
How experimenting with Dynamic Tables on Snowflake led to improvements in the Data Vault patterns.
We have seen enormous interest in Dynamic Tables for Snowflake. So what exactly are Dynamic Tables and where should they fit into your Data Vault architecture?
As a reminder, these are the Data Vault table types:
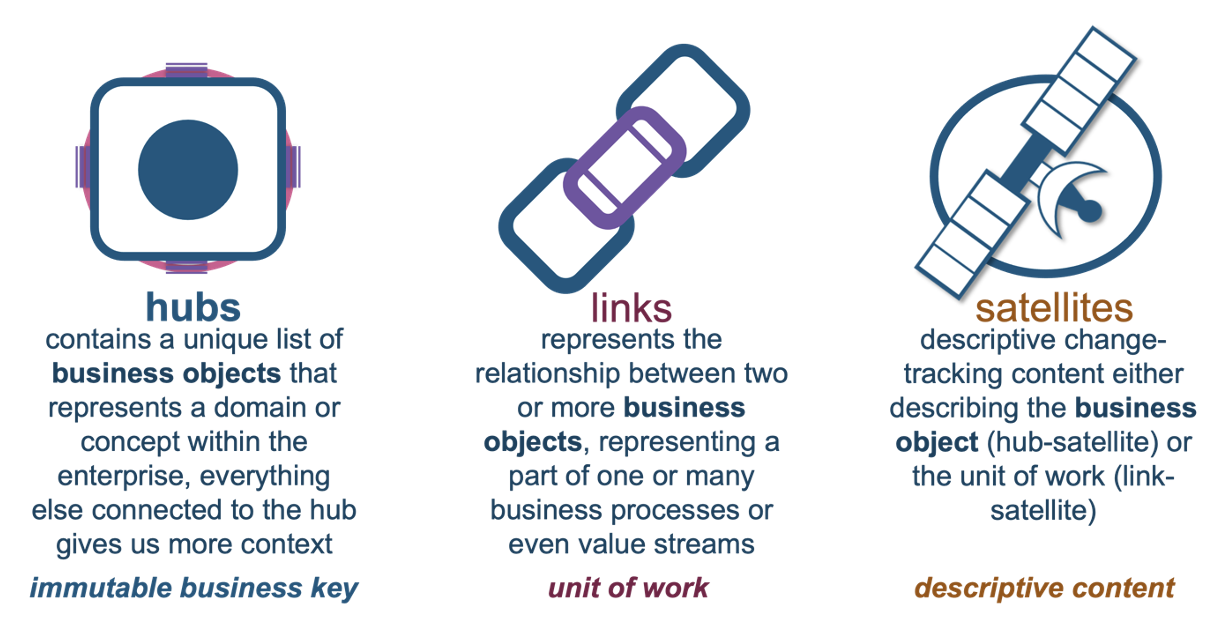
And these are the information mart patterns we need to efficiently get the data out of the Data Vault:
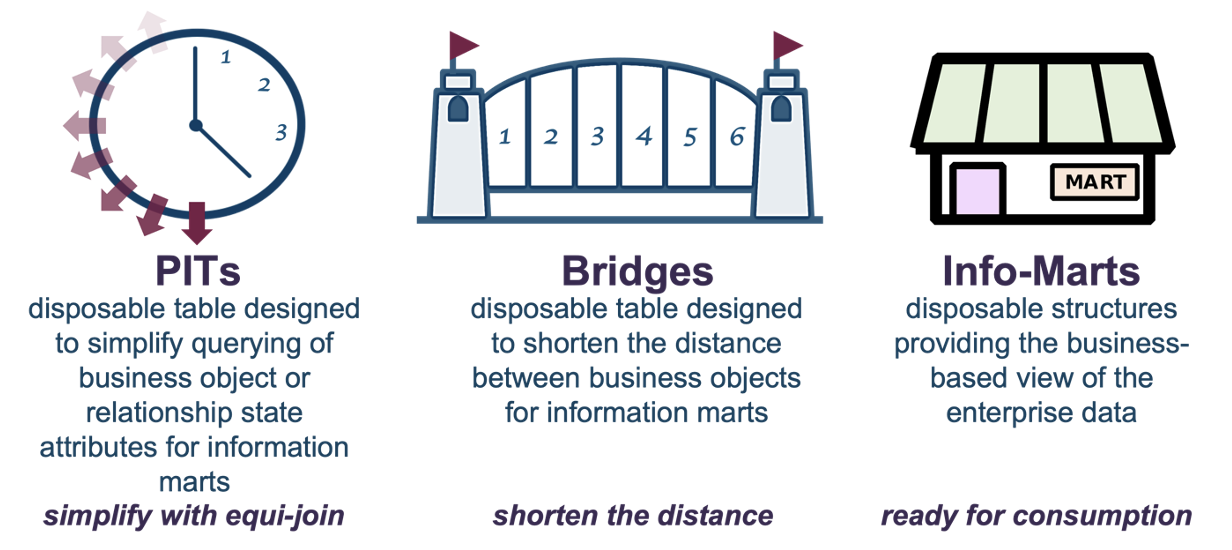
What are Dynamic Tables?
Announced at Snowflake Summit 2022 as Materialized Tables (and later renamed), Dynamic Tables are the declarative form of Snowflake’s Streams and Tasks. As Snowflake streams define an offset to track change data capture (CDC) changes on underlying tables and views, Tasks can be used to schedule the consumption of that data. We covered this in depth in a previous blog post.
To define a Dynamic Table, you:
- Declare the SQL you need to transform your data as a CREATE DYNAMIC TABLE AS statement, similar to CREATE TABLE AS (CTAS)
- Attach a virtual warehouse to perform the transformation work
- Define a schedule in CRONTAB syntax
- Sit back and watch Snowflake deploy Stream offsets on your behalf to underlying tables, views, and other Dynamic Tables to support your SQL declaration as a direct acyclic graph (DAG)
Dynamic Tables offer an account-level snapshot isolation, whereas traditional Snowflake tables are read committed isolation.
Updates to your Dynamic Tables take the required data in its account-level state without interfering with any updates that are concurrently happening to those supporting data structures, including other Dynamic Tables.
Another differentiator of Dynamic Tables is its join-behavior. You can define a Dynamic Table to include SQL joins between data structures as views, tables or other Dynamic Tables. For the Data Vault methodology, you will be executing SQL joins between a lot of tables.
To understand Dynamic Table’s join behavior, we can look back at Snowflake’s Streams on Views. Each Snowflake Stream deploys an offset on a change-tracked supporting table. When a stream is deployed on a view, the offset is not deployed on the view itself, but the underlying tables supporting that view. When the SQL query utilizing that stream is used to push the data and transform data into a target table (DML queries), each offset on each underlying table is independent and processes new change-tracked records.
If a new record is introduced to one of those supporting tables in a natural join, you may expect the SQL join to not find the corresponding record in the join because those other records have already been processed. Not so!
Snowflake will find that record in the other table to support your SQL join and process that record. The join behavior can be eloquently described as:
(Table 1 x Δ Table 2) + (Δ Table 1 x Table 2) + (Δ Table 1 x Δ Table 2)
Where delta (Δ) are the new unprocessed records.
