
Two different data modeling approaches—dimensional data modeling and Data Vault—each have their own pros and cons. But by using a hybrid approach, you can have the best of both worlds.
Modernizing a data warehouse with Snowflake Data Cloud is a smart investment that can provide significant benefits to businesses of all sizes, today more than ever as data models become ever more complex.
With Snowflake’s support for multiple data models such as dimensional data modeling and Data Vault, as well as support for a variety of data types including semi-structured and unstructured data, organizations can accommodate a variety of sources to support their different business use cases. Snowflake’s ability to handle structured and unstructured data allows companies to analyze diverse data sets, such as social media feeds, sensor data, and customer feedback, alongside traditional transactional data.
Traditionally, the dimensional data modeling approach is used to build complex data warehouses, while Data Vaults are used in data warehouses to offer long-term historical data storage while modeling. A hybrid approach can deliver benefits by overcoming the shortfalls of the two approaches.
Why is data modeling important for a data warehouse?
Data modeling creates a visual representation of a part or the whole information system so you can understand the types of data, relationships, groupings, attributes, and other parameters.
Please note, any data model or architecture’s performance is at the mercy of the architect and modeler, so the following claims are subjective. That being said, performing data modeling in a data warehouse offers many benefits like:
- Expansion of data warehouses or integration of new data sources
- The standardization of data models, which helps ensure consistency of data across the organization
- Well-organized data, which allows for faster, more accurate business decision-making
Enforcing entity relationships
In order to maintain the data model as a whole, constraints are crucial for maintaining the links between elements. To keep the data model in good form, Snowflake allows primary key, foreign key, unique key, and “not null” constraints. Snowflake will not enforce any constants other than not null. However, we may verify the entity relationship and data integrity in the data model using Snowflake Tasks.
What is dimensional data modeling?
Data dimensional modeling (DDM) is a modeling technique that uses dimension tables (descriptive data) and fact tables (metrics data) to store the data in a data warehouse efficiently. It optimizes the database to retrieve the data faster.
Dimensional models have a specific structure and organize the data to simplify complex data structures, and the denormalized data improves performance.

What is the Data Vault modeling approach?
The Data Vault modeling approach has a design suited for large, complex data integration. The hub-and-spoke architecture uses three types of tables: hubs (business key), links (relationship), and satellites (history of data). The Data Vault approach offers flexibility, scalability, and the ability to track historical information, conduct audits, and data lineage traceability by nature.

Why are data warehouses mostly built on top of a dimensional model?
Let’s take a healthcare clinical quality reporting (CQR) use case as an example to explore the data modeling approaches. In CQR, data has a hierarchical structure with the flow starting from the patient, their interaction with a healthcare provider, and medical procedures followed by diagnosis. Here, dimensional models work perfectly as they are capable of supporting hierarchies, drill-down analyses, and broad reporting capabilities.
Dimensional models offer flexibility in accommodating healthcare business changes and new data sources where the regulatory landscape is constantly evolving with new changes. Business Intelligence (BI) tools are compatible with dimensional models and help users to create a visualization of data and reports.
Choosing between dimensional model vs. Data vault
As we stated earlier, dimensional models and Data Vault data models have their different strengths and weaknesses.
The dimensional model excels at processing large amounts of complicated data, but it struggles to retain the lineage and integrity of the data when the nature of the source and data lineage change.
In contrast, the Data Vault model uses a hub-link-satellite structure that makes it easy to integrate and consolidate data from disparate sources while maintaining data quality. Though the Data Vault model has other advantages, it can be more complex to understand and implement and may require specialized skills.
You can see how Data Vault overcomes some limitations of the dimensional model below:
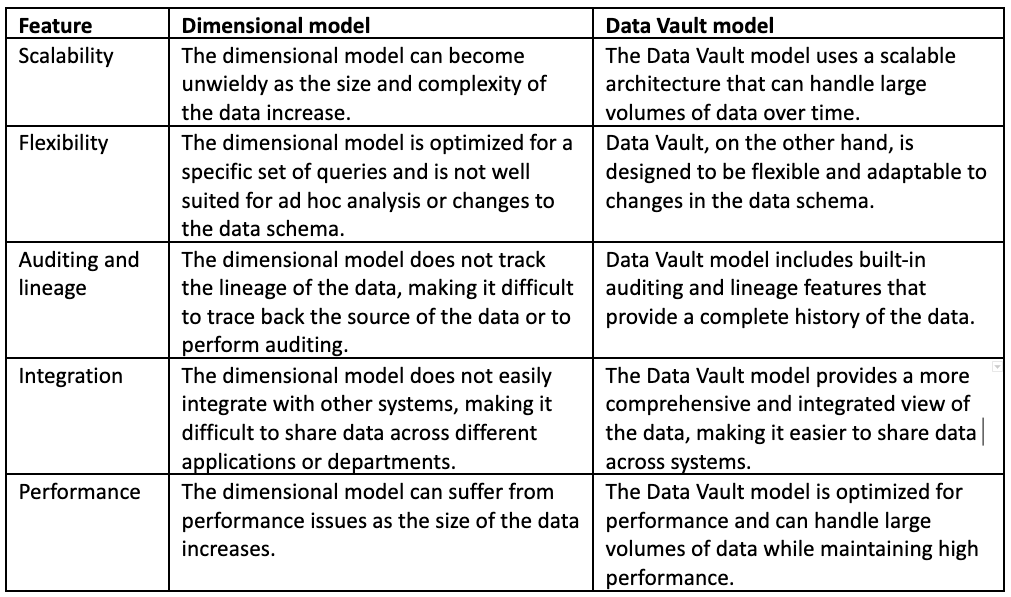
Why Data Vault can be a better choice for CQR and management data warehousing
In the CQR, data quality and accuracy are critical. Metadata in the Data Vault approach helps to track the origin and processing of data.
