The Apache Iceberg™ Variant Type: Flexible Semistructured Data, Reimagined


The launch of Apache Iceberg™ v3 is a major milestone for the open source project, introducing a suite of advanced capabilities, such as default values, deletion vectors and new data types. With these new capabilities, Iceberg v3 provides a robust, high-performance toolkit required by modern data engineers and data scientists who need to build efficient and flexible data platforms on open standards.
Among the most impactful new additions to the Iceberg v3 table spec is the Variant type. Variant enables more flexibility and improved support for semistructured data, allowing Iceberg tables to store data for a broader swath of use cases (e.g., logging and telemetry, configuration and profiles, and IoT, among others). Since the ratification of the v3 table spec in June 2025, the Iceberg community has been hard at work to enable Variant for users working with Iceberg tables and various engines, including Apache Spark™, Apache Flink® and others. The Iceberg community’s design for Variant was, in part, shaped by Snowflake’s experience helping customers with their semistructured data for nearly a decade.
In this blog, we’ll first dive into the Variant type and how it was introduced to Iceberg before showcasing how to get started with this new Iceberg data type.
Variant and its value
In data lakes and analytic warehouses, many of the data sets of interest are not rigid tables; instead, they contain semistructured data, such as JSON blobs, nested objects, arrays, optional fields, heterogenous records and more. Historically, accommodating this kind of data introduced compromises for data engineers:
Define a fixed schema ahead of time → force all downstream consumers to adapt when it changes
Store data as JSON strings → consumers have to parse the JSON at query time, which is slow and brittle.
Use wide tables with many nullable fields → inefficiencies in storage, schema drift, NULL-overload.
The Variant data type allows users to accommodate variable data without making these compromises. Within a Variant-typed column, a value can be any of:
A primitive (integer, string, timestamp)
An array (ordered list of Variants)
An object (unordered map from string keys to Variants)
And each row can hold a different type altogether.
Bringing Variant to life in Apache Iceberg
According to the Iceberg v3 table spec, the Variant type allows semistructured data to be directly stored in a column with binary encoding. This means that engines have more flexibility with schemas and can operate on the content more efficiently, using pushdown filters.
The addition of a Variant type in Iceberg brings flexibility and efficiency by standardizing on the leading interoperable open table format. For use cases that demand flexibility and ever-changing data, tables will see less “schema churn” as new fields are added within a Variant column. Variant offers an immediate performance improvement over storing JSON strings — with smaller storage overhead, relative to wide, nullable schema designs. A dedicated Variant type means that more expressive capabilities can be added for analytics and transformations.
Parquet and encodings
Importantly, types stored in Iceberg tables need to align with existing standards for underlying file storage formats; that means aligning with Apache Parquet™. To make Variant data types a reality, the Iceberg and Parquet communities worked closely together to ensure that both projects’ definitions for Variant were aligned. To that end, a Variant type stored in Parquet files consists of two binary fields: metadata and value.
optional group Variant_name (Variant(1)) {
required binary metadata;
required binary value;
}Metadata encoding
The metadata field encodes how the key strings in Variant objects are deduplicated, their dictionary and offsets into that dictionary. The metadata is broken down as follows:
A critical
headerbyte, which encodes:A 4-bit
version(current version = 1)A 1-bit
sorted_stringsflag (defining whether the dictionary strings are sorted and unique)A 2-bit
offset_size_minus_one(the byte-length used for dictionary offsets)
dictionary_size(unsigned integer,offset_sizebytes)A series of offsets (
dictionary_size + 1offsets)The concatenated bytes of all dictionary strings