Dynamic Tables support the same SQL join behavior, and we will illustrate this join behavior with the following sample code:
1. Set up the demo environment.
create table if not exists dim_table (
id int
, name varchar(10)
);
create table if not exists fact_table (
id int
, amt int
);
create or replace view dim_fact_equi as
select f.id as id
, f.amt
, d.name
from fact_table f
natural join dim_table d
;
create or replace stream stream_dim_fact_equi on view dim_fact_equi;2. Insert a matching fact and dimension record; the view and stream on view will contain the same number of records.

3. If we insert a fact without a matching dimension record, the new fact does not appear in the view because there is no matching dimension. The stream on the view will also reflect this.

4. When we insert the matching dimension record, it does appear in the view and the stream on view shows the same number of records.

5. When we consume the stream on view (we take the transformed records from the view and push it to a downstream table), the stream on view appears empty when you query it.

6. When we add a new fact record, it will appear in the stream on view.
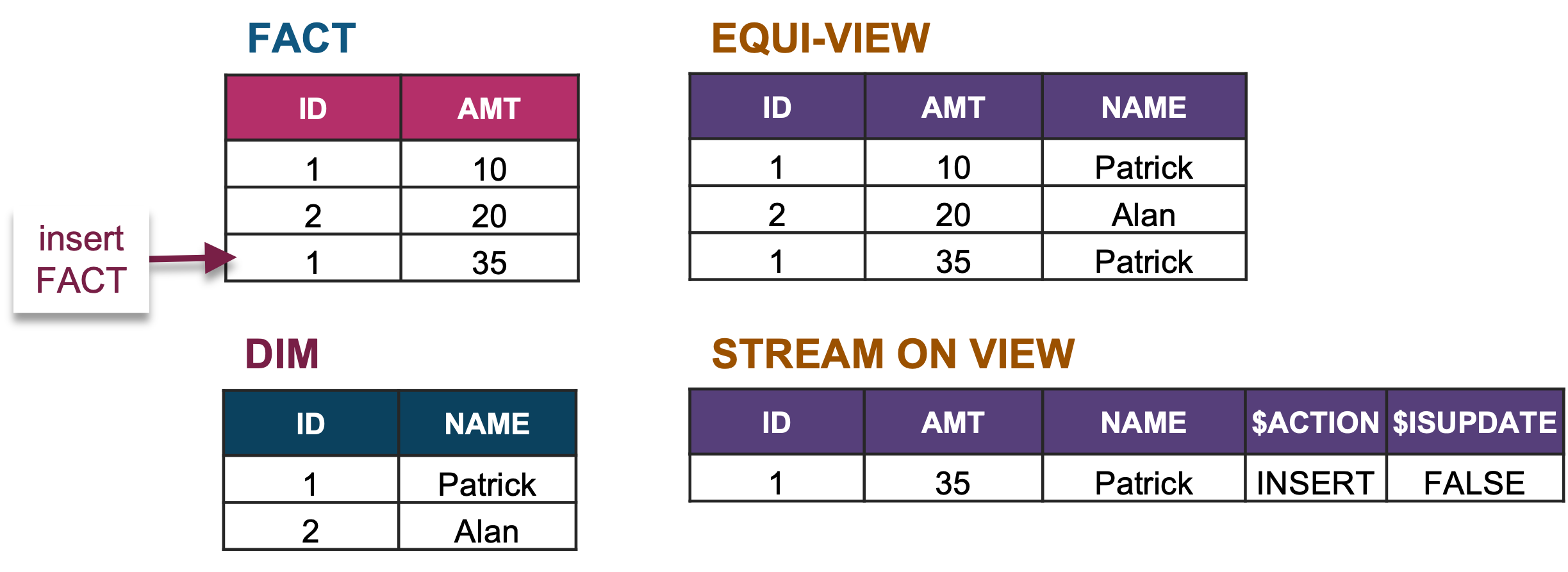
7. Insert another fact record and it will also appear in the stream on view.
Yes, very powerful!
(Fact x Δ Dimension) + (Δ Fact x Dimension) + (Δ Fact x Δ Dimension)
Where Dynamic Tables fit into a Data Vault
In our earlier blog post, we specifically used Append-Only Streams to ingest new data into Data Vault for several reasons:
- Data Vault is an INSERT-ONLY data modeling pattern, therefore updates and deletes to source data are not required.
- Automated deletions on Data Vault data are not normally permitted, and are something that should be carefully controlled; for example, it maybe that you will only permit deletions on Data Vault-loaded data when it relates to legal, regulatory or contractual obligations you might have with your service providers (think GDPR Article 17 “Right to be Forgotten”). Alternatively, we can track record deletions if the source sends a deletion flag or indicator, or we infer record deletions by using either a status tracking or record-tracking satellite tables.
Please keep in mind, you should always check with your company’s legal, regulatory and compliance teams regarding your data retention obligations.
Today’s Snowflake Dynamic Tables do not support append-only data processing. Should any of the sources of a Dynamic Table change to a degree that causes a deletion of records in the Dynamic Table itself, they should not be used to load raw and business vault data (at least not just yet). Because Dynamic Tables act like materialized views and change dynamically on the data that supports it, they are today best suited to the information mart layer in a Data Vault architecture.
Let’s dig into a few scenarios.
