
One thing nearly all such data providers have is a REST API. Snowflake’s recently announced external functions capability allows Snowflake accounts to call external APIs. By using external functions, data enrichment providers can fulfill requests for data from Snowflake Data Marketplace consumers. By calling their own APIs on behalf of their customers, from a Snowflake account in the consumer’s region, a data provider can simply share the resulting data to the customer’s Snowflake account.
Through this approach, data enrichment providers can be quickly added to Snowflake Data Marketplace and immediately fulfill consumer requests in any Snowflake cloud or region by using their existing API, eliminating the need for the engineering of new data flows by the provider, and eliminating the need for cross-region data replication.
The first part of this blog post introduced Quantifind, a financial-crimes prevention company that uses this API-based approach to offer data enrichment services on Snowflake Data Marketplace across all Snowflake regions, backed by data providers’ existing API.
This part provides a step-by-step example of how Quantifind does this.
Prerequisite
For Quantifind to enable the data enrichment and start automatically fulfilling consumer requests, data providers need to run a setup script. They do this just once in each Snowflake region where they have customers.
To follow along with this example, before you proceed, you’ll need to ask your Snowflake Sales Engineer to enable a parameter on your account called ENABLE_STREAMS_ON_SHARED_TABLES on your account and to set it to TRUE. This is needed because streams on shared tables is currently a Preview feature.
Diagram of End-to-End Data Flow
Figure 1 shows the end-to-end data flow we’ll set up. It shows the flow of data from an example consumer account, through the Quantifind account, to the API, and back to the consumer account. Here is a link to a full-size version.
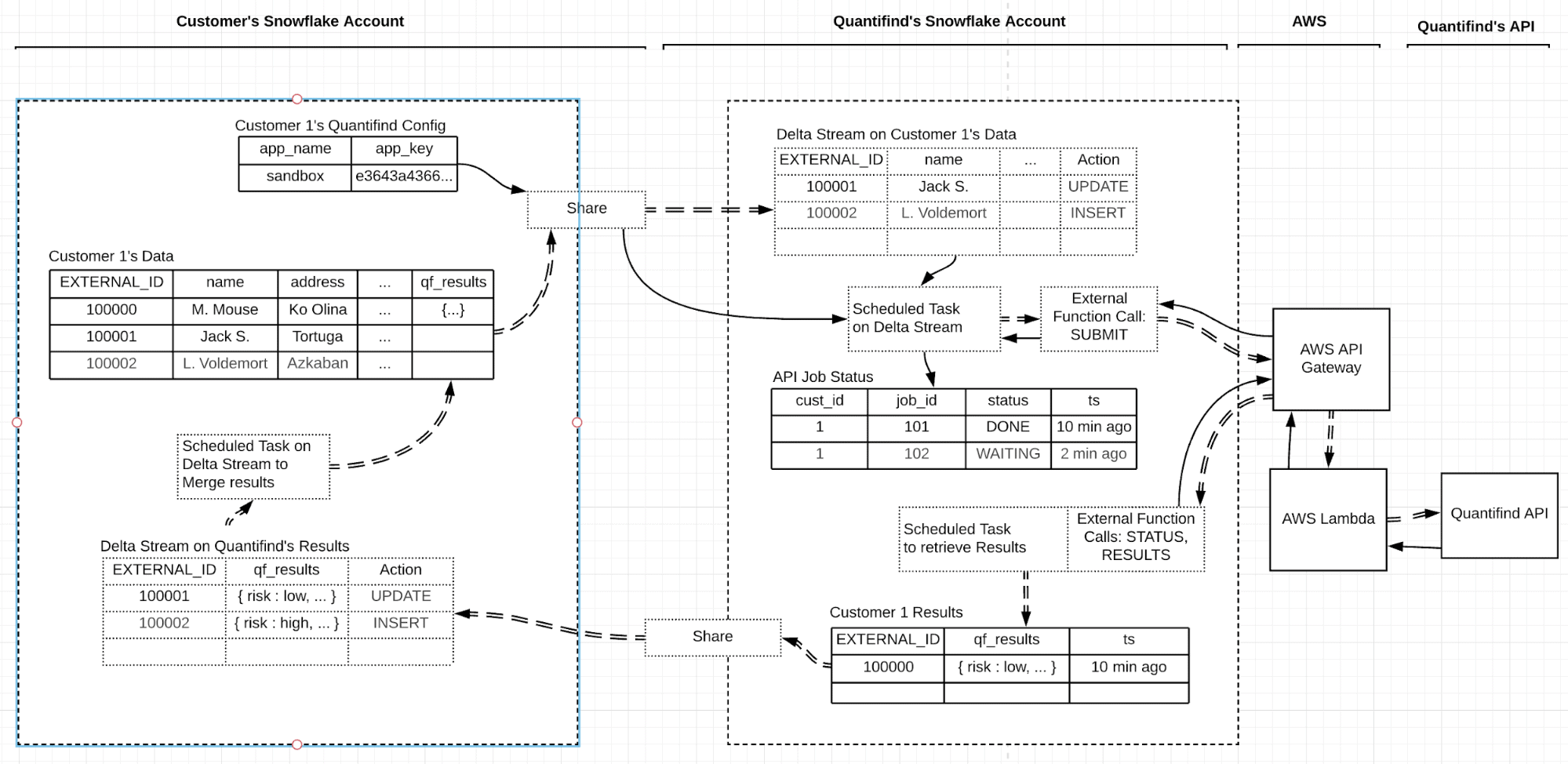
Steps to Enable API-Backed Data Enrichment
Now, let’s go through the Quantifind example step-by-step.
Step 1: Create a database and warehouse
First, create a database that will be used to hold the external function, a job tracking table, and the resulting data to be shared back to customers. Also create a new Snowflake compute instance (a “virtual warehouse”) to service the requests, in order to isolate this service’s resources from other Snowflake jobs, and allow them to automatically suspend when no jobs are pending.
