
As of December, customers got a whole new level of insight into Snowflake query performance and query execution statistics when Snowflake announced the public preview of the new get_query_operator_stats function, opening up programmatic access to Snowflake query profiles and providing customers a whole new level of insight into Snowflake query performance and query execution statistics.
Snowflake maintains its commitment to customers and ongoing platform improvements. Along with our Snowflake technology partners (with similar examples of innovation early last year), we will demonstrate how they use the new get_query_operator_stats function within their respective products and further empower all of our customers for ongoing success with Snowflake.
Faster time to insights when analyzing Snowflake queries
Every Snowflake developer and administrator likely has a basic level of familiarity with our Snowsight UI, and how it can be used to monitor activity within your Snowflake account, including Query History. These same individuals have also likely spent time analyzing queries using Query Profile. While incredibly powerful, there can also be a steep learning curve here, and the shape, complexity, and number of steps for any particular query can vary dramatically. Many users have found our instructor-led training courses and Snowflake Summit breakout sessions (especially the “Operating and Optimizing Snowflake” learning track) provide the resources they need to be successful.
We continue to hear from many customers that they want even more. And even though our ACCOUNT_USAGE.QUERY_HISTORY view provides several (but not all) of these same statistics, it never provided the same level of detail for individual queries that was available in Query Profile—until now! For the first time ever, customers are able to use the new get_query_operator_stats function to analyze Snowflake Query Profiles in a programmatic fashion. For years, our documentation has helped customers identify and better understand some of the common query problems identified by Query Profile, including:
- Exploding joins
- UNION without ALL
- Queries too large to fit in memory (most often evidenced by “spilling”)
- Inefficient pruning (most often evidenced by large table scans)
Historically, most of these common problems could only be diagnosed by viewing individual query profiles within the Snowflake web UI, one at a time. And even then, these problems have not always been easily noticeable to the untrained eye.
Snowflake technology partner solution accelerators for programmatic query profiling
We are excited to highlight several Snowflake technology partners who have integrated this new Snowflake feature into their products, either as an add-on to previously existing Snowflake accelerators, or as entirely new product functionality. Some of these partner solutions build upon previously mentioned approaches to analyze queries in bulk. All of these solutions offer new, easy-to-use approaches for viewing individual query statistics, quickly highlighting any of the common query problems that may exist. Several also offer helpful tips to improve performance for the individual query being analyzed, whether that is an adjustment to the SQL itself (for example, adding or correcting a JOIN operator or adding filters to reduce the size of your data set); re-examining a table’s structure (for example, cluster keys or sort order); increasing the size of the virtual warehouse; or utilizing newer Snowflake features such as Search Optimization or the Query Acceleration Service (QAS). The basic approach for all of these partner solutions involves first querying SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY, joined to SNOWFLAKE.ACCOUNT_USAGE.SESSIONS to include the different client tool names that may be executing queries on Snowflake. For example:
SELECT (columns_of_interest),
PARSE_JSON(s.CLIENT_ENVIRONMENT):APPLICATION::string as APPLICATION_NAME
FROM SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY q
INNER JOIN SNOWFLAKE.ACCOUNT_USAGE.SESSIONS s
ON q.SESSION_ID = s.SESSION_ID
LEFT OUTER JOIN SNOWFLAKE.ACCOUNT_USAGE.QUERY_ACCELERATION_ELIGIBLE qas
ON q.QUERY_ID = qas.QUERY_ID
WHERE q.END_TIME >= DATE_TRUNC('week', CURRENT_DATE) - INTERVAL '14 DAY'
/* additional optional parameters */
AND q.QUERY_TYPE = 'SELECT'
AND q.WAREHOUSE_NAME IS NOT NULL
AND q.EXECUTION_STATUS = 'SUCCESS' Next, when executing the function to analyze an individual query, it may be helpful to run it within a common table expression (CTE) first, checking for certain conditions and other problems right within the SQL. Note that the exact SQL commands within these queries are only suggestions, and will be very similar to the approaches used within the partner solution accelerators, Readers should feel free to experiment and ultimately use what works best for them.
with query_stats as(
select
QUERY_ID,
STEP_ID,
OPERATOR_ID,
PARENT_OPERATOR_ID,
OPERATOR_TYPE,
OPERATOR_STATISTICS,
EXECUTION_TIME_BREAKDOWN,
OPERATOR_ATTRIBUTES,
EXECUTION_TIME_BREAKDOWN:overall_percentage::float as OPERATOR_EXECUTION_TIME,
OPERATOR_STATISTICS:output_rows output_rows,
OPERATOR_STATISTICS:input_rows input_rows,
CASE WHEN operator_statistics:input_rows>0 THEN operator_statistics:output_rows / operator_statistics:input_rows ELSE 0 END as row_multiple,
/* look for queries too large to fit into memory */
OPERATOR_STATISTICS:spilling:bytes_spilled_local_storage bytes_spilled_local,
OPERATOR_STATISTICS:spilling:bytes_spilled_remote_storage bytes_spilled_remote,
operator_statistics:io:percentage_scanned_from_cache::float percentage_scanned_from_cache,
operator_attributes:table_name::string tablename,
OPERATOR_STATISTICS:pruning:partitions_scanned partitions_scanned,
OPERATOR_STATISTICS:pruning:partitions_total partitions_total,
OPERATOR_STATISTICS:pruning:partitions_scanned/OPERATOR_STATISTICS:pruning:partitions_total::float as partition_scan_ratio,
/* COMMON QUERY PROBLEMS IDENTIFIED BY QUERY PROFILE */
/* 1) EXPLODING JOIN */
CASE WHEN row_multiple > 1 THEN 1 ELSE 0 END AS EXPLODING_JOIN,
/* 2) "UNION WITHOUT ALL" */
CASE WHEN OPERATOR_TYPE = 'UnionAll' and lag(OPERATOR_TYPE) over (ORDER BY OPERATOR_ID) = 'Aggregate' THEN 1 ELSE 0 END AS UNION_WITHOUT_ALL,
/* 3) Queries Too Large to Fit in Memory */
CASE WHEN bytes_spilled_local>0 OR bytes_spilled_remote>0 THEN 1 ELSE 0 END AS QUERIES_TOO_LARGE_MEMORY,
/* 4) Inefficient Pruning (numbers can be changed to fit your use case) */
CASE WHEN partition_scan_ratio >= .8 AND partitions_total >= 20000 THEN 1 ELSE 0 END AS INEFFICIENT_PRUNING_FLAG
from table(get_query_operator_stats('your_query_id'))
ORDER BY STEP_ID,OPERATOR_ID
)
SELECT
QUERY_ID,
SYSTEM$ESTIMATE_QUERY_ACCELERATION('your_query_id'),
STEP_ID,
OPERATOR_ID,
PARENT_OPERATOR_ID,
OPERATOR_TYPE,
OPERATOR_STATISTICS,
EXECUTION_TIME_BREAKDOWN,
OPERATOR_ATTRIBUTES,
OPERATOR_EXECUTION_TIME,
OUTPUT_ROWS,
INPUT_ROWS,
ROW_MULTIPLE,
BYTES_SPILLED_LOCAL,
BYTES_SPILLED_REMOTE,
PERCENTAGE_SCANNED_FROM_CACHE,
TABLENAME,
PARTITIONS_SCANNED,
PARTITIONS_TOTAL,
PARTITION_SCAN_RATIO,
EXPLODING_JOIN,
UNION_WITHOUT_ALL,
QUERIES_TOO_LARGE_MEMORY,
INEFFICIENT_PRUNING_FLAG
FROM query_stats;
Learn more about each of the following partner solutions by clicking on the links below, and try them today.
Note: listed partners are sorted alphabetically.

Acceldata’s data observability platform empowers data teams with deep insights into compute, spend, data reliability, pipelines, and users.
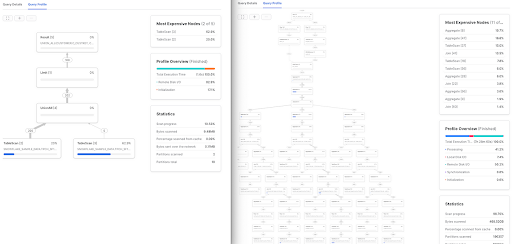
By leveraging Snowflake’s comprehensive metadata on query history and operator statistics, alongside Acceldata’s advanced query fingerprinting techniques, users can attain a deeper comprehension of their workloads and pinpoint the most resource-intensive or unoptimized queries. This functionality provides detailed insights into statistics such as elapsed time, scanned partitions, cache utilization, and more for grouped queries. Query grouping also streamlines the process of diagnosing performance issues by enabling users to compare selected executions of grouped queries, complete with all relevant metrics. Users can detect, understand, optimize, and enhance the performance of their query workloads, ultimately improving the reliability and performance of their Snowflake Data Cloud.
Native to Snowflake, Astrato is a cloud BI solution that enables all users to create custom data applications that actively drive better business decisions. The example below shows how a user can analyze the metadata of Snowflake’s Query History by aggregation and drill down. The user can also harness Snowflake’s powerful new function to collect operator statistics to identify and mark the four common types of query inefficiency: Cartesian, union, memory, and pruning. Although Astrato’s generated SQL queries meet the above efficiency criteria as built-in, users can now find inefficient or expensive query requests, such as from custom client’s SQL, with a few interactions.
In addition, we added more details around the query execution and indicators for common types of inefficiency to Astrato’s query insights panel to help users to save time and money with the most efficient queries possible.


