
注:本記事は(2022年6月14日)に公開された(Snowpark Python: Bringing Enterprise-Grade Python Innovation to the Data Cloud)を翻訳して公開したものです。
Snowpark for Pythonがパブリックプレビューになり、すべてのSnowflakeのお客様に利用いただけるようになりました。Snowflakeエンジンにネイティブに統合されているJavaやScalaなどの、広く利用可能なSnowpark言語と同様の使いやすさ、パフォーマンス、セキュリティ上のメリットを得られるようになります。
Snowpark Python APIとPython Scalarユーザー定義関数(UDF)に加えて、パブリックプレビューリリースの一部として、Python UDF Batch API(ベクトル化UDF)、テーブル関数(UDTF)ストアドプロシージャのサポートも開始します。これらの機能をAnacondaとの統合と併用することで、急成長するPythonコミュニティのデータサイエンティスト、データエンジニア、開発者たちは、柔軟なプログラミングコントラクトが可能になり、オープンソースのPythonパッケージに簡単アクセスして安全でスケーラブルなデータパイプラインと機械学習(ML)ワークフローをSnowpark内で直接構築できるようになります。
機能の概要
- Snowpark Python APIでの使い慣れた構文を使用したデータのクエリと処理能
Snowparkは、開発者が使用したい言語に深く統合されたDataFrameスタイルのプログラミングをもたらすための、新しい開発者エクスペリエンスです。
開発者はSnowpark Pythonクライアントをインストールして、お好みのIDEと開発ツールとともに使用して、DataFrameを使用したクエリを構築でき、SQL文字列を作成したり渡したりする必要はありません。
from snowflake.snowpark import Session
from snowflake.snowpark.functions import col
# fetch snowflake connection information
from config import connection_parameters
# build connection to Snowflake
session = Session.builder.configs(connection_parameters).create()
# use Snowpark API to aggregate book sales by year
booksales_df = session.table("sales")
booksales_by_year_df = booksales_df.groupBy(year("sold_time_stamp")).agg([(col("qty"),"count")]).sort("count", ascending=False)
booksales_by_year_df.show()内部的には、DataFrameオペレーションは透過的にSQLクエリに変換され、SQLクエリがプッシュダウンされ、既にご存じの高性能でスケーラブルなSnowflakeエンジンのメリットを享受します。また、APIはファーストクラスの言語構造を使用するため、開発環境からのタイプチェック、IntelliSense、エラーレポートのサポートもあります。パブリックプレビューの発表の一環として、Snowpark PythonクライアントAPIをオープンソース化しました。PythonコミュニティがAPIを拡張し、さらに便利なものへと進化させてくれることを楽しみにしています。詳細とコントリビューションの開始方法については、SnowflakeのGithubリポジトリをご確認ください。
2. Anaconda統合を介した人気のオープンソースパッケージへのシームレスなアクセス
Snowparkでは、DataFrameオペレーションを簡単に記述できるものの、これは単なるクエリの記述方法ではありません。カスタムのPythonロジックをUDFとして使用したり(後ほど説明)、Snowflakeにプリインストール人気のオープンソースパッケージを活用したりできます。
Pythonの強みはオープンソースパッケージの豊富なエコシステムにあるため、Snowpark for Pythonの一部として、Anaconda統合を介して、シームレスな、エンタープライズ級のオープンソースイノベーションをデータクラウドにもたらすことができて、非常に嬉しく思います。Anacondaの包括的なオープンソースパッケージとシームレスな依存関係管理により、Pythonベースのワークフローを高速化できます。
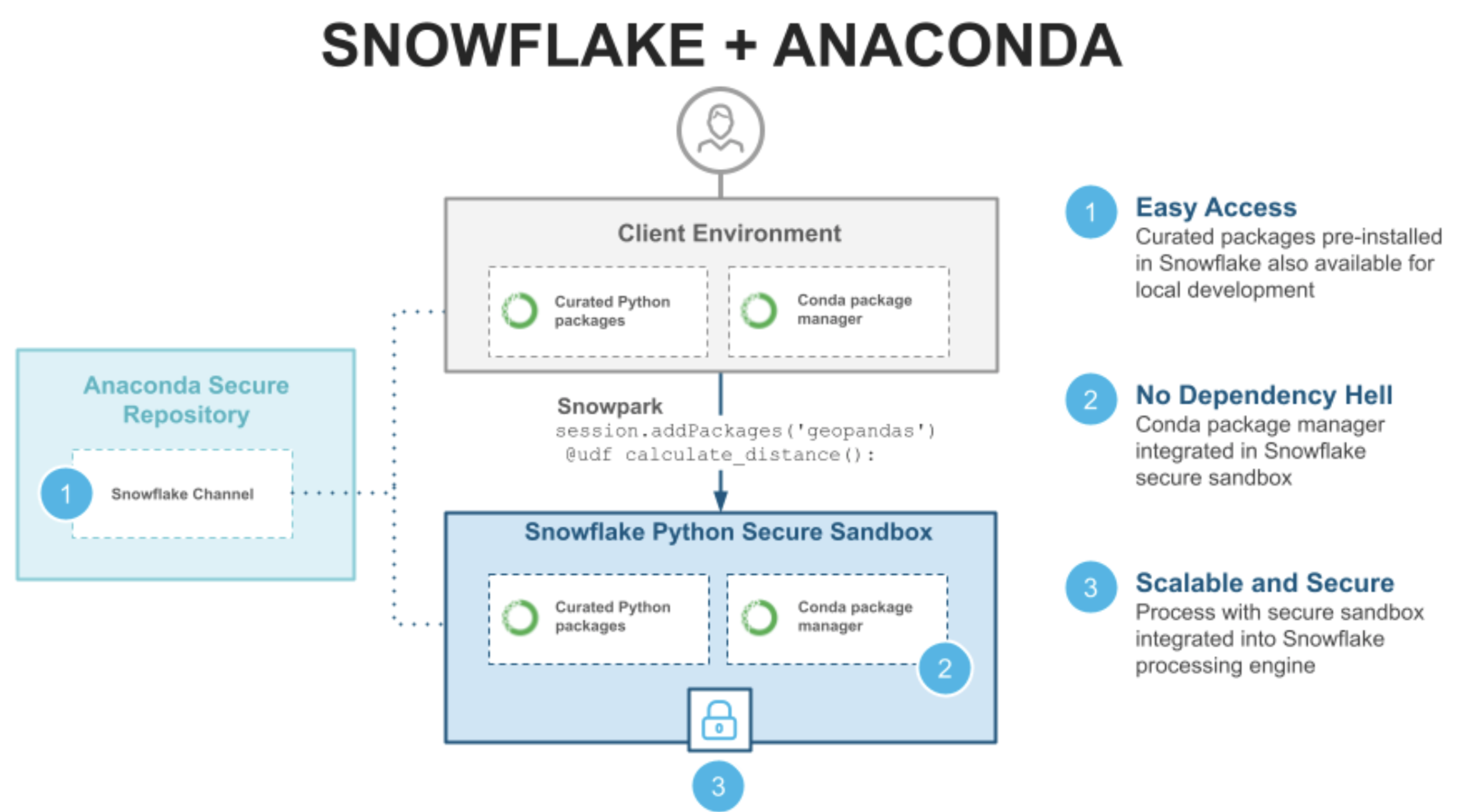
Anacondaが提供するサードパーティライブラリを活用してPythonワークフローを構築する方法について説明します。
