

HISTÓRIAS DE CLIENTES
Sanofi agiliza a análise de dados clínicos reais com o Snowpark
Ao substituir a solução Spark gerenciada pelo Snowflake, a Sanofi consegue acelerar o processamento de dados, reduzir o custo total de propriedade e garantir a conformidade e a governança de dados.
PRINCIPAIS RESULTADOS:
50% de melhoria no desempenho em comparação com a solução Spark gerenciada anterior
100 MILHÕES de dados de pacientes por grupo processados, em média, em apenas quatro minutos.


Setor
FarmacêuticoLocal
Bridgewater, NJ, EUAEm busca dos milagres da ciência
Nos Estados Unidos, a Sanofi, com sedes em Bridgewater (NJ) e Cambridge (MA), emprega mais de 13.000 profissionais em todo o país. Há quatro unidades de negócios na Sanofi U.S.: cuidados especializados, vacinas, medicamentos gerais e cuidados de saúde ao consumidor. Em todo o mundo, mais de 100.000 colaboradores da Sanofi buscam formas de melhorar a vida das pessoas.
Destaques da história
Dados clínicos reais para a comunidade médica: a Sanofi está desenvolvendo um app para web responsivo, construído sobre a plataforma Snowflake. Nele, os profissionais de saúde poderão analisar dados clínicos reais para avaliar os benefícios ou os riscos terapêuticos.
Do Spark gerenciado para o Snowpark: ao migrar da sua solução Spark gerenciada anterior, a Sanofi conseguiu uma melhoria de 50% no desempenho, eliminando desafios, como administração, configuração e simultaneidade.
Serviços profissionais: o Snowflake Professional Services e o Snowpark Migration Accelerator, uma ferramenta automatizada de conversão de código, ajudaram a converter o código PySpark em Snowpark, agilizando a migração.
Adicionando escalabilidade para dar suporte a uma aplicação de dados clínicos reais
A Sanofi vem trabalhando na tarefa de criar uma plataforma de processamento de dados para toda a empresa. O objetivo é auxiliar a comunidade médica em suas necessidades analíticas, especialmente no contexto da descoberta de novos medicamentos. O foco do projeto é a criação de um app para web intuitivo para profissionais de saúde inserirem filtros de consulta relacionados a doenças, medicamentos ou procedimentos e identificarem informações de pacientes que atendam a critérios específicos para analisar mais rapidamente dados clínicos reais e avaliar os benefícios ou os riscos terapêuticos.
O app processa bilhões de registros para gerar os insights analíticos de que usuário precisa. Para viabilizar isso, a arquitetura de dados anterior da Sanofi utilizava um mecanismo Spark gerenciado como camada de processamento. No entanto, a equipe de dados enfrentou vários desafios com a implementação e a manutenção manuais do Spark: problemas de escalabilidade de recursos, falhas frequentes no pipeline causadas por recursos computacionais limitados, problemas de simultaneidade durante picos de uso e dificuldades na movimentação de dados entre várias plataformas.
Para melhor atender os usuários, a equipe de dados da Sanofi decidiu reformular seu mecanismo analítico. Suku Muramula, Architecture and Data Engineering Lead, afirma: "Como já estávamos utilizando o Snowflake para diversas tarefas de processamento de dados, vimos a oportunidade de explorar o Snowpark como uma possível solução para atender às nossas futuras necessidades de processamento de dados".
Reformulando o mecanismo analítico da Sanofi no Snowflake e no Snowpark
A Sanofi escolheu o Snowflake e o Snowpark, o conjunto de bibliotecas e runtimes para implementar o código Python com segurança para uma das reformulações do seu mecanismo analítico. A separação do armazenamento e da capacidade de processamento, a manutenção quase nula e a escalabilidade sob demanda do Snowflake permitiram à Sanofi lidar com eficiência com o aumento das cargas de trabalho e dos volumes de dados sem comprometer o desempenho, tudo isso mantendo os custos em um nível ideal.
Ao iniciar a migração, a equipe de dados priorizou uma arquitetura focada em serviços. O objetivo era construir um sistema sólido e eficiente com serviços independentes, aprimorando o isolamento de falhas para garantir que problemas em um serviço não afetassem todo o sistema. Isso foi fundamental para agilizar o processo de migração de um cluster Spark gerenciado para o Snowflake, pois minimizou as interrupções do app.