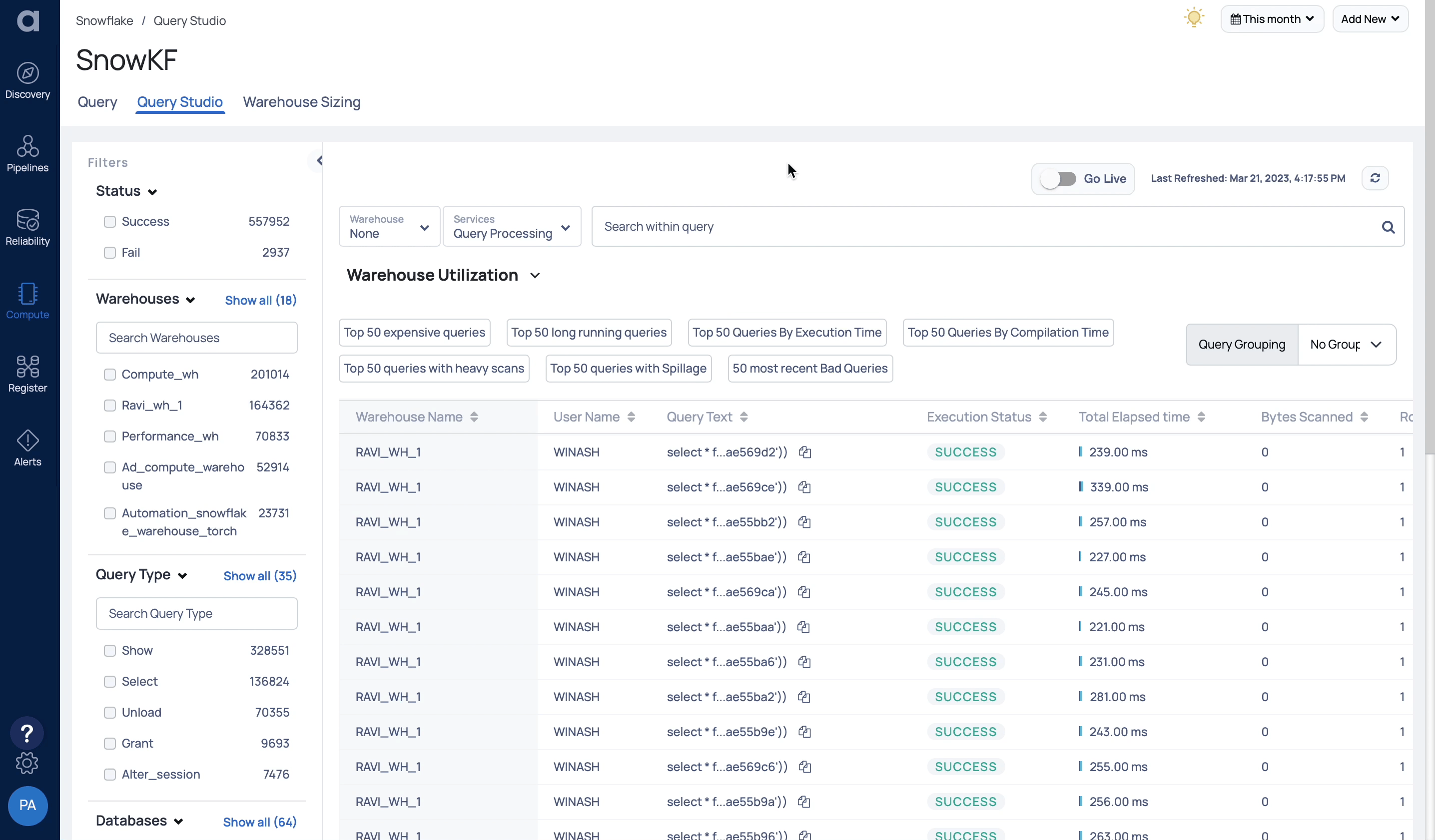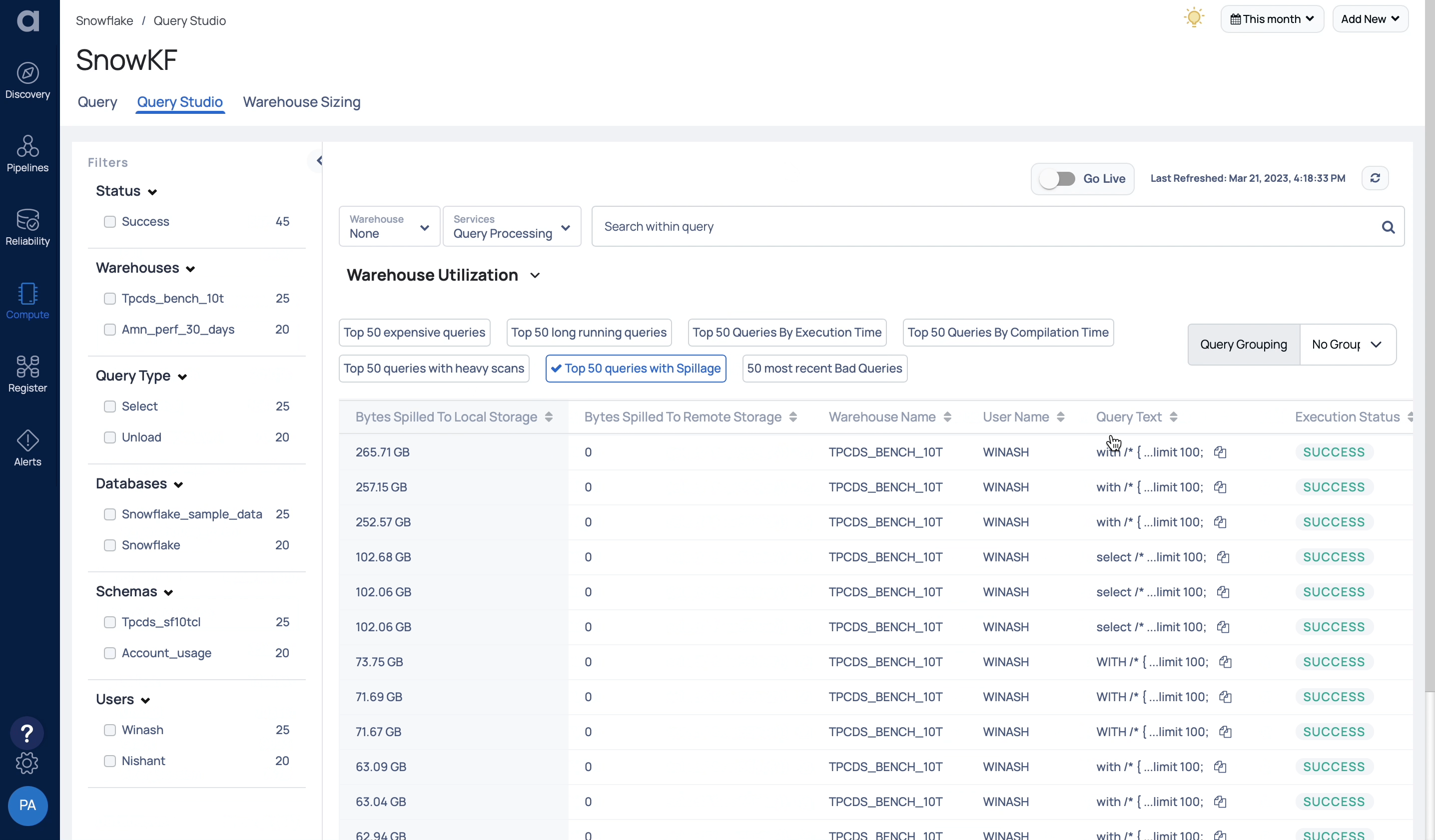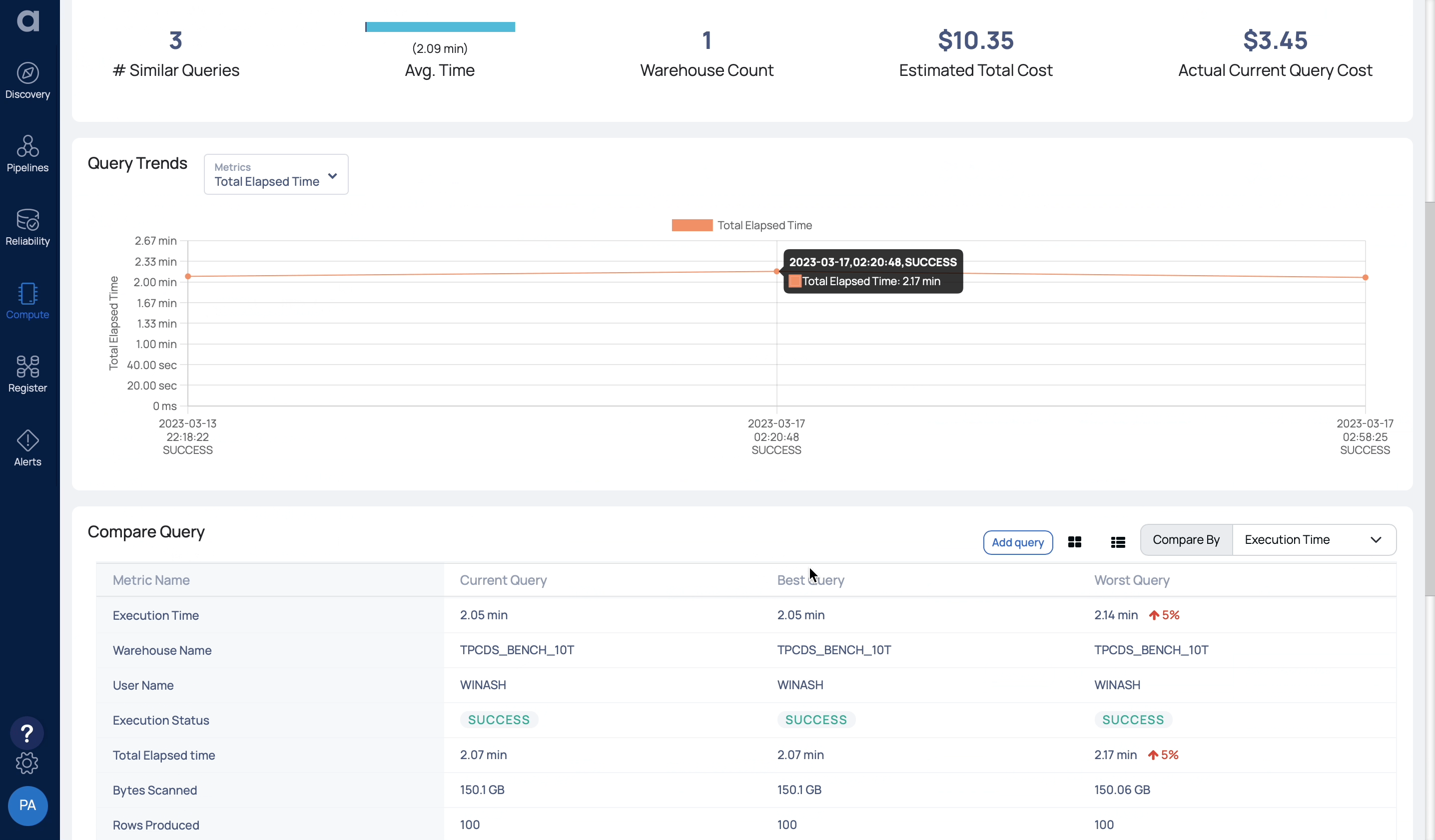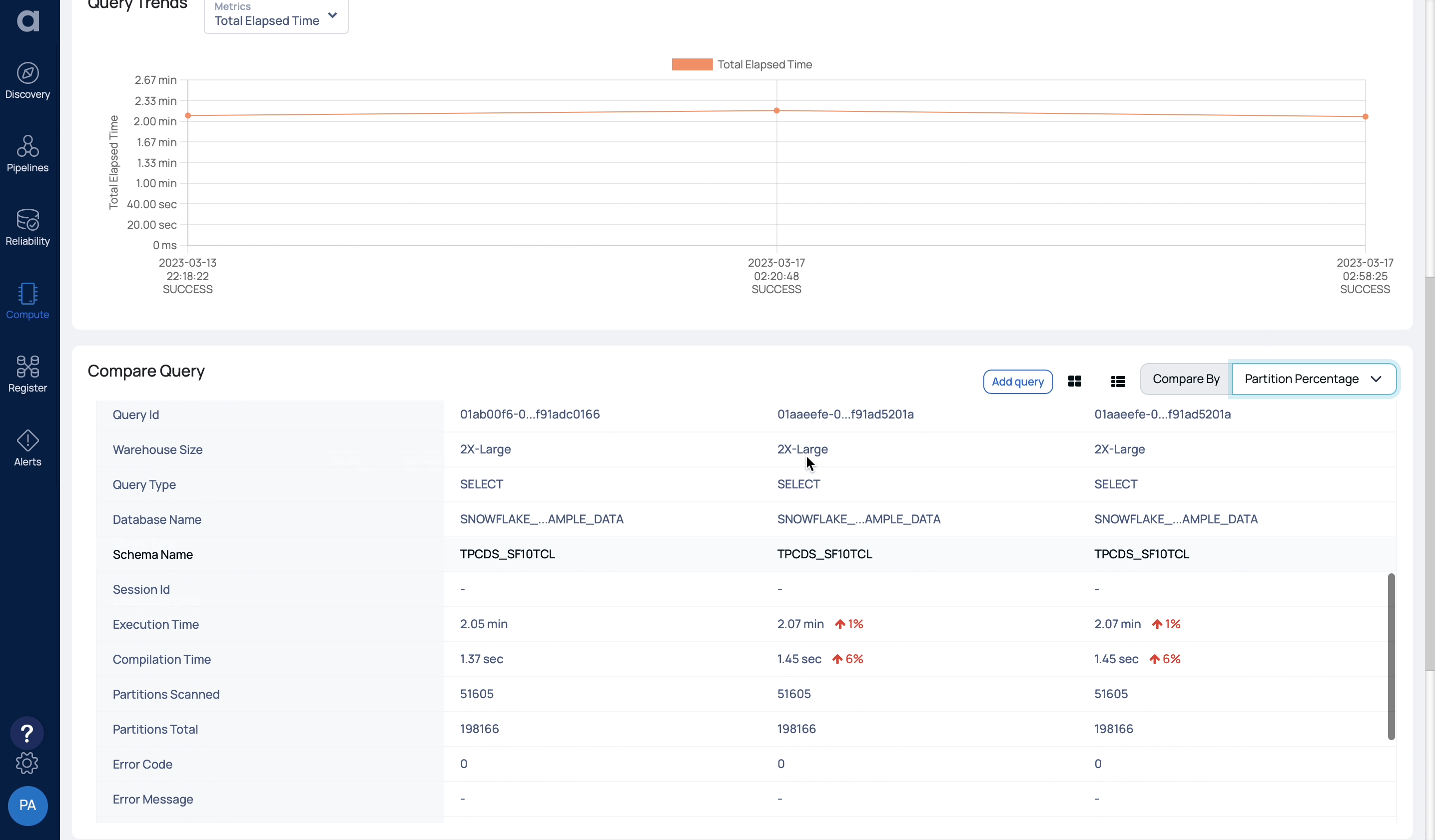
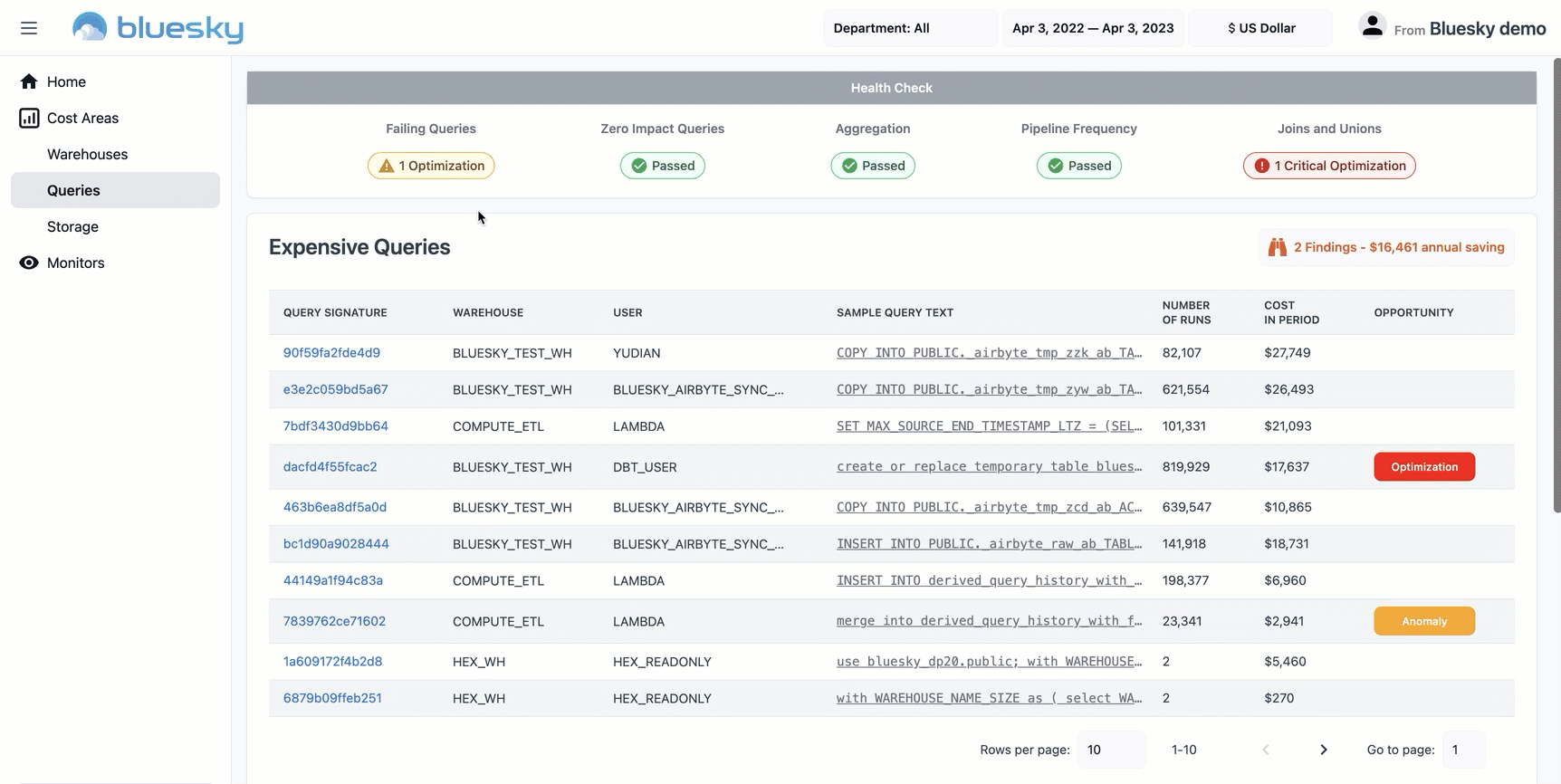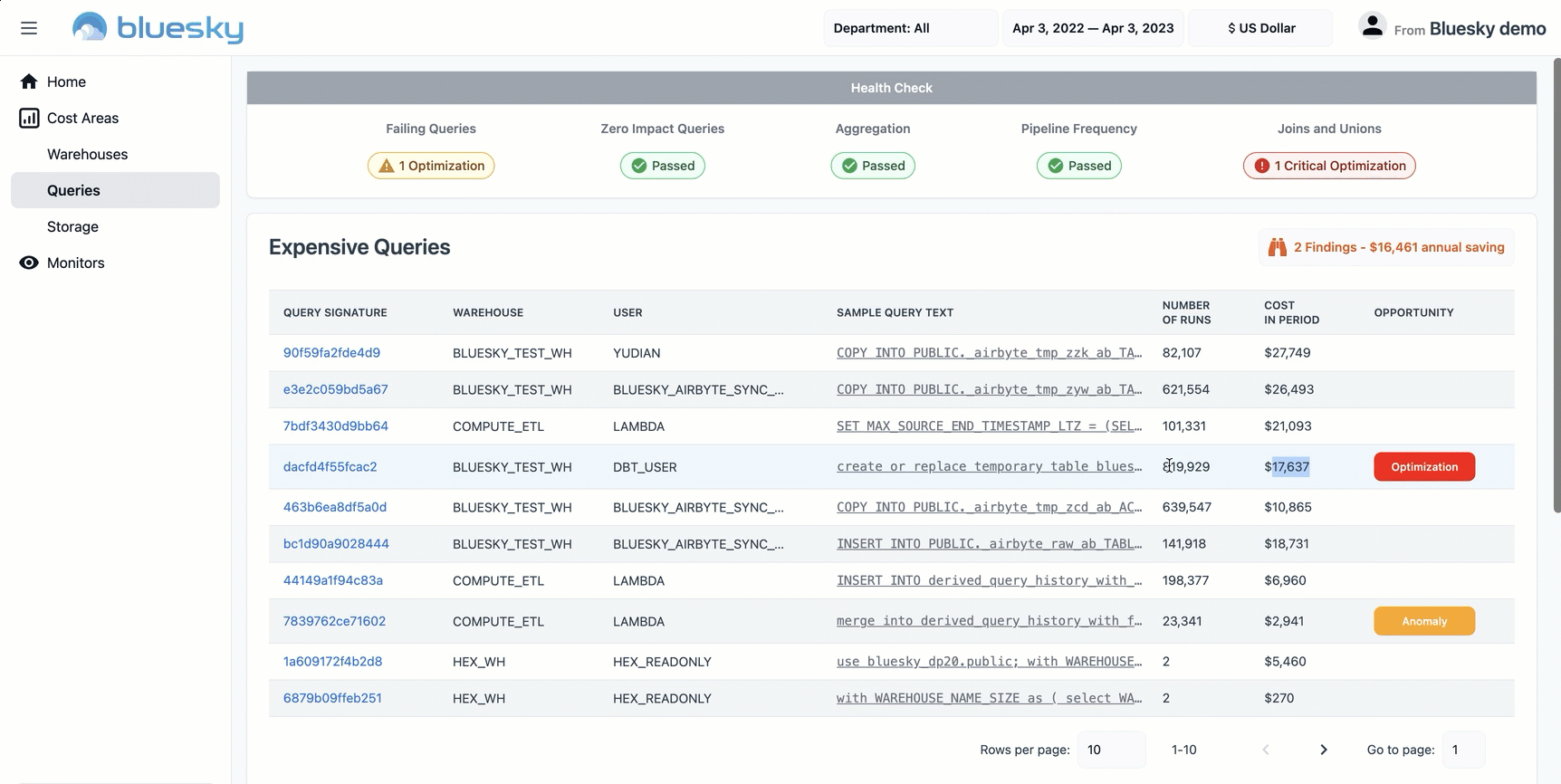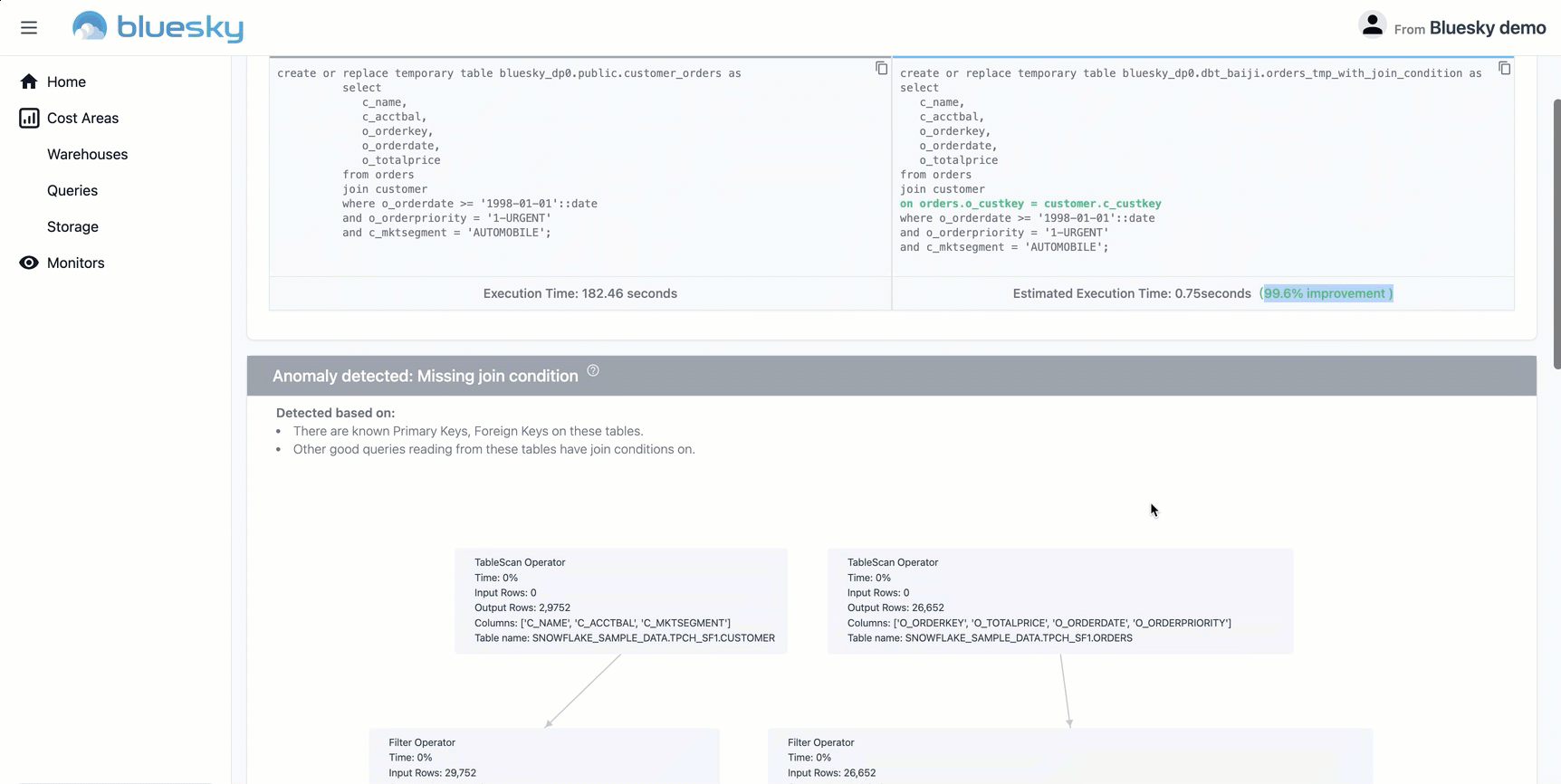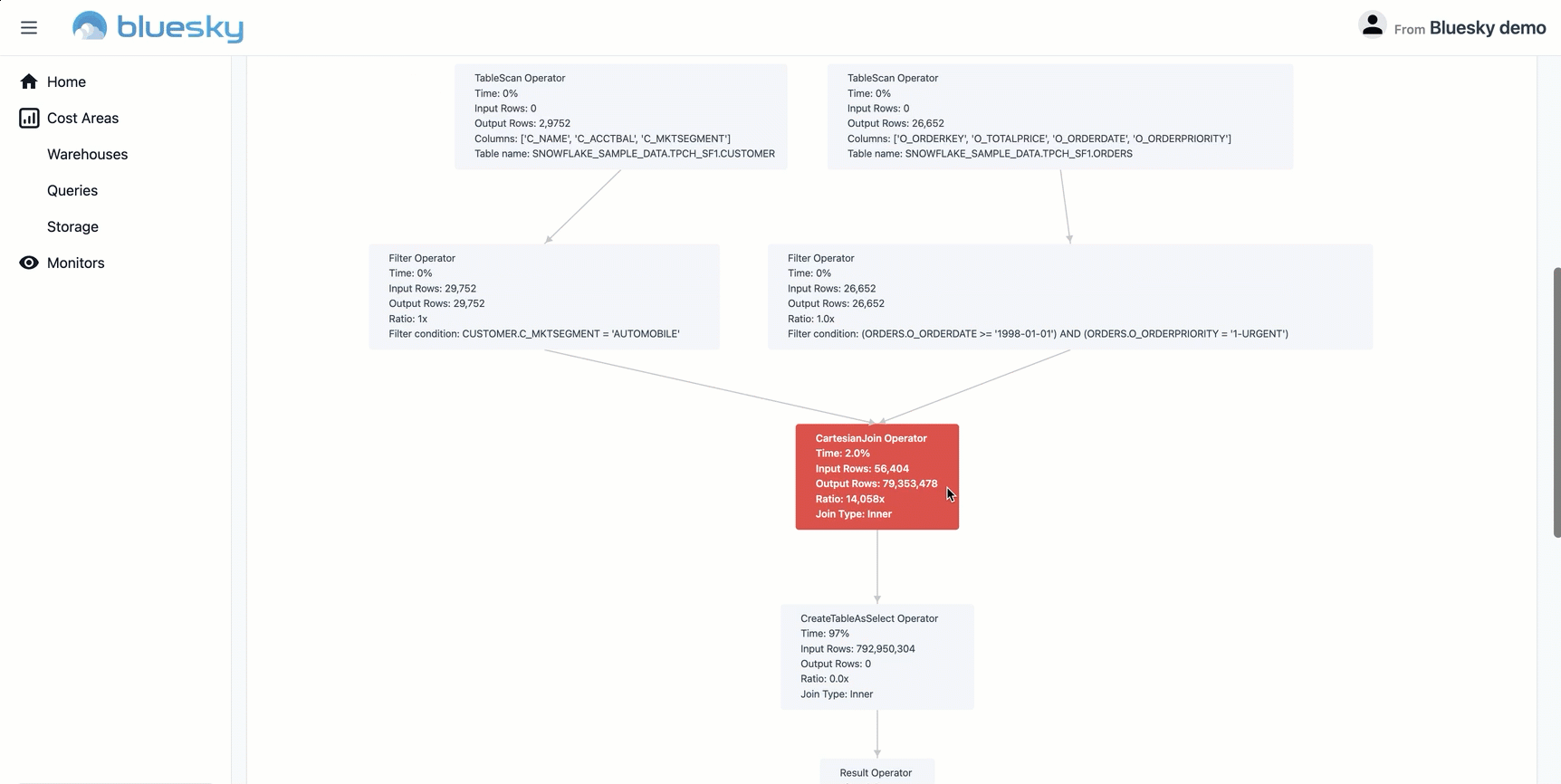
Bluesky is your co-pilot for Snowflake workload optimization, providing performance and cost governance features for continuous spend monitoring and optimization. Bluesky is unique in the market as it provides deep technical insights into the performance and cost aspects of query workloads (including query profiles and lineage), and suggests optimization parameters for warehouse and storage settings.
With Bluesky, companies can identify the most resource-intensive queries and optimize accordingly. Whether it’s a straightforward warehouse misconfiguration, or an advanced recommendation on clustering keys, Bluesky focuses on prioritizing insights and lending practical advice.