- ローカル開発:Snowflake環境で事前構築されたものと同じライブラリとバージョンを、CondaリポジトリでホストされているSnowflakeチャネルでも利用できます。ローカルで開発する場合は、ローカルのAnacondaのインストールをSnowflakeチャネルに指定するだけで、Snowflakeサーバー側で使用可能なものと同じパッケージとバージョンを使用できます。
- パッケージ管理:Python関数がサードパーティライブラリに依存している場合は、UDF宣言時に必要なPythonパッケージを指定するだけで、Snowparkが自動的にそれをピックアップし、サーバー側の依存関係を解決し、統合されたCondaパッケージマネージャーを使用して該当するパッケージをPython UDF実行環境にインストールします。これで、異なるパッケージ間の依存関係の解決に時間を割く必要がなくなり、膨大な時間の浪費となりうる「依存関係地獄」をなくすことができます。
- 安全でスケーラブルな処理:最後に、UDFが実行されると、Snowparkコンピューティング全体に分散され、Snowpark処理エンジンが提供するスケーリングと安全な処理が実現します。
これらはすべて、Snowflakeの標準的な消費ベースの価格設定で利用でき、Snowflakeと一緒に使用すれば追加機能や製品の追加料金は発生しません。

「NumPyやSciPyといった人気の高いPythonライブラリがあれば、開発プロセスから管理レイヤーを1つ削除できます。また、統合されたCondaパッケージマネージャーがあることで、依存関係管理の心配もなくなりました。」
– HyperGroup、データエンジニアリング&機械学習責任者、Jim Gradwell
詳細については、HyperGroupからのブログ、「How HyperFinity Is Streamlining Its Serverless Architecture with Snowpark for Python(HyperFinityがSnowpark for Pythonを使用してサーバーレスアーキテクチャを効率化している方法)」をご覧ください。
3. Pythonユーザー定義関数を使用したカスタムコードの実行
お気づきのように、SnowparkにはカスタムPythonロジックをデータのすぐ横で実行できるSnowflakeにプッシュする能力があります。これは、Snowflakeのコンピューティングリソース内でホストされている安全なサンドボックス化されたPythonランタイムによって可能になります。関数がUDFであることを宣言し、コードが依存するサードパーティのパッケージを指定するだけ実行できます。

#Given geo-coordinates, UDF to calculate distance between warehouse and shipping locations
from snowflake.snowpark.functions import udf
import geopandas as gpd
from shapely.geometry import Point
@udf(packages=['geopandas'])
def calculate_distance(lat1: float, long1: float, lat2: float, long2: float)-> float:
points_df = gpd.GeoDataFrame({'geometry': [Point(long1, lat1), Point(long2, lat2)]}, crs='EPSG:4326').to_crs('EPSG:3310')
return points_df.distance(points_df.shift()).iloc[1]
# Call function on dataframe containing location coordinates
distance_df = loc_df.select(loc_df.sale_id, loc_df.warehouse_address, loc_df.shipping_address, \
calculate_distance(loc_df.warehouse_lat, loc_df.warehouse_lng, loc_df.shipping_lat, loc_df.shipping_lng) \
.alias('warehouse_to_shipping_distance'))SnowparkがカスタムコードをPythonバイトコードにシリアル化し、必要な依存関係を解決してインストールし、すべてのロジックをSnowflakeにプッシュダウンするため、コードはデータのすぐ隣にある安全なサンドボックスで実行されます。DataFrameオペレーションで通常のPython関数を使用する場合と同じように、UDFを呼び出して使用できます。
SQLとのPython統合