Value encoding
The value binary encodes the Variant content with a value_metadata byte, followed by zero or more value_data bytes.
The value_metadata byte is a composite field that encodes:
The data kind: Primitive, short-string, array or object
For primitives: The specific type (e.g., null, boolean, integer, float, string)
Type-specific metadata: Type-specific metadata that vary based on the types
The value_data bytes provide the actual encoding of the data, which varies based on the types.
Primitive value: The values are encoded differently based on the types. Some types may not have data bytes (e.g., for boolean, it uses type
BOOLEAN_TRUE(1)andBOOLEAN_FALSE(2)without the data).Array value: The array value is encoded with the number of elements, indices to the elements, and sequence of encoded elements, which are Variants encoded recursively.
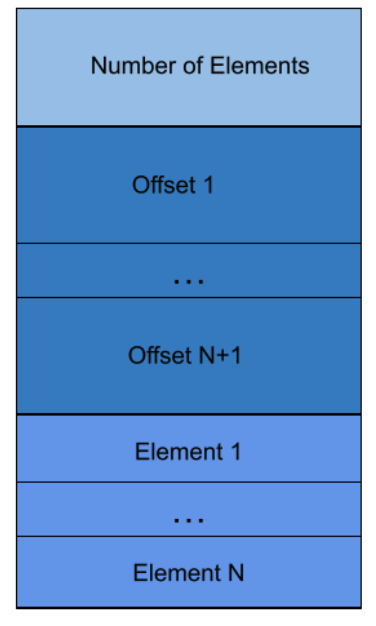
- Object value: The object value is encoded with the number of fields, the list of key indices into the metadata’s key dictionary, followed by the indices to the value fields and sequence of encoded fields, which are Variants encoded recursively.
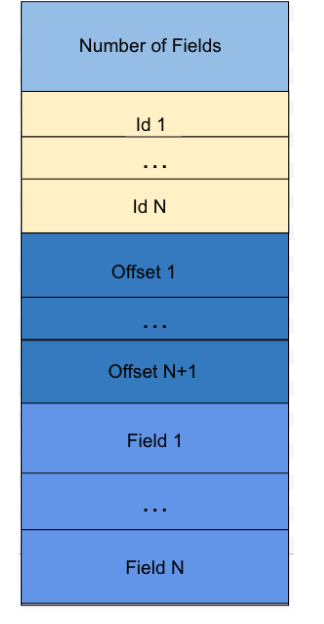
Variant shredding
On its own, the Variant type allows users to store variable fields and types in a single column. However, given the above encoding structure, in order to read the fields, both the value_metadata and value_data have to be deserialized. In addition to adding another step to the process of accessing the data within the Iceberg table, users no longer enjoy the usual performance benefits of columnar storage in Iceberg tables (e.g. file pruning, column statistics, predicate pushdown, etc).
To bring the same Iceberg performance gains to Variant columns, the community introduced shredding or subcolumnarization. The shredding process extracts selected fields within a Variant value into separate, explicitly typed Parquet columns. While doing so, it still preserves a residual binary representation for the rest of the data. The result combines the flexibility of semistructured data with the performance gains that users expect from Iceberg metadata.
As an example, a Variant object {"event_type": "noop", "event_ts": 1729794114937} can be shredded as:
optional group event (Variant(1)) {
required binary metadata;
optional binary value;
optional group typed_value {
required group event_type { # shredded field for event_type
optional binary value;
optional binary typed_value (STRING);
}
required group event_ts { # shredded field for event_ts
optional binary value;
optional int64 typed_value (TIMESTAMP(true, MICROS));
}
}
}Note that, for all data that doesn’t fit the shredded schema, the remaining data is encoded in the value binary field. This ensures that nothing is lost. Should the full Variant need to be reconstructed, the query engine can combine the shredded, typed parts with the residual Variant binaries recursively to build the full value.
Once the fields are shredded out, the shredded, typed columns are treated as standard columns with their own column-level statistics (e.g., min, max, null counts) for better filter pushdown. Queries targeting a specific field can avoid reading full Variant binaries and simply scan the corresponding shredded column.
Getting started with Iceberg Variant
Now it’s time to get hands-on with the new Variant type in Iceberg; the example below uses Spark, while many other engines are actively developing their support for Variant in Iceberg. For compatibility, ensure that the following versions are used:
Spark version 4.0 or above
Iceberg version 1.10
1. Create a table with a Variant column
CREATE OR REPLACE TABLE car_sales
(
record Variant
)
USING iceberg
TBLPROPERTIES (
'format-version' = '3'
);Tip: You must set 'format-version' = '3' within table properties in order to enable any of the v3 table spec features.
2. Insert semistructured data
INSERT INTO car_sales
SELECT
parse_json('{"date":"2017-04-28","dealership":"Valley View Auto Sales",
"salesperson":{"id":"55","name":"Frank Beasley"},
"customer":[
{"name":"Joyce Ridgely","phone":"16504378889","address":"San Francisco, CA"},
{"name":"Jim Ridgely","phone":"16504371129","address":"San Francisco, CA"}
],
"vehicle":[
{"make":"Honda","model":"Civic","year":"2017","price":"20275",
"extras":["ext warranty","paint protection"]}
]}')Tip: The parse_json(...) command in Spark is helpful to convert JSON strings or objects into the Variant type.
3. Query nested values
SELECT
| Variant_GET(record, '$.dealership', 'string') AS dealership,
| Variant_GET(record, '$.customer[0].name', 'string') AS customer_name,
| Variant_GET(record, '$.vehicle[0]') AS vehicle
| FROM car_salesWith Variant_GET, only requested fields are expected to be read, rather than the entire Variant. Note that Spark's Variant extraction pushdown to Iceberg tables is currently under development (as of this writing).
Looking ahead
As it stands, the addition of Variant in Apache Iceberg v3 opens up a path for managing semistructured data more flexibly and efficiently. It gives users the ability to combine the schema flexibility of JSON-style storage with the performance and query optimizations of a structured table format. For anyone dealing with semistructured data in their lakehouse or wanting to avoid rigid upfront schemas, Variant is an exciting option to explore.
At the same time, the Iceberg community is already preparing a roadmap of new features and improvements around the new Variant type. For example, improved pushdown extraction will enable calls to Variant_GET in Spark to fetch only the required subfields, instead of reconstructing the entire Variant when the Variants are shredded. In addition, shredded writes are currently in progress with more exciting changes to come!
Whether you’re already embracing an open lakehouse architecture or just getting started with Iceberg, Iceberg users have so much to look forward to with Variant and the rest of the v3 table spec.
Looking to get involved in Apache Iceberg? Check out the GitHub repository and peruse open issues.
Want to stay up to date on Apache Iceberg developments? Subscribe to the dev list.
Excited to use Variant and other v3 features in Snowflake? Stay tuned for announcements as Snowflake builds out Iceberg v3 support, and look out for more deep dives from the engineering team.

Generalized Skew Handling: How Snowflake Automatically Mitigates Data Skew

Graph Queries Across Billions of Rows of Scattered Data with Postgres and Apache AGE™

How to Choose Your Interoperable Catalog