The following example shows a query that is missing a join key, and therefore produces a Cartesian product that has an outsized output in terms of records as well as results in a high cost.
Laying out the original and proposed query side by side—thereby providing a graphical view of the execution path with actual figures and a human readable explanation—is a straightforward way to understand the source of inefficiency and revise the query for better data quality, performance, and lower cost. You can learn more about Bluesky’s solution here.

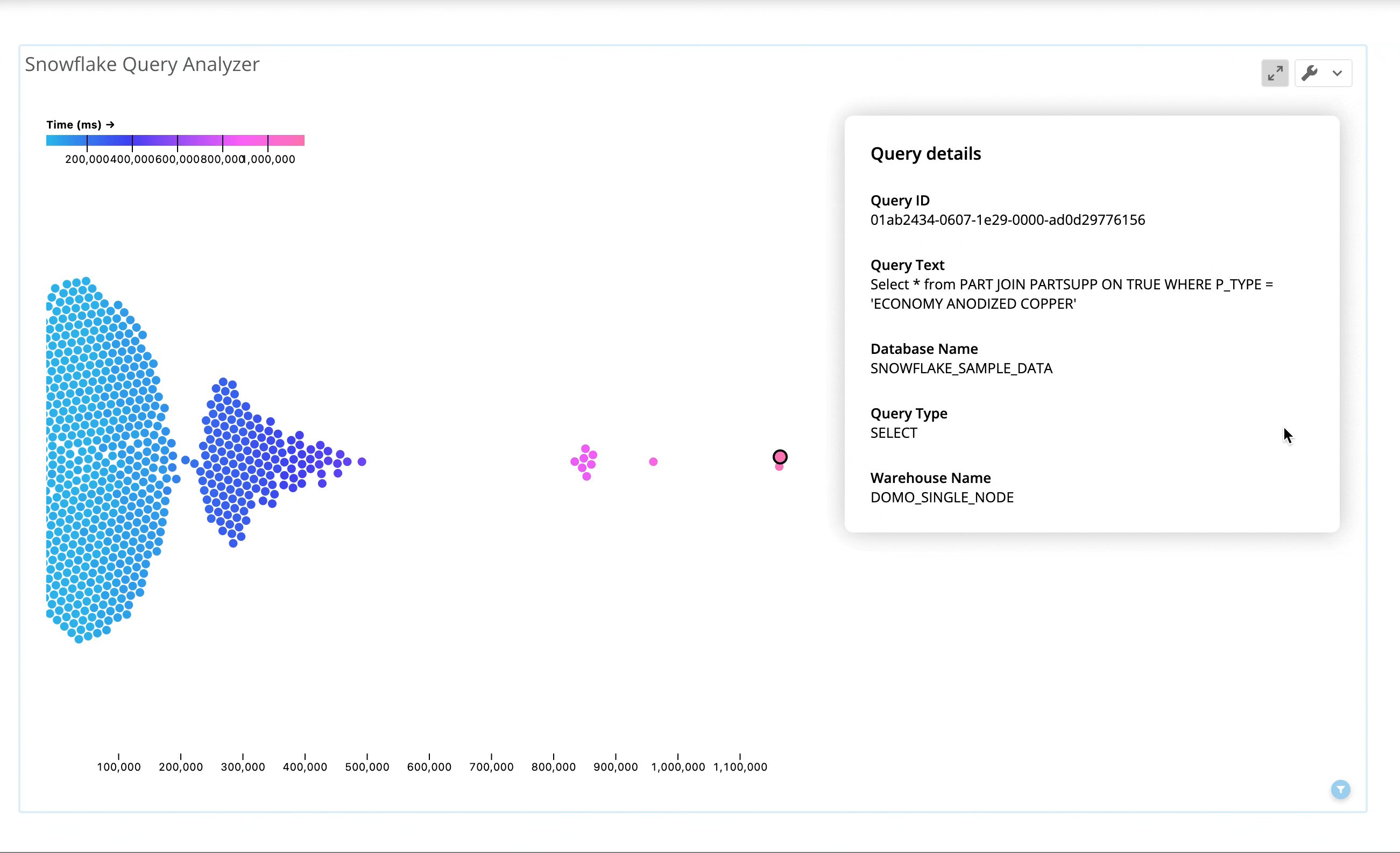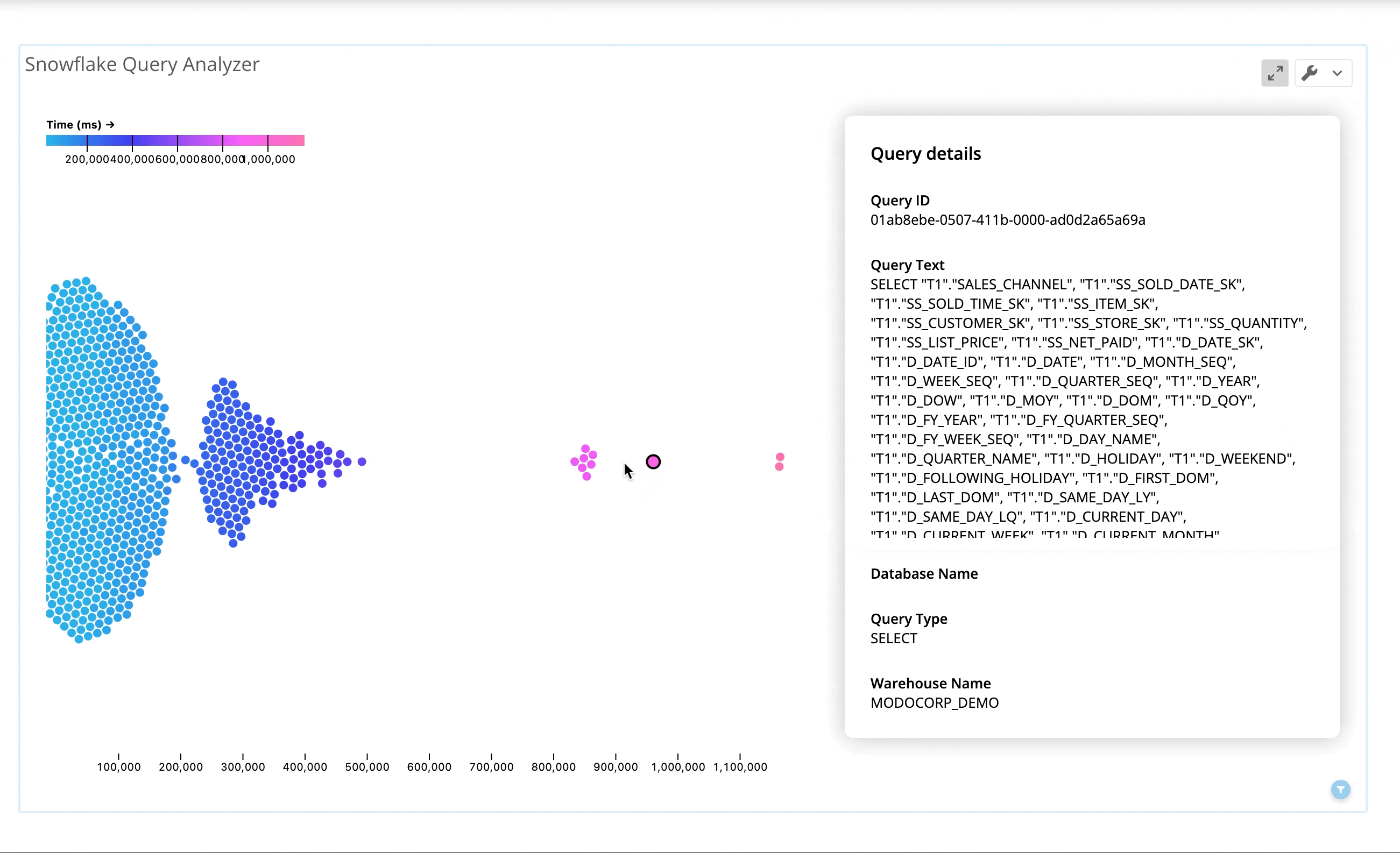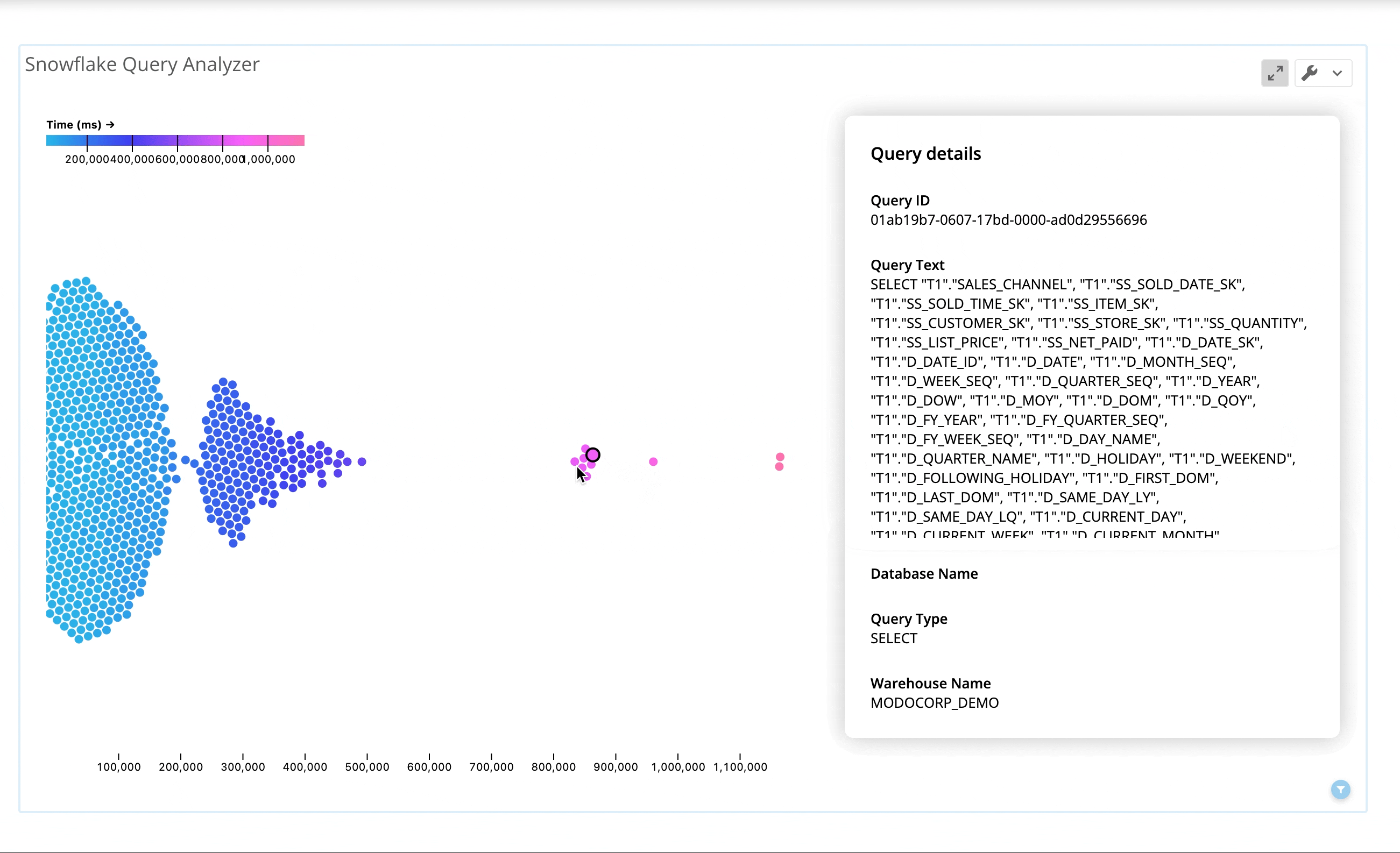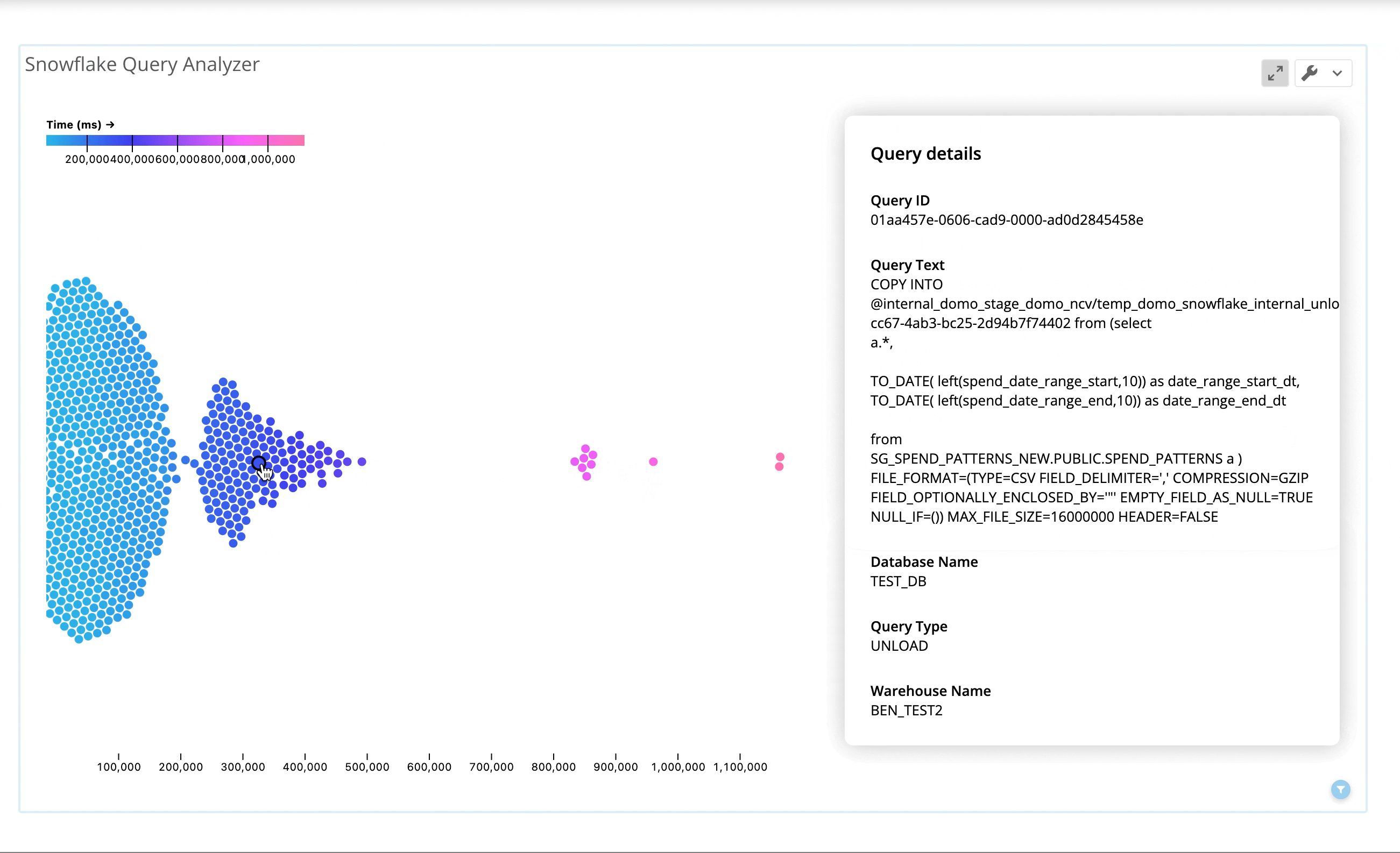
Domo is a data experience platform providing rich self-serve analytics capabilities that natively integrate with Snowflake. Domo’s Snowflake Query Investigator app helps identify potential “problem queries” through visualizations that summarize query volume and history, and rank how queries have performed in relation to each other and over time.
