
MAR 20, 2025|5 min read

Open data lakehouse platforms, built on formats such as Apache Iceberg, offer the flexibility to use multiple compute engines on the same data managed by an Iceberg catalog. When onboarding a new data platform like Snowflake, data architects have to make a key decision about how and where to manage the storage access for the underlying data, based on their organization’s security and governance policies. Primarily, the choice is to either manage the storage access within their database engine of their choice or centralize it in their catalog. For customers who choose to centralize governance in the catalog, our goal was to make integration seamless, reliable and secure. This required solving key engineering challenges, and this post explores how we changed Snowflake’s storage subsystem to accomplish it.
When integrating an engine such as Snowflake, architects are faced with two distinct choices for managing storage access. Each choice has their valid use cases based on an organization's lakehouse setup and requirements.
This model involves configuring your storage credentials directly within the database engine. A user explicitly configures and manages the credentials (like a cloud IAM role) required for Snowflake to access external cloud storage. This role is then associated with an EXTERNAL VOLUME object in Snowflake, which offers granular, engine-level control and can be ideal for organizations that prefer to manage storage access policies alongside their database configuration. However, it also means that storage security administration is split across the cloud provider's console and the database engines in the lakehouse, which can require additional scripts to keep them in sync.
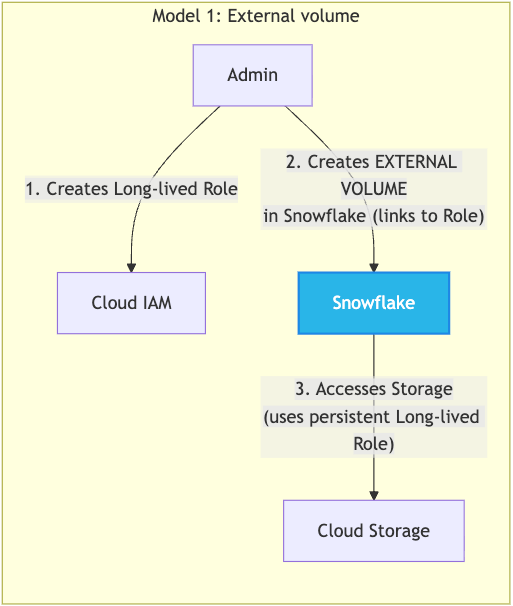
This model leverages the Iceberg catalog as a centralized security broker, delegating the responsibility of providing storage credentials to all the query engines. The query engine (Snowflake) holds no long-term credentials. Instead, it requests temporary, narrowly scoped credentials from the catalog on a per-table basis. This approach centralizes storage access control and ensures policies are consistently enforced, regardless of the query engine.
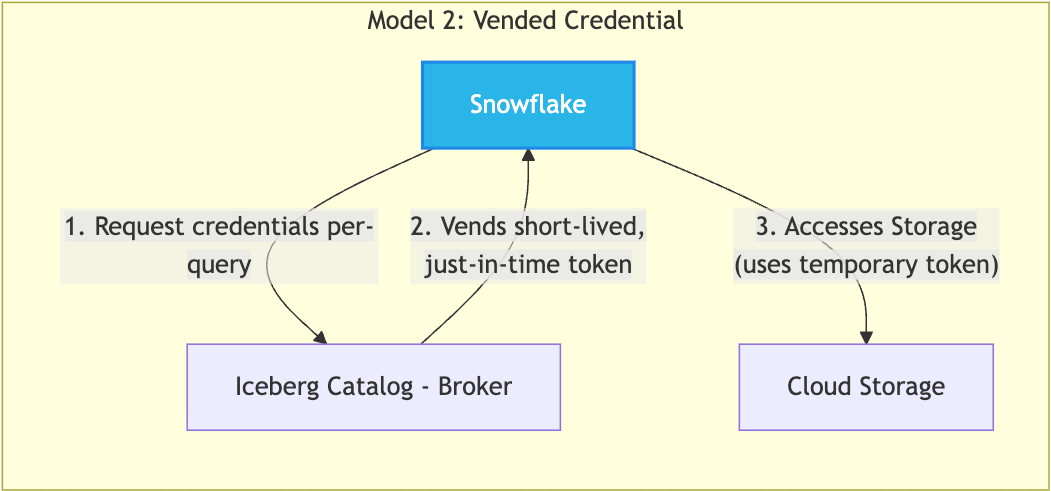
Customers could have valid preferences for either model based on their lakehouse setup. The catalog-centric model offers centralized governance, but it presents a few technical hurdles: How could an engine request credentials on demand without it being slow, complex and brittle? What happens when a temporary token expires in the middle of a long-running query? What if tables within the catalog are located across many storage locations? We needed to engineer a solution that delivered the benefits of vended credentials without compromising on performance or user experience while addressing all the above challenges.
