
MAR 20, 2025|5 min read

An open ecosystem needs an open source catalog. Apache Polaris™ (incubating), an open source catalog for Iceberg tables, is now expanding its support to Delta Lake. This enhancement helps data teams unify fragmented data more effectively while continuing to enjoy a single, vendor-neutral catalog for managing access control and read/write interoperability.
In this blog we’ll cover why organizations need a unified catalog, how Polaris’ support for Delta tables works, and how to get started with Polaris.
A data catalog serves as the central registry for a table’s metadata. It manages transactions and table state, as well as access controls and read/write interoperability. As organizations standardize from other formats, like Delta Lake and Apache Hudi™, onto Apache Iceberg™ they often end up managing multiple catalogs — leading to duplicated efforts and unnecessary complexity. This is because each table format has its own protocols and metadata requirements.
Even with Iceberg V3, Iceberg and Delta Lake, for example, each has its own unique way of tracking table state, schema evolution and data files.
Delta Lake relies on a transaction log that records every change to the table. The transaction log is a series of JSON files in a _delta_log directory. The log is updated with every add, delete and update operation. This means the log acts as the single source of truth for the table's current state and its history. The role of a Delta Lake catalog, like Hive Metastore, AWS Glue Data Catalog or Unity Catalog, is to maintain pointers to the transaction logs for various tables.
Iceberg, on the other hand, uses a tree of immutable metadata files. These include manifests, manifest lists and table metadata files. Each commit creates a new set of metadata files, and the Iceberg catalog handles the atomic swap from the previous snapshot to the new one. It also maintains pointers to snapshots for many tables.
With different catalogs for different formats, users likely access Delta and Iceberg tables from two distinct places, with separate sets of access controls — an all-around cumbersome and inefficient experience.
Apache Polaris addresses this challenge by providing a unified, open source and vendor-neutral catalog that can manage both Iceberg and Delta Lake tables, as well as tables of Parquet or JSON files. This reduces the need for separate catalogs and simplifies data discovery and access control.
Unified access across formats: Catalogs and namespaces can contain a mix of Delta and Iceberg tables.
Unified access controls across formats: Access controls can be applied across Delta and Iceberg tables at catalog, namespace or table levels.
Read and write interoperability: Polaris APIs are open source, providing flexibility to add read/write support for other engines.
The core of this new feature lies in the introduction of "generic” tables within Polaris. These generic table entities allow Polaris to manage non-Iceberg table formats, like Delta Lake and Apache Hudi™, through a new set of REST APIs. These new endpoints are designed for managing tables beyond what’s supported in the Iceberg REST catalog specification, and they support standard table operations such as list, create, read and drop tables.
