
You may ask, “So, how does Snowflake do data warehousing differently than any other solution available? Glad you asked. The answer is, architecture.
This blog details five characteristics about our multi-cluster, shared data architecture that are reason enough to move your on-premises data warehouse and analytic workloads to the cloud. If you already have a data warehouse in the cloud, but it’s a “cloud-washed” data warehouse, the imperative is the same.
The issue with most platforms in the cloud
For the last decade, you’ve likely heard from various technology companies that the best and most cost-effective way to quickly create insights from a mix of data, especially a mix of multi-structured data (JSON, Avro, tables, etc.), is to move the analytics to the data. Figure 1 represents the typical MPP or cluster architecture. The theory goes, if you tie data and compute resources together and spread them across commodity hardware through massively parallel processing (MPP), or perhaps Hadoop on distributed servers, analytics would be swift and low cost.

However, the passage of time and well publicized user frustrations have proven that tying compute to storage creates a number of negative business consequences. Tuning, for one, becomes a chore. Scaling the environment is disruptive, query concurrency is limited and supporting separate workloads simultaneously (e.g., new data loading and BI queries) is nearly impossible. In addition, accessing data in order to query it frequently requires engaging your organization’s data engineering professionals with the Java, Python or Scala language skills necessary to extract the data from the clusters.
But going through the data engineering team often means delays. It’s not the sort of process to have in place if you want to be a nimble, fast-moving, data-driven organization. Further, executives would much rather have data engineers focused on developing new products and services.
Now, let’s dive into Snowflake’s multi-cluster, shared data architecture and the reasons why you’ll love it.
Reason 1: Non-disruptive scaling
Snowflake was founded on the belief that tying compute and storage together is not an effective approach for limitless, seamless scaling. Snowflake’s multi-cluster, shared data architecture (See Figure 2), separates compute resource scaling from storage resources, thus enabling seamless, non-disruptive scaling.

