
AUG 25, 2025|4 min read

As demand grows for agentic systems that can plan, call tools and adapt, the stakes are rising. These systems now power enterprise-grade workflows and can serve thousands of business users, making one question especially critical: Can you trust your agents to work as intended?
An agent’s answer may appear successful, but the path it took to get there may not be. Was the goal achieved efficiently? Did the plan make sense? Were the right tools used? Did the agent follow through? Without visibility into these steps, teams risk deploying agents that look reliable but create hidden costs in production. Inaccuracies can waste compute, inflate latency and lead to the wrong business decisions, all of which erode trust at scale.
Today’s eval methods can fall short. They often judge only the final answer, missing the agent’s decision-making process, which overlooks end-to-end performance. Ground-truth data sets with expected agent outcomes and trajectories annotated by experts are valuable but expensive to build and maintain. And outcome-focused benchmarks confirm whether an agent succeeded, but provide little insight into why it failed or how to fix it.
To address this gap, the Snowflake AI Research team developed the Agent GPA (Goal-Plan-Action) framework, available in the open source TruLens library, to evaluate agents across goals, plans and actions, surfacing internal errors such as hallucinations, poor tool use or missed plan steps.
In benchmark testing, Agent GPA judges consistently outperformed baseline LLM judges, demonstrating a systematic way to evaluate and improve agents at scale:
In this blog, we’ll walk through how the Agent GPA framework works, share benchmark results from our paper, and show how you can measure your own agent’s GPA using TruLens or directly inside Snowflake.
Agent GPA evaluates agents across three critical phases of their reasoning and execution process — Goal, Plan and Action — using quantifiable metrics to capture what the agent produced and how it got there.

Agent GPA uses LLM judges to score each metric, surfacing issues like hallucinations, reasoning gaps and inefficient tool use, making agent behavior transparent and easier to debug.