Users can drill into a comprehensive view of query operator stats data to quickly investigate potential issues, and can customize logic from within Domo to apply different tolerance thresholds for management purposes. For example, a category of “inefficient pruning” can be created in the data, defined as queries where more than 50% of partitions were scanned and more than 50,000 partitions exist. This custom logic can be altered by those with editing rights, can power visualizations of the offending queries, and can trigger automated Domo alerts via email or SMS to the users responsible for Snowflake administration and optimization.
Qlik provides a complimentary Snowflake Utilization solution to help organizations keep track of their Snowflake usage and spending. Even if you have multiple tenants, Qlik’s solution fully supports as many tenants as you need to track. Recently, the company made updates to this solution to take advantage of the new function in Snowflake called “get_query_operator_stats.”
With this updated Qlik solution for Snowflake, users can easily identify and select a query of interest and get all the associated execution statistics live in a visually presented “flow.” The solution can represent each operation type with an image icon, and it color-codes any operation that needs attention. If the query involves an exploding join, UNION without ALL, inefficient pruning, or causes disk spillage, the solution quickly and clearly presents that information and provides a direct link to Snowflake documentation for further information.
In addition to being partners, Qlik is a Snowflake customer and utilizes this Snowflake Utilization solution internally to track and manage usage on all of its Snowflake tenants. The Snowflake Utilization solution is available for free, and Qlik solution architects are able to help joint customers get it configured and running.