The first challenge was to reduce the burden on the users to manage the creation of multiple volume objects and the volume assignment to Iceberg tables, which could become challenging as the number of tables increase. To address this issue, we changed our architecture to introduce a hidden, per-table volume. This internal volume is automatically created and managed by Snowflake for each Iceberg table and uses vended credentials. The volume’s lifecycle is tied directly to the table, which means it is created when the table is created and destroyed when it is dropped.
The catalog-vended credentials are scoped and temporary by nature, which ultimately leads to a critical question: What happens to a 10-hour query when its token expires after 30 minutes? To solve this problem, the hidden volume is designed for calling the external catalog's API to fetch fresh, temporary storage credentials. To enable uninterrupted long-running queries, Snowflake's caching framework monitors credential expiration and proactively calls the catalog to refresh the token before it expires. This automatic, seamless refresh mechanism manages the entire lifecycle of temporary tokens in the background, making the temporary nature of the credentials transparent to the user and the query.
When creating tables on a catalog that vends credentials, Snowflake cannot automatically determine the creation location because an external volume is not used. Consequently, the responsibility lies with either the catalog to provide a default location for table creation, or the user to explicitly specify a location or override the default using the BASE_LOCATION parameter.
For writing data files and metadata during DML and DDL operations, Snowflake relies on the storage location directly from the table's Iceberg metadata, such as the location field, as well as the table properties for correct placement of the files. This eliminates any need for manually specifying or synchronizing locations between the catalog and the database engine.
Solving these core engineering challenges allows the customers who choose to centralize their storage policies in the catalog to gain operational simplicity, as well as the full platform capability of Snowflake. For data teams, this means:
No EXTERNAL VOLUME objects to create, manage or synchronize. The setup is simplified to a single parameter ACCESS_DELEGATION_MODE in the CATALOG INTEGRATION to declare the intent to use storage credentials vended by the catalog.
Reduced complexity in figuring out how to assign and manage lifecycle of volumes across different tables or schemas.
Seamless storage credential scoping and refreshes for the table.
The following table highlights some of the trade-offs between choosing the database engine-managed credentials and catalog-managed credentials on the Snowflake platform:
| Feature/Task | Database engine-managed credentials (external volume) | Catalog-managed credentials (vended credentials) |
|---|---|---|
| Credential management | Users manage long-lived IAM roles in Snowflake. Can add additional configurations on external volume, such as allowing or restricting writes to the volume. |
The Iceberg catalog manages and issues short-lived, temporary tokens on demand. |
| Snowflake configuration | Requires two interdependent objects: EXTERNAL VOLUME and CATALOG INTEGRATION. |
Requires only a single CATALOG INTEGRATION object configured for vended credentials. |
| Setup complexity | The Snowflake admin needs to manage the access to the cloud providers and set up the external volume with right privileges. | The Snowflake admin just points to a preconfigured catalog. The access and authorization to cloud providers needs to be managed by the catalog admin. |
| Flexible storage buckets | Does not support tables in the same catalog being in different storage buckets since CLD could be mapped to a single volume. | Supports tables in the same catalog being in different storage buckets. |
Managing storage access remains a key governance decision in any open data lakehouse. While architects can choose between engine-managed or catalog-managed credentials, we ensure that Snowflake works well with either choice.
We enabled Snowflake to work with catalogs that centralize storage governance based on an internal architecture of hidden, per-table volumes and just-in-time credential refreshing to solve the associated challenges. Our engineering solution abstracts away complexity, enabling a reliable, simple and powerful read/write lakehouse for our customers.
The easiest way to experience this is with catalog-linked databases (CLDs), which map the remote catalog as a first-class database in Snowflake. For complete, vendor-specific setup instructions for catalogs from Polaris, Databricks, AWS and more, please check out our official documentation.
