
PLEASE NOTE: This post was originally published in 2020. It has been updated to reflect currently available products, features, and/or functionality.
The Data Vault methodology can be applied to almost any data store and populated by almost any ETL or ELT data integration tool. As former Snowflake Chief Technical Evangelist Kent Graziano mentions in one of his many blog posts, “DV (Data Vault) was developed specifically to address agility, flexibility, and scalability issues found in the other mainstream data modeling approaches used in the data warehousing space.” In other words, it enables you to build a scalable data warehouse that can incorporate disparate data sources over time. Traditional data warehousing typically requires refactoring to integrate new sources, but when implemented correctly, Data Vault 2.0 requires no refactoring.
Successfully implementing a Data Vault solution requires skilled resources and traditionally entails a lot of manual effort to define the Data Vault pipeline and create ETL (or ELT) code from scratch. The entire process can take months or even years, and it is often riddled with errors, slowing down the data pipeline. Automating design changes and the code to process data movement ensures organizations can accelerate development and deployment in a timely and cost-effective manner, speeding the time to value of the data.
Snowflake’s Data Cloud contains all the necessary components for building, populating and managing Data Vault 2.0 solutions. erwin® by Quest® Data Vault Automation models, maps, and automates the creation, population, and maintenance of Data Vault solutions on Snowflake. The combination of Snowflake and erwin provides an end-to-end solution for a governed Data Vault with powerful performance.
Quest (the company behind erwin by Quest) and Snowflake formed a partnership to collaborate on developing and deploying an enterprise data platform within Snowflake using erwin data modeling, data governance, and automation tools. With that partnership, Quest has been able to create the automation necessary to build out a Data Vault architecture using the features and functionality of Snowflake.
The erwin/Snowflake data vault automation solution
The erwin/Snowflake Data Vault Automation Solution includes the erwin Data Intelligence Suite, erwin Data Modeler, and the Snowflake platform. The solution covers all aspects of the data warehouse, including entity generation, data lineage analysis, and data governance, plus DDL, DML, and ETL generation.
The erwin automation framework within erwin Data Intelligence generates Data Vault models, mappings, and procedural code for any ETL/ELT tool. erwin Data Modeler adds the capability to define a business-centric ontology or business data model (BDM) and use this to generate the Data Vault artifacts.
Let’s take a look at each aspect of the solution:
- Enterprise data modeling capabilities with erwin Data Modeler
- Data mapping capabilities with erwin Data Intelligence
- Bottom-up and top-down Data Vault automation
- Snowflake DML and DDL generation
- Automation framework for custom Snowflake orchestration
- Data governance of the Data Vault solution
Enterprise data modeling capabilities with erwin Data Modeler
You can use erwin Data Modeler to create BDMs or take a conceptual data model and create a logical data model that is not dependent on a specific database technology, which is a massive benefit to data architects. You can forward-engineer the DDL required to instantiate the schema for a range of database management systems. The software includes features to graphically modify the model, including dialog boxes for specifying the number of entity relationships, database constraints, and data uniqueness.
Figures 1 and 2 show a sample Snowflake BDM visualized in erwin Data Modeler and a generated Data Vault 2.0 model in erwin Data Modeler.
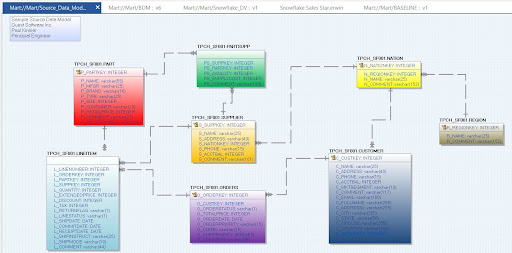
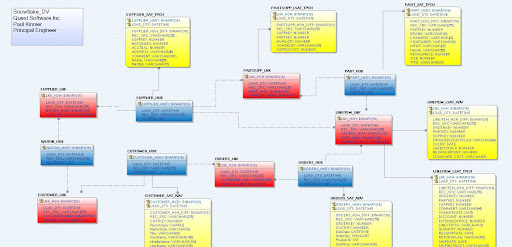
Data mapping capabilities with erwin Data Intelligence
Figure 3 details a mapping between a source (in this case a database table) to the BDM. The left side of the mapping defines the source and the right shows an individual BDM entity. The BDM contains the components necessary to identify the Data Vault objects to be generated. In this case, CUSTOMER contains a business key, foreign key relationships, and user-defined attributes that generate a stage object with hub and link hash keys as well as additional mapped attributes that drive satellite generation for the Data Vault model.

Figure 4 shows the automatically generated mapping detailing the physical load between the source table and the target stage table. erwin Smart Data Connectors automatically derive the physical lineage between the source fields and their target Data Vault 2.0 standard components, hub hash keys, link hash key, hash difference key, load date, and record source. The blue lineage flows show transformations that are taking place. In this example, MD5 hashes, system timestamps, and record source hard rules are generated and will be detailed in the generated Snowflake SQL later in this post.
There is a lot of analysis and debate on whether to utilize Hashing with a Snowflake Data Vault Implementation but I’ll save this discussion for a later post. The erwin Data Vault Automation Smart Data Connectors provide a configuration option to include Hashing or not. For the purposes of demonstrating the functionality, this blog post assumes Hashing is desired.
The rest of the blog post focuses on examples of the stage load.

