
In the first part of this series, my esteemed colleague, Robert Fehrmann, demonstrated how to create vast amounts of data in Snowflake using standard SQL statements. In the second part of this series, he continued to develop a Python script that automates the creation of those SQL statements leveraging a standardized specification. These scripts and documentation can be found here.
I recently worked on a project that required accurate representation of the customer’s existing data in order to test the overall cost difference between their current architecture and a proposed change. The environment consisted of more than 2,000 tables of varying sizes, which I did not have direct access to. I needed a way to generate accurate statistics to plug into Robert’s spreadsheet, which I would then use to generate SQL statements on a different Snowflake account. It dawned on me that the effort involved for my customer to generate the statistics and then the effort for me to plug those numbers into the template could be alleviated by using Python and a notebook that did both of these at the same time.
This post will provide a high-level overview of the Python I created. The notebook is available on GitHub here and was built on Google Colaboratory (Colab). For those who have not used it before, Colab provides a hosted Python Notebook environment for free. You can load the GitHub .ipynb file directly from Colab’s interface.
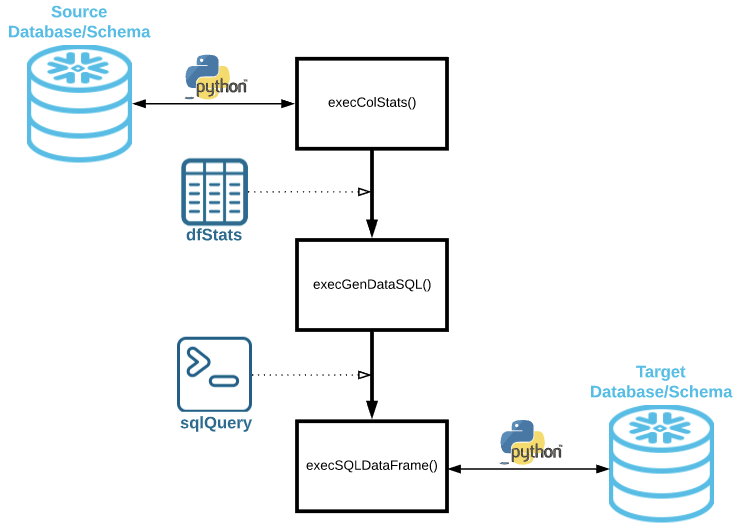
The Dynamic Data Generator Notebook
The notebook walks you through the following pieces of code:
- Code for installing the correct libraries necessary for the Python code in the notebook. Note that this is necessary to run in a tool such as Colab, but if you are using your own Jupyter or other iPython environment, you can just execute them once to get things set up.
- Code for setting up connection variables for both your source account (the system that you want to replicate data from) and your target account (the system that you will be generating data on).
- Four functions included in the notebook. The first function is getEngine(), which simply creates a SQLAlchemy engine based on the variables set in step #2 . The second function is execSQLDataFrame(), which executes any SQL passed to it and returns the data as a Pandas DataFrame. The other two functions, execColStats()and execGenDataSQL(), are detailed further below.
- The main cell, which executes the functions for each table in a schema on the source account.
execColStats() function
This function generates statistics from the source tables based on the data types of each field. The input of the function is a DataFrame that contains all the column information for a table, which comes from the following SQL:
SELECT *
FROM information_schema.columns
WHERE table_name = '""" + str(dfTables.name[i]) + """'
AND table_schema = '""" + sourceSchema + """'
AND data_type NOT IN ('VARIANT','ARRAY')
ORDER BY ordinal_position;
Since different data types require different statistics, I created the following table to show what the code in this function is generating in addition to the table_name, column_name, and data_type fields:
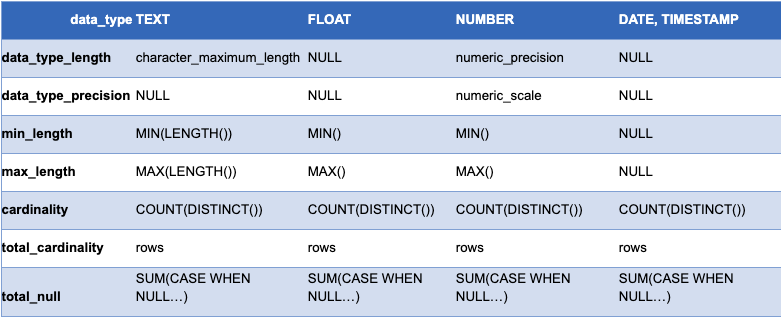
Note that Robert’s code does not currently handle generating ARRAY or VARIANT values on the target side. The notebook filters out ARRAY and VARIANT columns from being evaluated and they will ultimately be populated with NULL values.