In Snowflake, while queries are running, compute resources can scale without disruption or downtime, and without the need to redistribute/rebalance data (storage). Scaling of compute resources can occur automatically, with auto-sensing. This means the Snowflake software can automatically detect when scaling is needed and scale your environment without admin or user involvement.
For storage, you can scale resources to virtually any capacity without the extra cost of adding unnecessary compute resources. Both resource groups can scale up or down – including suspend in the case of compute resources. With Snowflake, you can easily and seamlessly customize resources to the specific needs of your organization.
Traditional MPP clusters in the cloud may require you to place your database into read-only mode or may require you to take the cluster offline. With other architectures, if you are able to scale compute “automatically”, you still have to manually engage the system to tell it to scale. This is not seamless.
Reason 2: Physical separation with logical integration
Other cloud data warehouse offerings are beginning to separate compute and storage. But, from a cloud data warehouse perspective, separating compute and storage layers is not enough. If all that was accomplished was the separation of compute and storage, you’d have a topology that resembles the server plus storage networking (either LAN or SAN) topologies typical of on-premises data centers that, in some cases, date back to the 1990s. In these environments, you typically have to separately build in capabilities such as high availability, data protection, data retention, metadata management and security. This is more complex and costly.
Porting an on-premises environment to the cloud leaves you with the same issues. Plus, relying on what a cloud provider inherently offers won’t deliver all of the robust capabilities that will satisfy a range of requirements. The needs of a large enterprise will be different than a SMB.
As shown in Figure 2, Snowflake’s multi-cluster, shared data architecture shines because compute and storage resources are physically separate, but they are logically part of a single, integrated and modern cloud-built data warehouse system. The architecture includes built-in cloud services such as transparent provisioning of resources, automatic metadata management and resilience (e.g., data backup/retention and node failure protection). A
single integrated system eliminates the cluster-building efforts you must make to have separate layers work together.
Reason 3: Process separate workloads concurrently against consistent data
When it comes to supporting multiple, separate workloads with architectures that are not cloud-built, one of two things generally happen. One, you are unable to isolate workloads because most architectures are single cluster – workloads share resources. This leads to a fight for resources and poor performance, which means you may have to resort to off-hours scheduling. Or, you’ll separate concurrent workloads to different clusters but there will be a risk of data inconsistency as separate clusters independently make changes to data. This can result in dirty reads and inaccurate analytics.
To prevent this, you’ll have to apply some level of overhead in the form of external metatable or change-table management and/or syncing.
Snowflake’s multi-cluster architecture enables you to support as many separate workloads as you can dream up. You can provide each workload its own compute engine and rest easy. We take care of ensuring data consistency (a single source of truth) with ACID-compliant integrity.
Reason 4: Quickly load, transform and integrate JSON and other semi-structured data
Snowflake’s architecture allows quick consolidation of all your diverse data onto one platform, enabling analytics against larger and broader data sets. The more you can execute analytics against consolidated data, the more complete insights you can develop. Making this possible is our patented VARIANT data type. Snowflake loads semi-structured data as a VARIANT data type, enabling you to quickly query JSON in a fully relational manner (See Figure 3.).
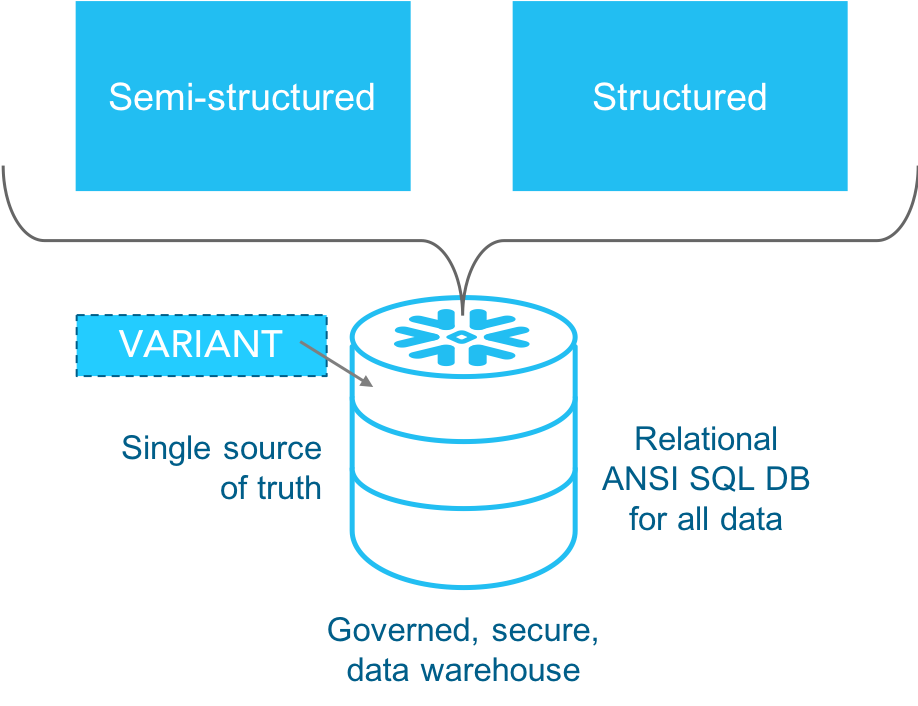
Other platforms may require multiple data stores and query grids to handle analytics and data warehousing across mixed data. This is a more complex data architecture approach.
Reason 5: Live, secure data sharing
Snowflake’s multi-cluster shared data architecture enables fast access and analytics for program managers, marketing teams, executives, business analysts and data scientists. You can also share data across your organization and outside your company to include your ecosystem of business partners and any external data consumers (See Figure 4.).
You can accomplish this with granular, secure access and secure views of your data with no data movement involved. Enabled by comprehensive metadata management, Snowflake’s architecture allows you to specify the live data you want share. You simply grant access and you can share an entire database or just a slice of one with access to data that is always up to date.

Other approaches to data sharing will limit you to sharing an entire database or will require you to engage in laborious efforts to encrypt and transmit data, including the onus of separating private and sensitive data. Making matters worse, data be will be stale the moment an element changes on your end.
Of course there’s more
These are just five reasons why you’ll love Snowflake’s multi-cluster, shared data architecture in the cloud. Read more about the many other reasons why our customers chose Snowflake. Stay tuned. In future blogs, we’ll compare Snowflake’s architecture to other approaches such as Lambda architectures, and more.