Bottom-up and top-down Data Vault automation
You can use erwin Smart Data Connectors to build the Data Vault from the bottom up, which is the technical metadata-driven approach (see Figure 5). But creating the desired components in the Data Vault Architecture from the bottom up requires consistent naming conventions across different data sources and properly defined relationships and data types. Rarely do all of an enterprise’s source systems contain every component needed, leading to manual work to fix discrepancies. With bottom-up automation, you can build the Data Vault in an hour, but it might not be the best approach.
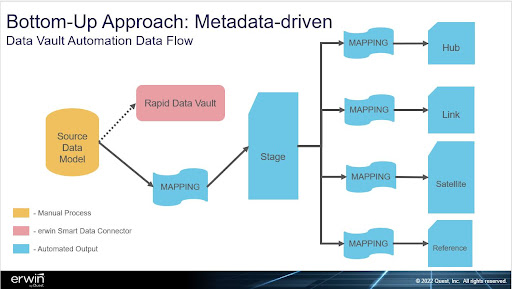
Alternatively, a business-driven, top-down approach enables you to automate the Data Vault with a mapping from the data source to a BDM (see Figure 6). With this approach, you can map any metadata regardless of its structure or naming conventions to the BDM to drive the Data Vault generation, which enables you to easily integrate multiple data sources into existing Data Vault data warehouses without refactoring.
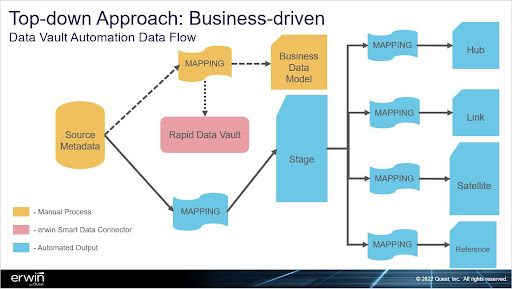
erwin offers Data Vault automation bundles that can include bottom-up or top-down automation, or even a combination of the two to meet acceleration needs. With proper tagging of well-defined data sources, you can apply bottom-up automation to accelerate delivery, or you can map less-defined data sources to the BDM to properly define the target Data Vault structures.
Snowflake DDL and DML generation
erwin Smart Data Connectors automate model and mapping generation. In addition, they manage physical artifacts from technology-specific DDL, DML, and ETL. erwin handles all data types for any technology with documented data type conversion files, which are installed in the Smart Data Connectors based on each individual use case.
Figure 7 shows forward-engineering of the CUSTOMER stage DDL specific to Snowflake ANSI SQL standards. You can customize it to incorporate stored procedures, parameters, Liquibase syntax, grant statements, and more. The Data Vault DDL Smart Data Connector automatically recognizes any Data Vault object in the generated models by table class (for example, STG, HUB, LINK, and SAT) and produces the DDL structures for each, also enabling you to use any desired Data Vault naming conventions in the Data Vault architecture.

Figure 8 demonstrates forward-engineering the CUSTOMER stage load mapping into a templatized stage load DML statement. The generated scripts automatically recognize and handle all the Data Vault 2.0 best practices in hash-key calculations, load-date timestamp, record source, and sequence ID generation defined in the source-to-target mappings.

An automation framework for custom Snowflake orchestration
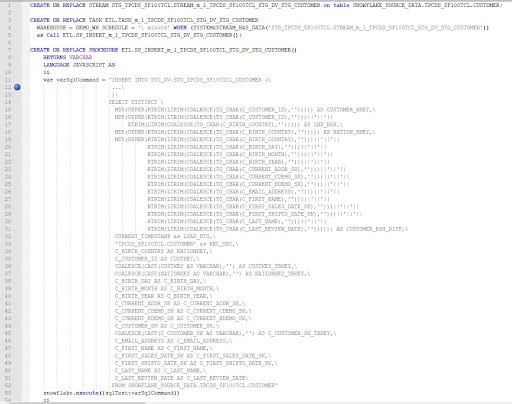
You can orchestrate the generated Snowflake SQL in several ways. Specifically, you can configure erwin Smart Data Connectors to create wrappers around the generated Snowflake SQL for any SDK for the orchestration requirements. As most Snowflake users know, Snowflake can orchestrate its data processing natively with the use of streams and tasks. Figure 9 shows the generated Snowflake SQL from the previous example with the additional commands to create the stream and task for the stg.STG_LINEITEM load as a wrapper. A best practice from Data Vault 2.0 is to run the Raw Vault loads in parallel. By adding the additional tasks for the hub, link, and satellite loads to the stream, you enable Snowflake to natively orchestrate the tasks in parallel.
Data governance of the Data Vault solution
erwin Data Intelligence comes with enterprise-level data lineage-analysis and impact-analysis reporting to ensure that all enterprise metadata is documented from both the technical and business aspects. Figure 10 details a single business key’s lineage through the staging and raw vault layers of the generated Data Vault.

Automated Data Vault processes ensure the warehouse is well documented with traceability from the marts back to the operational data, which enables you to investigate issues and analyze the impact of changes faster.
Additionally, with erwin Data Intelligence, data governance teams can further leverage automation and other stewardship capabilities to ensure data vault assets are framed with business context—defined terminology, business rules, and policy. And that all data users have the immediate discovery capabilities, information, and interactive visualizations to quickly understand assets, their relationships, and the governance provided for their use.
Conclusion
Using erwin Data Vault Automation for Snowflake can reduce the time to value of your Snowflake Data Vault implementation, gives you a fully documented and auditable set of metadata for enterprise data governance, and provides the basis for agile enhancements as new requirements emerge.
Additional Data Vault resources
DataVaultAlliance.com and Building a Scalable Data Warehouse with Data Vault 2.0 by Dan Linstedt and Michael Olschimke provide the tools for the data warehouse architecture and a fully defined data warehouse solution, with answers to questions regarding all aspects of data warehouse implementations, including things such as team building, Agile methodology, designs, definitions, terminology, consistency, and automation.
The Elephant in the Fridge by John Giles is another great resource with information to ensure Data Vault success. In his book, Giles talks about the importance of data modeling for building a business-centered ontology. This was the original inspiration for the top-down Data Vault automation approach.