The output of this function is then a DataFrame of these statistics that can be used by the execGenDataSQL() function to produce Robert’s data generation SQL statements.
execGenDataSQL() function
This function leverages the DataFrame from execColStats() to create the necessary SQL statement that dynamically generates data using Robert’s code. The biggest modification from Robert’s code to this notebook is that the SQL statement is an INSERT statement, rather than a CREATE TABLE AS SELECT, since the main cell of the notebook will generate the table for you ahead of time, if it doesn’t exist using the actual data definition language (DDL) from the source system. I found this to be a more accurate way of creating the tables. The output of this function is a SQL statement as a string, which is then used in the main cell at the bottom of the notebook.
Main Cell
For each table in the schema specified, the following code is executed. The code executes the code that was referenced earlier in this post to create a dfColumns DataFrame. Once the DataFrame is created, it is passed into execColStats() to produce a dfStats DataFrame containing the information needed to produce the SQL query. dfStats is sent into execGenDataSQL() (as explained above) to create a sqlQuery that can be executed. Before executing sqlQuery, the target is checked to see if the table exists. If the table does not exist, the code will run a get_ddl() statement against the source to generate the table on the target. This code is shown below for reference:
dfColumns = execSQLDataFrame(SourceEngine, sqlQuery)
if dfColumns.shape[0] != 0:
dfStats = execColStats(dfColumns,str(dfTables.rows[i]))
sqlQuery = execGenDataSQL(dfStats)
sqlCheckQuery = """
SELECT table_name
FROM information_schema.tables WHERE
table_name = '""" + dfTables.name[i] + """'
and table_catalog = '""" + targetDatabase + """';"""
target_check = execSQLDataFrame(TargetEngine, sqlCheckQuery)
if target_check.shape[0] != 0:
output = execSQLDataFrame(TargetEngine, sqlQuery)
else:
target_ddl_sql = """SELECT get_ddl('table','""" + dfTables.name[i] + """') as
ctas;"""
target_ddl = execSQLDataFrame(SourceEngine, target_ddl_sql)
execSQLDataFrame(TargetEngine, target_ddl.ctas[0])
output = execSQLDataFrame(TargetEngine, sqlQuery)
There are a few things to note regarding the get_ddl() function that could create issues, however. First, if the table definition has constraints for tables that do not exist on the target, the DDL will fail. Second, if the table definition has comments that contain apostrophes, the DDL will fail. For both of these cases, you must manually generate the table on the target. Included in the notebook is an optional cell at the very bottom that allows the sqlQuery to be printed to the notebook rather than executed directly. This allows you to manually execute the INSERT statement after you’ve created the table manually.
Summary
If you find yourself in a situation where you are trying to generate random data that looks very similar to an existing Snowflake database, the notebook referenced in this document will help you replicate a source schema and create a new target schema with random data. It leverages a slightly modified version of Robert’s data generator, but it skips the process of generating statistics, collecting them in a CSV or Excel spreadsheet, and then using that information to generate SQL statements. Instead, it generates those statistics for you, leverages them directly to create the SQL statements, and then executes them for you on a new target schema. For the customer that I worked with, this process saved us many days of executing, gathering, and processing statistics in order to generate random data.