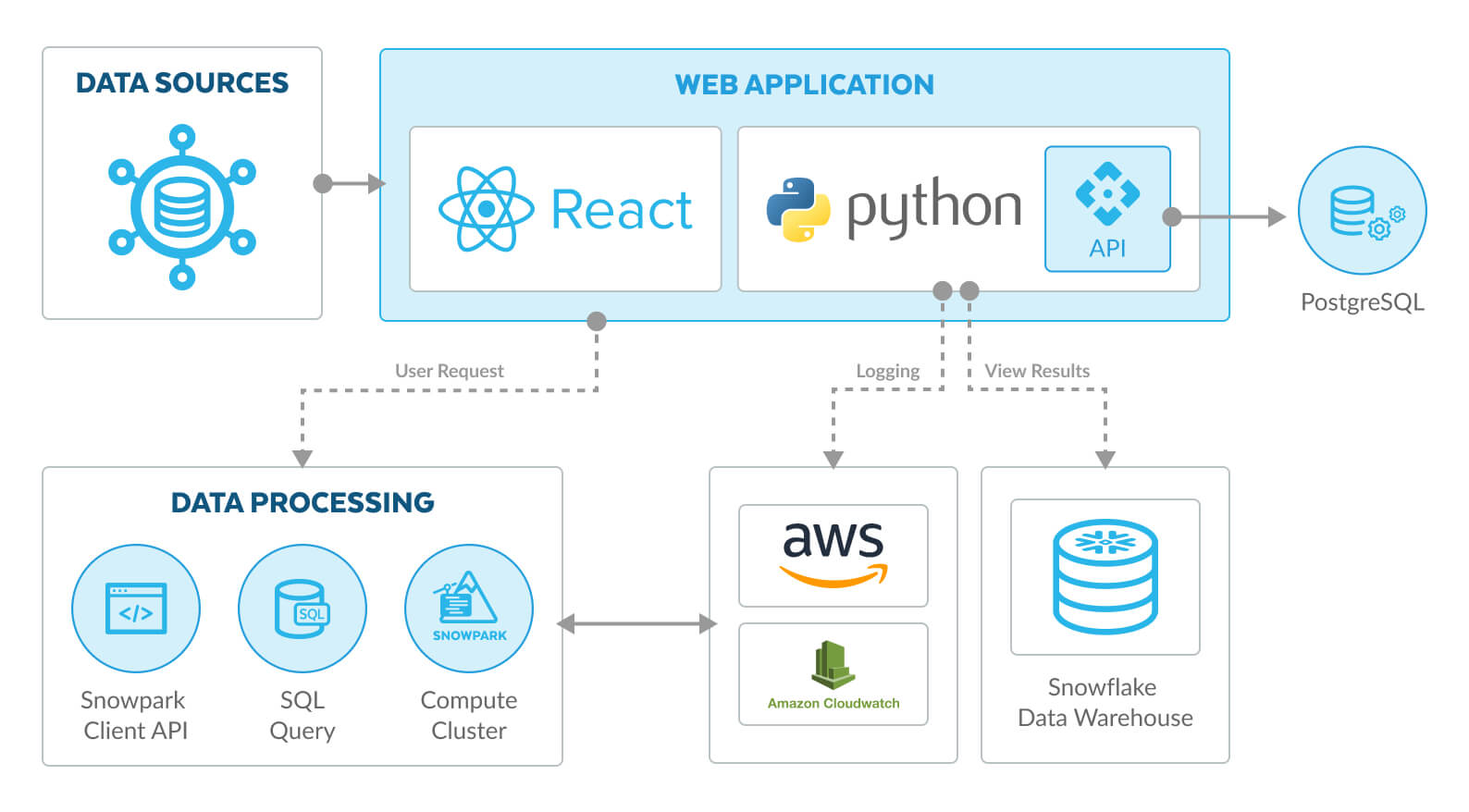
Figura 1. Arquitetura atual com o ecossistema Snowflake e Snowpark.
Conforme mostra a Figura 1, em vez de usar pipelines complexos, a nova arquitetura simplifica o processamento de dados, mantendo os dados e a plataforma de processamento juntos com o Snowflake e o Snowpark. Isso reduziu a latência e melhorou o desempenho geral, permitindo um processamento e uma análise de dados mais rápidos.
Os recursos do Snowflake para governança de dados, incluindo permissões granulares e controle de acesso baseado em funções, oferecem controle eficaz sobre dados e bibliotecas. Isso garante a segurança dos dados e a conformidade com as políticas.
Além de melhorar a velocidade de processamento de dados, em nosso setor é fundamental proteger os dados proprietários intelectuais e garantir a segurança do algoritmo e a governança eficaz. Usar o Snowpark como a camada computacional para código Python dentro da plataforma de dados Snowflake nos permite eliminar a necessidade de transferir dados e dar aos nossos administradores uma autoridade mais completa sobre todos os dados e as bibliotecas."