Often, data management professionals have to submit the data lineage report to prove the accuracy of clinical quality reporting. Some of this reporting goes to federal regulatory agencies (i.e The Drug Enforcement Administration (DEA), National Institutes of Health (NIH) and CDC) with related oversight, meaning any data quality issues (ex: misleading data set) could have the unintended result of potentially regulatory fines and penalties. Since a Data Vault preserves the source data pattern and layout, that can be tracked back when needed.
Also, the sources of CQR data warehouse changes frequently based on regulatory and environmental needs. Dimensional models are less malleable, requiring heavy transformation and multiple business rules applied to data before it can be loaded into the model, making this a complex process less conducive to the requirements of healthcare.
This gives a Data Vault the upperhand in this case. By design, a Data Vault is close to the data sources, making it easy to audit and track data lineage. Its design ensures data integrity and scalability in accommodating large, complex data integration scenarios as well as flexibility in adapting to business changes.
The Snowflake advantage: Using the Data Vault model with Snowflake
Snowflake’s query performance, currently in public preview, is one of its major advantages.
Its unique architecture, along with its columnar storage, enables quick and efficient querying of large volumes of data. This feature enables healthcare organizations to rapidly access the data they require for making informed decisions regarding clinical quality. Snowflake’s advantages include columnar storage, micro-partitioning, enhanced data sharing, and data protection. All of this adds more value and, if used as Data Vault 2.0, there are even more advantages.
Challenges associated with the Data Vault approach
When creating a reporting dashboard or conducting data analysis, data scientists or analysts often face the challenge of joining multiple tables, which adds more complexity.
Business users and business applications are often trained on traditional dimensional model presentation layers or data marts for their ad-hoc querying and data analysis. To serve business users and business applications, a data vault uses Point-In-Time tables and Bridge tables. To some degree, it resembles dimensional model fact tables attached to a data vault which causes confusion for business users and apps.
To solve this, developers create a presentation layer on top of the Data Vault to serve business tools, but this adds overhead in data processing and performance. The view is designed to imitate a dimensional model by combining satellite tables to create a dimension and combining hub tables to create a fact. This is often done using a view instead of duplicating the data in another dimensional model to prevent excessive copying and data duplication.
There is the possibility to use SAL (Same as Link) tables to solve some of these problems listed above, but still the Data Vault challenges (for example, data is far away from business applications expectation) will remain, and this needs to be addressed with another layer on top of the Data Vault.
Though both models have their own advantages and disadvantages, the best choice will depend on the specific needs and requirements of the organization, including data complexity, regulatory requirements, and data integration needs.
How can a hybrid model drive benefits?