use role ACCOUNTADMIN; create or replace database quantifind_data; use database quantifind_data; CREATE OR REPLACE WAREHOUSE PROVIDER_ENRICH_WH WITH WAREHOUSE_SIZE = 'SMALL' WAREHOUSE_TYPE = 'STANDARD' AUTO_SUSPEND = 60 AUTO_RESUME = TRUE MIN_CLUSTER_COUNT = 1 MAX_CLUSTER_COUNT = 1 SCALING_POLICY = 'STANDARD';
Step 2: Configure the AWS API Gateway and an AWS Lambda function, and test the function
Before proceeding, configure the AWS API Gateway and an AWS Lambda function that will call the remote REST API by performing the procedures in the following sections of this page:
- Step 1: Create the Remote Service (Lambda Function on AWS)
- Step 2: Configure the Proxy Service (API Gateway on AWS) and Create the API Integration (in Snowflake)
- Step 3: Create the External Function
- Step 4: Call the External Function
For now, implement and test the sample function described on that page. We will replace it with the actual lambda to call Quantifind’s API in a later step.
Note: In the section “Step 2: Configure the Proxy Service (API Gateway on AWS) and Create the API Integration (in Snowflake),” when you get to the step that says, ‘When asked to “Specify accounts that can use this role”, paste the previously-saved Cloud Platform Account Id,”’ you should enter your own AWS Account ID number, which you can find on the AWS Support tab. Also in that step, if you get an “invalid principal” error when saving your updated resource policy, leave the page and come back. You will likely see that the policy has been saved despite the error, and you should be able to resave it to confirm and proceed.
Step 3: Update the lambda function
Replace the sample AWS Lambda function with this Quantifind function, and click Save in Lambda.
Step 4: Create the API Integration
If you already created an API integration in Step 2, you can reuse it. If you want to create a new one, use the following code, substituting correct values for role_arn and allowed_prefixes. You may also need to update your security policy settings on the AWS side for this new integration, if you replace your existing integration.
create or replace api integration quantifind_api
api_provider = aws_api_gateway
api_aws_role_arn = 'arn:aws:iam::#####:role/servicenow_ext_function_prototype'
enabled = true
api_allowed_prefixes =
('https://gu41r3343pc.execute-api.us-east-2.amazonaws.com/deploy/')
;
describe integration quantifind_api;
// you'll need the 2 fields below to update the AWS policy settings
// user arn ____
// external id ____
Step 5: Create the external functions
Now, create the external functions that will be used to call the remote API. In both statements, you’ll need to replace the api_integration field to match the name of your integration, and the entire “as” string to match your specific AWS API integration URL.