Suku Muramula
Architecture and Data Engineering Lead, Sanofi
Obtendo 50% de melhoria no desempenho com o Snowpark
A Sanofi enfrentou vários desafios com a arquitetura anterior ao usar um mecanismo Spark gerenciado como camada de processamento. A implementação manual do mecanismo exigia atualizações manuais sempre que novos recursos eram adicionados ou alterações eram feitas no pipeline de back-end. Essa maior necessidade de coordenação e dependência manual em todos os processos resultava em um aumento no tempo de execução do pipeline do início ao fim.
A criação e a configuração de um cluster Spark também exigia muitos recursos. "Notamos que o cluster não era dimensionável e exigia configuração manual para iniciar uma instância maior e executar consultas complexas ou intensivas, o que gerava problemas de desempenho no pipeline", explicou Ratan Roy, Data Engineer da Sanofi. "Também não havia otimizações automáticas em vigor, e o processamento exigia uma quantidade enorme de memória."
A equipe de dados enfrentou muitos cenários de falha ou atraso no pipeline devido à falta de recursos computacionais. Como o ambiente Spark gerenciado era compartilhado, os recursos de computação estavam disponíveis com base na disponibilidade do cluster Spark, e não sob demanda, com base nas solicitações.
A plataforma web, utilizada pela comunidade de usuários médicos, apresentava problemas de simultaneidade quando vários usuários interativos faziam solicitações ao mesmo tempo para executar programas do app. Considerando a grande exigência de processamento de mais de um bilhão de registros pelo cluster Spark, o tempo médio de resposta analítica para uma solicitação era de cerca de 15 minutos durante os horários de pico.
Enquanto na plataforma Snowflake, a separação entre a capacidade de processamento e o armazenamento de dados é nativa, a solução Spark gerenciada anterior não possuía uma camada de armazenamento de dados integrada. O processamento de dados precisava ser realizado separadamente, exigindo configuração, preparação e movimentação de dados adicionais entre várias plataformas, o que era demorado.
Ao decidir migrar para o Snowpark e a plataforma Snowflake, a equipe de dados da Sanofi realizou uma análise de benchmark constatando uma melhoria geral de 50% no desempenho em comparação ao cluster Spark gerenciado, e um menor custo total de propriedade (total cost of ownership, TCO) geral. "Conseguimos processar dados em grande escala no ambiente Snowflake, o que nos dá maior agilidade e velocidade a um custo menor", comenta Ratan. "Com o Snowflake como armazenamento central de dados e o Snowpark como mecanismo de processamento, reduzimos os custos de movimentação de dados, o que resultou em um desempenho mais rápido e menor custo de processamento."

“Todo o nosso algoritmo e pipeline de engenharia de dados é desenvolvido usando código Snowpark e Python. O Snowpark processa todas as consultas de dados na plataforma Snowflake.”
Ratan Roy
Engenheiro de dados, Sanofi
Trabalhando em parceria com o Snowflake Professional Services
Ao decidir migrar do Spark para o Snowpark, a Sanofi contou com a equipe de Snowflake Professional Services como parte essencial desse processo de transição.
"Na verdade, ficamos muito satisfeitos com a experiência que tivemos com o Professional Services. A equipe nos apoiou desde o primeiro dia, facilitando o gerenciamento e a identificação do que é necessário para uma migração bem-sucedida", disse Muramula. "A avaliação de prontidão deles foi simplesmente excepcional, e eu diria que nos ajudou a obter insights valiosos sobre o processo de migração, além de garantir que estivéssemos bem preparados para estabelecer os recursos e identificar eventuais falhas no processo", afirmou Muramula.
O Snowpark Migration Accelerator, uma ferramenta automatizada de conversão de código, converteu o código PySpark em Snowpark, agilizando todo o processo de migração. "Isso fez toda a diferença e nos permitiu avançar com agilidade, mantendo a integridade do código. De modo geral, recomendo muito que as pessoas trabalhem com o Snowflake Professional Services durante processos desse tipo", afirma Muramula.
Simplificando o compartilhamento e a ciência de dados
Com a aplicação atual, a equipe de dados da Sanofi pode se concentrar em um número limitado de fontes de dados. No entanto, a empresa planeja expandir para mais fontes de dados visando permitir que a comunidade médica pesquise outras doenças e tratamentos.
"À medida que avançamos, nossos procedimentos de coleta e processamento de dados continuam a evoluir. Precisamos lidar com bilhões de registros adicionais para melhorar nossos recursos analíticos", diz Muramula. "Estamos confiantes de que a plataforma Snowflake continuará sendo a nossa melhor opção para garantir escalabilidade dinâmica, solidez e para nos adaptarmos com facilidade ao cenário em constante expansão."

