Getting Started with Snowpark for Python with Scikit-learn
Overview
By completing this guide, you will be able to go from raw data to build a machine learning model that can help to predict house prices.
Here is a summary of what you will be able to learn in each step by following this quickstart:
- Setup Environment: Use write_pandas and tables to ingest raw data from local file system into Snowflake
- Data Engineering: Leverage Snowpark for Python DataFrames to perform data transformations such as group by, aggregate, pivot, and join to prep the data for downstream applications.
- Machine Learning using scikit learn: Prepare data and run ML Training in Snowflake using scikit-learn and log the model to Snowflake Model Registry.
In case you are new to some of the technologies mentioned above, here’s a quick summary with links to documentation.
What is Snowpark?
The Snowpark API provides an intuitive library for querying and processing data at scale in Snowflake. Using a library for any of three languages, you can build applications that process data in Snowflake without moving data to the system where your application code runs, and process at scale as part of the elastic and serverless Snowflake engine.
Snowflake currently provides Snowpark libraries for three languages: Java, Python, and Scala.

Learn more about Snowpark.
What is scikit-learn?
It is one of the most popular open source machine learning libraries for Python that also happens to be pre-installed and available for developers to use in Snowpark for Python via Snowflake Anaconda channel. This means that you can use it in Snowpark for Python User-Defined Functions and Stored Procedures without having to manually install it and manage all of its dependencies.
What You’ll Learn
- How to ingest data in Snowflake
- How to do data explorations and understanding with Pandas and visualization
- How to encode the data for algorithms to use
- How to normalize the data
- How to training models with Scikit-Learn and Snowpark (including using Snowpark Optimized warehouse)
- How to evaluate models for accuracy
- How to deploy models on Snowflake
Prerequisites
- A Snowflake account with Anaconda Packages enabled by ORGADMIN. If you do not have a Snowflake account, you can register for a free trial account.
- You will need to accept acknowledge the Snowflake Third Party Terms by following Anaconda link in previous step.
- A Snowflake account login with ACCOUNTADMIN role. If you have this role in your environment, you may choose to use it. If not, you will need to 1) Register for a free trial, 2) Use a different role that has the ability to create database, schema, tables, stages, and stored procedures OR 3) Use an existing database and schema in which you are able to create the mentioned objects.
Clone GitHub Repository
This section covers cloning of the GitHub repository and creating a Python 3.10 environment.
-
Clone GitHub repository
-
Download the miniconda installer from https://conda.io/miniconda.html. (OR, you may use any other Python environment with Python 3.10).
-
Open
environment.ymland paste in the following config:
name: snowpark_scikit_learn channels: - https://repo.anaconda.com/pkgs/snowflake/ - nodefaults dependencies: - python=3.10 - pip - snowflake-snowpark-python==1.23.0 - snowflake-ml-python==1.6.4 - snowflake==1.0.0 - ipykernel - matplotlib - seaborn
- From the root folder, create conda environment by running below command.
IMPORTANT:
- If you are using a machine wth Apple M1 chip, follow these instructons to create the virtual environment and install Snowpark Python instead of what's described below.
conda env create -f environment.yml conda activate snowpark_scikit_learn
Note: For the account parameter, specify your account identifier and do not include the snowflakecomputing.com domain name. Snowflake automatically appends this when creating the connection.*
Troubleshooting pyarrow related issues
- If you have
pyarrowlibrary already installed, uninstall it before installing Snowpark. - If you do not have
pyarrowinstalled, you do not need to install it yourself; installing Snowpark automatically installs the appropriate version. - Do not reinstall a different version of
pyarrowafter installing Snowpark.
Data Ingest
The Notebook linked below covers the following data ingestion tasks.
- Download data file to be used in the lab
- Read downloaded data as pandas dataframe
- Connect to Snowflake using session object
- Create database, schema and warehouse
- Load pandas dataframe object into Snowflake table
Data Ingest Notebook in Jupyter or Visual Studio Code
To get started, follow these steps:
-
In a terminal window, browse to this folder and run
jupyter notebookat the command line. (You may also use other tools and IDEs such Visual Studio Code.) -
Open and run through the cells in 1_snowpark_housing_data_ingest.ipynb
IMPORTANT: Make sure in the Jupyter notebook the (Python) kernel is set to snowpark_scikit_learn-- which is the name of the environment created in Clone GitHub Repository step.