create or replace external function quantifind_api(tablename varchar, app_name varchar, app_token varchar, base_url varchar) returns variant api_integration = quantifind_api MAX_BATCH_ROWS = 200 as 'https://gu41r343pc.execute-api.us-east-2.amazonaws.com/deploy/quantifind-api' ; create or replace external function quantifind_api(tablename varchar, app_name varchar, app_token varchar, base_url varchar, payload varchar) returns variant api_integration = quantifind_api MAX_BATCH_ROWS = 200 as 'https://gu41r343pc.execute-api.us-east-2.amazonaws.com/deploy/quantifind-api' ;
Note that two versions of the function are created here: one with a payload field, which will be used to submit actual data for enrichment, and one without, which is used to check the status of existing jobs. These two versions can co-exist, and the correct one is automatically used based on the parameters that are used when you call the function.
Step 6: Create a job tracking table
Quantifind’s data enrichment API is an asynchronous API, meaning first data is submitted using a “submit” method, then you check on the jobs with a “status” call, and when the jobs are done, you retrieve the results with a “results” call. Since we will be making multiple calls for each job, we need to track those in a job tracking table. This also serves as a record of what was done, which could also be used for logging, billing, rate limiting, call-capping, or other purposes.
create or replace table api_jobs (customerid integer, app_name varchar, app_key varchar, jobid integer, totalsearches integer, status_flag varchar, submittedts timestamp_ltz(9), completedts timestamp_ltz(9)); ALTER TABLE api_jobs SET DATA_RETENTION_TIME_IN_DAYS = 14 CHANGE_TRACKING = TRUE; create or replace stream pending_jobs on table api_jobs APPEND_ONLY = TRUE;
The last line above creates a Snowflake stream that will help us know later if any jobs are pending, so that we don’t need to spend resources checking for completed jobs if no jobs are currently pending.
Step 7: Create a logging procedure
This step creates a procedure that can be used for logging the remaining steps. This is useful for developing stored procedures, to get visibility into what’s happening when the procedures are run.
CREATE or replace PROCEDURE do_log(MSG STRING)
RETURNS STRING
LANGUAGE JAVASCRIPT
EXECUTE AS CALLER
AS $$
// See if we should log - checks for session variable do_log = true.
try {
var stmt = snowflake.createStatement( { sqlText: 'select $do_log' }
).execute();
} catch (ERROR){
return; //swallow the error, variable not set so don't log
}
stmt.next();
if (stmt.getColumnValue(1)==true){ //if the value is anything other than true,
don't log
try {
snowflake.createStatement( { sqlText: 'create table identifier ($log_table)
if not exists (ts number, msg string)'} ).execute();
snowflake.createStatement( { sqlText: 'insert into identifier ($log_table)
values (:1, :2)', binds:[Date.now(), MSG] } ).execute();
} catch (ERROR){
throw ERROR;
}
}
$$
;
Step 8: Create a procedure to process completed job results
The procedure below checks the api_jobs table to get a list of all pending jobs, and then it calls the external function to get the status of those jobs from the remote API. Then it iterates over the results, calls the API again for each job that is done, and stores the results in a results table specific to each customer. (The results table will be created in a later step as consumers are enabled.)
