct SQL with a deep understanding of customers’ sophisticated data schemas, governed and protected by their existing rights, roles and access controls.
As we’re building LLMs at Snowflake, we are also building a platform for organizations to securely fine-tune and deploy open source models for their use cases using their own data with Snowpark Container Services and Snowpark ML model registry, both currently in private preview.
As new versions of Llama, Code Lllama and other open source models become available, Snowflake customers will be able to instantly use them to their advantage. They will be able to further tune them for their own bespoke needs, with vast amounts of their own proprietary Snowflake-stored data, and data from Snowflake Marketplace and Data Cloud—all within their Snowflake accounts.
By securely running inside Snowflake, these models can be used easily and natively via SQL or Python, within data cleansing and ELT pipelines. They can also be fused directly into applications through Snowflake Native Applications and Streamlit.
Importantly, users can train, tune and prompt standard and bespoke LLM models while respecting the role-based access control of the underlying data. Neither the customers’ data, the models, or prompts and their respective completions ever need to leave Snowflake’s governed security perimeter, leveraging the existing security structures in place on the data.
If you’d like to explore this exciting area of Snowflake as part of our Snowpark Container Services private preview, sign up here.
Appendix
Here is the system and few-shot prompt we use for prompting Llama2:
def gen_sql(input, model, tokenizer):
tokens = tokenizer(input, return_tensors="pt", max_length=2048)
tokens = model.generate(input_ids=tokens['input_ids'].to('cuda'), attention_mask=tokens['attention_mask'].to('cuda'), max_new_tokens=512)[:, tokens['input_ids'].shape[1]:]
return tokenizer.batch_decode(tokens, skip_special_tokens=True)[0]
system_prompt = """[INST] <>
You are a coding assistant helping an analyst answer questions over business data in SQL. More specifically, the analyst provides you a database schema (tables in the database along with their column names and types) and asks a question about the data that can be solved by issuing a SQL query to the database. In response, you write the SQL statement that answers the question. You do not provide any commentary or explanation of what the code does, just the SQL statement ending in a semicolon.
< >
"""
instance_prompt= """
Here is a database schema:
department :
Department_ID [ INT ] primary_key
Name [ TEXT ]
Creation [ TEXT ]
Ranking [ INT ]
Budget_in_Billions [ REAL ]
Num_Employees [ REAL ]
head :
head_ID [ INT ] primary_key
name [ TEXT ]
born_state [ TEXT ]
age [ REAL ]
management :
department_ID [ INT ] primary_key management.department_ID=department.Department_ID
head_ID [ INT ] management.head_ID=head.head_ID
temporary_acting [ TEXT ]
Please write me a SQL statement that answers the following question: How many heads of the departments are older than 56 ? [/INST] select count ( * ) from head where age > 56; [INST] Here is a database schema:
book_club :
book_club_id [ INT ] primary_key
Year [ INT ]
Author_or_Editor [ TEXT ]
Book_Title [ TEXT ]
Publisher [ TEXT ]
Category [ TEXT ]
Result [ TEXT ]
culture_company :
Company_name [ TEXT ] primary_key
Type [ TEXT ]
Incorporated_in [ TEXT ]
Group_Equity_Shareholding [ REAL ]
book_club_id [ TEXT ] culture_company.book_club_id=book_club.book_club_id
movie_id [ TEXT ] culture_company.movie_id=movie.movie_id
movie :
movie_id [ INT ] primary_key
Title [ TEXT ]
Year [ INT ]
Director [ TEXT ]
Budget_million [ REAL ]
Gross_worldwide [ INT ]
Please write me a SQL statement that answers the following question: What are all company names that have a corresponding movie directed in the year 1999? [/INST] select culture_company.company_name from movie inner join culture_company on movie.movie_id = culture_company.movie_id where movie.year = 1999; [INST] Here is a database schema:
station :
id [ INTEGER ] primary_key
name [ TEXT ]
lat [ NUMERIC ]
long [ NUMERIC ]
dock_count [ INTEGER ]
city [ TEXT ]
installation_date [ TEXT ]
status :
station_id [ INTEGER ] status.station_id=station.id
bikes_available [ INTEGER ]
docks_available [ INTEGER ]
time [ TEXT ]
trip :
id [ INTEGER ] primary_key
duration [ INTEGER ]
start_date [ TEXT ]
start_station_name [ TEXT ]
start_station_id [ INTEGER ]
end_date [ TEXT ]
end_station_name [ TEXT ]
end_station_id [ INTEGER ]
bike_id [ INTEGER ]
subscription_type [ TEXT ]
zip_code [ INTEGER ]
weather :
date [ TEXT ]
max_temperature_f [ INTEGER ]
mean_temperature_f [ INTEGER ]
min_temperature_f [ INTEGER ]
max_dew_point_f [ INTEGER ]
mean_dew_point_f [ INTEGER ]
min_dew_point_f [ INTEGER ]
max_humidity [ INTEGER ]
mean_humidity [ INTEGER ]
min_humidity [ INTEGER ]
max_sea_level_pressure_inches [ NUMERIC ]
mean_sea_level_pressure_inches [ NUMERIC ]
min_sea_level_pressure_inches [ NUMERIC ]
max_visibility_miles [ INTEGER ]
mean_visibility_miles [ INTEGER ]
min_visibility_miles [ INTEGER ]
max_wind_Speed_mph [ INTEGER ]
mean_wind_speed_mph [ INTEGER ]
max_gust_speed_mph [ INTEGER ]
precipitation_inches [ INTEGER ]
cloud_cover [ INTEGER ]
events [ TEXT ]
wind_dir_degrees [ INTEGER ]
zip_code [ INTEGER ]
Please write me a SQL statement that answers the following question: What are the ids of stations that have latitude above 37.4 and never had bike availability below 7? [/INST] select id from station where lat > 37.4 except select station_id from status group by station_id having min ( bikes_available ) < 7; [INST] Here is a database schema:
concert :
concert_ID [ INT ] primary_key
concert_Name [ TEXT ]
Theme [ TEXT ]
Stadium_ID [ TEXT ] concert.Stadium_ID=stadium.Stadium_ID
Year [ TEXT ]
singer :
Singer_ID [ INT ] primary_key
Name [ TEXT ]
Country [ TEXT ]
Song_Name [ TEXT ]
Song_release_year [ TEXT ]
Age [ INT ]
Is_male [ bool ]
singer_in_concert :
concert_ID [ INT ] primary_key singer_in_concert.concert_ID=concert.concert_ID
Singer_ID [ TEXT ] singer_in_concert.Singer_ID=singer.Singer_ID
stadium :
Stadium_ID [ INT ] primary_key
Location [ TEXT ]
Name [ TEXT ]
Capacity [ INT ]
Highest [ INT ]
Lowest [ INT ]
Average [ INT ]
Please write me a SQL statement that answers the following question: What are the names, themes, and number of singers for every concert? Do not provide any commentary or explanation of what the code does, just the SQL statement ending in a semicolon."""
prompt_llama2 = system_prompt + instance_prompt + " [/INST] select"
prompt_codellama2 = instance_prompt + " select"