Data Exploration
The Notebook linked below covers the following data exploration tasks.
- Establish secure connection from Snowpark Python to Snowflake
- Compare Snowpark dataframe to Pandas dataframe
- Use describe function to understand data
- Build some visualisation using seaborn and pyplot
Data Exploration Notebook in Jupyter or Visual Studio Code
To get started, follow these steps:
-
If not done already, in a terminal window, browse to this folder and run
jupyter notebookat the command line. (You may also use other tools and IDEs such Visual Studio Code.) -
Open and run through the cells in 2_data_exploration_transformation.ipynb
IMPORTANT: Make sure in the Jupyter notebook the (Python) kernel is set to snowpark_scikit_learn-- which is the name of the environment created in Clone GitHub Repository step.
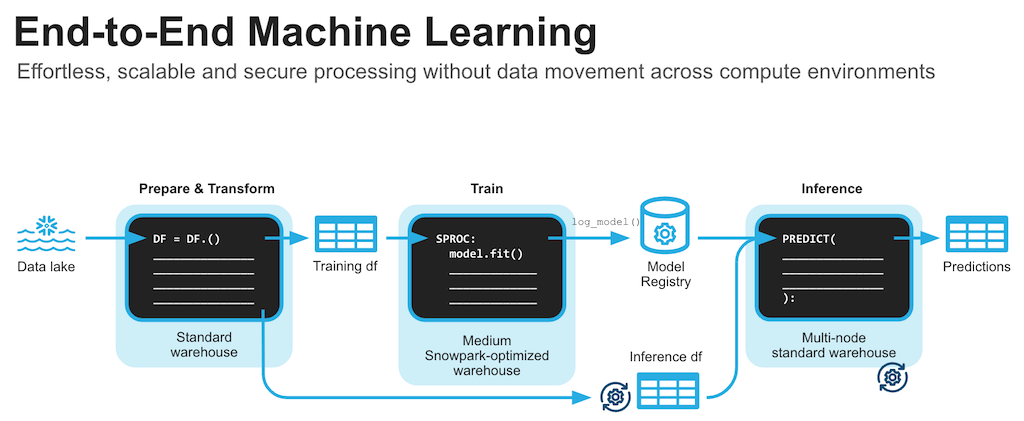
Machine Learning using Scikit learn
PREREQUISITE: Successful completion of previous steps
The Notebook linked below covers the following machine learning tasks.
- Establish secure connection from Snowpark Python to Snowflake
- Get features and target from Snowflake table into Snowpark DataFrame
- Create Snowflake stage for the Python Stored Procedure code
- Prepare features using scikit learn for model training
- Create a Python Stored Procedure to deploy model training code on Snowflake
- Optinally use Snowpark optimised warehouse for model training
- Log the model to Snowflake Model Registry and use it for inference on new data points
Machine Learning Notebook in Jupyter or Visual Studio Code
To get started, follow these steps:
-
If not done already, in a terminal window, browse to this folder and run
jupyter notebookat the command line. (You may also use other tools and IDEs such Visual Studio Code.) -
Open and run through the 3_snowpark_end_to_end_ml.ipynb
IMPORTANT: Make sure in the Jupyter notebook the (Python) kernel is set to snowpark_scikit_learn -- which is the name of the environment created in Clone GitHub Repository step.
Conclusion And Resources
Congratulations! You've successfully completed the lab using Snowpark for Python and scikit-learn.
What You Learned
-
How to ingest data in Snowflake
-
How to do data explorations and understanding with Pandas and visualization
-
How to encode the data for algorithms to use
-
How to normalize the data
-
How to training models with Scikit-Learn and Snowpark (including using Snowpark Optimized warehouse)
-
How to evaluate models for accuracy
-
How to deploy models on Snowflake and do inferencing
Related Resources
This content is provided as is, and is not maintained on an ongoing basis. It may be out of date with current Snowflake instances