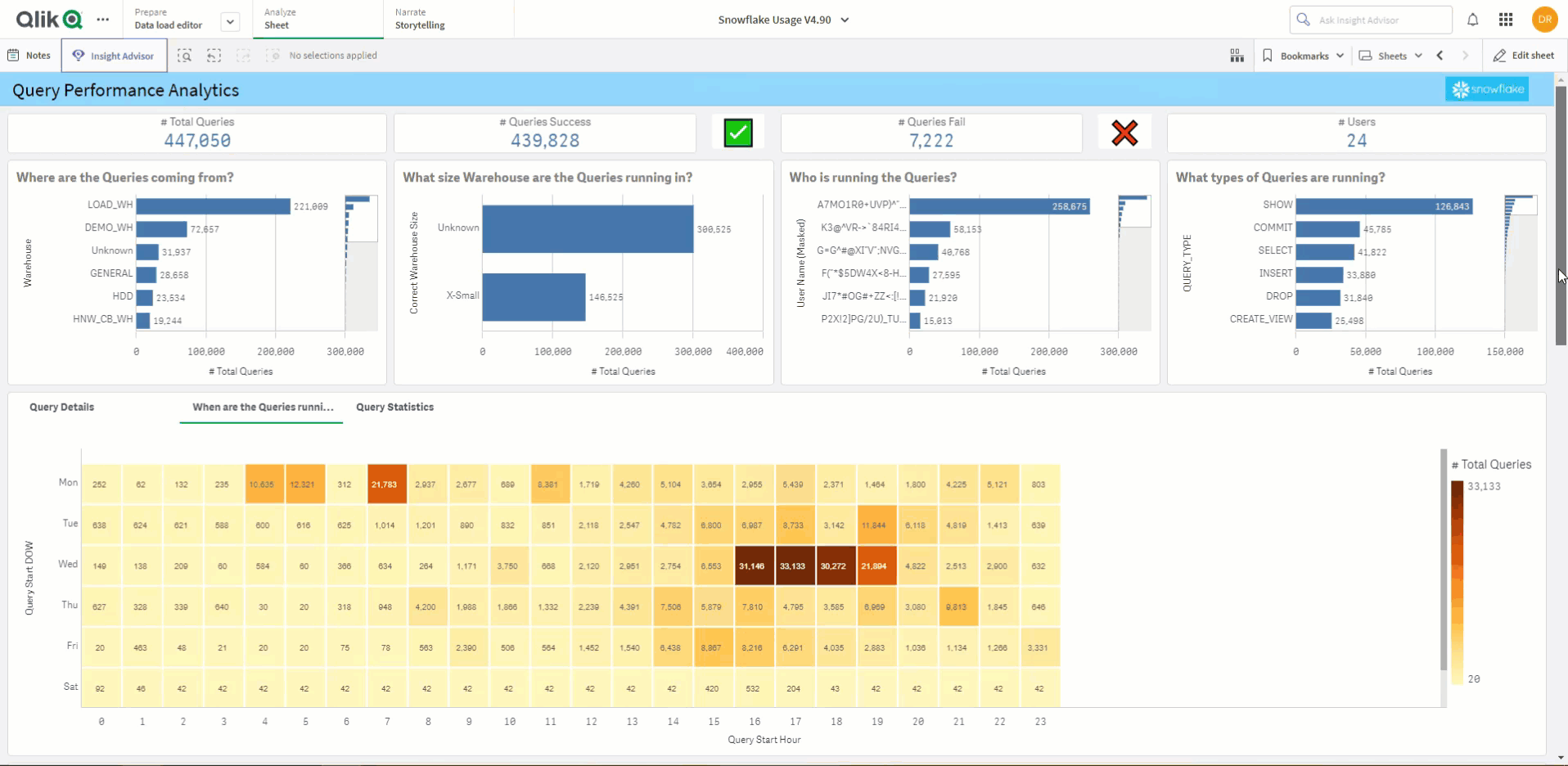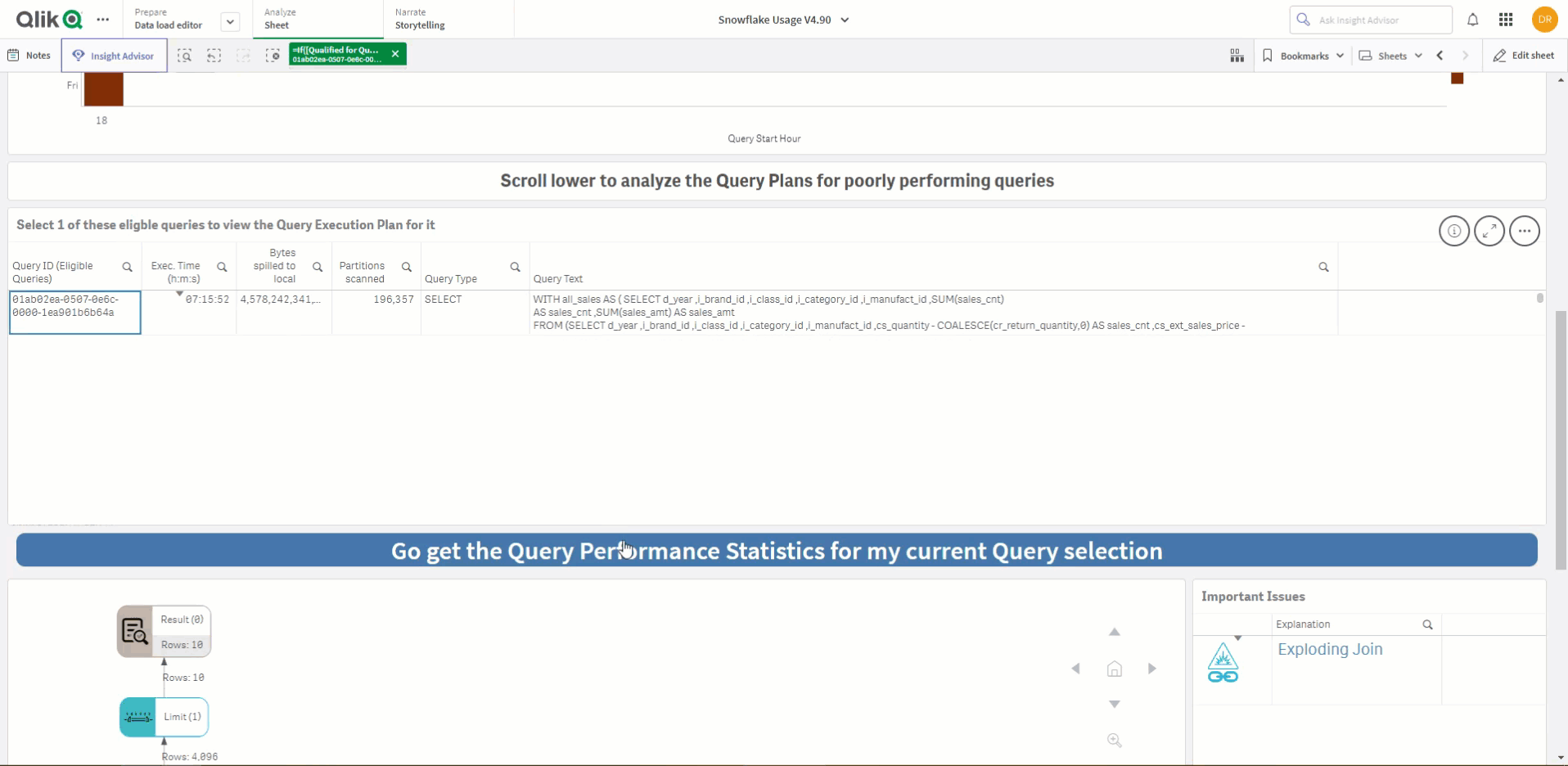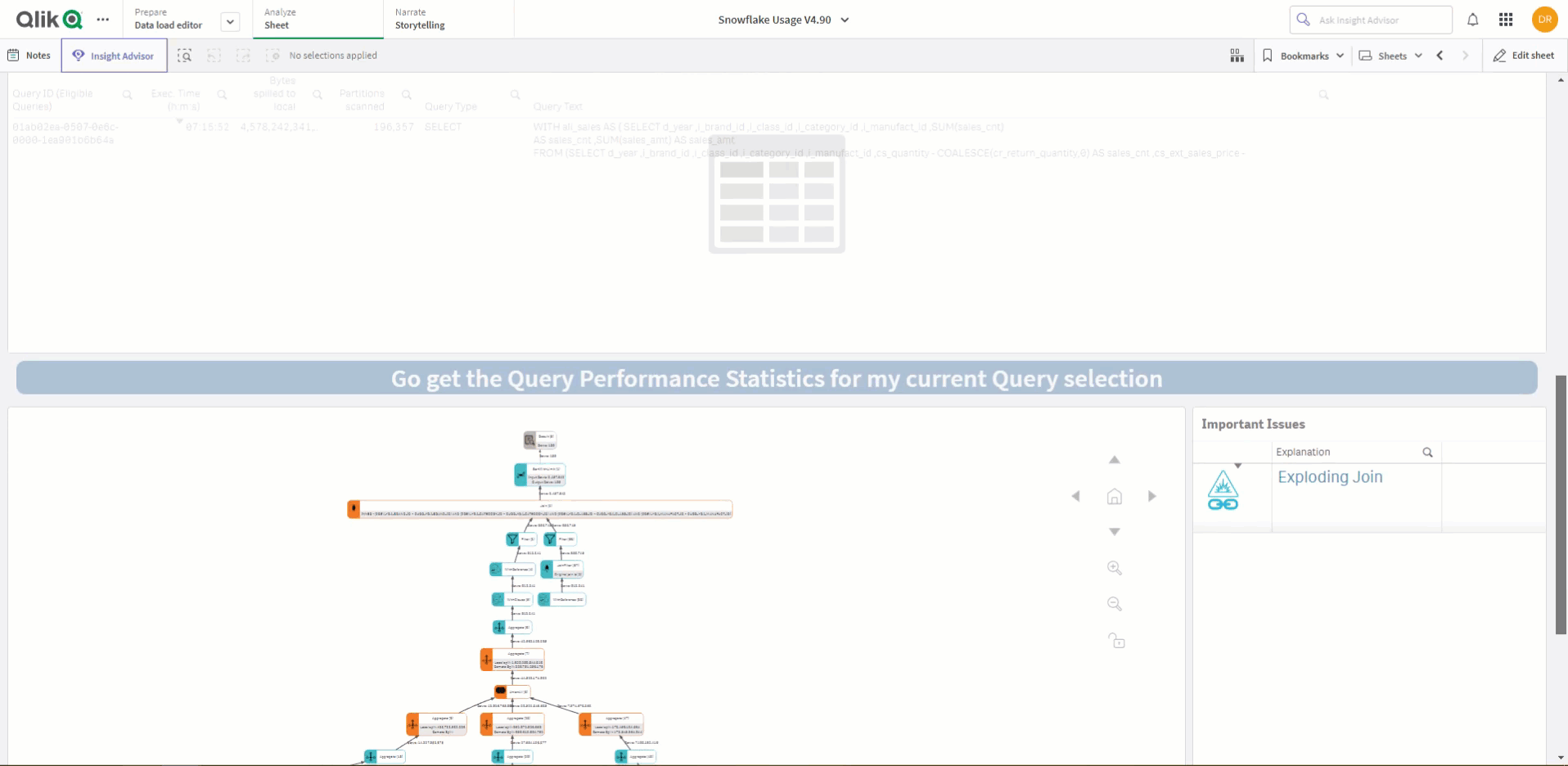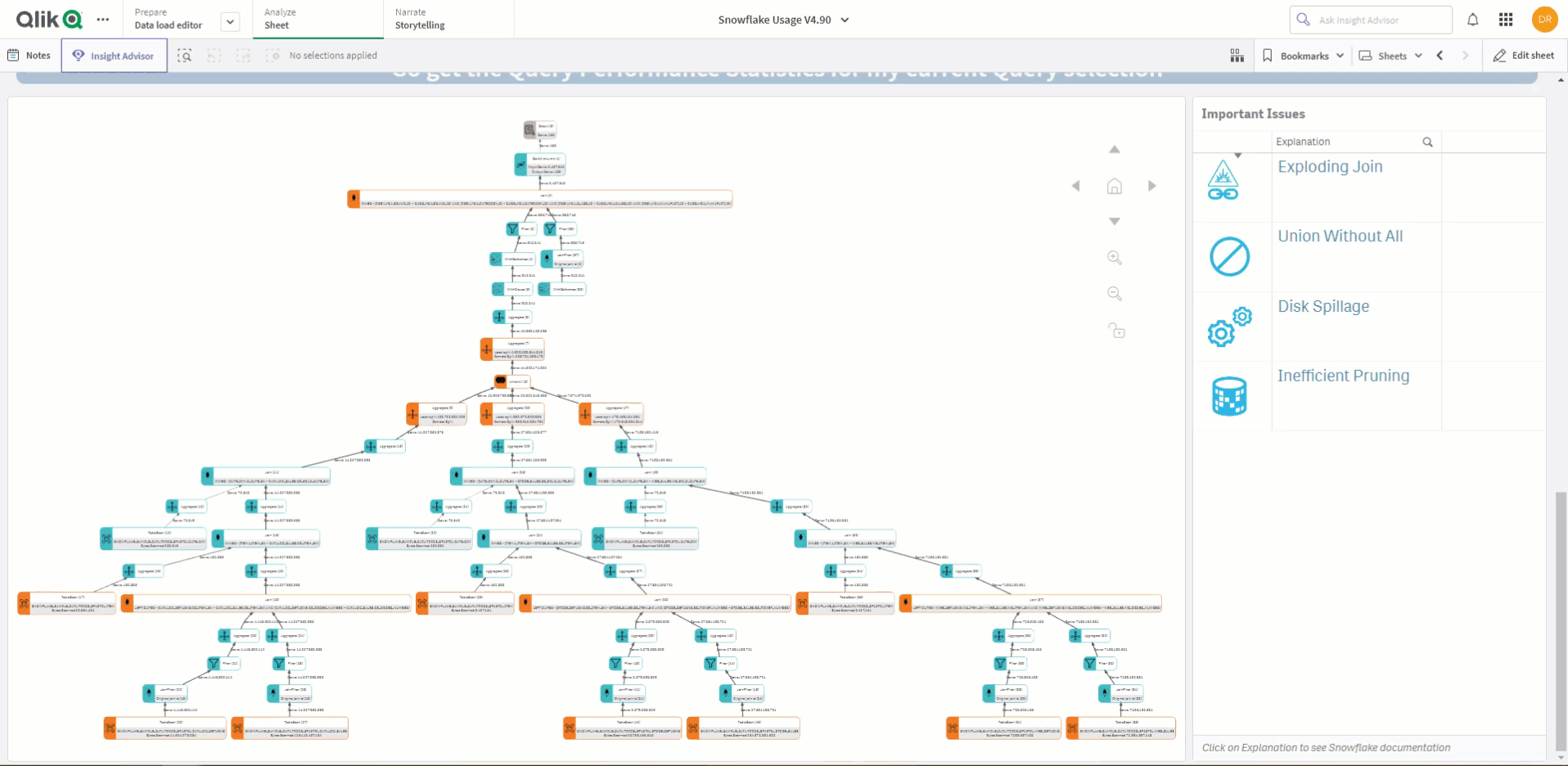
In Power BI we have connected to a Snowflake account using Direct Query and then used dynamic SQL within Power Query to pass the query ID into the Snowflake function. This retrieves the stats of the query ID in question.
Dynamic M parameters allow Power BI to dynamically pass the Query ID into the SQL statement, which allows the user to interactively choose the query ID from a list—which will in turn call the function and retrieve the results instantly. This solution is available here.
Sigma is an analytics and business intelligence platform purpose built for the cloud. Sigma sits directly on top of Snowflake, and passes machine-generated SQL to Snowflake for execution. Sigma includes a robust set of Snowflake monitoring templates free for every customer, built right into its platform. These Snowflake templates assist users with monitoring their Data Cloud implementation, providing insights into query performance, warehouse usage, user activity, and overall cost optimization.
Sigma’s users can take this analysis a step further with a Sigma Query Profile Workbook, which allows users to optimize performance at the individual query level. Sigma’s Query Profile Workbook for Snowflake assists users in identifying resource-intensive queries and ways to optimize them. The workbook includes high-level account statistics including longest running queries, Snowflake credits consumed, and warehouse usage greater than the 7 day average. Users of the workbook can see live views of the QUERY_HISTORY view located in the ACCOUNT_USAGE schema of every Snowflake instance to identify queries of interest. When a query is selected and pasted into the query ID box, Sigma will call Snowflake’s