create or replace procedure quantifind_process_results(master_db_name varchar,
base_url VARCHAR)
returns variant not null
language javascript
EXECUTE AS CALLER
as
$$
function log(msg){
snowflake.createStatement( { sqlText: 'call do_log(:1)', binds:[msg] }
).execute();
}
var my_sql_command = "with qs1 as (with qs as (select customerid, app_name,
app_key, jobid, status_flag from "+MASTER_DB_NAME+".public.api_jobs where status_flag
= 'READY' order by jobid limit 10) select customerid, jobid, app_name, app_key,
quantifind_api('status?jobId='||qs.jobid,qs.app_name, qs.app_key,'"+BASE_URL+"') as
value from qs ) select customerid, jobid, app_name, app_key, value[0]:status::varchar
as stats from qs1;"
var statement1 = snowflake.createStatement( {sqlText: my_sql_command} );
log(my_sql_command);
var result_set1 = statement1.execute();
resultrows = 0
while (result_set1.next())
{
resultrows += 1;
var custid = result_set1.getColumnValue(1);
var jobid = result_set1.getColumnValue(2);
var appid = result_set1.getColumnValue(3);
var appkey = result_set1.getColumnValue(4);
var stats = result_set1.getColumnValue(5);
// merge in new results
if (stats == "COMPLETED")
{
resultrows=resultrows+1;
var my_sql_command2 = "merge into customer"+custid+"_results cr using (select
t.value:externalId::varchar externalid, t.value quantifind_result,
current_timestamp(9) ts from
Table(Flatten(quantifind_api('results?jobId="+jobid+"','"+appid+"','"+appkey+"','"+BAS
E_URL+"'))) t) as r on cr.externalid = r.externalid when matched then update set
cr.QUANTIFIND_RESULT = r.QUANTIFIND_RESULT, cr.result_ts = r.ts when not matched then
insert (externalid, quantifind_result, result_ts) values (r.externalid,
r.quantifind_result, r.ts);";
log("merging: "+my_sql_command2);
var statement2 = snowflake.createStatement( {sqlText: my_sql_command2} );
var result_set2 = statement2.execute();
// update status flag
var my_sql_command3 = "update "+MASTER_DB_NAME+".public.api_jobs set status_flag =
'DONE', completedts = current_timestamp(9) where customerid = "+custid+" and jobid =
"+jobid+";";
log("updating: "+my_sql_command2);
var statement3 = snowflake.createStatement( {sqlText: my_sql_command3} );
var result_set3 = statement3.execute();
}
}
return { "rows loaded":resultrows };
$$
;
Step 9: Create a wrapper procedure
This step creates a procedure that calls the one created in step 8, and then it checks to see if any jobs are still pending. If no jobs are still pending, it clears out the pending_jobs stream, so that we do not spend any further resources checking for finished jobs while there are no jobs pending.
create or replace procedure quantifind_check_results(master_db_name varchar, wh_name
VARCHAR, base_url VARCHAR)
returns variant not null
language javascript
EXECUTE AS CALLER
as
$$
function log(msg){
snowflake.createStatement( { sqlText: 'call do_log(:1)', binds:[msg] }
).execute();
}
log("Looking for results for all customers");
var my_sql_command = "call
quantifind_process_results('"+MASTER_DB_NAME+"','"+BASE_URL+"');";
var statement = snowflake.createStatement( {sqlText: my_sql_command} );
var result_set = statement.execute();
var my_sql_command = "select * from api_jobs where status_flag = 'READY';";
var statement = snowflake.createStatement( {sqlText: my_sql_command} );
var result_set = statement.execute();
log("checking to see if any jobs remain");
if (!result_set.next()) {
log("done with jobs; purge pending jobs stream");
// purge pending jobs stream
var my_sql_command = "create or replace stream pending_jobs on table api_jobs
APPEND_ONLY = TRUE;";
var statement = snowflake.createStatement( {sqlText: my_sql_command} );
var result_set = statement.execute();
}
log("done");
return { "done":"done" };
$$
;
Step 10: Create a task to automatically trigger checking for finished jobs
This step creates a task that is automatically run every minute to check for finished jobs, using the procedure we created in Step 9. The WHEN clause causes it to trigger only if there are jobs pending, so that no resources are used when no jobs are pending.
create or replace task customer_all_task_results
WAREHOUSE = PROVIDER_ENRICH_WH
SCHEDULE = '1 minute'
WHEN
SYSTEM$STREAM_HAS_DATA('pending_jobs')
AS
call
quantifind_check_results('quantifind_data','PROVIDER_ENRICH_WH','https://bapi.quantifin
d.com/api/v1/job/');
alter task customer_all_task_results RESUME;
Step 11: Create a customer tracking table
This step creates a table to keep track of consumers that we will be servicing from this region, and their associated Snowflake account ID.