For Apache Spark™ users, a new Spark plugin, capable of handling both Iceberg and generic table API requests, is available. This plugin enables Spark to communicate with these new Polaris APIs and manage both Iceberg and Delta Lake tables in one place. When loading a table, if the client isn’t able to find a matching Iceberg table it’ll then attempt to load a matching generic table.
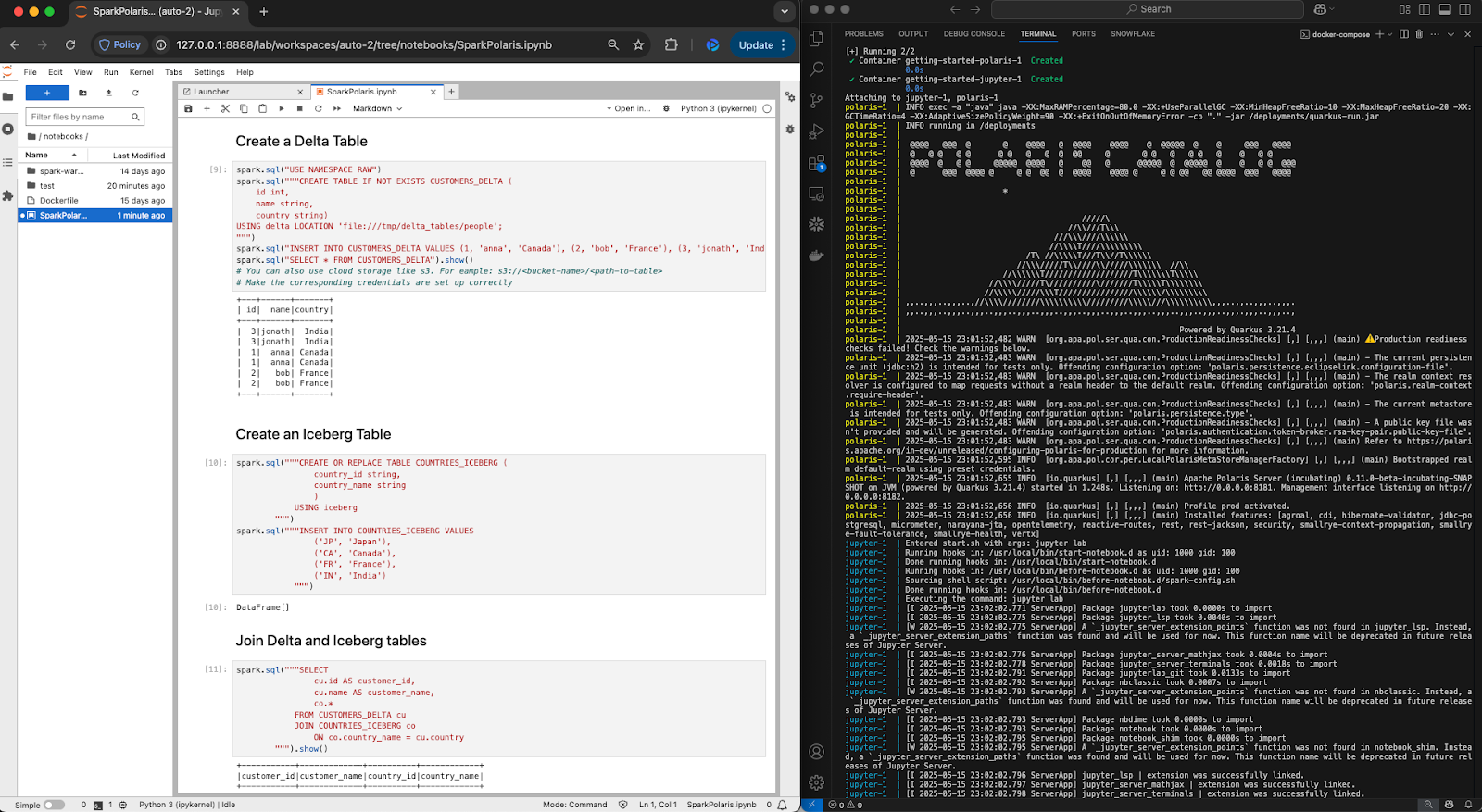
Generic tables can be created by providing a name, format (e.g., "delta," "parquet"), properties (like location), and an optional description. Below is an example of how to create a Delta table in Polaris with Spark SQL, where the table location could be Amazon S3, Google Cloud Storage, Azure Blob Storage or Azure Data Lake Storage Gen2.
CREATE TABLE IF NOT EXISTS my_table (
id int,
name string
)
USING delta
LOCATION 's3://bucket/some_catalog/delta_namespace/my_table';Polaris also reuses existing table privileges for generic tables, including TABLE_CREATE, TABLE_DROP, TABLE_LIST and TABLE_FULL_METADATA. This separation between Polaris’s privilege model and table APIs allows for a unified set of access controls that extend to any table format that Polaris supports.
This new capability unlocks important use cases:
Simplifying migrations: Organizations transitioning from Delta Lake to Iceberg can use Polaris to manage both formats in one place during the migration process.
Enabling cross-platform intelligence: Polaris facilitates analytics and AI across different platforms by providing a unified view of Iceberg, Delta Lake and other data sets.
Unifying data governance: Organizations can enforce access control policies across all their data lake tables, regardless if it’s in Iceberg, Delta Lake or other formats.
Want to try it out? Check out this guide to creating Iceberg and Delta tables in Polaris with Spark, available in the Apache Polaris main repository. This setup includes a Jupyter Notebook environment for running PySpark and interacting with Polaris locally.
This is a step toward expanding Apache Polaris to help Iceberg and Delta Lake communities manage diverse data lake environments in one place. We see an opportunity to work with the Polaris community to further improve interoperability with features like:
More engine and format support: Implement support for more engines like Trino to read and write more table formats in Polaris.
Federating to Delta catalogs: Surface Delta tables from other catalogs already in use, such as Unity Catalog, AWS Glue Data Catalog or Hive Metastore, to create a “single pane of glass.”
Extending credential vending beyond Iceberg: Extend credential vending that’s already supported for Iceberg tables to other table formats.
Table format conversion: Enable the conversion of tables from one format to another to expand interoperability and integrations.
Beyond table formats, there are many other features on the proposed roadmap for Apache Polaris.
Whether you have feedback about this functionality or want to participate in shaping the future of Apache Polaris, the community is open and glad to have you! There are many ways to get involved:
Participate in conversations on Slack, mailing list and recurring video meetings
Improve documentation and contribute to the codebase by opening issues and pull requests. If you haven’t already contributed to Polaris, the community maintains a list of good first issues to pick up.
Delta Lake support in Snowflake’s managed service for Apache Polaris is in development. To learn more about Snowflake’s managed service, click here.