GET_QUERY_OPERATOR_STATS function, and display the query profile. As the query profile populates, Sigma will evaluate the profile for performance optimizations that could be made for a query, including warehouse sizing, poorly performing UNION and JOIN statements, as well as queries that could benefit from using Snowflake Query Acceleration Service.
Snowflake developers and administrators may have heard about Snowflake’s acquisition of Streamlit. This blog post highlights new approaches to visualizing data using Snowflake technology partner tools, and would be incomplete without Streamlit. With tens of thousands of developers, Streamlit empowers Python practitioners to build and deploy interactive applications and share them with colleagues. The Streamlit Snowflake query profiling app is built upon the same Snowflake data sources as the other examples. It allows the user to interactively explore queries of interest and highlights potential problems within seconds of retrieval.

Tableau released a Snowflake Cost and Performance Monitoring Dashboard in 2022 that uses Snowflake account usage tables to analyze the cost and performance of a Snowflake instance. The workbook includes error tracking analysis, storage and warehouse cost analysis, slow-running queries analysis, and more.
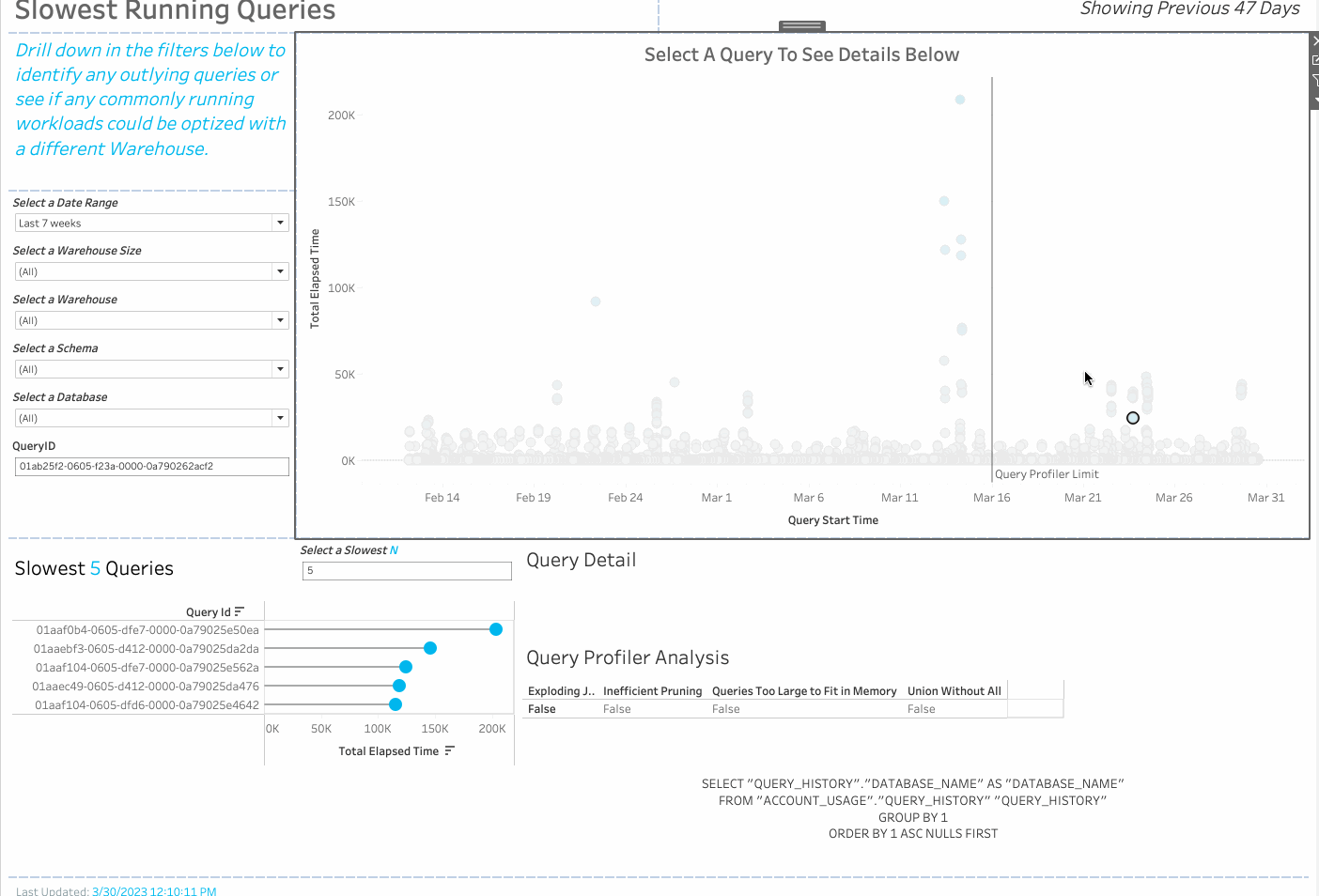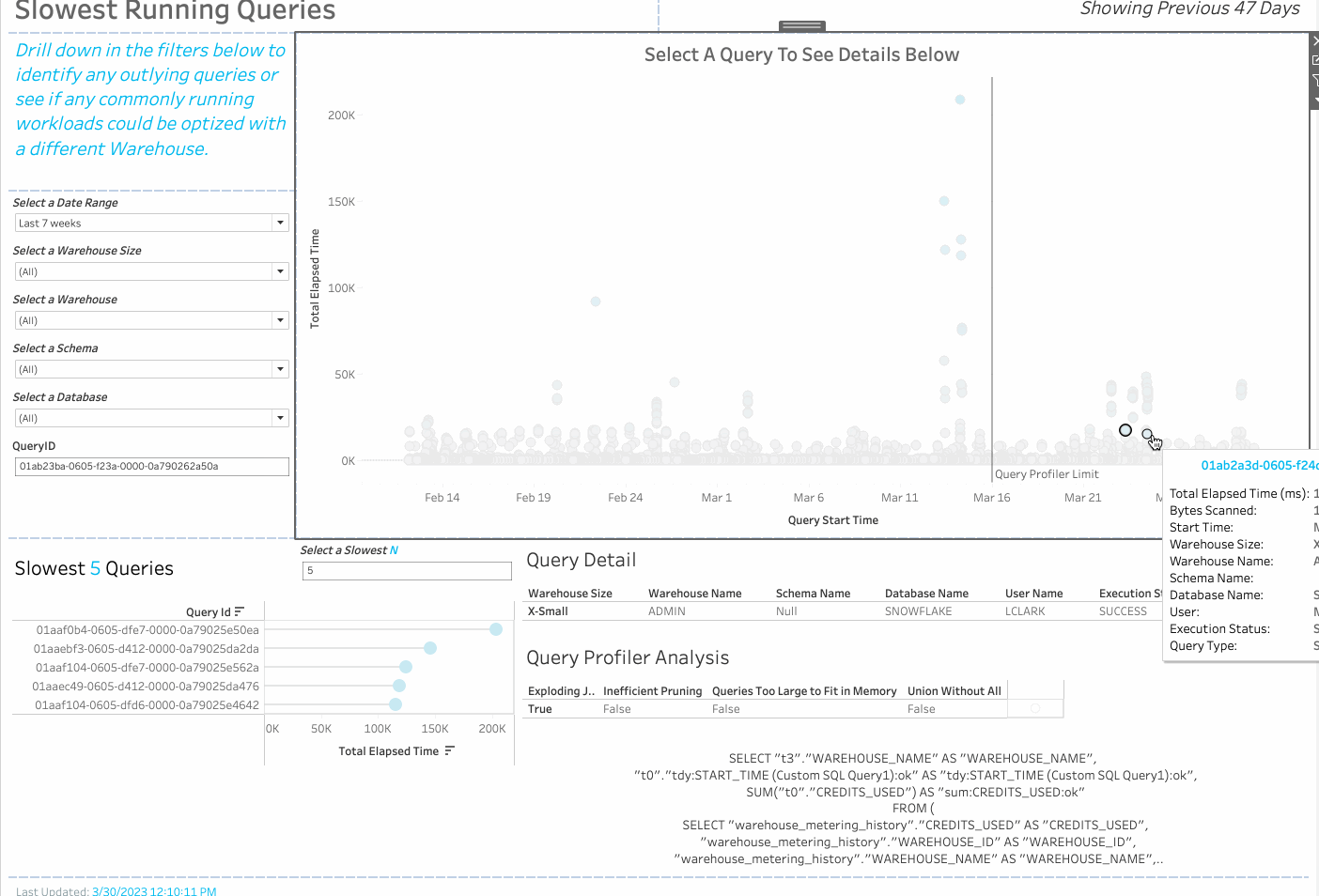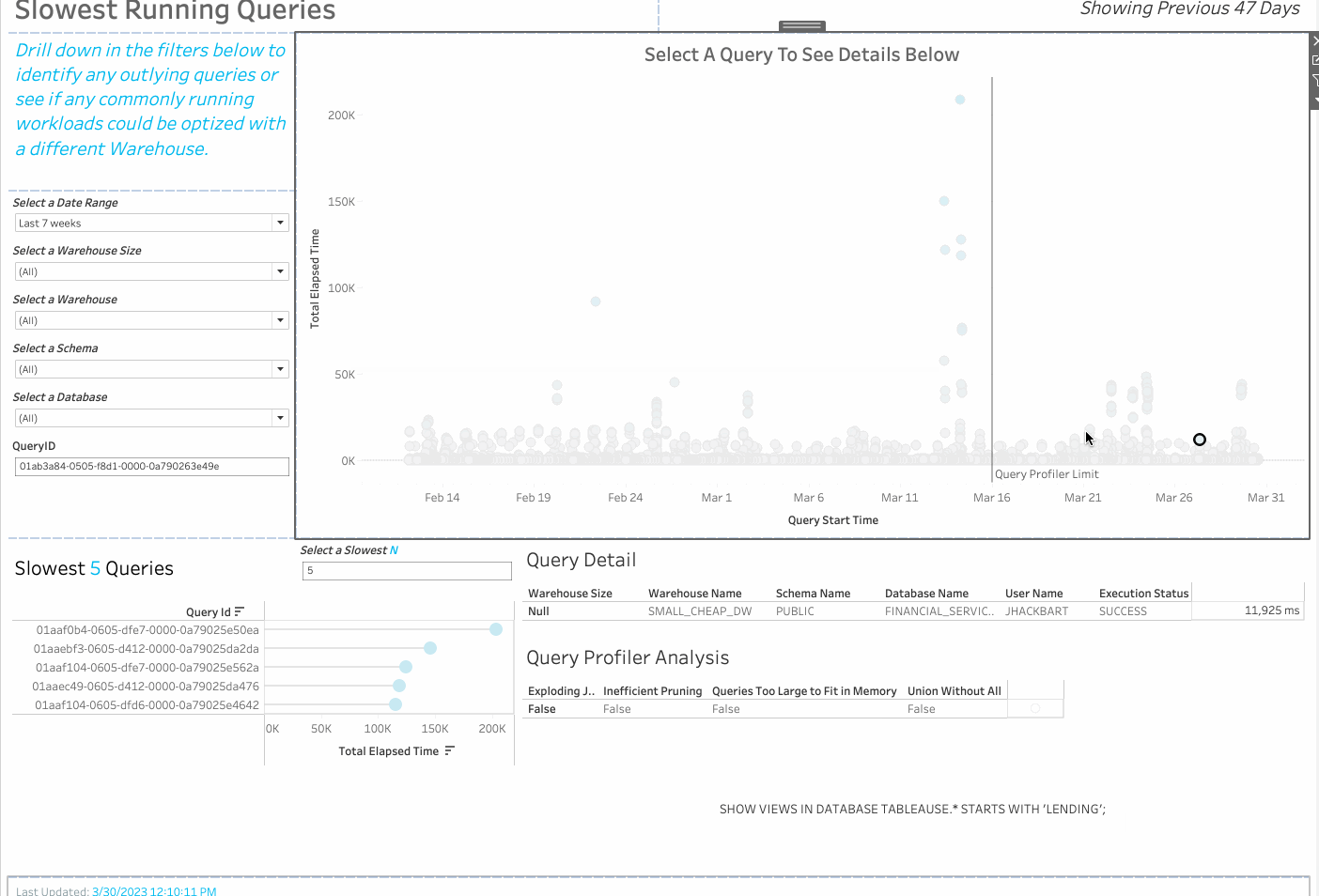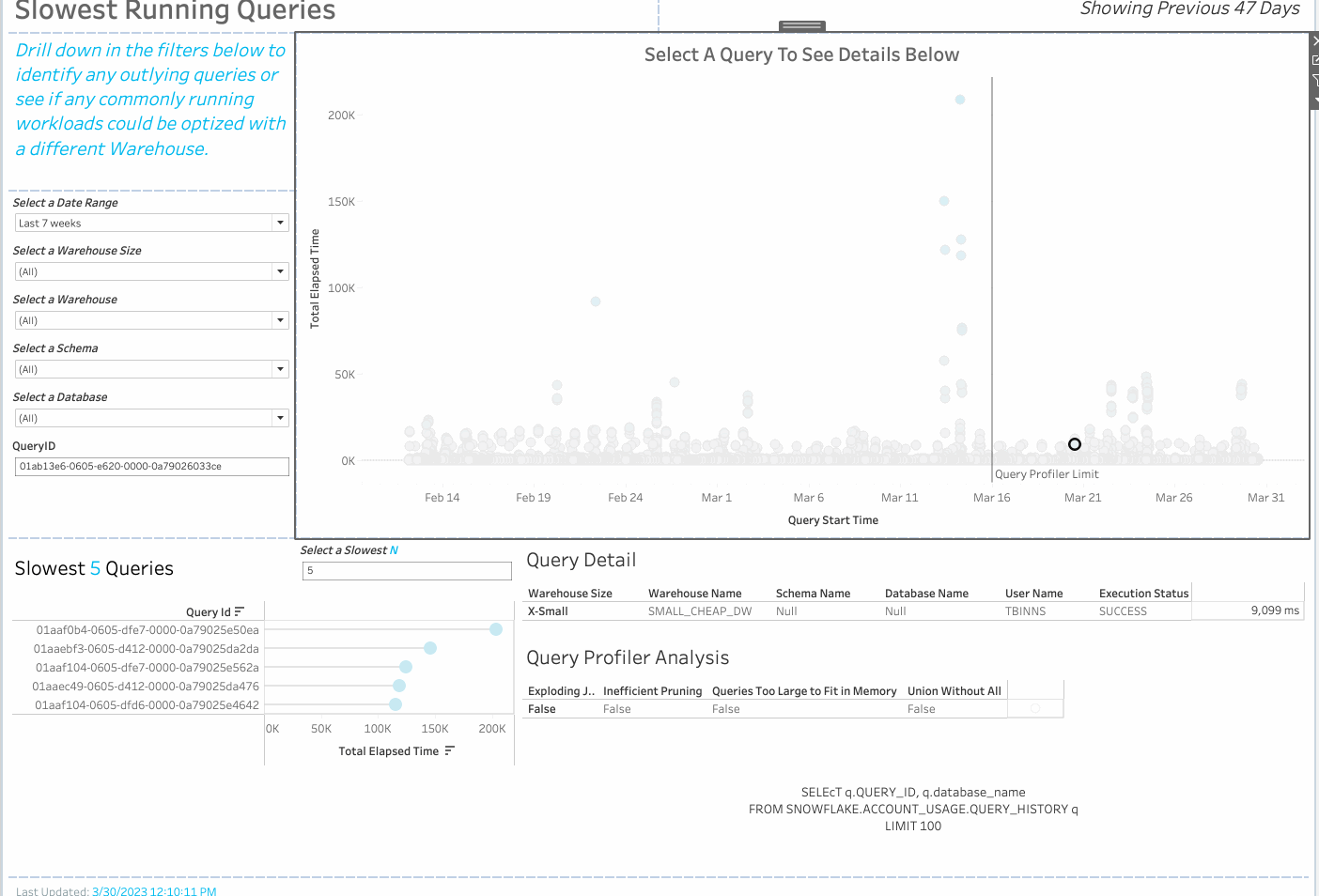
Using the new programmatic access to query profiler stats feature in Snowflake, customers are now able to use a new version of the Snowflake Cost and Performance Monitoring Dashboard that adds query profiler analysis.