create or replace table customer_list (customerid integer, snowflake_acct_name varchar); insert into customer_list (customerid, snowflake_acct_name) VALUES (0, 'START');
Step 12: Create a consumer provisioning procedure
This step creates a procedure that is called just once to provision each consumer account that we want to service from this region. It automatically sets up data sharing to and from the consumer. The procedure could be called automatically from an external task management or customer onboarding system.
create or replace procedure provision_consumer(consumer_account varchar, master_db_name varchar)
returns variant not null
language javascript
EXECUTE AS CALLER
as
$$
function log(msg){
snowflake.createStatement( { sqlText: 'call do_log(:1)', binds:[msg] }
).execute();
}
log("Provisioning consumer "+CONSUMER_ACCOUNT);
// get next customer number
var my_sql_command = "select max(customerid) from customer_list;";
var statement = snowflake.createStatement( {sqlText: my_sql_command} );
var result_set = statement.execute();
result_set.next();
newcustid = result_set.getColumnValue(1) + 1;
log("New custid="+newcustid);
// insert new customer details in customer table
var my_sql_command = "insert into customer_list (customerid, snowflake_acct_name)
VALUES ("+newcustid+", '"+CONSUMER_ACCOUNT+"');";
var statement = snowflake.createStatement( {sqlText: my_sql_command} );
var result_set = statement.execute();
// create response tables
var my_sql_command = "create or replace table customer"+newcustid+"_results
(EXTERNALID varchar, QUANTIFIND_RESULT variant, result_ts timestamp_ltz(9));";
var statement = snowflake.createStatement( {sqlText: my_sql_command} );
var result_set = statement.execute();
var my_sql_command = "ALTER TABLE customer"+newcustid+"_results SET
DATA_RETENTION_TIME_IN_DAYS = 14 CHANGE_TRACKING = TRUE;";
var statement = snowflake.createStatement( {sqlText: my_sql_command} );
var result_set = statement.execute();
// share response tables
var my_sql_command = "create or replace share
quantifind_to_customer"+newcustid+";";
var statement = snowflake.createStatement( {sqlText: my_sql_command} );
var result_set = statement.execute();
var my_sql_command = "grant usage on database "+MASTER_DB_NAME+" to share
quantifind_to_customer"+newcustid+";";
var statement = snowflake.createStatement( {sqlText: my_sql_command} );
var result_set = statement.execute();
var my_sql_command = "grant usage on schema "+MASTER_DB_NAME+".public to share
quantifind_to_customer"+newcustid+";";
var statement = snowflake.createStatement( {sqlText: my_sql_command} );
var result_set = statement.execute();
var my_sql_command = "grant select on table customer"+newcustid+"_results to share
quantifind_to_customer"+newcustid+";";
var statement = snowflake.createStatement( {sqlText: my_sql_command} );
var result_set = statement.execute();
var my_sql_command = "alter share quantifind_to_customer"+newcustid+" add
accounts="+CONSUMER_ACCOUNT+";";
var statement = snowflake.createStatement( {sqlText: my_sql_command} );
var result_set = statement.execute();
log("done");
return { "newcustid":newcustid };
$$
;
Step 13: Create a consumer enablement procedure
Once each consumer has completed its side of the enablement described here, the following procedure completes the enablement of the new consumer. This procedure turns on Snowflake streams and tasks to watch for new data from the consumer, and when new data is detected, it triggers the enrichment process. This procedure can also be called from an external automation or onboarding system to fully automate the new-consumer onboarding process.