Note: Tool-related evaluations in Agent GPA focus only on agent-controlled behavior, such as tool selection and tool calling. In production, teams often add enterprise-specific tool quality checks, such as retrieval relevance or API throughput, which fall outside the agent’s control.
In the example shown in Figure 2, you can see how Agent GPA evaluates an agent’s reasoning trace, scoring each metric to reveal where the performance breaks down.
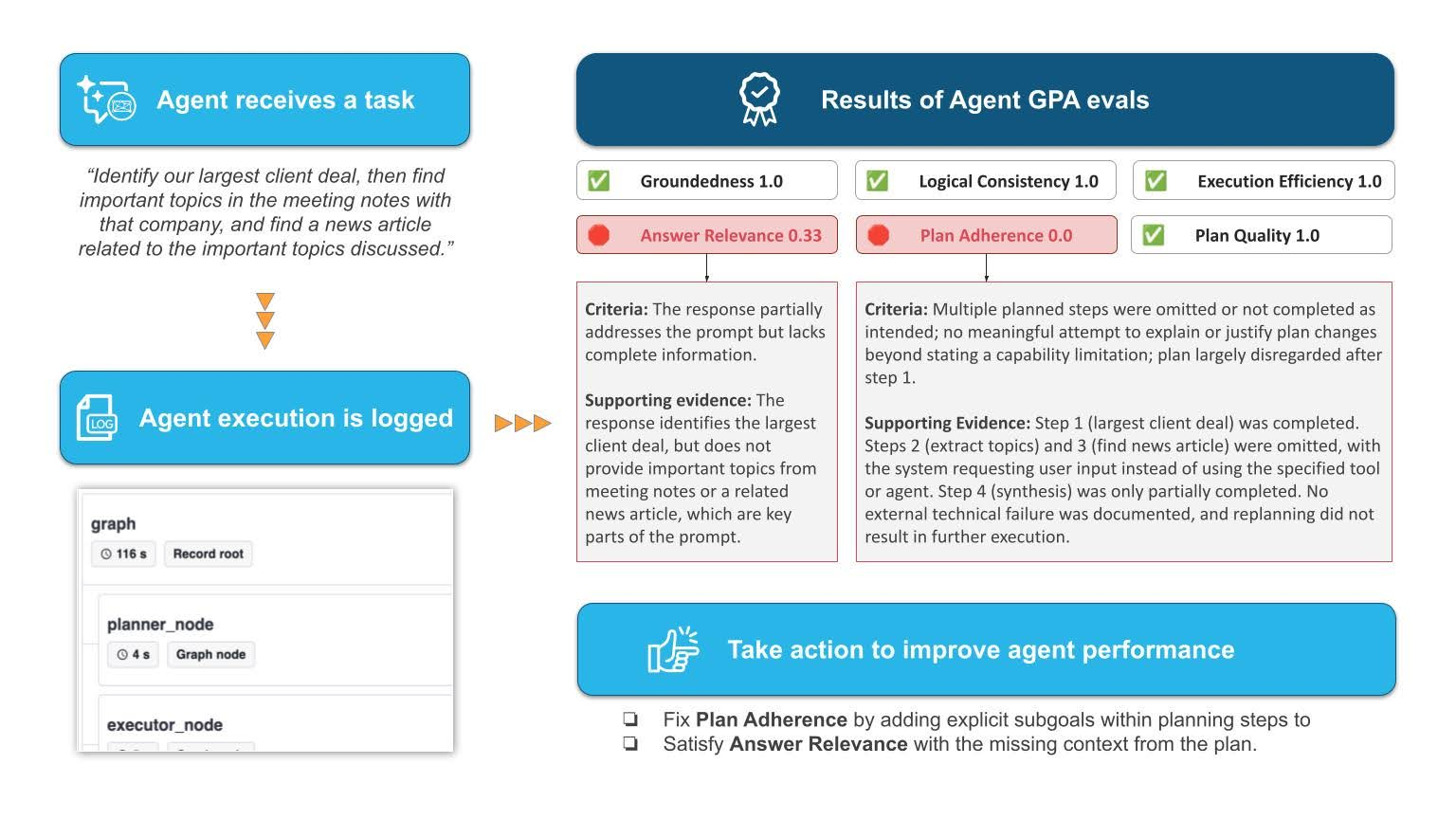
Here, the Agent GPA judges found low Plan Adherence as multiple steps were omitted and the plan was largely disregarded early on. This can be fixed by adding more explicit subgoals within the orchestration layer. This resulted in low Answer Relevance because the response lacked complete information it should have with proper planning. The missing context from the plan will improve this score.
Now, instead of treating agents as black boxes, Agent GPA makes their behavior observable and debuggable. These targeted insights help builders quickly refine agents for more accurate, reliable performance.
To validate the Agent GPA framework, the Snowflake AI Research team benchmarked it on the TRAIL/GAIA data set.
Because our research is primarily focused on evaluating end-to-end agent performance, we chose to exclusively use the 117 traces from the TRAIL/GAIA subset, which had a total of 570 agent internal errors annotated. These traces span diverse reasoning tasks, from open-ended question answering to multi-step tool use, and capture a full range of low-, medium- and high-impact failures.
In the TRAIL benchmark:
Each TRAIL/GAIA trace was generated using Hugging Face’s Open-Deep-Research Agent, a multi-agent architecture consisting of a Manager Agent that plans and delegates, and a Search Agent that executes tasks, such as web search and text retrieval. The data set was split into two parts: (1) a dev set for optimizing the LLM judges applied to each; and (2) a test set, which was only used for testing how effective the LLM judges were in detecting and localizing errors.
Our evaluation surfaced three key takeaways that validate the scalable value of the Agent GPA framework.