ここまで見てきたように、Snowpark APIにはDataFrameクエリとカスタムロジックの両方をSnowflakeにプッシュする性能があります。SQLユーザーがPython関数のメリットを最大限に活用できるようにする必要もあります。これらの機能を構築するには、基本的な操作が必要な場合に、コードを単純なインライン定義として記述し、SQLを使用してUDFをSnowflakeワークシートに直接登録します。
より複雑なユースケースの場合は、既存のツールセット(ソースコントロール、開発環境、デバッグツールなど)を最大限に活用して、ローカルで開発およびテストできます。その後、そのコードをSnowflakeに取り込みます。SQLへの取り込みは、コードをzipファイルとしてパッケージ化し、Snowflakeステージにロードして、Python関数として登録する時にインポートとして指定するだけで行えます。Python UDFが作成されると、SQLユーザーは他の関数と同じように、通常のクエリの一部としてロジックを使用できます。Python関数は他の関数が使用されるほとんどすべての場所で使用できるため、ストリームとタスクを使用してELT、ML、CI/CDワークフローを自動化することも可能になります。
他のUDFコントラクト
前述の例では、各行を個別に操作し、単一の結果を生成するスカラーUDFを使用しました。スカラー関数は簡単に記述してさまざまな問題に対処できますが、スカラーコントラクトが不足している場合は、追加のUDFコントラクトが役立つ場合があります。
Python UDF Batch APIを使用すると、入力行のバッチをPandas DataFrameとして受け取り、結果のバッチをPandas配列またはシリーズとして返すPython関数を定義できます。Scalar UDFを使用した行ごとの処理パターンと比較すると、Batch APIは、特にPythonコードが行のバッチで効率的に動作する場合に、パフォーマンスが向上する可能性が高まります。パフォーマンスの向上に加えて、Batch APIを使用するとPandas DataFramesまたはPandas配列で動作するライブラリを呼び出す際に必要な変換ロジックが少なくなります。例えば、(ステージから事前トレーニングされたXGBoostモデルをロードする)Batch APIを使用して定義された以下の推論UDFは、数百万行の大きなテーブルをスコアリングする時に大幅なパフォーマンスの向上をもたらします。
–- Using SQL to register a UDF to predict customer propensity score based on historical sales data
create or replace function score_vec(category string, region_code string)
returns double
language python
runtime_version = '3.8'
imports=('@ml_demo/model/model_0_0_0.csv')
packages = ('numpy','pandas','xgboost','scikit-learn')
handler = 'score'
as $$
import pandas as pd
import xgboost as xgb
import sys, pickle, codecs
from _snowflake import vectorized
import_dir = sys._xoptions["snowflake_import_directory"]
with open(import_dir + 'model_0_0_0.csv', 'r') as file:
file_contents = file.read()
pickle_jar = pickle.loads(codecs.decode(file_contents.encode(), "base64"))
bst = pickle_jar[0]
ohe = pickle_jar[1]
bst.set_param('nthread', 1)
@vectorized(input=pd.DataFrame)
def score(features):
dscore = xgb.DMatrix(ohe.transform(features).toarray())
return bst.predict(dscore)
$$;
-- Scoring 20M rows using the Batch API takes about ~8 sec vs ~5 mins for a Scalar UDF on an XL warehouse
select score_vec(category, region_code) from wholesale_customer_salesPythonテーブル関数 を使用すると、入力行ごとに複数の行を返したり、行のグループに対して単一の結果を返したり、スカラーまたはバッチAPIでは実行できない複数の行の状態を維持したりできます。以下は、UDTFを使用し、spaCyライブラリを利用して名前付きエンティティの認識を行う方法の簡単な例です。UDTFは文字列を入力として受け取り、認識されたエンティティとそれに対応するラベルのテーブルを返します。