create or replace procedure enable_consumer(customerid varchar, consumer_account varchar, base_url varchar, share_name varchar, master_db_name varchar, wh_name varchar)
returns variant not null
language javascript
EXECUTE AS CALLER
as
$$
function log(msg){
snowflake.createStatement( { sqlText: 'call do_log(:1)', binds:[msg] }
).execute();
}
log("Enabling consumer "+CONSUMER_ACCOUNT);
// create inbound share
var my_sql_command = "CREATE or REPLACE DATABASE customer"+CUSTOMERID+"_data FROM
SHARE "+CONSUMER_ACCOUNT+"."+SHARE_NAME+";";
var statement = snowflake.createStatement( {sqlText: my_sql_command} );
var result_set = statement.execute();
// switch back to regular database
var my_sql_command = "use database "+MASTER_DB_NAME+";";
var statement = snowflake.createStatement( {sqlText: my_sql_command} );
var result_set = statement.execute();
// create stream on inbound share
var my_sql_command = "create or replace stream
"+MASTER_DB_NAME+".public.customer"+CUSTOMERID+"_stream on table
customer"+CUSTOMERID+"_data.public.my_data_quantifind APPEND_ONLY = TRUE;";
var statement = snowflake.createStatement( {sqlText: my_sql_command} );
var result_set = statement.execute();
// create consumer task
var my_sql_command = "create or replace task customer"+CUSTOMERID+"_task WAREHOUSE =
"+WH_NAME+" SCHEDULE = '1 minute' WHEN
SYSTEM$STREAM_HAS_DATA('"+MASTER_DB_NAME+".public.customer"+CUSTOMERID+"_stream') AS
INSERT INTO "+MASTER_DB_NAME+".public.api_jobs ( with qf as (select "+CUSTOMERID+" as
customer_id, qc.app_name as app_name, qc.app_key as app_key,
quantifind_api('submit',qc.app_name,qc.app_key,'"+BASE_URL+"',TO_JSON(OBJECT_CONSTRUCT
('externalId', externalId, 'entityType', entityType, 'firstName', firstName,
'middleName', middleName,'lastName', lastName, 'name', orgName, 'addresses',
array_construct(object_construct('city', city, 'state', state, 'country',
country)),'birthDate', birthDate, 'employer', employer, 'email', email, 'phone',
phone))) qfr from "+MASTER_DB_NAME+".public.customer"+CUSTOMERID+"_stream qs,
customer"+CUSTOMERID+"_data.public.quantifind_config qc where qs.metadata$action =
'INSERT' or qs.metadata$action = 'UPDATE' ) select customer_id, app_name, app_key ,
qf.qfr[0]:jobId jobId, max(qf.qfr[0]:totalSearches) totalSearches,
max(qf.qfr[0]:status)::varchar as status_flag, current_timestamp(9) submittedTS, null
as completedTS from qf group by 1, 2, 3, 4);"
log("task="+my_sql_command);
var statement = snowflake.createStatement( {sqlText: my_sql_command} );
var result_set = statement.execute();
// enable consumer task
var my_sql_command = "ALTER TASK customer"+CUSTOMERID+"_task RESUME;";
var statement = snowflake.createStatement( {sqlText: my_sql_command} );
var result_set = statement.execute();
log("done");
return { "enabled": CUSTOMERID };
$$
;
Step 14: Enable the first consumer
While the above steps are numerous, they need to be run only once per region where a data provider plans to operate, and they take only a few seconds to execute. No other setup is needed on a per-region basis. You can save all the previous commands to a script file that you can run automatically via Snowflake’s SnowSQL CLI or through any other automation process that can run SQL whenever you want to deploy it to a net new Snowflake region.
Then, once a region is enabled, adding a new consumer in that region is a matter of just calling the consumer provisioning procedure we created in Step 12 and the consumer enablement procedure we created in Step 13 for that new consumer, as shown in the code below:
// STEP 1: Provision a specific consumer // set these defaults for your database and warehouse set my_master_db = 'quantifind_data'; set my_wh = 'PROVIDER_ENRICH_WH'; set base_url = 'https://bapi.quantifind.com/api/v1/job/'; // set these values provided by the consumer set consumer_account = 'ENTER CUSTOMER ACCOUNT ID HERE'; set consumer_share_name = 'customer_to_quantifind'; // run this procedure to set things up on provider's side call provision_consumer($consumer_account,$my_master_db); // set the results of the function above to this session variable set new_cust_id = 1; // STEP 2: Take the newcustid number returned by the above, and tell the consumer to run the consumer enablement procedure with that customer ID // STEP 3: Once the consumer has confirmed that they have done that, run this to enable the consumer: call enable_consumer($new_cust_id, $consumer_account, $base_url, $consumer_share_name, $my_master_db, $my_wh);
You can see the consumer’s side of the experience, including how the consumer can then insert new data and receive the enrichments back, here.