Consuming from multiple Data Vault tables:
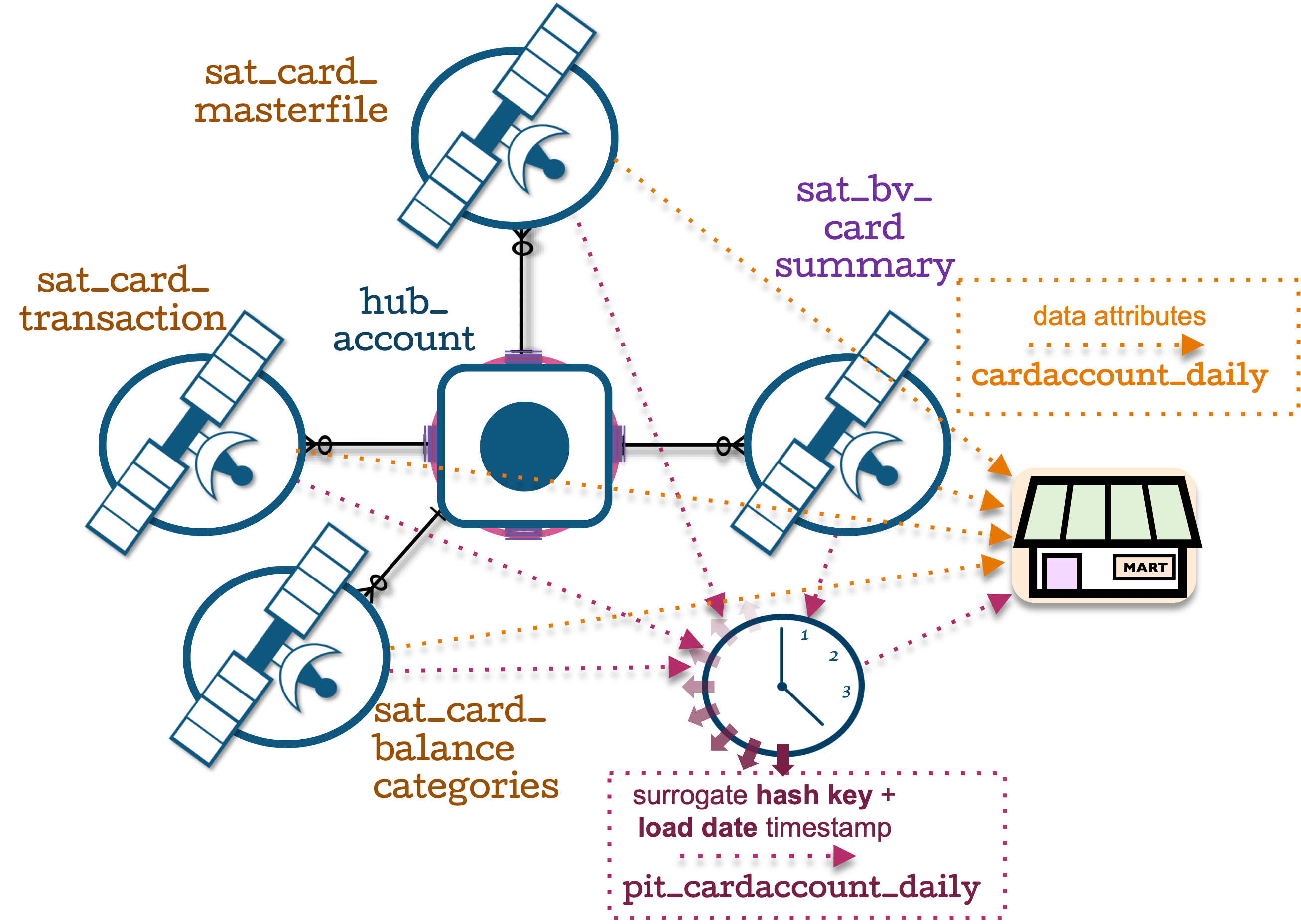
As discussed above, the ideal implementation of Dynamic Tables is to take advantage of its ability to process updates incrementally. Data Vault PIT tables are built as a snapshot query, and when we define the snapshot PIT as a Dynamic Table in the standard Data Vault way, we do indeed see the expected behavior when checking its refresh method—this is either a FULL refresh (essentially a truncate and reload) or INCREMENTAL. This of course means that at every refresh, Snowflake is rebuilding the content for that PIT table (opposite to the purpose of using Dynamic Tables).
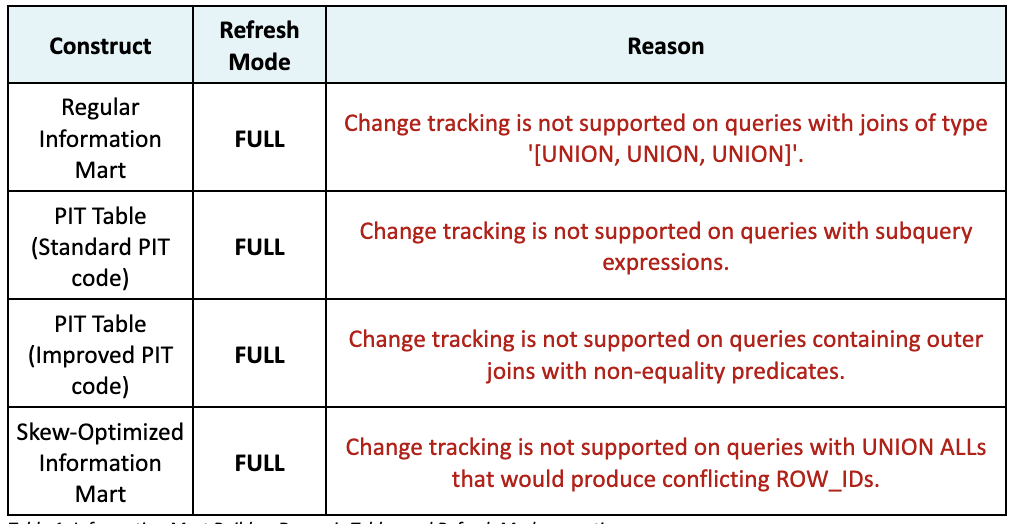
Can we achieve incremental refreshes when deploying a snapshot PIT table as Dynamic Table? Yes, we can!
As we have seen in the reasons listed above, to satisfy an incremental Dynamic Table load for a PIT construct, we need to
- Avoid sub-query expressions
- Ensure we do not use outer joins with non-equality predicates
For that first bullet point, we move where the cross-join is executed in the standard PIT code (where it was used to “build” the matching keys and load dates for each satellite table) to where we expand the needed keys and dates in the parent hub or link table instead.
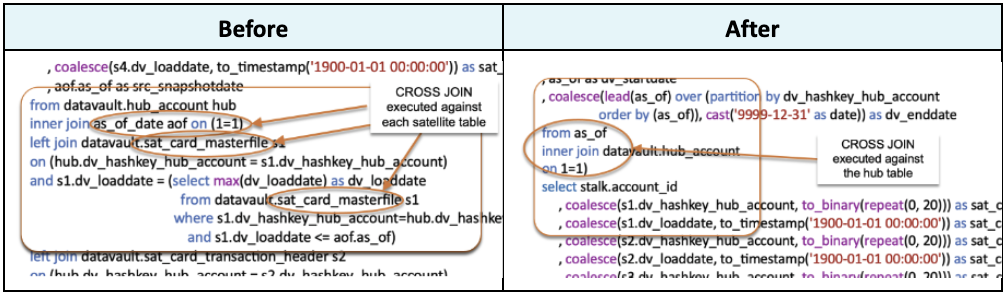
For that second bullet point, we infer the matching load dates and keys by using the Window LAG function with the “IGNORE NULLS” option, like so:
, coalesce(s1.dv_loaddate
, lag(s1.dv_loaddate) IGNORE NULLS over
(partition by st.dv_hashkey_hub_account
order by st.snapshotdate)
, to_timestamp('1900-01-01 00:00:00')) as sat_card_masterfile_dv_loaddateThe window function will:
1. Return the matched load date and surrogate key from the adjacent satellite table for a snapshot date.
2. If a match is not found, then retrieve the previously matched load date and surrogate key from the adjacent satellite table.