–-UDTF that uses Spacy for named entity recognition
create or replace function entities(input string)
returns table(entity string, label string)
language python
runtime_version = 3.8
handler = 'Entities'
packages = ('spacy==2.3.5')
imports = ('@spacy_stage/spacy_en_core_web_sm.zip')
as $$
import zipfile
import spacy
import os
import sys
import_dir = sys._xoptions["snowflake_import_directory"]
extracted = '/tmp/en_core_web_sm' + str(os.getpid())
with zipfile.ZipFile(import_dir + "spacy_en_core_web_sm.zip", 'r') as zip_ref:
zip_ref.extractall(extracted)
nlp = spacy.load(extracted + "/en_core_web_sm/en_core_web_sm-2.3.1")
class Entities:
def process(self, input):
doc = nlp(input)
for ent in doc.ents:
yield (ent.text, ent.label_)
$$;
select * from table(entities('Hi this is Ryan from Colorado, calling about my missing book from order no 2689.'));
「お客様の環境を保護するには、継続的なイノベーションが必要です。Sophosのサイバーセキュリティソリューションには、多数の機械学習モデルが組み込まれており、常に追加のモデルを展開しています。Snowpark for Pythonがあれば、機械学習モデルの開発と運用を、初期パイプラインから本番環境でのモデル推論まで劇的に合理化、拡張できます。」
— Sophos、AI部門シニアディレクター、Konstantin Berlin
4. ストアドプロシージャを使用してSnowflakeでコードを直接ホストして操作可能にする
前の例にあったように、Snowpark Python APIを使用すれば、DataFrameなどの強力な抽象化を使用してデータパイプラインを構築、実行するクライアント側プログラムを作成できます。ただし、パイプラインを構築してテストしたら、次のステップはそれを運用可能にすることです。そのためには、そのクライアントプログラムをホストしてスケジュールするための家を見つける必要があります。Snowpark Pythonストアドプロシージャでは、まさにそれを実行できます。Snowflake仮想ウェアハウスをコンピューティングフレームワークとして使用して、Snowflake内で直接Pythonパイプラインをホストでき、スケジューリング用タスクなどのSnowflake機能と統合できます。これにより、関与するシステム数を減らし、すべてをSnowflake内に含めることで全工程を簡素化できます。
中でも注目すべきは、Snowparkストアドプロシージャは驚くほどパワフルな上に、非常に使いやすいという点です。以下は、営業ボーナスを毎日計算して適用するSnowpark Pythonパイプラインを操作する際の簡単な例です。
-- Create python stored procedure to host and run the snowpark pipeline to calculate and apply bonuses
create or replace procedure apply_bonuses(sales_table string, bonus_table string)
returns string
language python
runtime_version = '3.8'
packages = ('snowflake-snowpark-python')
handler = 'apply_bonuses'
AS
$$
from snowflake.snowpark.functions import udf, col
from snowflake.snowpark.types import *
def apply_bonuses(session, sales_table, bonus_table):