Using This Approach with Your Own API
If you’ve gotten to this point, you’re probably thinking about how you could apply this technique to your own API. While much of what I have presented for this Quantifind example is reusable, the following parts would need to be adapted:
- The lambda function to call your API. Different APIs are called in different ways, especially when it comes to the format of the input and output payloads, and the methods that need to be invoked.
- Result pagination. In this example, the batch size per API call is limited to 200 in Step 5 (and the data is automatically chunked into calls by Snowflake), and one row in equals one row out, so we don’t need to pull paginated results because they will never exceed 200. However, in many scenarios, one request could result in thousands or millions of rows back, in which case the result pulls need to be paginated. I will show this technique in a future blog post.
- The authentication approach (where the API key is stored and how it is passed). Different APIs have different ways of handling this.
- The procedures to submit and receive results. The version shown here is asynchronous, although many APIs will be synchronous, which simplifies the flow. I will show an example of a synchronous flow in a future blog post.
- The specific data needed from the consumer. In this example, the consumer provides customer data, but this may vary with your use case.
Snowflake Professional Services would be happy to assist you in adapting this approach to your particular API, or you can use the patterns above to do it on your own.
Security Considerations
In this example, Quantifind provides an API key to their customers via email or another channel, and the consumer shares that API key from their Snowflake account to Quantifind. Then Quantifind uses that key to call their API on the consumer’s behalf. This provides for strong data security, access protection, rate limiting, and contract call-capping for each customer.
Alternatively, a provider could use a customer-specific API key, or even a master API key, that it stores in its Snowflake account or in its lambda function (or in a key management service attached to the lambda). However, that would increase the security considerations for the provider compared to this “API key stays in customer’s account” model where the key is accessed by the provider as needed but is never stored by the provider.
Another security consideration relates to the storage of resulting data in the provider’s Snowflake account. In this example, the results are stored in Quantifind’s Snowflake account and then shared with the customer. If that is a concern for either party, the result payloads could be encrypted by the lambda (or even by a remote API), shared with the consumer in encrypted form, and then decrypted once they are in the consumer’s Snowflake account. Our new ENCRYPT function may be useful for this, although ideally the encryption step happens either in the lambda or on the remote API itself. Our new DECRYPT function can be used by the consumer on the data they receive to securely decrypt it inside the consumer’s own Snowflake account.
Another mitigation of such concerns is to purge data from the provider’s account after a period of time that allows the consumer to first use the streams to store the data locally. Quantifind uses this approach, but I omitted it from the code examples in this post to keep things slightly simpler.
Cost Considerations
In this example, the provider incurs four types of costs:
- Snowflake compute to make the API calls when a consumer adds new data. Generally, an “Extra Small” Snowflake compute instance (Virtual Warehouse) can be used, and it can only be active when it is actually making API calls.
- Snowflake storage to store the resulting data (although this can be for only a small amount of time, which typically makes these costs rather small)
- AWS API Gateway, and AWS lambda execution and associated data transfer costs (these tend to be rather small)
- Any costs of running or maintaining the provider’s existing API that is being called
These costs can be offset by data sharing rebates, which are generated when the consumer queries the resulting data. Some providers also charge their customers an extra fee to provide data in this manner. The best way to estimate these costs is to simulate a typical customer’s activity pattern, measure the resulting costs, and extrapolate to the total customer population you expect to serve.
Automation Considerations
While the steps in this example may seem complex, once they are developed and tested against a data provider’s API, the process is completely automatable for both new regions and new consumers. Adding support for consumers in a net new Snowflake region takes just a few minutes, and adding a new consumer takes a few seconds. Both steps are easy to script for automation, for example, by calling them from an existing system, such as ServiceNow, or from a command line interface, as new customers are onboarded.
Because all of the steps are done on the Snowflake side, as mentioned previously, Snowflake Professional Services can be retained to perform the development and testing of these procedures, so the data provider does not need to do any data engineering or other work, or change anything at all on their existing systems.
How to Get Started
If you have a data enrichment API and you want to become a provider on Snowflake Data Marketplace, this API-based approach may be a good way to get there by leveraging your existing API. Another benefit of this approach is that if you adopt Snowflake more natively over time, you could start to share data natively and reduce your reliance on your API, without the need for your customers to make any changes on their side. Join the Snowflake Data Marketplace team to begin the journey!