3. If no previous load date and surrogate key match exists, then return the GHOST record.
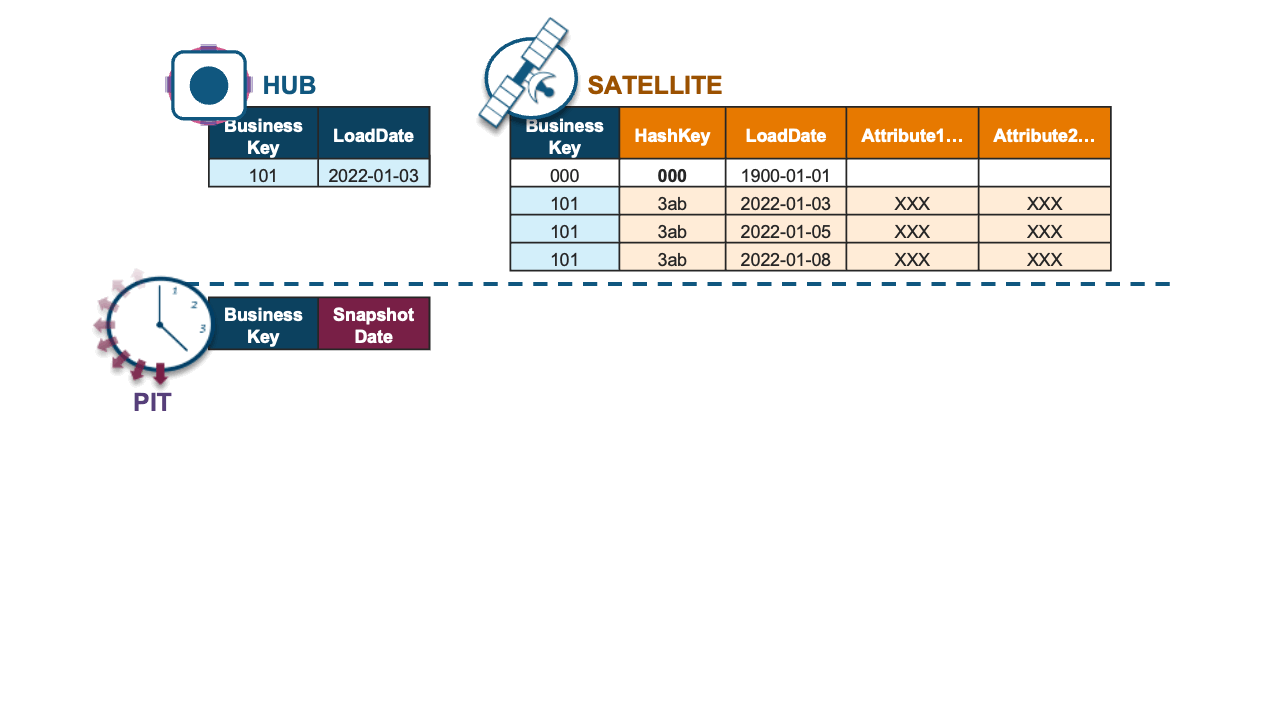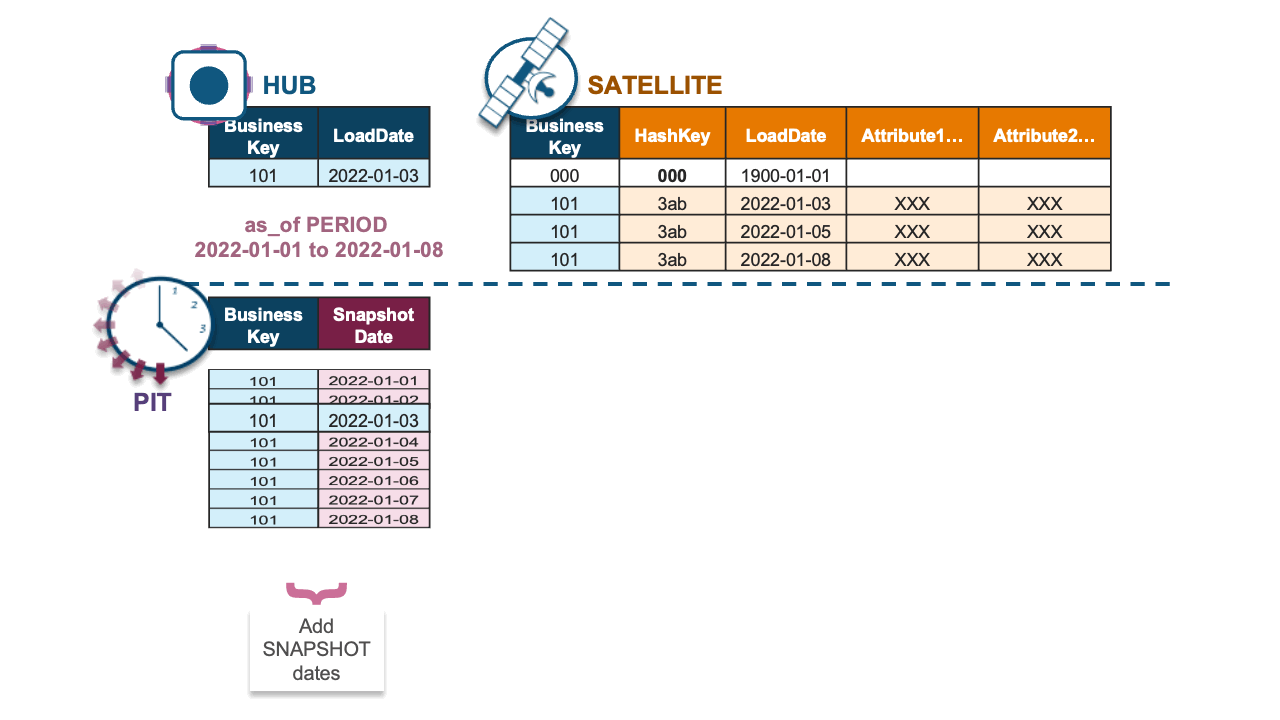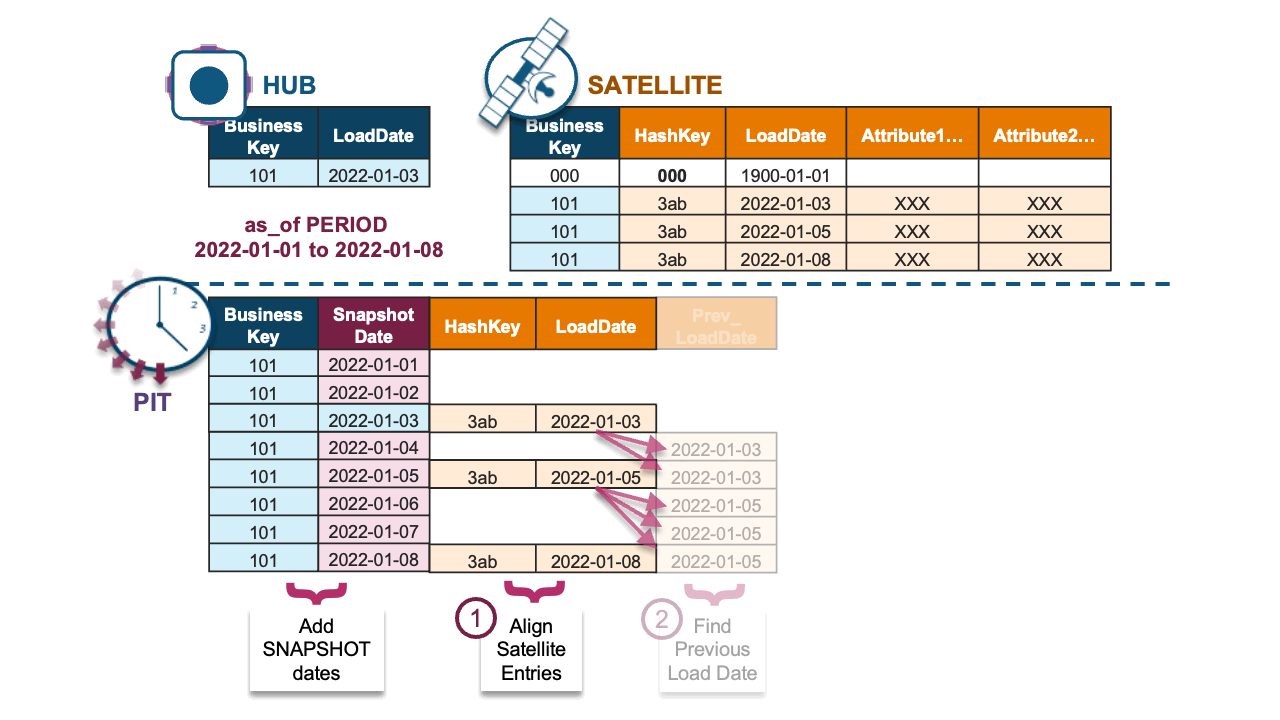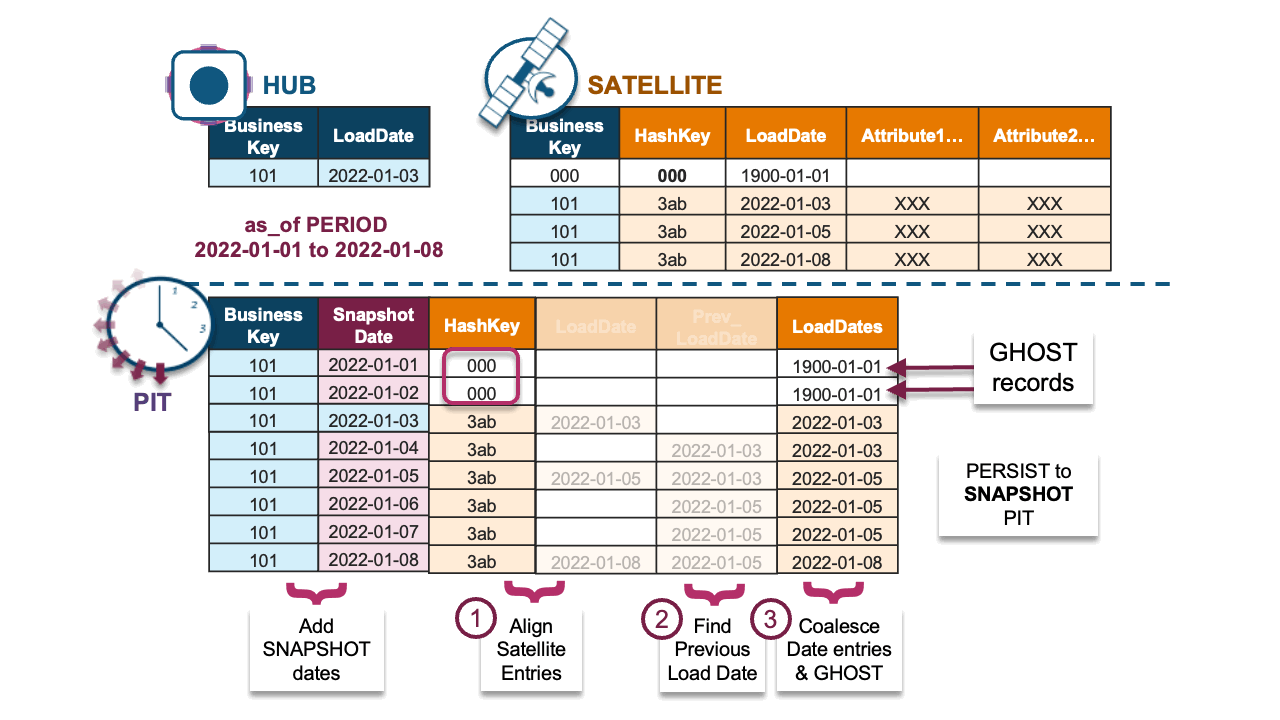
Combined, the full Dynamic Table implementation is defined in a single SQL statement below and achieves incremental updates to a snapshot PIT table.
create or replace dynamic table dt_pit_cardaccount_daily
lag = '1 min'
warehouse = vault
as
with as_of as (select as_of
-- add logarithmic flags here
from as_of_date)
, hub as (select account_id
, dv_hashkey_hub_account
, dv_loaddate as hub_begin_date
from hub_account)
, stalk as (select account_id
, dv_hashkey_hub_account
, as_of as snapshotdate
from as_of
inner join hub
on 1=1)
select st.*
-- sat match, ghost key
, coalesce(s1.dv_hashkey_hub_account
, lag(s1.dv_hashkey_hub_account) IGNORE NULLS over
(partition by st.dv_hashkey_hub_account order by st.snapshotdate), to_binary(repeat(0, 20)))
as sat_card_masterfile_dv_hashkey_hub_account
, coalesce(s2.dv_hashkey_hub_account
, lag(s2.dv_hashkey_hub_account) IGNORE NULLS over
(partition by st.dv_hashkey_hub_account order by st.snapshotdate), to_binary(repeat(0, 20)))
as sat_card_transaction_header_dv_hashkey_hub_account
, coalesce(s3.dv_hashkey_hub_account
, lag(s3.dv_hashkey_hub_account) IGNORE NULLS over
(partition by st.dv_hashkey_hub_account order by st.snapshotdate), to_binary(repeat(0, 20)))
as sat_card_balancecategories_dv_hashkey_hub_account
, coalesce(s4.dv_hashkey_hub_account,
lag(s4.dv_hashkey_hub_account) IGNORE NULLS over
(partition by st.dv_hashkey_hub_account order by st.snapshotdate), to_binary(repeat(0, 20)))
as sat_bv_account_card_summary_dv_hashkey_hub_account
-- sat match, lag sat, ghost date
, coalesce(s1.dv_loaddate
, lag(s1.dv_loaddate) IGNORE NULLS over
(partition by st.dv_hashkey_hub_account order by st.snapshotdate)