Using custom SQL and a parameter called “QueryID,” Tableau is able to retrieve the query profiler stats in real time upon selection of a mark on the “Slow Running Queries” Dashboard. These stats are then parsed into the four different categories of common reasons for slow queries, and show up in the “Query Profiler Analysis” Sheet as True/False values. Each category is calculated using a Tableau calculated field. Viewers of this dashboard can then see the query string that was run; the user that ran it; warehouse, database, and schema, and more. This requires no additional setup in Snowflake.
ThoughtSpot is the AI-Powered Analytics company. With natural language and AI, ThoughtSpot empowers everyone in an organization to ask data questions, get answers, and take action. ThoughtSpot is intuitive enough for anyone to use, yet built to handle large, complex data at cloud scale.
The ThoughtSpot SpotApp for Snowflake Query Profiling is an AI-powered analytics accelerator that provides a holistic view of query performance in the Snowflake Data Cloud. Easy to deploy through a guided implementation process, the SpotApp gives users a proactive look into problematic queries as well as the ability to drill into underlying issues such as latency, failed execution, exploding joins, and more. The SpotApp even provides tips to resolve issues and make future queries more efficient.
Try it out!
We invite Snowflake developers and administrators everywhere to become more familiar with the partner accelerators described above. After connecting the partner solution to your Snowflake account, view a list of recent queries from SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY, and take a deeper dive into individual queries. The new get_query_operator_stats function provides customers a whole new level of insight into Snowflake query performance and query execution statistics. Snowflake and our technology partners are excited to share approaches for customers to expand their ability to visually analyze this information.