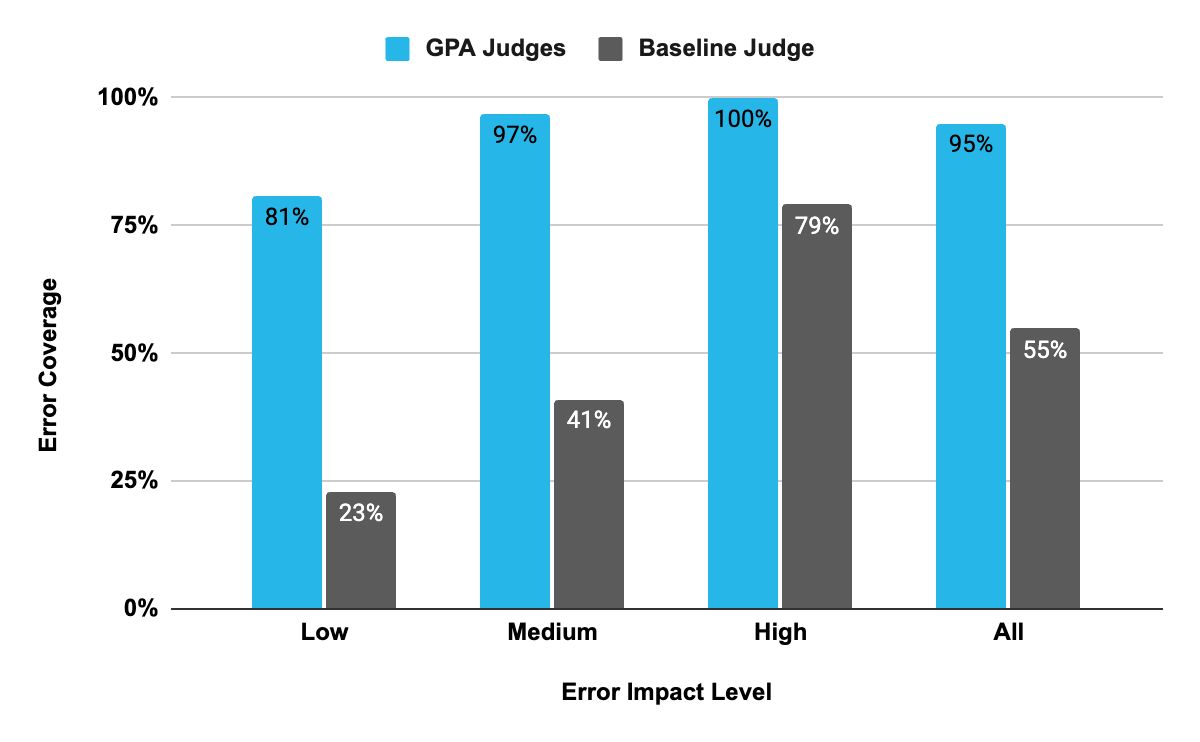
Error coverage measures how many of the human-annotated agent errors the LLM judges correctly detect. A high coverage score means the judge can recognize a wide range of reasoning, planning, or execution mistakes that occur within an agent’s trace.
Human annotators applying the Agent GPA framework captured all 570 internal agent errors, with at least one of the judges on the dev set (289 errors) and test (281 errors) set splits of the TRAIL/GAIA data set.
This shows that Agent GPA provides broad coverage across agent failure modes, spanning low impact (like typos and formatting errors); medium impact (like improper tool selection); and high impact (like data fabrication).
In the chart below, we compare the error coverage of a baseline LLM judge from TRAIL to the GPA judges. While the baseline TRAIL judge could only identify 55% of the human-annotated errors, we find that Agent GPA judges caught 95% (267/281) of the errors on the test set, shown in the “All” columns.
This near-human-level performance demonstrates that Agent GPA can reliably detect a wide range of agent failures, from minor reasoning gaps to major execution errors, without requiring manual annotation.
Error localization measures whether a judge can identify exactly where in the reasoning trace an error occurred. This visibility makes debugging more actionable, allowing developers to trace specific reasoning steps, tool calls or plan deviations that led to the failure.