, to_timestamp('1900-01-01 00:00:00')) as sat_card_masterfile_dv_loaddate
, coalesce(s2.dv_loaddate
, lag(s2.dv_loaddate) IGNORE NULLS over
(partition by st.dv_hashkey_hub_account order by st.snapshotdate)
, to_timestamp('1900-01-01 00:00:00')) as sat_card_transaction_header_dv_loaddate
, coalesce(s3.dv_loaddate
, lag(s3.dv_loaddate) IGNORE NULLS over
(partition by st.dv_hashkey_hub_account order by st.snapshotdate)
, to_timestamp('1900-01-01 00:00:00')) as sat_card_balancecategories_dv_loaddate
, coalesce(s4.dv_loaddate
, lag(s4.dv_loaddate) IGNORE NULLS over
(partition by st.dv_hashkey_hub_account order by st.snapshotdate)
, to_timestamp('1900-01-01 00:00:00')) as sat_bv_account_card_summary_dv_loaddate
from stalk st
left join sat_card_masterfile s1
on st.dv_hashkey_hub_account = s1.dv_hashkey_hub_account
and st.snapshotdate = s1.dv_loaddate
left join sat_card_transaction_header s2
on st.dv_hashkey_hub_account = s2.dv_hashkey_hub_account
and st.snapshotdate = s2.dv_loaddate
left join sat_card_balancecategories s3
on st.dv_hashkey_hub_account = s3.dv_hashkey_hub_account
and st.snapshotdate = s3.dv_loaddate
left join sat_bv_account_card_summary s4
on st.dv_hashkey_hub_account = s4.dv_hashkey_hub_account
and st.snapshotdate = s4.dv_loaddate)
;Supporting current active records for each satellite table
Data Vault satellite tables are INSERT ONLY table structures with end-dates to each record inferred using the window LAG function in every query. We define this once over the underlying table as an SQL view. For a small satellite table, the performance may be fine, but when the satellite table grows to hundreds of millions or billions of records, the performance may begin to suffer. We did discuss a pattern to solve this performance bottleneck in this blog post, and as you might have guessed, we can use Dynamic Tables that refresh incrementally for this pattern, too.
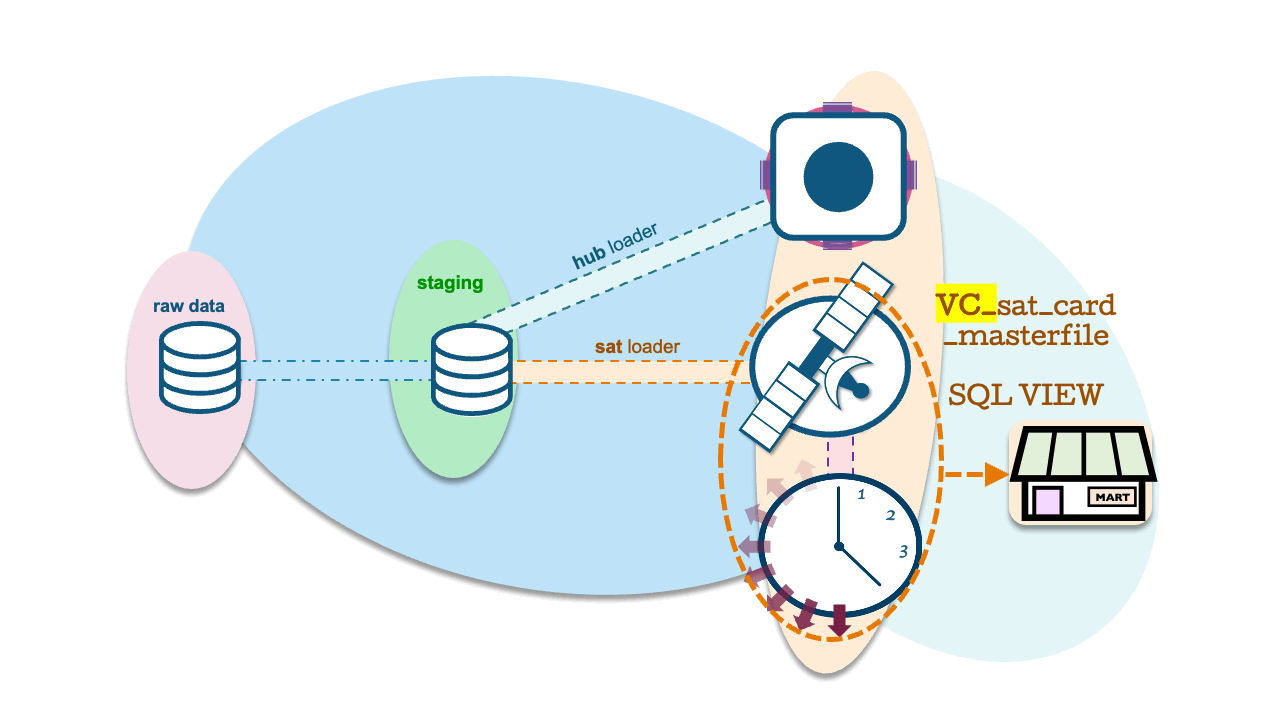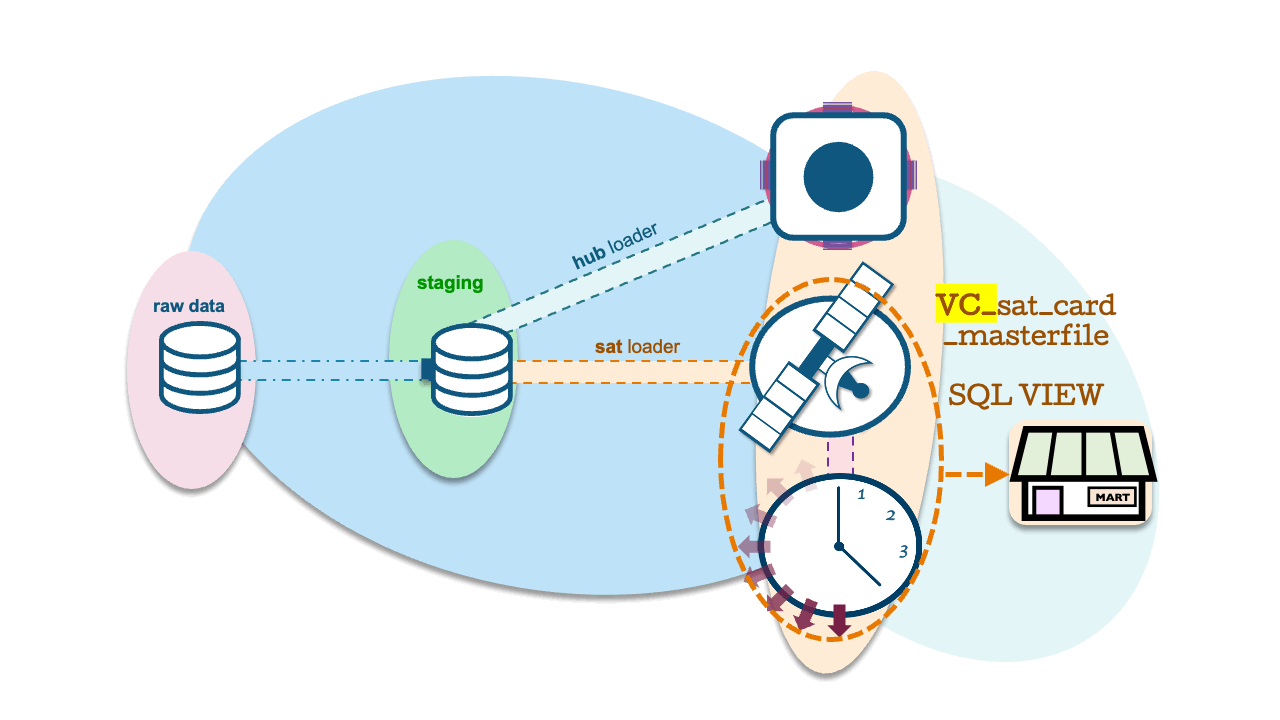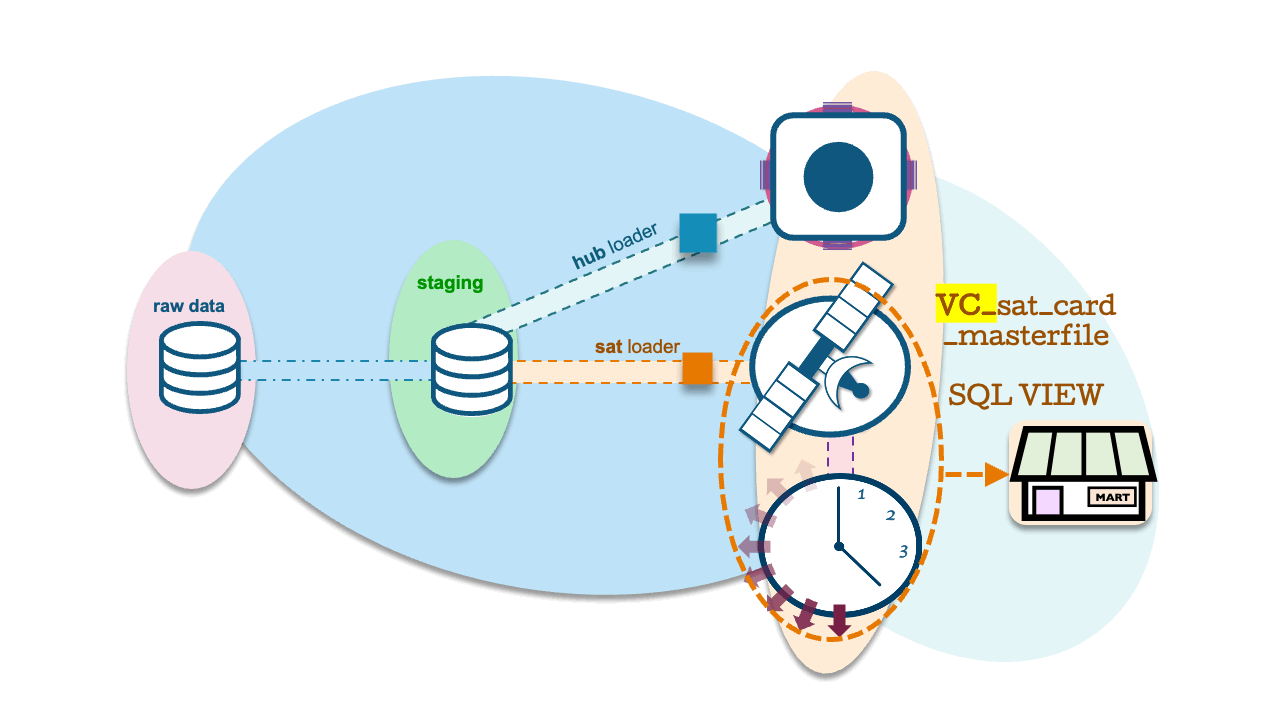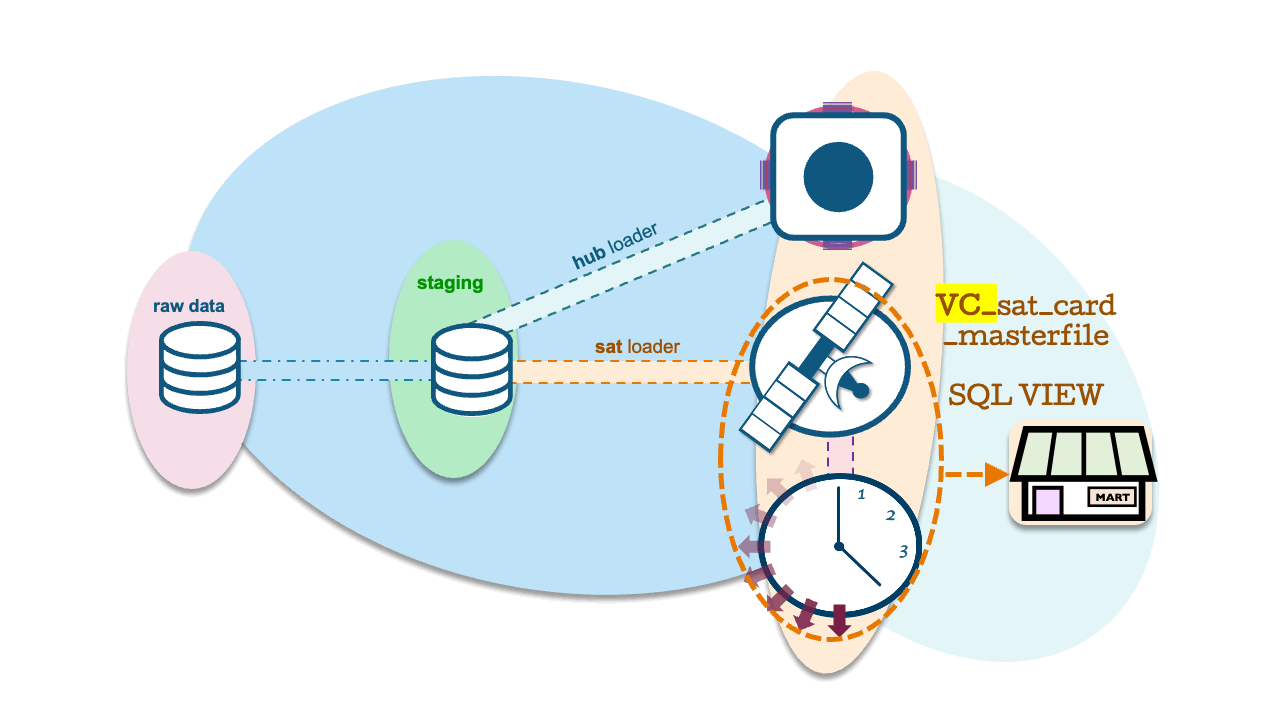
Dynamic Tables as C-PITs
To achieve this, we simply use a Dynamic Table with a QUALIFY clause and row_number() function. Define the SQL VIEW as an inner join between the current PIT table and adjacent satellite table, and Snowflake will use a JoinFilter to return the active records through dynamic pruning.