session.table(sales_table).select(col("rep_id"), col("sales_amount")*0.1).write.save_as_table(bonus_table)
return "SUCCESS"
$$;
--Call stored procedure to apply bonuses
call apply_bonuses('wholesale_sales','bonuses');
– Query bonuses table to see newly applied bonuses
select * from bonuses;
– Create a task to run the pipeline on a daily basis
create or replace task bonus_task
warehouse = 'xs'
schedule = '1440 minuite'
as
call apply_bonuses('wholesale_sales','bonuses');
「Snowpark for Pythonのおかげで、AllegisはMLベースソリューションの市場投入までの時間を短縮でき、さらにアーキテクチャの合理化にも役立っています。ストアドプロシージャとプリインストールされたパッケージを使用することで、データサイエンティストはよりデータに近いPythonコードを実行し、Snowflakeの伸縮性のある高性能エンジンを活用できます。」
— Allegis、AI&MDMドメインアーキテクト、Joe Nolte
Snowpark Acceleratedプログラム
さらに嬉しいことに、パートナーエコシステム内で、Snowpark for Pythonを活用した、お客様に提供するエクスペリエンスを強化するための統合の構築への関心も高まっています。
今回の公開の時点で、Snowpark Acceleratedプログラムの多数のパートナーが既に製品統合と専門技術を構築し、データクラウドのPythonの利便性をお客様にまで広げています。

今後の展開
サミットでのオープニング基調演説では、ここで説明した内容以外にもMLトレーニング用のより大きなメモリウェアハウス、SnowflakeでのネイティブStreamlit統合、データクラウドでのアプリケーションの構築とデプロイなど、Snowpark for Pythonの他の多数の機能についても発表しました。詳細はこちらでご覧いただけます。
Snowparkでより迅速にスマートに作業
Snowparkは、Snowflakeのプラットフォームのシンプルさ、拡張性、セキュリティを維持しながら、データを使って簡単にインパクトの強い成果を簡単に出せるようにすることを目的としています。Snowpark for Pythonを使ってお客様が何を作り出すの、楽しみにしています。
始める際は、以下のリソースをご確認ください。
And if you want to see Snowpark for Python in action, you can sign up for Snowpark Day.
Happy hacking!
Snowparkの最新情報をチェック
見通しに関する記述
見通しに関する記述も、将来本記事には、明示または黙示を問わず、(i)Snowflakeの事業戦略、(ii)開発中や一般公開されていないものも含めたSnowflakeが提供する製品、サービス、テクノロジー、(iii)市場の成長、トレンド、競争に関する考慮事項、(iv)サードパーティプラットフォームと連携したまた同プラットフォーム上でのSnowflake製品の統合、相互運用性、および可用性、についての言及など、将来の見通しに関する記述が含まれています。これらの将来の見通しに関する記述は、さまざまなリスク、不確実性、前提に左右されます。これには、Snowflakeが証券取引委員会に提出するForm 10-Q(四半期レポート)およびForm 10-K(年次報告書)内の「リスク要因」などのセグメントに記載されているリスク、不確実性、前提が含まれます。これらのリスク、不確実性、前提を考慮すると、将来の見通しに関する記述において予想または暗示されている結果と比較して、実際には大きく異なる結果や反対の結果に至る可能性があります。そのため、将来の見通しに関するいかなる記述も、未来の出来事についての予測として利用するべきではありません。
© 2022 Snowflake Inc. All rights reserved. Snowflake、Snowflakeのロゴ、およびその他ここに記載されるすべてのSnowflake製品、機能、サービス名は、米国およびその他の国々におけるSnowflake Inc.の登録商標または商標です。本書で言及または使用されているその他のブランド名やロゴはすべて識別のみを目的としており、それぞれの保有者の商標である可能性があります。Snowflakeとかかる保有者との間には、提携、スポンサー、または推奨関係があるとは限りません。