If the hybrid model is your choice, this can help address the major challenges in the Data Vault methodology by combining the Data Vault and part of the dimensional model side-by-side:
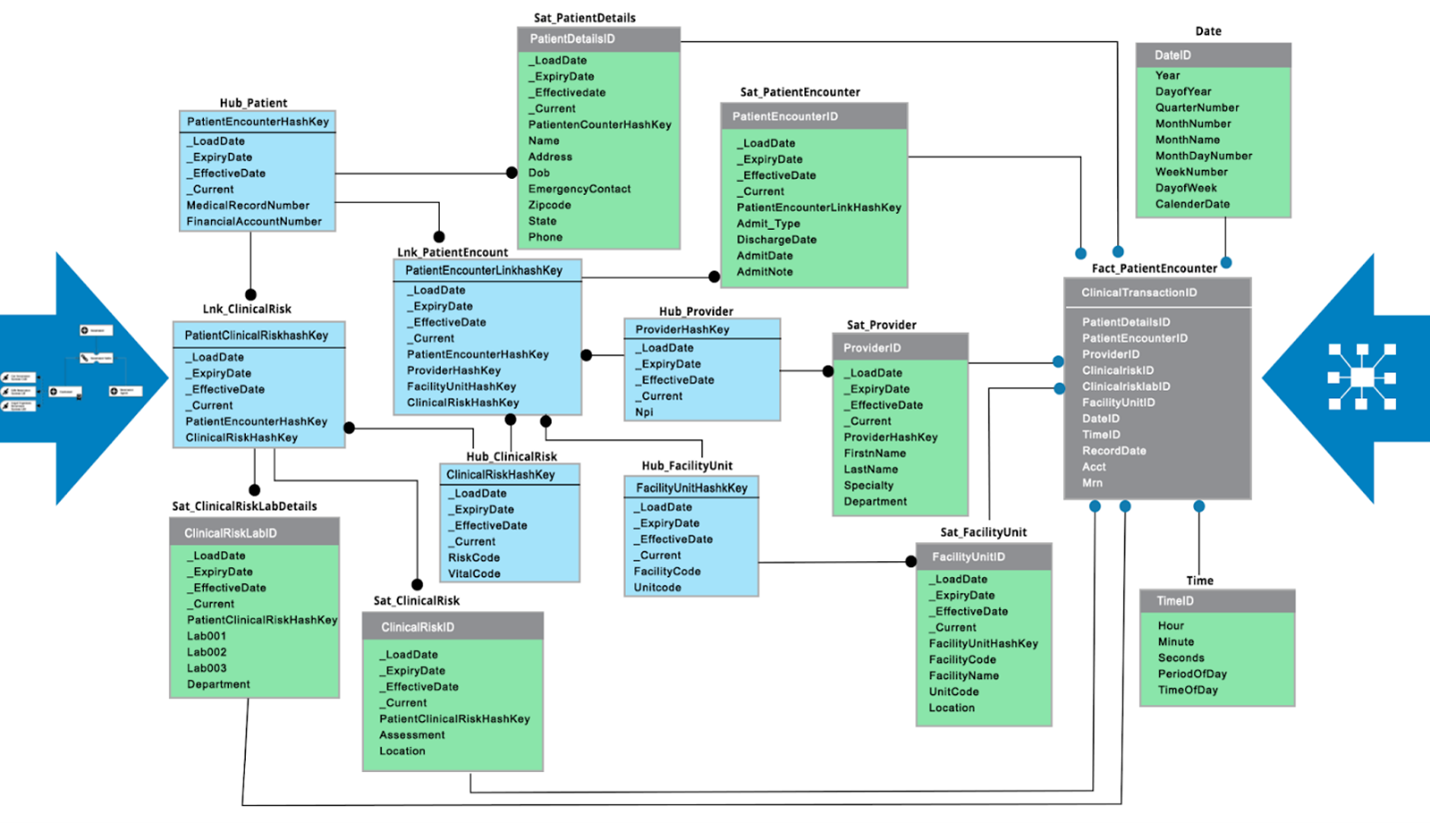
In the above example, data processes from left to right provide the Data Vault advantages, and those from right to left provide dimensional model advantages. Here the Data Vault satellite tables play a dual role as satellite tables and as dimensional tables. By combining the Data Vault and part of the star schema, the hybrid model delivers the benefits of both models. Also, the hybrid model eliminates most challenges associated with dimensional and Data Vault models.
From another perspective, a virtual dimensional model can be created on top of the Data Vault—Snowflake’s Materialized Views feature could help to achieve this. This would solve part of the problem (such as creating another data layer on top of the Data Vault) discussed earlier in this article, but it will not address the challenges associated with new and often changing data sources or new business rules introduced and data lineage tracking. The hybrid model solution combines the benefits of dimensional modeling (such as maintaining the calculated and transformed data as business applications requires) and Data Vault (such as a simple and clean data model to retain the data pattern as same as source and data lineage tracing).
Advantages of the hybrid model
- Structural information is separated from descriptive information to improve flexibility and avoid re-engineering in the case of change.
- It allows parallel loading of data and is suitable for processing large amounts of data.
- The metadata separation allows data engineers to set business rules even after the data is loaded into the data store. This allows for flexible data transformation.
- The data are not processed or filtered upon loading, but the hybrid model can still process large amounts of data.
- The hybrid model allows both business users and data engineers to interact with raw data by enabling them to change or create, for instance, metadata and data enrichment rules. Also, it is flexible, scalable, and agile.
- The hybrid model reduces the complexity of pulling and analyzing data sets for business applications.
- The fixed dimensions (for example, date, geography) and fact table are closely tied with the Data Vault tables such as the satellite table, which helps in troubleshooting and auditing.
Finding the right model
By leveraging the flexibility and adaptability of Data Vault with the clarity and simplicity of Dimensional models, organizations can optimize their data architecture to better support strategic decision-making and enhance operational efficiency.
Ultimately, data modeling is akin to mapping out the digital landscape of an organization, and the hybrid data model serves as a robust navigational tool. By adopting this versatile model, businesses can ensure they are better equipped to traverse the ever-evolving data terrain and unlock the full potential of their data resources. Embracing the hybrid data model is a strategic decision that can yield significant long-term benefits for businesses in today’s data-driven world.