create or replace dynamic table dt_CURRENT_SAT_CARD_MASTERFILE_PIT
lag = '1 min'
warehouse = vault
as
select dv_hashkey_hub_account
, dv_loaddate
from sat_card_masterfile
qualify row_number()
over
(partition by dv_hashkey_hub_account order by dv_applieddate desc, dv_loaddate desc) = 1
;
-- users do not see the join
create or replace view vc_sat_card_masterfile as
select s.*
from SAT_CARD_MASTERFILE s
inner join dt_CURRENT_SAT_CARD_MASTERFILE_PIT cpit
on s.dv_hashkey_hub_account = cpit.dv_hashkey_hub_account
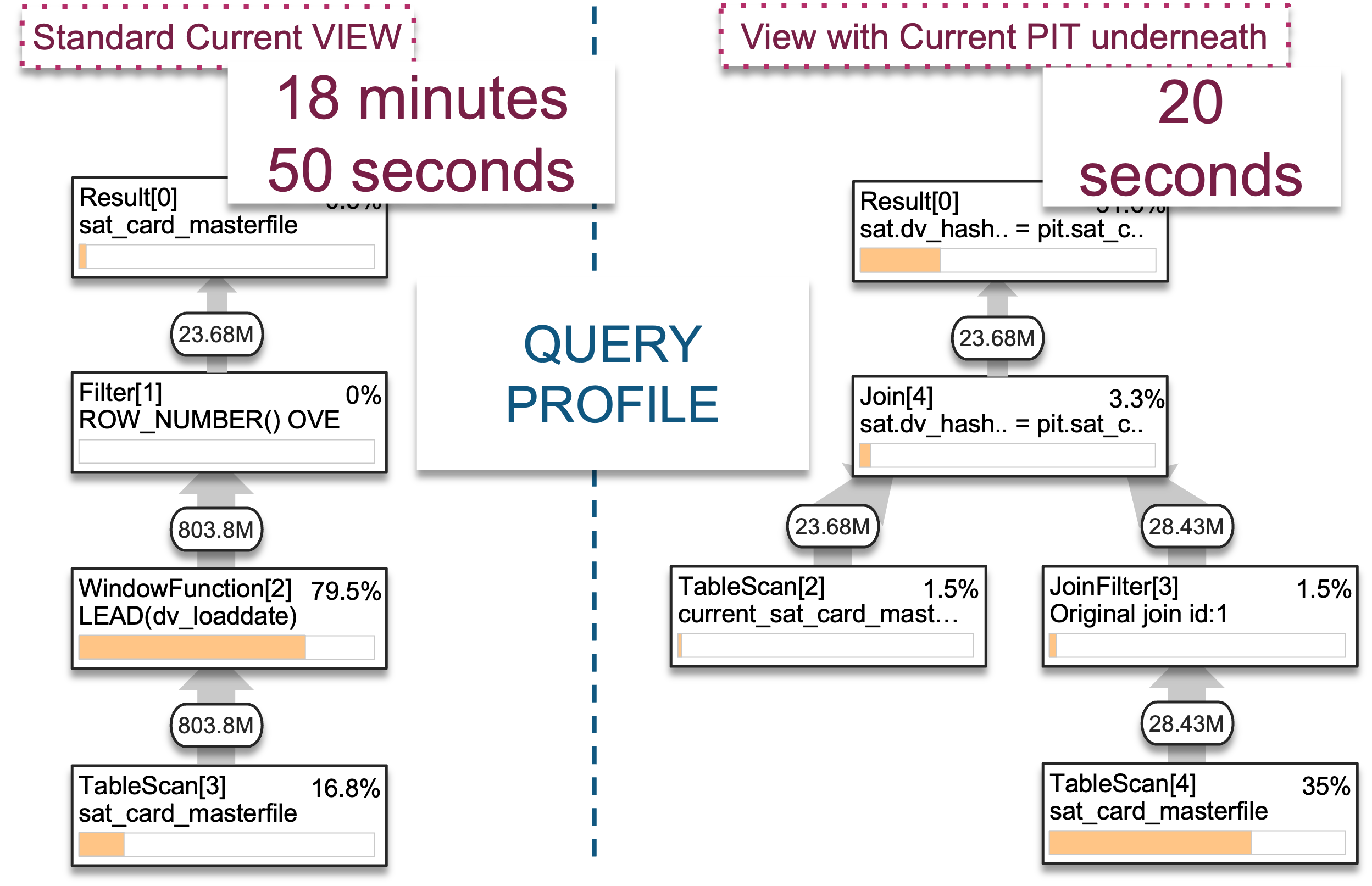
and s.dv_loaddate = cpit.dv_loaddateAs for the outcome, an 800 million record satellite table returns 23 million active records in 20 seconds!
What about near real-time streaming?
The intention of Dynamic Tables is to apply incremental transformations on near real-time data ingestion that Snowflake now supports with Snowpipe Streaming. Data enters Snowflake in its raw operational form (event data) and Dynamic Tables transforms that raw data into a form that serves analytical value. Data Vault does indeed prescribe real-time data model structures for this ingestion pattern, called non-historized link and satellite tables.
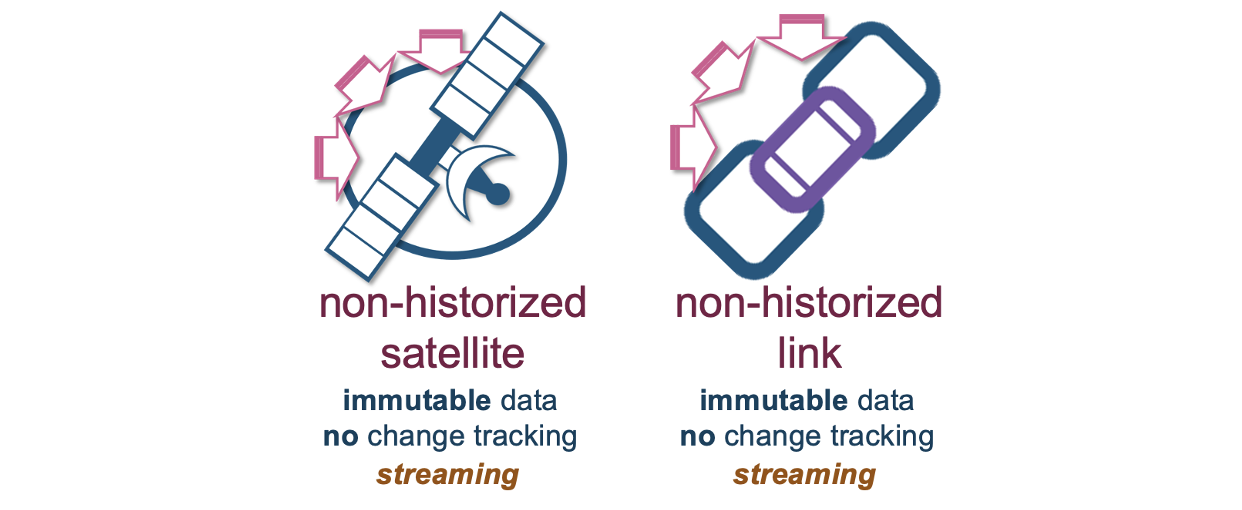
Unlike regular link and satellite table loading patterns, the loading pattern for non-historized tables assumes that every ingested event is always new and the data loaded is immutable. Therefore, to load non-historized tables, no checking for true changes is necessary and Snowpipe Streaming already guarantees exactly once semantics. The pattern therefore remains the same: ingest into raw and business vault and deploy Dynamic Tables in your information mart layer.
An alternative approach
These are just early days for this feature, and Snowflake’s Dynamic Tables will add more functionality over time. Dynamic Tables do not replace Streams & Tasks but rather offer an alternative to how you manage your data pipelines within Snowflake. Streams & Tasks give you fine-grained control of your offsets, while Dynamic Tables hands that finer-grain control over to Snowflake. You can also view and administer your Dynamic Tables in Snowsight.
Within your Data Vault architecture, you can see that you can already start using Dynamic Tables for several use cases to enhance your Data Vault on Snowflake experience.
As always, use the above patterns as a guide and test the patterns for your scenarios yourself. We look forward to widespread adoption of Dynamic Tables. Until next time!
References
- Data Vault Guru: A Pragmatic Guide to Building a Data Vault https://www.amazon.com/dp/B08KSSKFMZ
- Keep your Data Vault honest with this test suite https://github.com/PatrickCuba/the_data_must_flow
- Data Vault and Domain-Driven Design https://medium.com/snowflake/1-data-vault-and-domain-driven-design-d1f8c5a4ed2
- Dynamic Tables https://docs.snowflake.com/en/user-guide/dynamic-tables-about
To deep dive into the topics discussed above and other performance patterns and recommendations for your Data Vault, visit this medium post, Data Vault on Snowflake: Performance Tuning with Keys