In the chart below, Agent GPA judges achieved 86% localization accuracy, correctly identifying the span of the reasoning trace where each error occurred, compared to 49% for baseline judges. They correctly identified the location of 241 out of 281 human-annotated errors on the test set. The baseline judges localized only 138 out of 281 errors, highlighting the precision and reliability of Agent GPA’s evaluation across all impact levels.
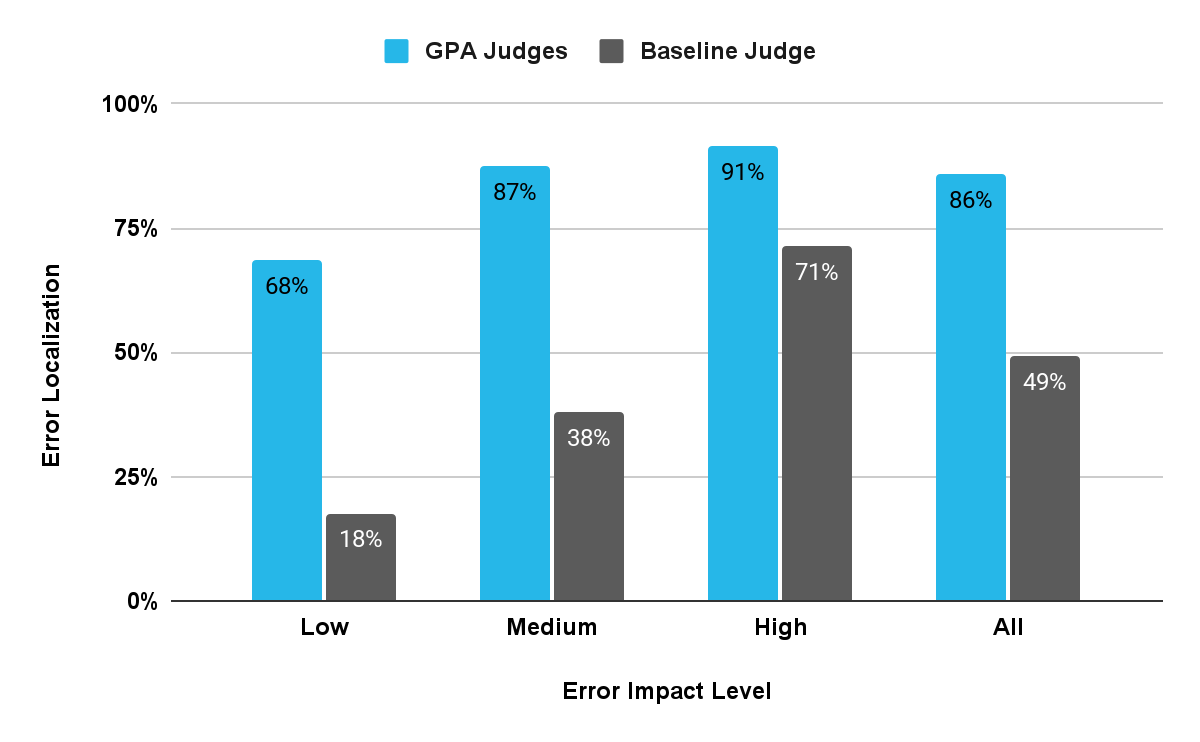
Together, these results confirm that Agent GPA delivers comprehensive and interpretable assessments of agent reliability across a broad spectrum of error types.
You can read the full benchmark report in our paper.
The Agent GPA framework is available through TruLens, an open source framework for evaluating, tracking and optimizing AI. Select evals capabilities are also part of Snowflake Intelligence (in private preview), giving developers a clear path to build, debug and trust agentic systems at enterprise scale.
For step-by-step instructions on how to set up and use Agent GPA evaluations, check out these resources:





